


物体检测相关——学习笔记
1.概述
对图片/视频,用框(bounding box)标出物体的位置,并给出物体的类别。
2. 物体检测数据集
PASCAL VOC, 20类, 比较简单, 图片中物体所占比较大比较少; http://host.robots.ox.ac.uk/pascal/VOC/
COCO, 微软做的,80类物体, 单张物体稠密, 验证检测器性能常用数据集。http://cocodataset.org/#home
3. 评价检测器的性能

绿色为人手工标注的ground truth,红色是检测器标注的。
怎么评价检测器的性能:
3.1 Intersection over Union(IoU)交并比
是预测框与label的交集比上两者并集的比值;若为1则为最优分类器,一般来说IOU>0.5就代表预测正确。
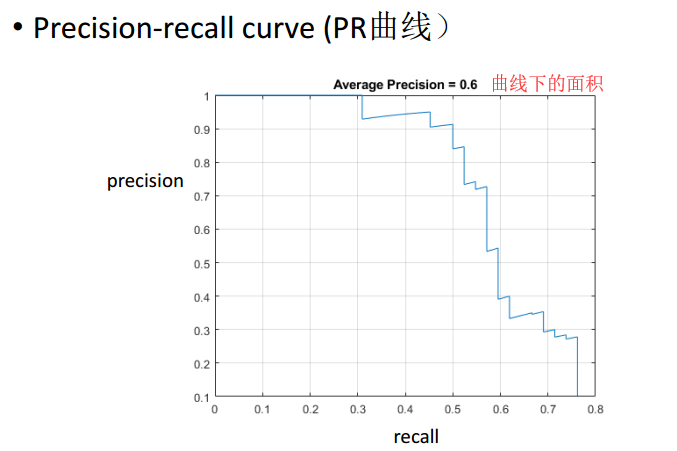
3.2 precision-recall curve(PR曲线)精度-召回曲线
改变置信度的阀值计算精度和召回,做出曲线,代表评测器综合性能。
对于一张图片的检测结果,每一个结果都有一个对应的得分,得分代表一种检测的结果置信度,根据检测结果可以计算得到TP,FP,FN,TN等,通过不断改变阈值就可以绘制出PR曲线。
特点:整体趋势,随着召回率的增加精度下降,但局部会发生增加现象。
原因:整体下降:随着置信度阀值的降低召回率基本不变,而精度会逐渐降低;局部增加:正例中含有假正例子还造成局部增加。
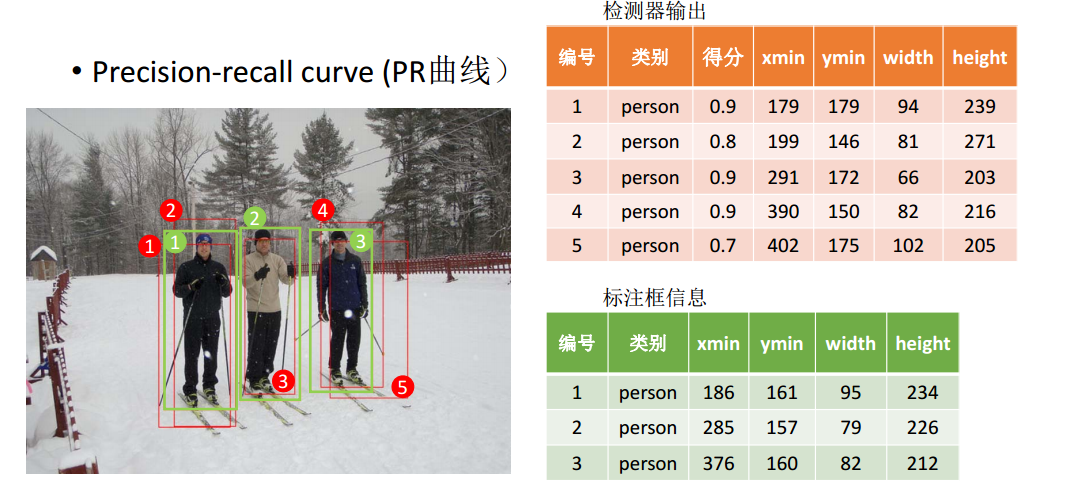
将检测结果按照得分降序排序;打标签,一对一规则。

不断改变阈值。

4、物体检测算法
不管是传统方法还是深度学习方法都可以看作:搜索加分类;
传统方法中是滑动窗,提取窗口内的部分进行物体检测。
框的大小固定,将图像resize为各种大小的图片集合(图像金字塔),使得框内的部分大小变化,从而实现用固定大小的框检测不同大小的物体。

传统的方法:人工手动特征+浅层分类器
基于深度学习网络:带有标签的数据+深度神经网络

传统方法:
论文1:Robust Real-Time Face Detection
使用了滑动窗+图像金字塔
Haar特征,用白框的像素值减去灰框中的像素值,得到的结果是该区域的Haar特征值
级联分类器

论文2:Deformable Part Models(DPM)
特征HOG+分类器SVM,图像金字塔

深度学习方法:
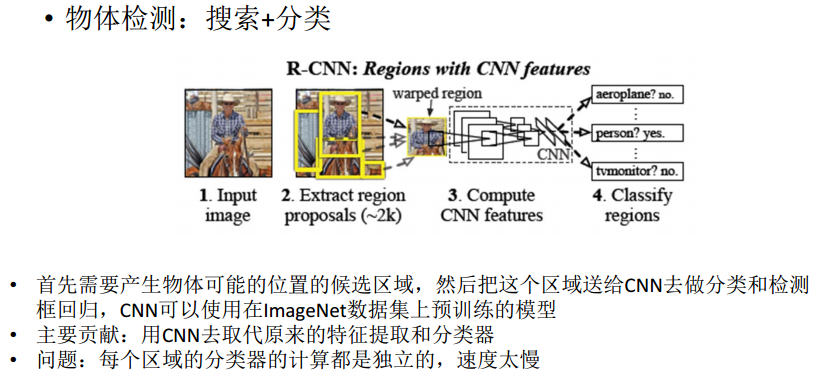
论文1 R-CNN
http://islab.ulsan.ac.kr/files/announcement/513/rcnn_pami.pdf
传统方法与神经网络结合,使用传统方法生成候选区域,候选区域resize到固定尺寸后,送入CNN分类。
主要贡献:用CNN取代了原来的特征提取和分类器。
论文2 Fast RCNN
https://arxiv.org/pdf/1504.08083.pdf
RCNN的问题是会重复计算。对每个候选区域,可能会有重叠,在重复计算。
FastRCNN将图片送入CNN,得到特征图,feature map。
使用了ROI pooling,转为固定尺寸的大小,后接全连接。
主要贡献:避免了相同区域的特征重复提取。但是目前的候选区域生成都是传统方法,成为瓶颈。
具体改进是将原始图片直接送进CNN网络,之后在输出的feature map上进行候选区域的选择;同时引入了一层ROI pooling,用来将候选区域转换为固定大小的feature map。转化出来的feature map转换为全连接层,之后继续进行特征分类以及BB回归。这种方法共享了特征图计算,节省了大量计算量。

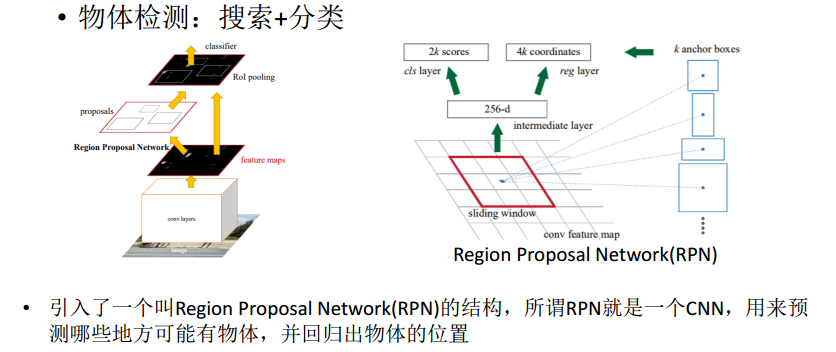
论文3 Faster RCNN
https://arxiv.org/pdf/1506.01497.pdf
引入了RPN结构(浅层CNN),来生成一系列候选区域。提高速度。
论文4 R-FCN
https://arxiv.org/pdf/1605.06409.pdf

加入位置敏感score maps,直接得到类别的概率。
图中,C代表类别。例如coco数据集,80类+1背景类。
论文5 YOLO
https://arxiv.org/pdf/1506.02640.pdf
对一张图片直接计算回归,得到bb的位置和类别。
7*7是大小,30=VOC20类+10(2框*(4+1))

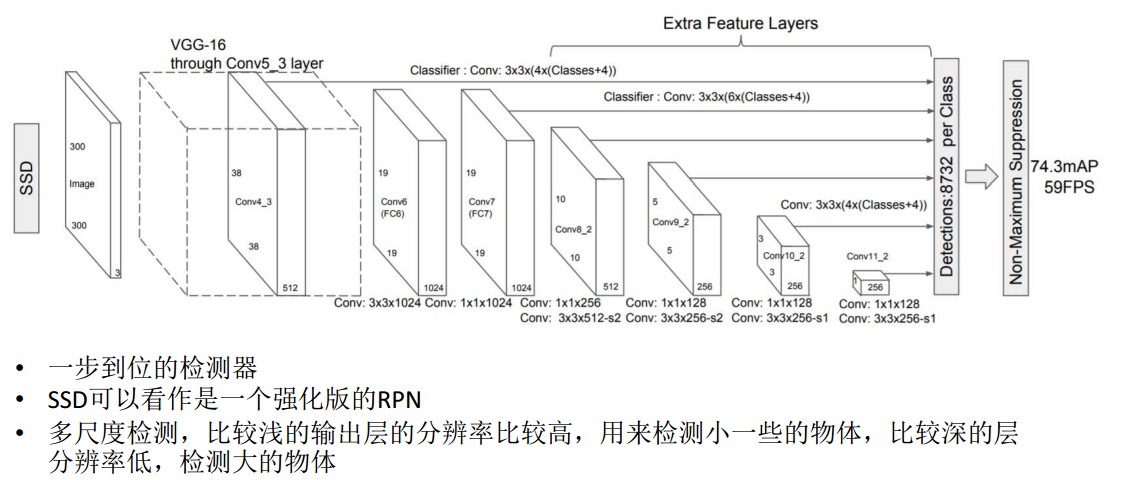
论文6 SSD,强化版RPN
https://arxiv.org/pdf/1512.02325.pdf
类似YOLO,一步到位。
可以看做强化版的RPN
用不同阶段的特征图进行预测,所以可以检测不同尺度的物体。
论文7 FPN
https://arxiv.org/pdf/1612.03144.pdf
多尺度检测
将深层的特征图与浅层的特征图相加(有交融),提升表达能力。

论文8 Mask RCNN
https://arxiv.org/pdf/1703.06870.pdf

论文9 Focal Loss
https://arxiv.org/pdf/1708.02002.pdf
one stage准确率低于two stage的原因:
样本不均衡,负样本太多

目标检测原理与应用(上) - 计算机视觉基础入门课程(从算法到实战应用) - AI研习社 - 研习AI产学研新知,助力AI学术开发者成长。 http://www.mooc.ai/course/353/learn?lessonid=2343&groupId=46#lesson/2343

