
集成学习AdaBoost算法——学习笔记
集成学习
个体学习器1
个体学习器2
个体学习器3 ——> 结合模块 ——>输出(更好的)
...
个体学习器n
通常,类似求平均值,比最差的能好一些,但是会比最好的差。
集成可能提升性能、不起作用、甚至起负作用。
集成要提高准确率!
每一个个体学习器之间存在差异
一定要有差异性,有差异性才能提升。这些弱学习器需要,好而不同。
集成学习分类:Bagging Boosting
Bagging:并行生成,然后结合。不存在依赖关系。
Boosting:依赖关系,一个一个学习器产生。
AdaBoost算法
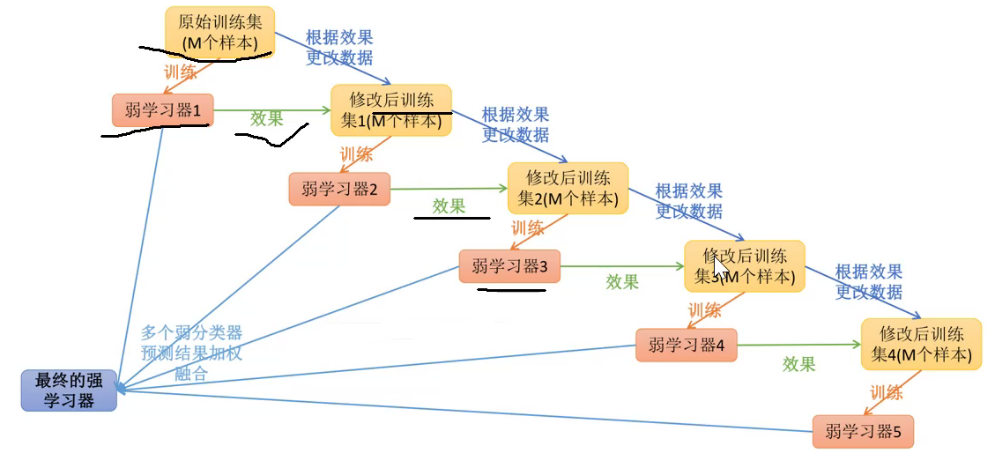
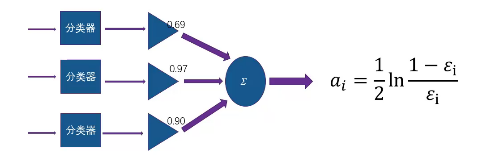
多个弱学习器加权融合:
误差率
每一个样本权重1/M,如果分错一个
分错第几个点
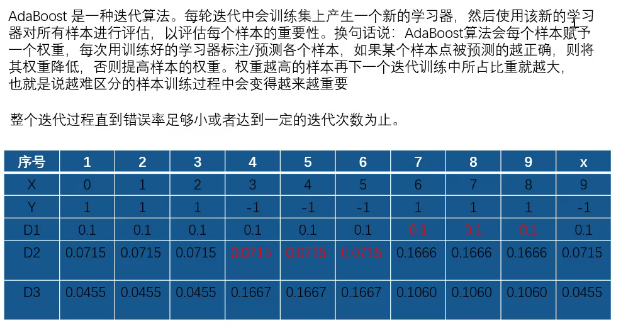
预测错误的权重提高(预测),迭代训练至错误率足够小。

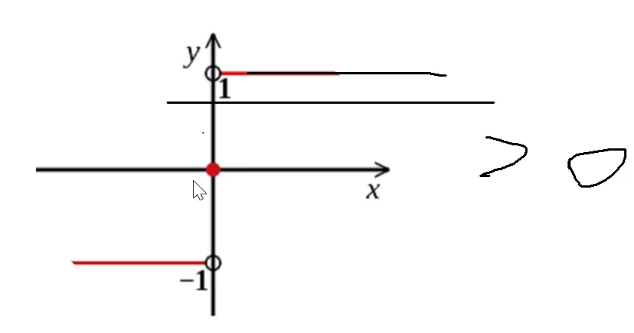
Sign函数:1、-1两类。(>0or<0?)
算法流程:
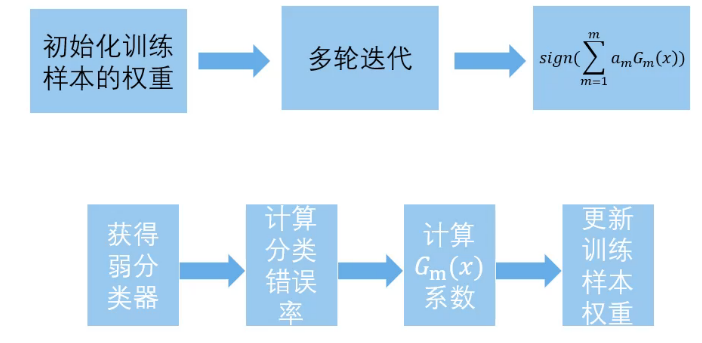

10个样本,每个样本权重1/10=0.1
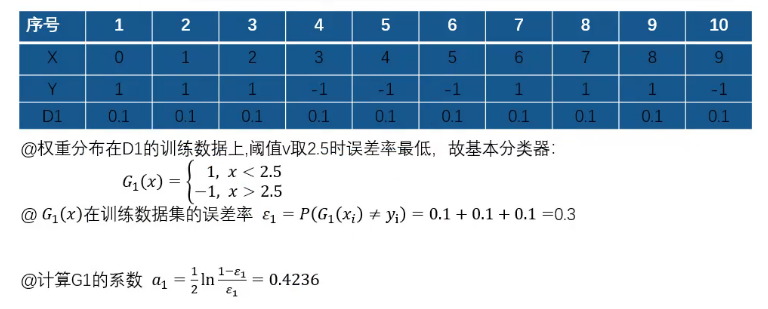
阈值根据观察,可以2.5/5.5/8.5?
选择误差率最低的,<阈值,Y=1。
2.5时,6、7、8,Y=-1分错了;
5.5时,3、4、5、6、7、8分错了。

第二次:

计算系数后,再次更新权重:

第三次:
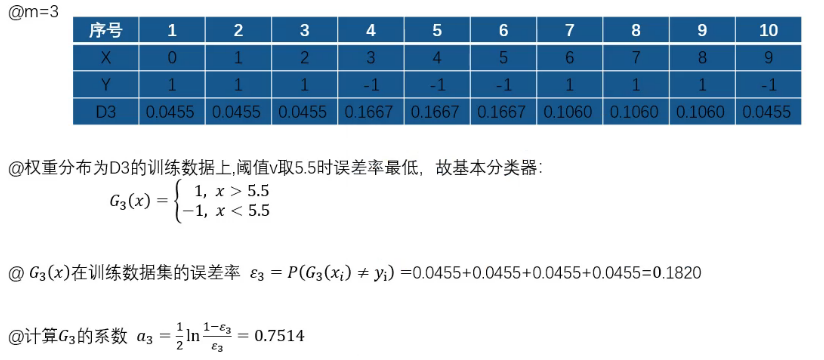
权重变化
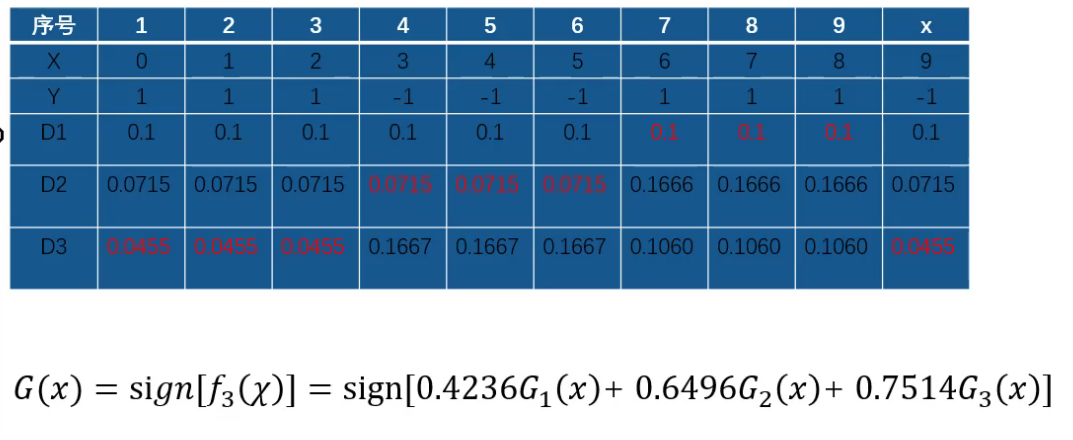
对上一个分类器,分类错误的。迭代。
优点:

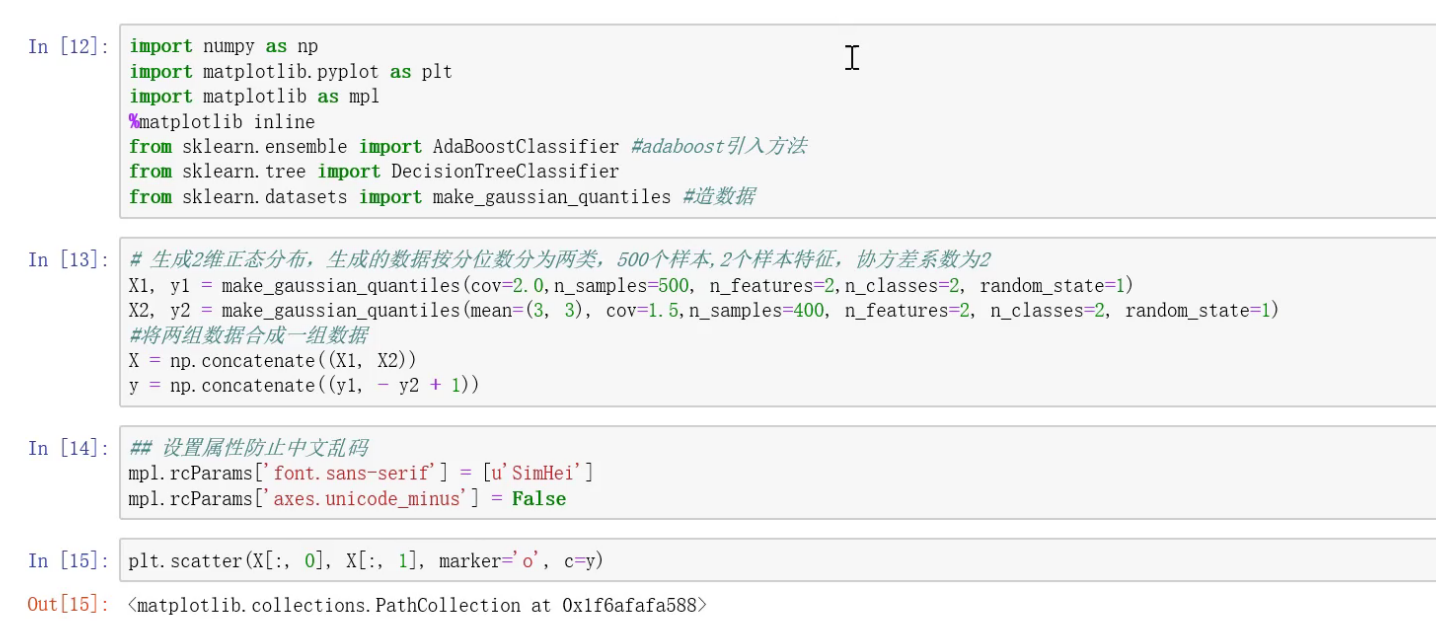
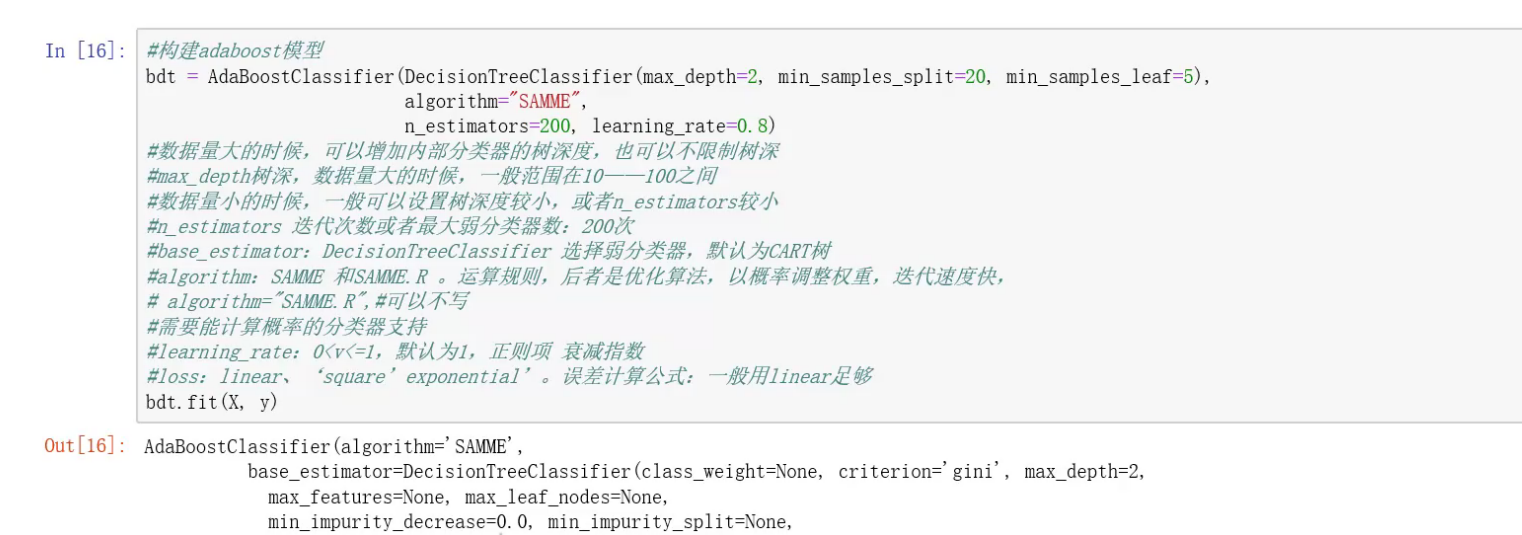
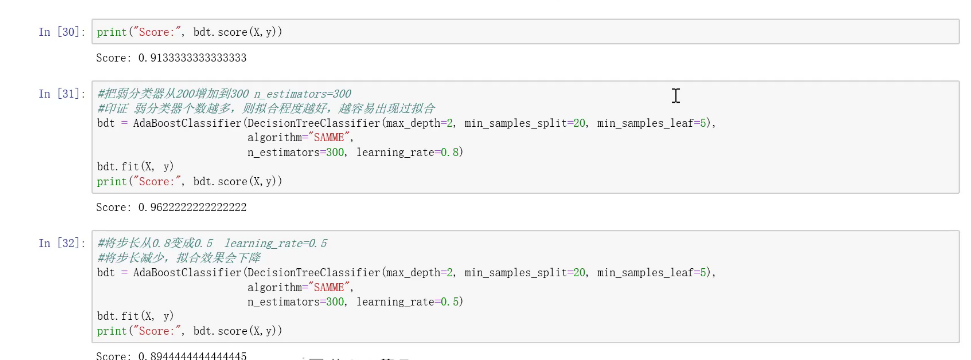
决策树构建模型:
ζั͡ޓއ genji - 至此只为原地流浪.......
