redis的数据类型
六种数据类型(2016-01-26):字符串、散列、列表、集合、有序集合、HyperLogLog
字符串
:存储文字、数字、二进制为字符串设置值:set key value [NX|XX]
NX:键key不存在才生效(新建),XX存在才生效(覆盖旧值)
setnx key value <==> set key value NX
同时设定
mset key1 value1 key2 value2,复杂度O(N)
mget key1 key2
键的命名:不能重复的,一般使用::,如news::sport:cache
只有当所有的key都不存在才成功,只有有一个存在,则失败
msetnx key1 value1 key2 value2
设置新值并返回旧值 getset key new_value #返回old_value
def getset(key,new):
old=get(key)
set key new
return old
追加内容到字符串尾部,时间复杂度O(N) append key value
长度:strlen key,复杂度O(1)
范围设定 setrange key index value,只能使用正向索引
范围取值 getrange key start end 包括start,end
数字操作:
不支持太大的值,字母,科学计数法
增加或者减少数字的值 incrby、decrby key increment
增1减1,incr key;decr key
浮点自增和自减 incrbyfloat num 3.14/-3.14,没有decrbyfloat
数字也可以执行append、strlen、setrange、getrange。数字->字符串->执行命令->数字
二进制索引:从左到右依次递减
设置二进制位的值 setbit key index value。命令返回旧值(0/1)
getbit key index 返回给定索引上的二进制的值
计算为1的二进制位的位置 bitcount key [start][end]
二进制位运算 bitop operation(and or xor not) dest_key key1 key2
存储中文注意:一个英文只要一个字节存储,中文一般3个
strlen、setrange、getrange都是为英文设定的,中文不太合适。
散列:
有多个域组成关联域值对:hset key field value,如果field之前没有关联值,返回1;
获取关联域的值:hget key field
仅当域不存在,则设定关联field: hsetnx key field value
检测域是否存在 hexists key value,存在返回,不存在返回0
删除给定的域值hdel key field [field2]. 复杂度O(N)
获取散列包含的键值对数量:hlen key
一次设定或获取散列中的多个域值对:hmset key field1 value1 field2 value2…
hmget key field field1 field2
获取散列的所有域、值、或者域值对:hkeys key; hvals key; hgetall key
对域的值进行自增:hincrby key field increment; hincrbyfloat key field increment #没有相应decr
散列与字符串
散列的好处:将相关的信息存储在key中,而不是直接分散存储。方便数据管理,尽量避免误操作
避免键名冲突,虽然之前有说过使用::做分隔符,但这种存储的键比较少
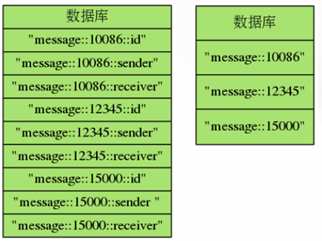
减少内存占用:redis每存储一个键,都要存储一些附加的信息(比如键的类型,访问的时间等),所以键值越多。服务器在存储附加管理信息方面耗费的内存就越多,花在管理数据库键上的CPU也会越多。另外当散列包含的域 值对数量比较少的时候,redis就会自动使用一种占用内存非常少的数据结构来做散列的底层实现。在散列数量比较多的时候,这对减少内存有很大的帮助
不使用散列而使用字符串:
使用二进制位操作:redis字符串支持setbit,getbit,bitop;过期功能只能对key有效,对field没用
列表list
左推,返回列表长度:lpush key value1 value2 value2
右退:rpush
lpush 0 1 2 3 -> 3 2 1 0; rpush 0 1 2 3 -> 0 1 2 3
左弹:lpop
右弹:rpop
长度:llen key
返回给定索引项lindex key index,复杂度O(N)
返回给定索引范围之内的所有项 lrange key start stop
设定指定索引上的列表项:lset key index value;
指定位置插入列表项:linsert key before|after pivot value;返回-1表示pivot不存在;0表示key不存在;插入成功,返回列表长度
从列表中删除指定的值lrem key count value ; count>0,从左向右删除最多count个值;count<0从右向左删除最多count绝对值个;count=0 删除列表中所有的value的项;时间复杂度为O(N)
提取列表中的项:ltrim key start stop,索引可以是负数
阻塞弹出:blpop key1 [key2,key3] timeout 从左到右,访问给定的各个列表,并弹出首个非空列表最左[brpop右]端的项;如果所有给定列表都为空,那么客户端将被阻塞,直到等待超时,或者有可弹出的项为止,timeout设定为0表示永远阻塞;需要注意的是,如果多个客户端都在blpop,brpop时阻塞,但是redis会按照先到先服务的原则,如果客户端A先发送命令,则当有数据推到列表中时,先返回给A
开源的消息队列:python rq、resque、celery
集合set
无序的
添加元素 sadd key element[element2..]
移除元素: srem key element [element..]
检测给定元素是否存在: sismember key element,元素和不存在的key返回0
获取集合大小:scard key,命令复杂度O(1)
返回集合的所有元素 smembers key, 复杂度O(N)。当集合基数很大时,应尽量避免使用此命令
随机弹出一个元素:spop,返回弹出的元素
从集群中随机返回元素:srandomember key [count],如果没有指定count,那么命令随机返回集合中的一个元素。如果count为正数,且小于元素总数,返回一个有count个各不相同的元素。如果count大于等于集合个数,返回整个集合。当count为负数。返回count个元素,元素可能有重复的值。注意它不会删除弹出的值
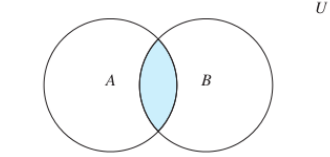
差集:sdiff A B; sdiffstore destkey C A B;
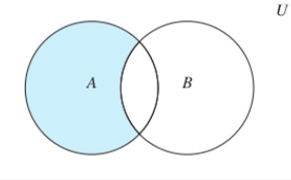
交集:sinter A B;sinterstore C A B
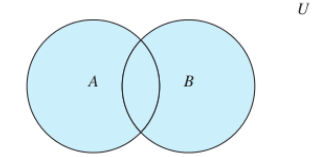
并集:sunion A B; sunionstore C A B;
有序集合sorted set/zet
每个元素有分值(float)的集合
添加元素 zadd key score element [score2 element2]。复杂度O(M*log(N))
删除元素 zrem key element [element2 element3]。返回成功删除元素的个数
返回元素的分值 zscore key element
增加或减少元素的分值:zincrby key increment element;注意没有相应的decr
返回元素数量: zcard key
返回元素的排名:zrank key element; 时间复杂度O(log(N))
返回元素的逆序排名:zrevrank key element
获取指定索引范围内的升序元素:zrange key start stop [withscores];复杂度为O(log(N)+M)
获取指定索引范围内的降级元素:zrevrange key start stop [withscores];
获取指定分值范围内的升序元素:zrangebyscore key min max [withscores] [limit offset count],返回有序集合在按照分值升序排列列表的情况下,分值在min和max范围之间,withscores返回分数和值,给定limit时,通过offset跳过多少个结果集,而count参数则用于指定返回元素的数量
获取指定分值范围内的降序元素: zrangebyscore key min max [withscores] [limit offset count], 复杂度log(N) + M;M返回元素的数量
计算给定分值范围内的元素数量: zcount key min max
移除指定排名范围内的升序排列元素:zremrangebyrank key start stop
移除指定分值范围内的升序排列元素:zremrangebyscore key min max
计算并集:zunionstore destkey numkeys key[key2…]
计算交集:zinterstore destkey numkeys key[key2..];numkeys指定计算的有序集合个数
HyperLogLog
使用常量空间估算大量的基数,适用于只想知道输入元素基数,但不需要知道具体输入元素。优点:输入元素的数量或体积非常大,计算基数所需的空间总是固定的、并且是很小的。在redis中,每个HyperLogLog键只需要花费12kb内存,就可以计算接近2^64个不同元素的基数。这和计算基数时,元素越多耗费的内存就越多的集合形成鲜明对比。因为HyperLogLog只会根据输入元素来计算基数,而不会存储输入元素本身,所以HyperLogLog不能像集合那样,返回输入的各个元素
将元素添加至HyperLogLog:pfadd key element[element…],元素改变返回1
返回基数估算值:pfcount key
合并多个hyperloglog: pfmerge destkey sourcekey[sourcekey2…],复杂度O(N)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号