
《信息安全系统与设计》第九章学习笔记
第九章 I/O库函数
系统调用函数
1.open( ):打开和创建文件,例如:
int open(const char * pathname, int flags, mode_t mode)
2.read( ):读文件,例如:
ssize_t read[1] (int fd, void *buf, size_t count)
3.write( ):写文件,例如:
ssize_t write (int fd, const void * buf, size_t count)
4.lseek( )每一个已打开的文件都有一个读写位置, 当打开文件时通常其读写位置是指向文件开头, 若是以附加的方式打开文件(如O_APPEND), 则读写位置 会指向文件尾. 当read()或write()时, 读写位置会随之增加,lseek()便是用来控制该文件的读写位置. 参数fildes 为已打开的文件描述词, 参数offset 为根据参数whence来移动读写位置的位移数。例如:
off_t lseek(int fildes, off_t offset, int whence)
5.close( ):关闭文件,例如:
int close(int fd)
I/O库函数
1.fopen( ):以指定的形式打开文件
(1)r 以只读方式打开文件,该文件必须存在。
(2)r+以读/写方式打开文件,该文件必须存在。
(3)rb+以读/写方式打开一个二进制文件,只允许读/写数据。
(4)rt+以读/写方式打开一个文本文件,允许读和写。
(5)w打开只写文件,若文件存在则长度清为0,即该文件内容消失,若不存在则创建该文件。
(6)w+打开可读/写文件,若文件存在则文件长度清为零,即该文件内容会消失。若文件不存在则建立该文件。
(7)a以附加的方式打开只写文件。若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾,即文件原先的内容会被保留(EOF符保留)。*
(8)a+以附加方式打开可读/写的文件。若文件不存在,则会建立该文件,如果文件存在,则写入的数据会被加到文件尾后,即文件原先的内容会被保留(原来的EOF符 不保留)。
(9)wb以只写方式打开或新建一个二进制文件,只允许写数据。
(10)wb+以读/写方式打开或建立一个二进制文件,允许读和写。
(11)wt+以读/写方式打开或建立一个文本文件,允许读写。
(12)at+以读/写方式打开一个文本文件,允许读或在文本末追加数据。
(13)ab+以读/写方式打开一个二进制文件,允许读或在文件末追加数据。
2.fread( ):从给定流 stream 读取数据到 ptr 所指向的数组中。
(1)size_t fread(void *ptr, size_t size, size_t nmemb, FILE stream)
(2)ptr -- 这是指向带有最小尺寸 sizenmemb 字节的内存块的指针。
(3)size -- 这是要读取的每个元素的大小,以字节为单位。
(4)nmemb -- 这是元素的个数,每个元素的大小为 size 字节。
(4)stream -- 这是指向 FILE 对象的指针,该 FILE 对象指定了一个输入流。
fwrite( ):把 ptr 所指向的数组中的数据写入到给定流 stream 中.
(1)size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream)
(2)fseek( ):设置流 stream 的文件位置为给定的偏移 offset,参数 offset 意味着从给定的 whence 位置查找的字节数。
(3)int fseek(FILE *stream, long int offset, int whence)
(4)stream -- 这是指向 FILE 对象的指针,该 FILE 对象标识了流。
(5)offset -- 这是相对 whence 的偏移量,以字节为单位。
(6)whence -- 这是表示开始添加偏移 offset 的位置。它一般指定为下列常量之一。
fclose( ):关闭流 stream。刷新所有的缓冲区。
(1)int fclose(FILE *stream)
I/O库函数的算法
1.fread算法
(1)第一次调用时,fread()使用保存的文件扫描符fd发出 n=read(fd, fbuffer, BLKSIZE);系统调用,用数据块填充内部的fbuff[];
(2)初始化fbuff[]指针、计数器和状态变量;
(3)将数据复制到程序缓冲区;
(4)若内部缓冲没有足够的数据,则使用read()继续填充内部缓冲区,并将数据从内部缓冲区复制到程序缓冲区;
(5)复制完之后,更新内部缓冲区的指针、计数器,为下次read()做准备。
2.fwrite算法
(1)将数据写入内部缓冲区,调整缓冲区指针、计数器和状态变量;
(2)若缓冲区满,则调用write()将缓冲区写入系统内核。
fclose算法
(1)关闭文件流局部缓冲区;
(2)发出close(fd)系统调用关闭file结构体文件描述符;
(3)释放file结构体,并将file指针重置为null。
I/O库模式
1.字符模式I/O
int fgetc(FILE *fp)
该函数以无符号 char 强制转换为 int 的形式返回读取的字符,如果到达文件末尾或发生读错误,则返回 EOF。
int ungetc(int c, FILE *fp)
如果成功,则返回被推入的字符,否则返回 EOF,且流 stream 保持不变
int fputc(int c, FILE *fp)
如果没有发生错误,则返回被写入的字符。如果发生错误,则返回 EOF,并设置错误标识符。
2.行模式I/O
char *fgets(char *buf, int size, FILE *fp)
从fp中读取最多的为一行(以\n结尾)的字符
int fputs(char *buf,FILE *fp)
将buf中的一行写入fp中。
3.格式化I/O
(1)格式化输入
scanf(char *FMT,&items)
fscanf(fp, char *FMT,&items)
(2)格式化输出
printf(char *FMT,items)
fprintf(fp,char *FMT,items)
3.内存中的转换函数
sscanf(buf,FMT,&items)
sprintf(buf, FMT, items)
4.其他I/O库函数
(1)fseek()、ftell()、rewind():更改文件流中的读/写字节位置
(2)feof()、ferr()、fileno():测试文件流状态
(3)fdopen():用文件描述符打开文件流
(4)freopen():以新名称重新打开现有的流
(5)setbuf()、setvbuf():设置缓冲方案
(6)popen():创建管道,复刻自进程来调用sh
文件流缓冲
1.概述
每个文件流都有一个FILE结构体,其中包含一个内部缓冲区。对文件流进行读写需要遍历FILE结构体的内部缓冲区。文件流可以使用三种缓冲方案中的一种。
(1)无缓冲:从非缓冲流中写入或读取的字符将尽快单独传输到文件或从文件中传输。
(2)行缓冲:遇到换行符时,写入行缓冲流的字符以块的形式传输。
(3)全缓冲:写入全缓冲流或从中读取的字符以块大小传输到文件或从文件传输。这是文件流的正常缓冲方案。
2.setvbuf()
解释:定义流 stream 应如何缓冲
int setvbuf(FILE *stream, char *buffer, int mode, size_t size)
3.fflush()
解释:刷新流 stream 的输出缓冲区。
int fflush(FILE *stream)
具体实例:
#include<stdio.h>
int main(){
setvbuf(stdout, NULL, _IONBF, 0); //设置缓冲区
while(1){
printf("20201319"); //not a line yet
fflush(stdout); //清除stdout
sleep(1); //sleep for 1 second
}
}
执行结果为:
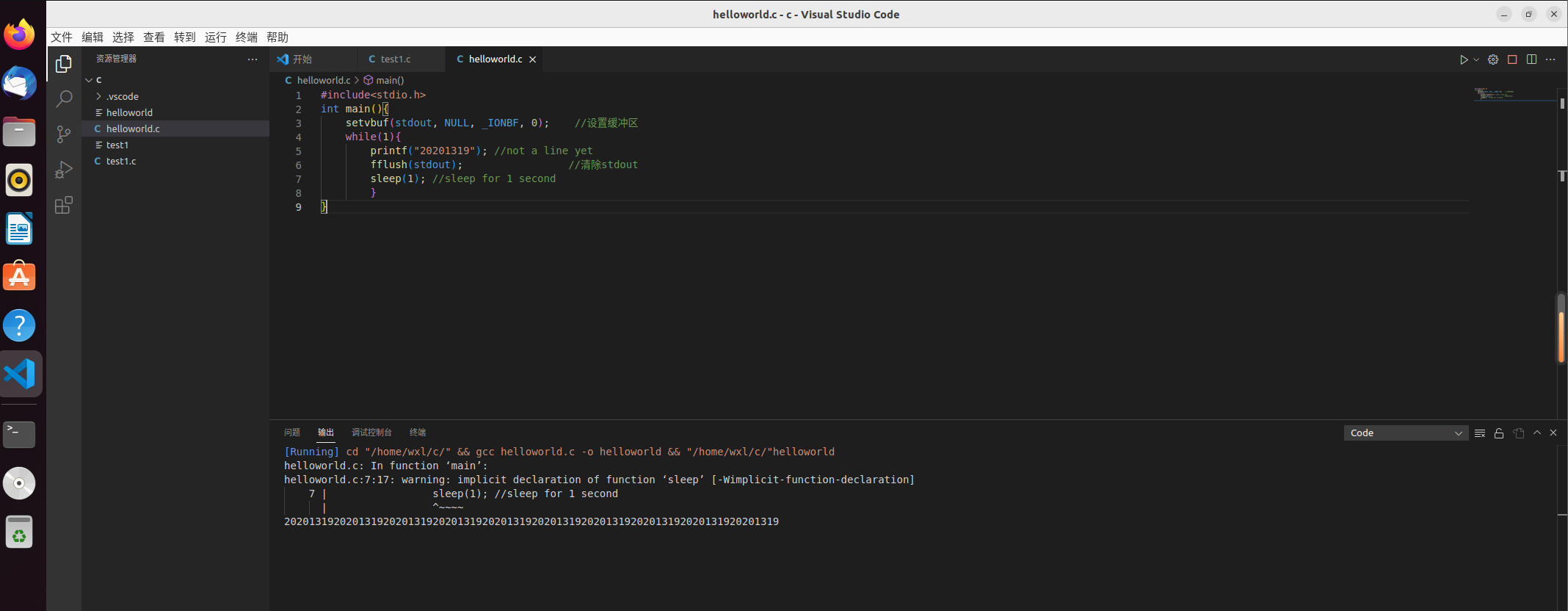
设置缓冲区的效果为无缓冲,则每秒打印一个“20201319”,如果不设置,因为stdout是行缓冲,则只有当打印出来的字符与stdout的所有内部缓冲区匹配时,才会输出。
如果将设置缓冲区和清除stdout注释掉则不会输出,因为stdout是行缓冲,如果没有换行标志“\n”,则需要写满缓存区才能执行I/O操作。因为加入whiel(1)死循环,程序不会终止,系统不能清理缓存区,同时,行缓存的缓存区大小为1024,而要打印的字符是无法填满缓存区的,所以无法打印。
自己的收获
最大的收获是明白了系统调用和I/O库调用的区别,以及为什么I/O库调用会更快。以read/write函数与fgetc/fputc函数举例:
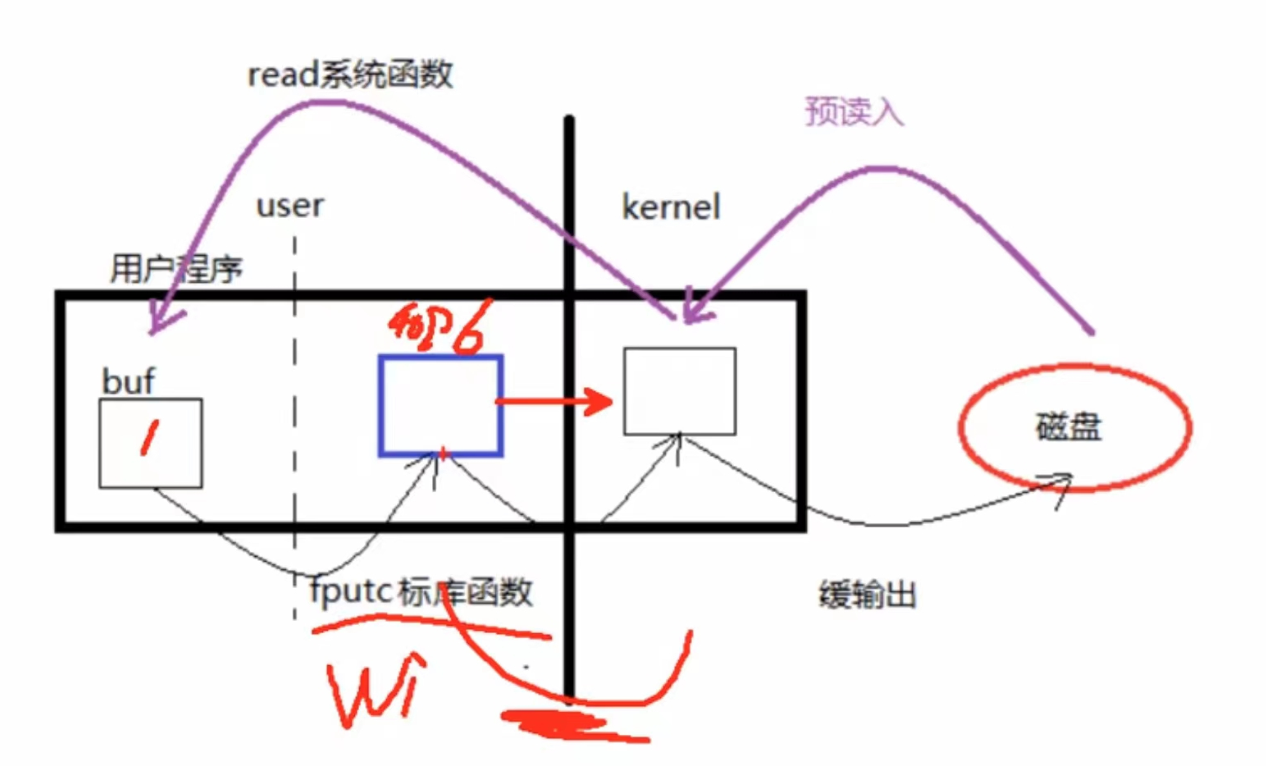
如上图所示,write函数需要不断重复的执行系统调用进入到内核写入内核缓存,当内核系统缓存写满(4kb)后再写入磁盘;而库函数内部就有一个库函数缓存,当库函数写满后(4kb)再调用系统调用函数read/write函数进入内核写入内核缓存并立即写入磁盘中。因此库函数fgetc/fputc速度比系统调用函数read/write函数速度更快。
问题
1.系统调用是怎么进行的?
当一个进程正在运行,遇到读写文件操作,会发生一个中断,中断后系统会把当前用户进程的一些寄存器信息保存在内核堆栈中,接着去处理中断服务程序,这里是要去执行系统调用,Linux 中通过执行 int $0x80 来执行系统调用的中断,但内核实现了很多系统调用,这时需要传递「系统调用号」来指明需要哪个系统调用。参考网络上代码如下具体说明:
#include<stdio.h>
#include<stdlib.h>
int main()
{
time_t tt;
struct tm *t;
asm volatile (
"mov $0,%%ebx\n\t"
"mov $0xd,%%eax\n\t"
"int $0x80\n\t"
"mov %%eax,%0\n\t"
: "=m" (tt)
);
t = localtime(&tt);
printf("Time: %d-%02d-%02d %02d:%02d:%02d\n",
t->tm_year + 1900,
t->tm_mon + 1, t->tm_mday,
t->tm_hour, t->tm_min, t->tm_sec);
}
运行结果为:
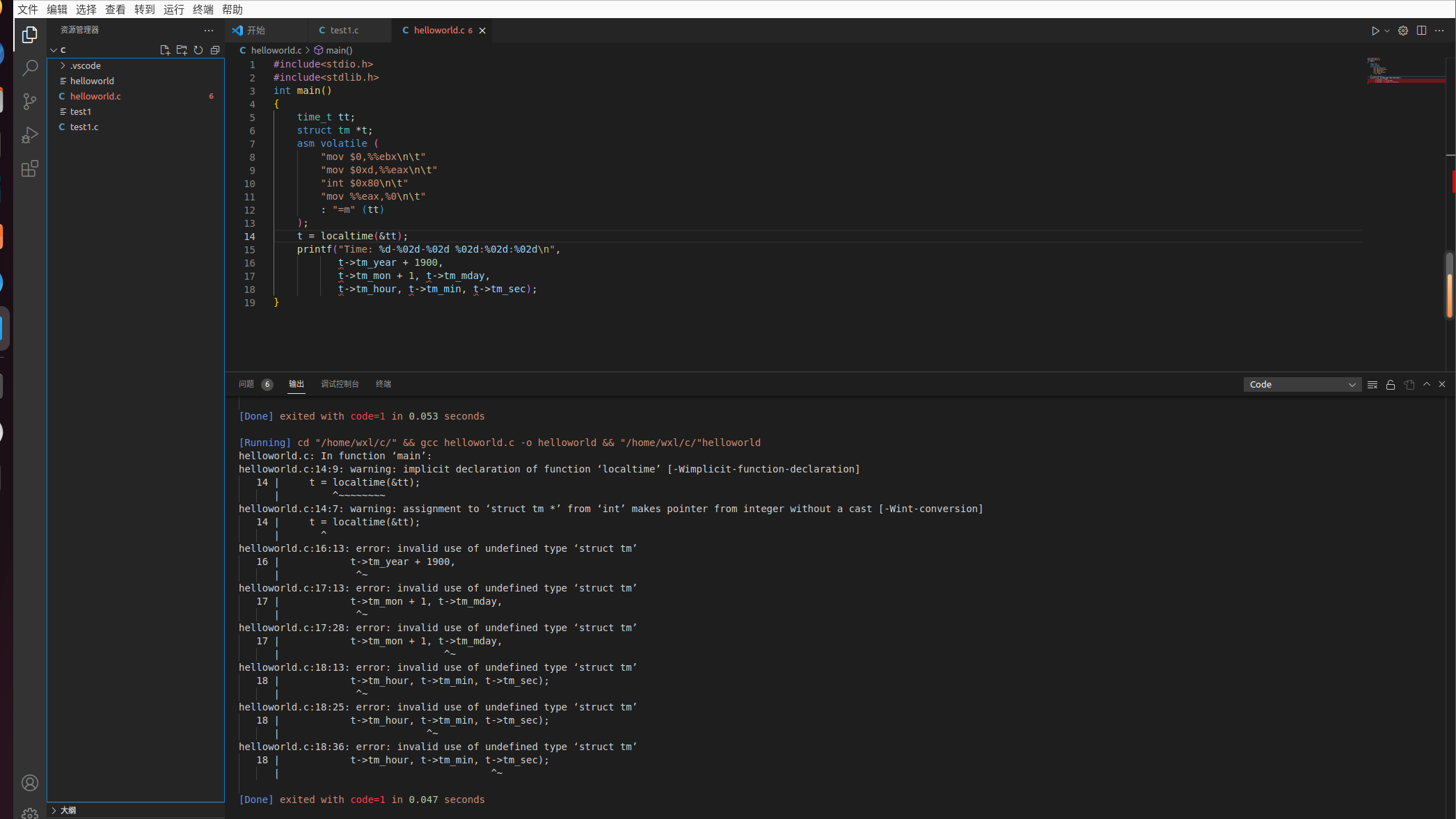
首先通过 mov $0xd %%eax 来将系统调用放入 %eax 寄存器中,time() 的系统调用号是 13,然后执行 int $0x80 系统就会去执行 time() 这个系统调用了。其实代码中的汇编部分就是实现 time() 系统调用的功能,这就是系统调用的整个过程。
