
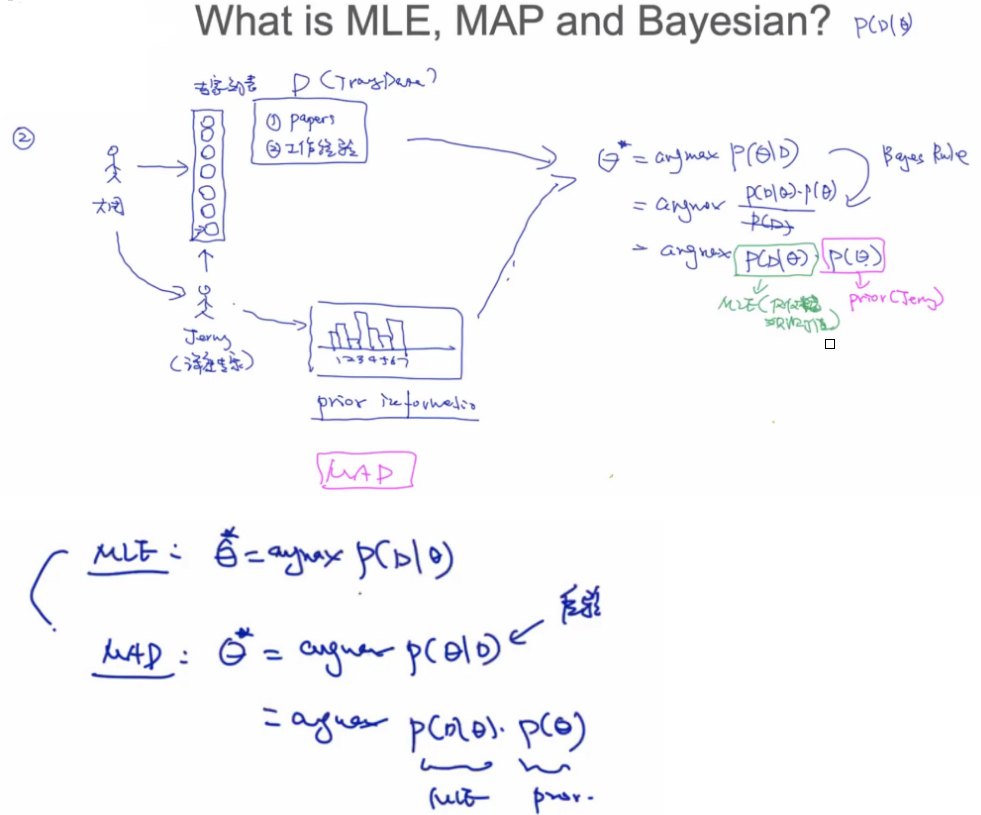
MLE、MAP、贝叶斯三种估计框架
三个不同的估计框架。
MLE最大似然估计:根据训练数据,选取最优模型,预测。观测值D,training data;先验为P(θ)。
MAP最大后验估计:后验概率。
Bayesian贝叶斯估计:综合模型。权重叠加。
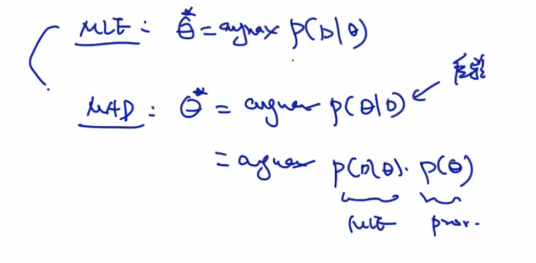
Coin Toss Problem 扔硬币问题
硬币不均匀,P(H正面)=θ
若所投硬币序列为HHTHHT。
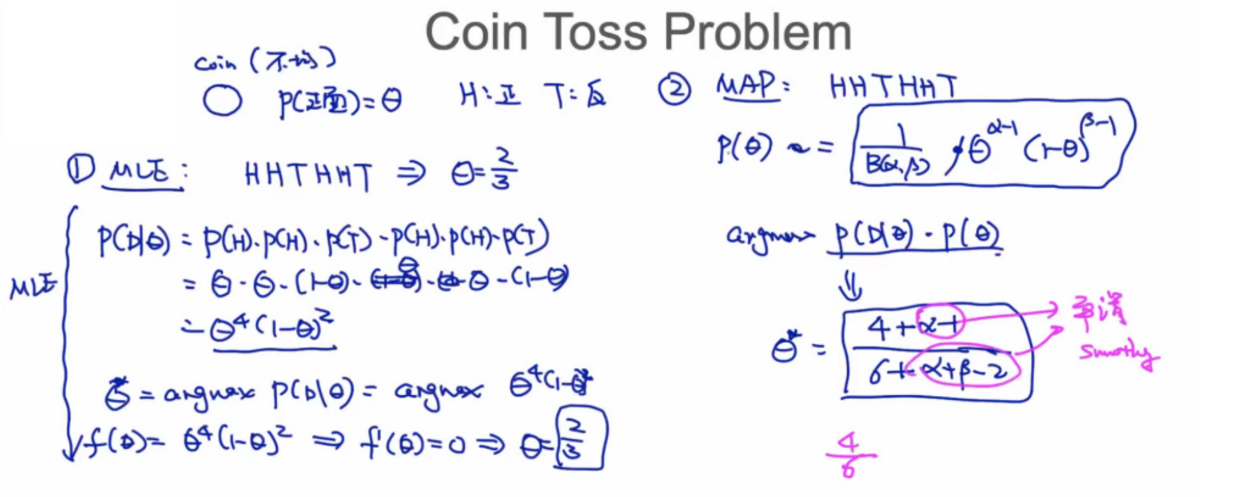
可以看出,若由人直接感官判断,正面概率为2/3。这其中包含了MLE思想。
由MLE严格推导可以得出正面概率确实为2/3。
MAP近似到MLE
当n足够大时,先验P(θ)可以忽略。先验本身不会随着数据量增多而变化。

逻辑回归+高斯先验
P(θ)主要由

添加了高斯先验时,等同于添加了L2正则。
添加了拉普拉斯先验,等同于L1正则,会形成稀疏解。

LASSO:
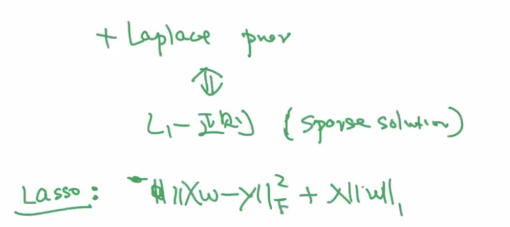
MLE:只根据训练数据得到模型,通过最优模型来预测。
MLE和MAP都是点估计。

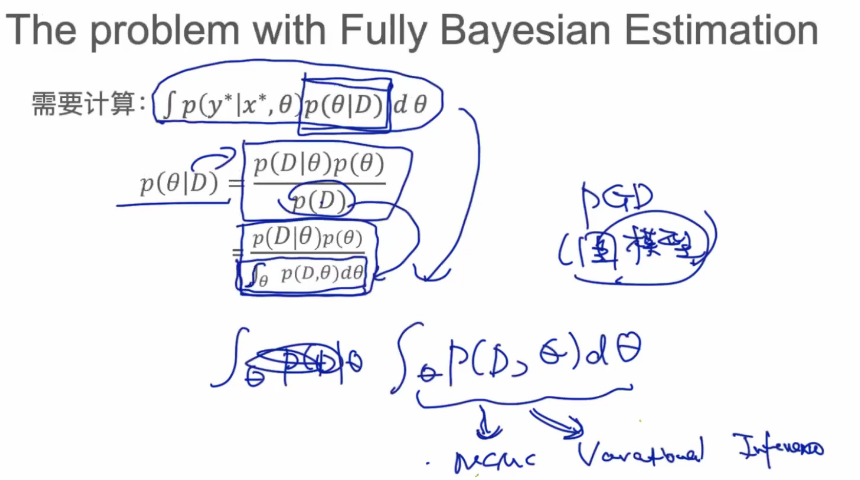
MCMC:一种采样方法。
贝叶斯模型很复杂,通常需要蒙特卡洛或变分法来求解。
Monte Carlo Simulation蒙特卡洛仿真
抽样,近似。用在Bayesian中近似函数

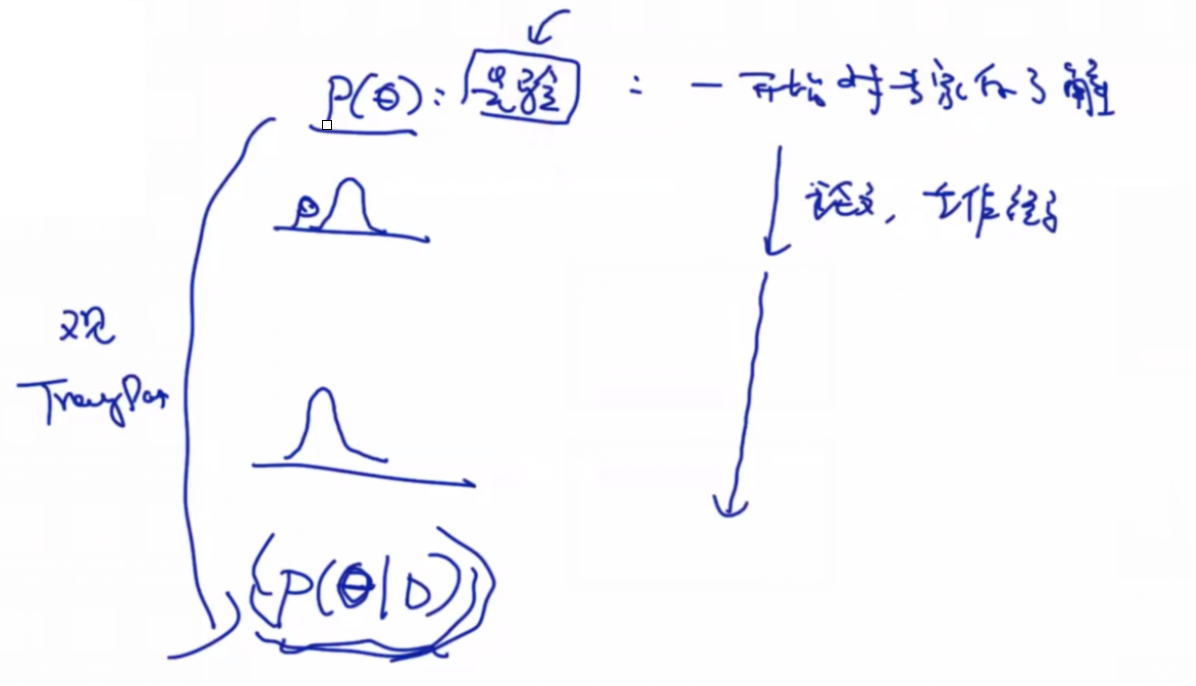
先验概率
后验概率:D在后面,表示根据训练数据获得更为精确的P(θ)。
L1正则更为稀疏。
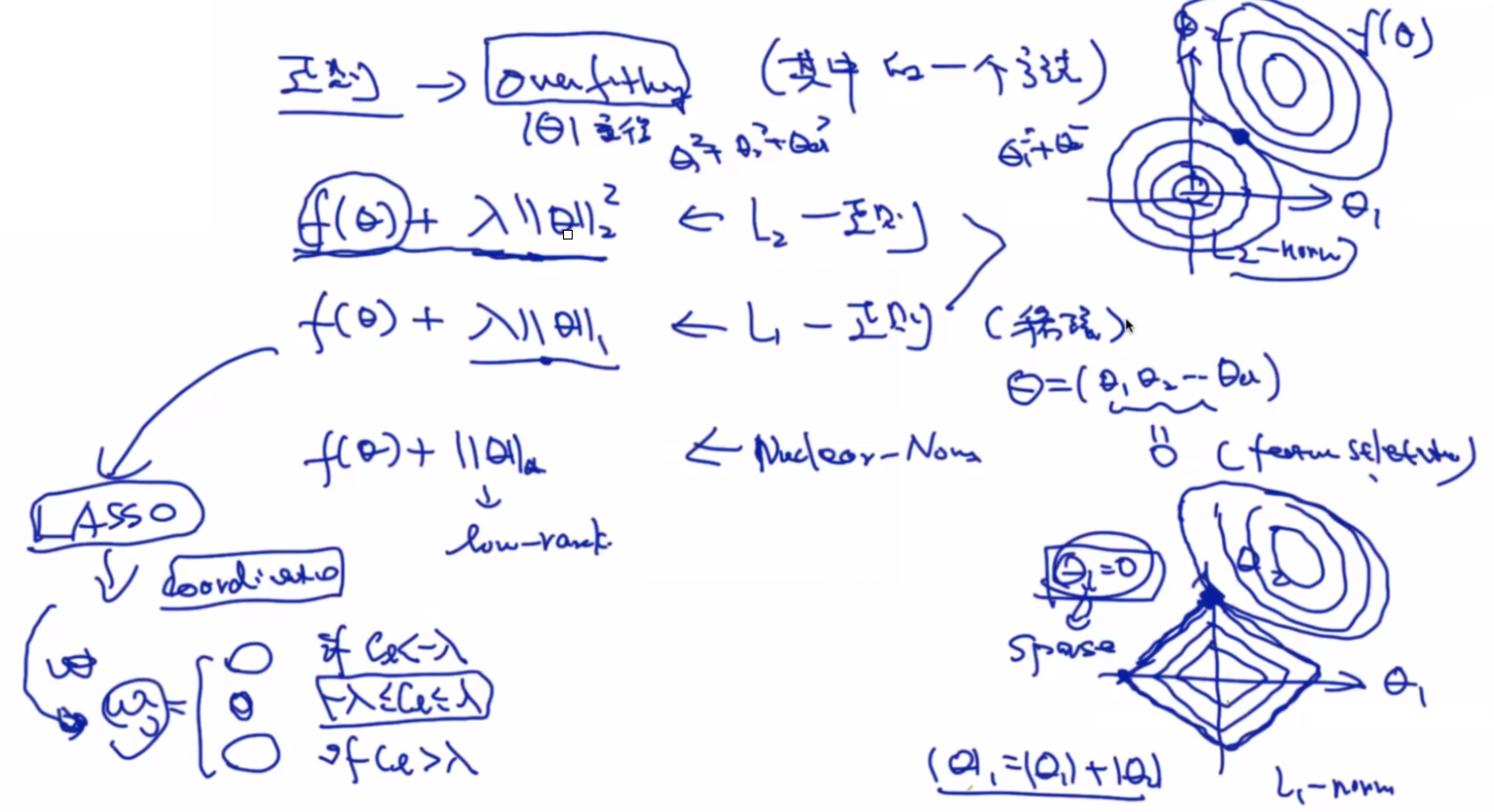
ζั͡ޓއ genji - 至此只为原地流浪.......
