
顶刊TPAMI 2024 | PERF:一张2D全景图可合成高质量的360度3D场景
前言 本文提出了一种新的方法解决单张 2D 全景图恢复 360 度 3D 全景问题,利用扩散模型的先验知识和单目深度估计器进行合作修补大尺度遮挡区域,并提出了一种新的冲突避免策略,实现了当前最佳的单张全景图恢复 360 度 3D 场景的效果。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
本文转载自PaperWeekly
仅用于学术分享,若侵权请联系删除
招聘高光谱图像、语义分割、diffusion等方向论文指导老师

研究背景随着深度学习与 3D 技术的发展,神经辐射场(NeRF)在 3D 场景重建或逼真新视图合成方面取得了巨大的进展。给定一组 2D 视图作为输入,神经辐射场通过优化隐式函数来表示 3D 场景。
然而,在很多情况下,我们只有单张 2D 视图。一些工作尝试从具有 3D 先验的单张图像训练神经辐射场。他们主要关注有限的视野,因此仅需考虑少量的遮挡,这极大地限制了它们在具有大尺寸遮挡的真实 360 度全景场景中的可扩展性。
在很多真实的应用场景下,我们通常需要 360 度全视角的 3D 场景。因此,有必要研究利用 360 度视角相机(例如 Insta360 或者 Ricoh THETA SC2)拍摄的一张 2D 全景图来恢复 360 度全视角的 3D 场景任务,如图 1 所示。

▲ 图1. 单张全景图恢复360度3D场景

研究挑战和存在的方法
利用单张 2D 全景图进行 360 度 3D 全景恢复是一个挑战的问题。具体地:
1. 全景图是全景相机在某个位置捕获得到的 360 度 2D 视图,不包含 3D 信息。在没有任何 3D 先验的条件下,无法从单张 2D 全景图中训练出有效的神经辐射场 NeRF;
2. 由于单张全景图像只能捕捉到相机位置目光所及的可见区域,存在部分无法观测的区域。因此,训练单视图全景神经辐射场非常具有挑战性,它耦合了 3D 场景重建和 3D 场景生成两个学习任务。一方面,给定的一张全景图,我们需要重构其可见区域;而另一方面,我们必须在不可见区域生成合理的内容,在语义上匹配 3D 空间的可见区域,这是很困难的。
3. 与有限视角的单张图恢复 3D 场景 [1-3] 或以物体为中心的 360 度物体重建 [4] 不同,全景场景通常包含大尺寸遮挡且侧重于开放场景。
4. “可见区域的重建”和“不可见区域的生成”通常会出现几何冲突。在不可见区域的场景生成过程中,新合成的 3D 几何体不应遮挡原始视角能观测到的可见区域。否则,将导致训练期间出现几何冲突。
注意到,在同期的工作 [5] 中,为了解决 3D 空间中物体的检测与去除,F. Wei 等提出了通过投票和裁剪的方法来保证各视角几何/纹理填补时的不一致性,但存在一些技术上的不同。也推荐读者去阅读此篇论文。本文工作发表在 TPAMI 2024 上。

论文题目:
PERF: Panoramic Neural Radiance Field from a Single Panorama
作者单位:
MMLab@NTU、大湾区大学、香港大学
项目主页:
https://perf-project.github.io/
论文链接:
https://arxiv.org/pdf/2310.16831.pdf
代码链接:
https://github.com/perf-project/PeRF
附:Guangcong Wang 和 Peng Wang 为共同一作,Ziwei Liu 为通讯作者。此工作在 MMLab@NTU 完成。收录顶刊 TPAMI 2024!

研究动机神经辐射场(NeRF)在基于多视图的新视图合成方面取得了实质性进展。近期一些工作尝试从具有 3D 先验的单个图像训练神经辐射场。它们主要关注具有少量遮挡的有限视野,这极大地限制了它们对具有大尺寸遮挡的真实 360 度场景的可扩展性。为了解决这个问题,本文提出了一种新的方法解决单张 2D 全景图恢复 360 度 3D 全景问题。
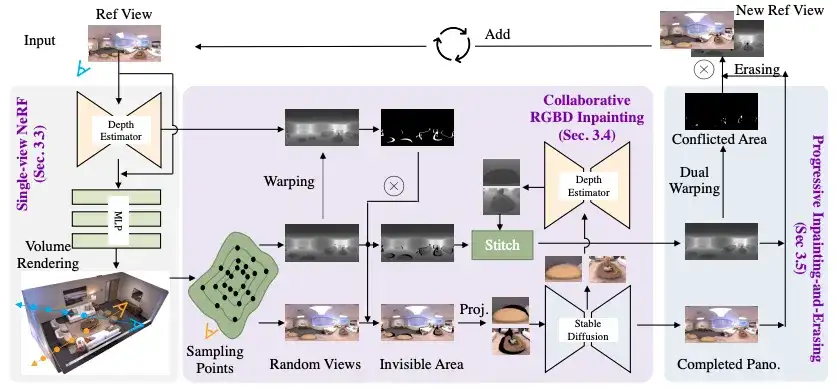
▲ 图2. 本文所提出的PERF框架图

方法框架
上图展示了我们方法 PERF 的框架图。PERF 主要由三个部分组成,包括 1)包含深度图的单视图 NeRF 训练;2)协作 RGBD 修复不可见区域;3)渐进式修复和擦除。
具体来说,给定一张 2D 全景图,我们使用单目深度估计器来预测其深度图,并将输入视图(RGB+depth)作为初始化来训练 NeRF。然后利用一个协作 RGBD 修复模块进行不可见区域填补,该模块包含一个深度估计器和一个稳定扩散模型 (StableDiffusion),从而将 NeRF 扩展到随机视角渲染。
为了避免几何冲突,本文使用了渐进式修复和擦除模块来判别冲突区域并在训练中忽略这些区域。我们使用给定的单视图全景图和随机视点生成的新全景图进行 NeRF 模型的微调直到收敛。

主要贡献
本文的主要贡献有三点:
1. PERF,一种从单张全景图训练 360 度 3D 全景神经辐射场的新方法。为此,我们提出了一种新的协作 RGBD 修补方法,利用预训练的稳定扩散(StableDiffusion)模型进行 RGB 修补,以及使用一个经过训练的单目深度估计器进行几何修补。值得注意的是,协作 RGBD 修补不需要额外的训练。
2. 我们提出了一种渐进式修补和擦除方法,以避免不同视角之间的几何冲突。我们通过逐渐增加一个随机视角来修补不可见区域,并通过比较新添加的视角和参考视角的几何,擦除之间的冲突区域。
3. 在 Replica 和 PERF-in-the-wild 数据集上的大量实验表明,PERF 在单视图全景神经辐射场中达到了新的最先进水平。所提出的 PERF 可应用于全景图-3D、文本-3D 和 3D 场景风格化应用场景,这几个应用展示了非常好的结果。
应用1:单张全景图恢复360度3D场景
利用单张全景图训练,得到的新视角渲染视频。
▲ 图3. 单张全景图恢复360度3D场景
应用2:文本生成360度3D场景应用
首先利用 Text2Light [6] 或者 skybox [7],由文本生成全景图,然后利用本文方法将全景图生成 360 度 3D 场景。如下示例中利用了 skybox。

▲ 图4. 文本生成360度3D场景1

▲ 图5. 文本生成360度3D场景2
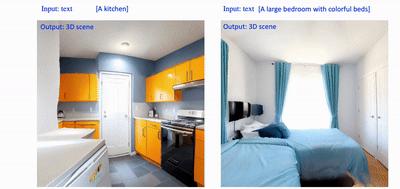
▲ 图6. 文本生成360度3D场景3
应用3:3D场景风格化
先利用 InstructPix2Pix [8] 将全景图风格化,然后利用本文方法将全景图生成 360 度 3D 场景。
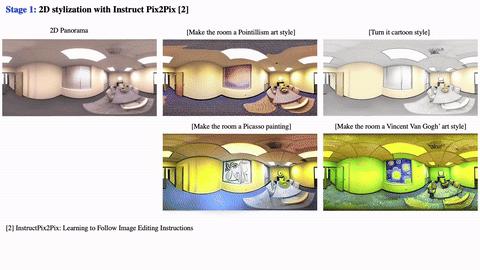
▲ 图7. 3D场景风格化
大湾区大学王广聪课题组招聘
欢迎对计算机视觉、深度学习和图形学等领域感兴趣的同学(2024,2025级)加入王广聪课题组!我们诚挚邀请博士后、博士研究生、硕士研究生、研究助理、访问学生和实习生加入我们的课题组,共同探索前沿科技,详情请点击:
https://wanggcong.github.io/recruit2024.html
参考文献
[1] D. Xu, Y. Jiang, P. Wang, Z. Fan, H. Shi, and Z. Wang, “Sinnerf: Training neural radiance fields on complex scenes from a single image,” in Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXII. Springer, 2022, pp. 736–753
[2] Z. Yu, S. Peng, M. Niemeyer, T. Sattler, and A. Geiger, “Monosdf: Exploring monocular geometric cues for neural implicit surface reconstruction,” Advances in Neural Information Processing Systems (NeurIPS), 2022
[3] A. Yu, V. Ye, M. Tancik, and A. Kanazawa, “pixelnerf: Neural radiance fields from one or few images,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 4578–4587
[4] D. Xu, Y. Jiang, P. Wang, Z. Fan, Y. Wang, and Z. Wang, “Neurallift360: Lifting an in-the-wild 2d photo to a 3d object with 360deg views,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 4479–4489
[5] F. Wei, T. Funkhouser, and S. Rusinkiewicz, “Clutter detection and removal in 3d scenes with view-consistent inpainting,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 18 131–18 14
[6] Z. Chen, G. Wang, and Z. Liu. "Text2light: Zero-shot text-driven HDR panorama generation." ACM Transactions on Graphics (TOG) 41, no. 6 (2022): 1-16.
[7] https://skybox.blockadelabs.com/[8] Brooks, T., Holynski, A. and Efros, A.A., 2023. Instructpix2pix: Learning to follow image editing instructions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 18392-18402).
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
LSKA注意力 | 重新思考和设计大卷积核注意力,性能优于ConvNeXt、SWin、RepLKNet以及VAN
CVPR 2023 | TinyMIM:微软亚洲研究院用知识蒸馏改进小型ViT
ICCV2023|涨点神器!目标检测蒸馏学习新方法,浙大、海康威视等提出
ICCV 2023 Oral | 突破性图像融合与分割研究:全时多模态基准与多交互特征学习
HDRUNet | 深圳先进院董超团队提出带降噪与反量化功能的单帧HDR重建算法
南科大提出ORCTrack | 解决DeepSORT等跟踪方法的遮挡问题,即插即用真的很香
1800亿参数,世界顶级开源大模型Falcon官宣!碾压LLaMA 2,性能直逼GPT-4
SAM-Med2D:打破自然图像与医学图像的领域鸿沟,医疗版 SAM 开源了!
GhostSR|针对图像超分的特征冗余,华为诺亚&北大联合提出GhostSR
Meta推出像素级动作追踪模型,简易版在线可玩 | GitHub 1.4K星
CSUNet | 完美缝合Transformer和CNN,性能达到UNet家族的巅峰!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号