RepVGG-GELAN | 融合 VGG、ShuffleNet 与 YOLO 图像检测的准确性及效率再上一层!
前言 基于YOLO的目标检测算法在速度和准确性之间取得了显著的平衡。然而,它们在脑肿瘤检测中的应用仍然未被充分探索。本研究提出了RepVGG-GELAN,这是一种新型的YOLO架构,通过集成RepVGG,一种重新参数化的卷积方法,特别关注于医学图像中的脑肿瘤检测。RepVGG-GELAN利用RepVGG架构来提高检测脑肿瘤的速度和准确性。将RepVGG集成到YOLO框架中旨在实现计算效率和检测性能之间的平衡。
本研究还包括了一个基于空间金字塔池化的通用高效层聚合网络(GELAN)架构,进一步增强了RepVGG的能力。在脑肿瘤数据集上进行的实验评估表明,RepVGG-GELAN在精确度和速度上都超过了现有的RCS-YOLO。具体来说,RepVGG-GELAN在240.7 GFLOPs的运算速度下,比最新的现有方法精确度提高了4.91%,AP50提高了2.54%。
本文转载自集智书童
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
招聘高光谱图像、语义分割、diffusion等方向论文指导老师

Code:https://github.com/ThensiB/RepVGG-GELAN
1 Introduction
鉴于高发病率和死亡率,脑肿瘤是全球健康关注的重点问题。通过利用深度学习算法等最先进技术,自动化检测技术可以有效解决脑肿瘤识别的挑战。将自动化检测融入医疗流程,有望通过革新脑肿瘤的管理方式显著提高患者疗效和医疗服务,尤其是随着技术的发展。最先进的目标检测方法YOLO在估算每个网格单元的类别概率和边界框时,将输入图像划分为网格。
将YOLO应用于脑肿瘤检测,对于提高神经成像诊断方法的准确性、效率和可扩展性具有重大潜力。卷积神经网络(CNN)作为YOLO目标识别方法的主要组成部分被广泛采用。CNN提供了在图像中识别目标所需的特征提取能力。
因为CNN采用多个卷积和池化层从原始视觉数据构建分层的特征模型,它们能够捕捉到可能指示各种健康问题的复杂模式和结构[3]。为了满足更复杂网络的需求,具有更深层可学习参数的网络,提出了VGG深度卷积神经网络架构。在网络内部,几个卷积层后跟的是最大池化层。
它们密集的分层结构使得能够精确检测和诊断,因此,它们能够从医学图像中识别复杂的模式和特征。VGG架构擅长从医学图像中提取复杂特征和细粒度信息,使其适合需要高分辨率分析的任务[4]。更现代的卷积神经网络架构ShuffleNet的目标是在保持有竞争力的计算效率的同时最大化准确度。
这引入了组卷积和通道混洗的概念,极大地降低了处理成本,同时促进了通道间高效的数据流。ShuffleNet架构在准确性和效率之间提供了合理的平衡,使其成为低功耗设备部署和实时医学成像应用的理想选择。
YOLO架构中实时目标检测的主要思想是,将空间上分离的边界框与匹配的类别概率作为回归任务。为了提高检测的准确性和速度,YOLOv4融入了多项增强措施。它通过跨阶段部分连接包含了CSPDarknet53主干网络,改善了梯度传播和信息流。在YOLOv7中实施了 Anchor-Free 点(AF)检测,使得 Anchor 点框变得多余。这增强了适应性和简化了布局。
此外,YOLOv7还融入了动态卷积,通过动态地根据输入特征值修改感受野,增强了模型提取上下文数据的能力。YOLOv9是YOLO目标检测方法的演变,因其实时检测能力而受到赞赏。
通过结合PGI和GELAN,YOLOv9引入了许多架构改进和训练方法,提高了准确性和性能。YOLOv9建立在YOLOv7和Dynamic YOLOv7的框架之上,并包含了带有CSPNet块的RepConv和GELAN,实现了简化的下采样模块和优化了的 Anchor-Free 点预测头。PGI的辅助损失部分在YOLOv7的辅助头设置之后。
基于重参化卷积和广义高效层聚合网络(GELAN),本研究提出了一种独特的YOLO模型,称为RepVGG-GELAN,以开发用于医学图像的高准确度目标检测器。RepVGG-GELAN的目标是将GELAN和RepVGG模型的优点结合起来,用于目标检测应用。
本文的后续部分结构如下:
第2部分提供了相关研究的概述。
第3部分深入解释了所提出的RepVGG-GELAN模型。
第4部分展示了实施后得到的结果和成果的分析。
最后,第5部分包括结论部分。
2 Literature Review
RepVGG/RepConv ShuffleNet
受到ShuffleNet的启发,RepVGG/RepConv ShuffleNet(RCS)方法采用结构重参化卷积来增强特征提取同时降低计算成本[2]。
如图1所示,使用通道分割算子将具有C x H x W维度的输入张量(分别代表通道、高度和宽度)分割成两个维度相等的张量。在训练期间,每个张量都通过多个卷积块进行处理。这包括3x3卷积、1x1卷积和恒等分支。两个分支的数据在处理完毕后通过通道拼接方式合并。单个张量经过多次卷积步骤以收集大量的特征数据用于训练。由于这种特征学习的多样性,模型能够适应包括复杂背景或遮挡在内的各种目标检测情况。
单个3x3 RepConv在推理时包含所有使用结构重参化的训练方法。这种优化使模型能够更快地得出结论并减少内存使用,这对于需要即时行动或资源有限的情况非常有用。通过改善两个张量之间的信息融合,通道Shuffle算子提高了特征表示的效率。通道Shuffle算子能够正确地结合来自多个卷积组的特征信息,从而增强模型的特征提取性能。通过通道Shuffle算子,计算成本可以降低到1/g,其中'g'表示聚合卷积中的总组数。
与传统的3x3卷积相比,RCS在推理时保持通道间数据传输的同时,将计算成本降低了一半,如图1(b)所示。因此,RCS能够有效地收集进行精确目标检测所需的上下文信息和空间连接。通过使用包括重参化、Shuffle和通道分割在内的前沿方法,RCS产生了出色的特征表示。RCS提供快速有效的推理,可以降低实时应用中的计算复杂度和内存使用。由于结构允许在训练期间从输入数据中学习健壮的表示,它提高了模型识别复杂模式的能力。
RCS是实际目标检测应用的一个优秀选择,因为它通过使用图1所示的RepVGG架构,在计算效率和特征表示之间取得了平衡。
(a)训练阶段,(b)推理阶段(或部署阶段)。
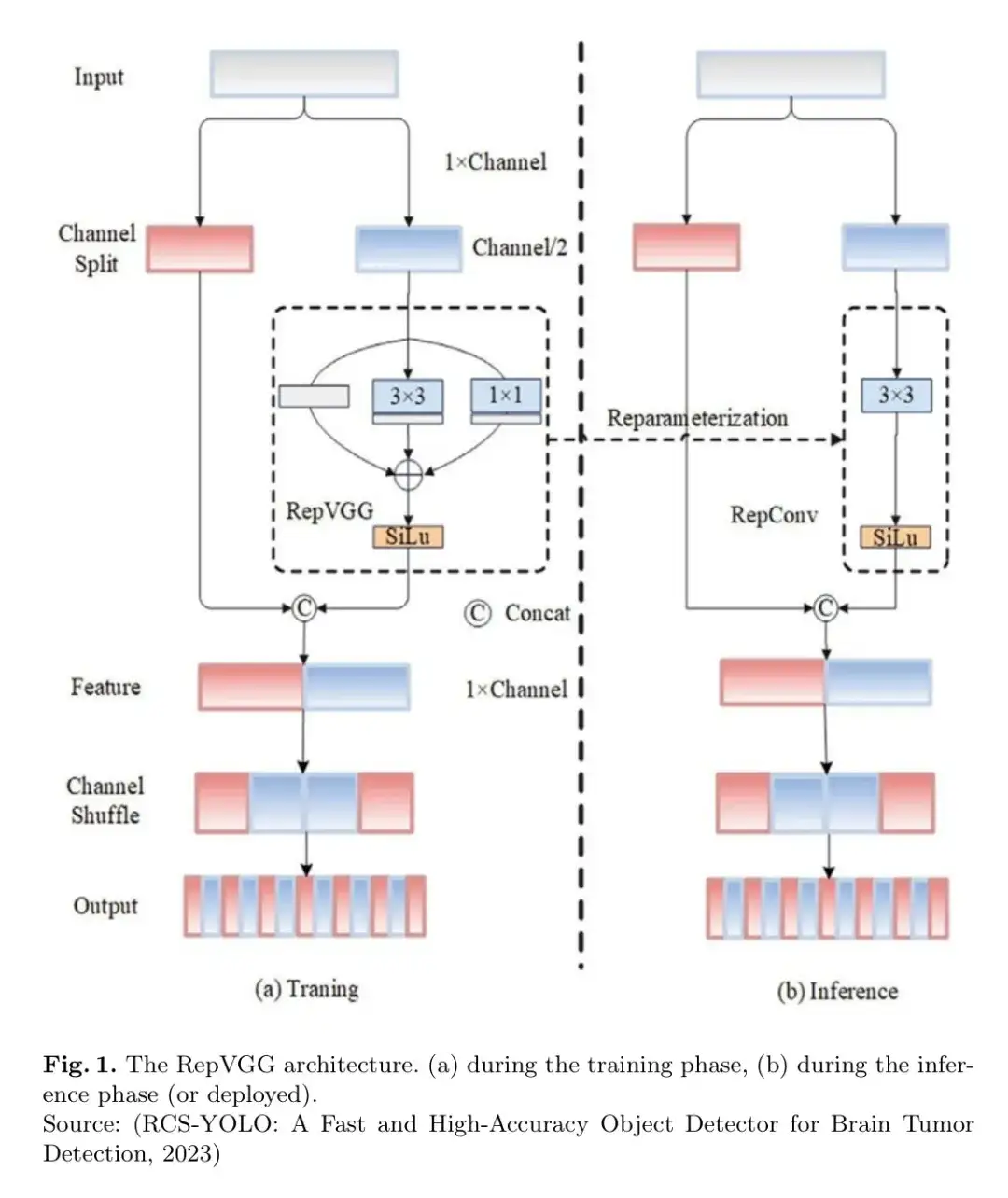
通道分割、Shuffle和重参化算法的灵活性。它在学习不同属性、内存优化和有效推理方面的多功能性使其成为计算机视觉中一个必不可少的工具[2]。
Generalized Efficient Layer Aggregation Network (GELAN)
图2:广义高效层聚合网络架构
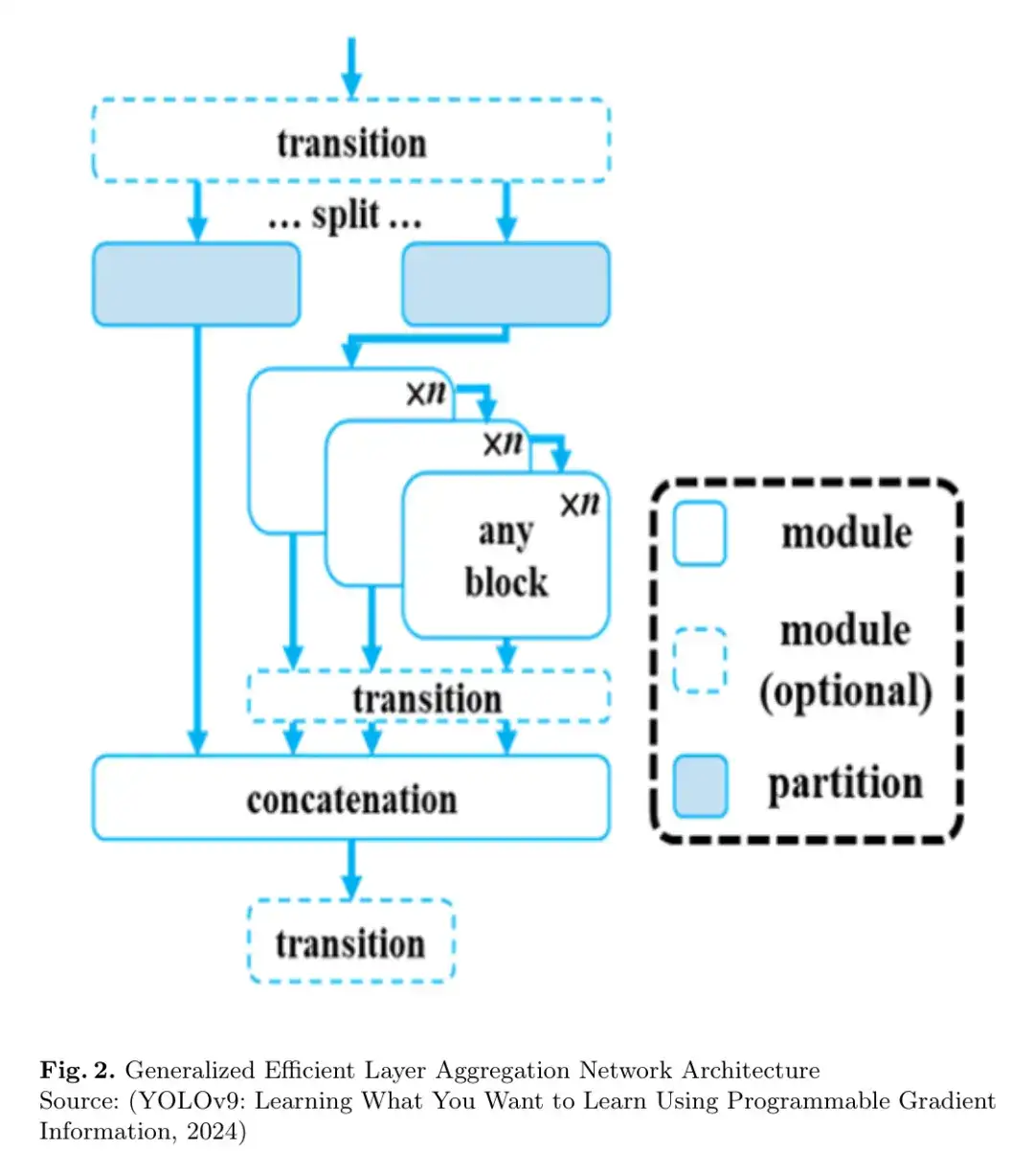
GELAN提供了一种依赖于任务的先进方法。输入张量代表了一组输入到GELAN目标检测模型中的图像数组。批次中的所有图像都有预先确定的通道、高度和宽度。图2解释了GELAN的架构,这是一种基于梯度路径规划的轻量级网络架构。输入张量在 Backbone 层中经历了多次卷积操作。在某些情况下,通道数可以增加,而特征图的空间尺寸(高度和宽度)会减小。
利用这些层在抽象的不同层次提取特征的能力,模型可以获得对目标检测至关重要的高级语义信息和基本细节。输入张量通过 Backbone 层时,对其应用层次化特征提取。每一层捕获不同抽象层次的特征。在接收输入张量后,SPP(空间金字塔池化)块处理特征图以提取多尺度特征。通过自适应池化方法,SPP块提取不同空间分辨率的特征,使其更能抵抗目标大小变化和遮挡。此外,RepNCSPELAN4(带有跨阶段部分CSP和ELAN的Rep-Net)块通过处理输入张量增强和细化特征表示。
RepNCSPELAN4块整合了卷积层以训练判别特征。这些架构组件旨在有效地管理输入属性,同时保留进行准确目标检测所需的空间和语义信息。在网络的不同层次应用上采样技术以增强特征图的空间分辨率。通过将上采样的特征图与早期层的特征图连接,促进了多尺度数据集成。这使得模型能够保留细粒度特征和空间联系,从而改善了目标定位和识别。
在评估特征图后,检测Head生成目标检测的预测。检测Head为接收图像中检测到的每个目标生成边界框、类别概率和其他相关信息。GELAN的检测模块接收来自不同检测层的特征图,并使用它们提供类别置信度评分和边界框预测。
为了生成预测,前向传递中应用卷积层到输入特征图。类别置信度评分和边界框回归预测是通过这些层的输出来计算的。在推理过程中,模块动态地根据输入特征图的结构计算步长和 Anchor 框。这些 Anchor 框被用于解码边界框预测。如果输入发生变化, Anchor 框和步长会动态改变。
GELAN的模块化和灵活性架构使其能够轻松适应各种数据集和目标检测应用。由于其重参化的卷积块、空间金字塔池化和层次结构,模型能够检测大量目标属性和空间相关性。其适应性结构和推理速度使其非常适合在一系列计算机视觉应用中的实际实施,从自动驾驶车辆和医疗成像中的目标检测到监控系统中的人行横道检测。
3 Methodology
本研究提出了一种新型YOLO模型,如图3所示的RepVGG-GELAN,基于RepVGG/RepConv构建了一种用于医学图像的高精度目标检测器。RepVGG-GELAN旨在结合RepVGG和GELAN模型的优势,用于目标检测任务。
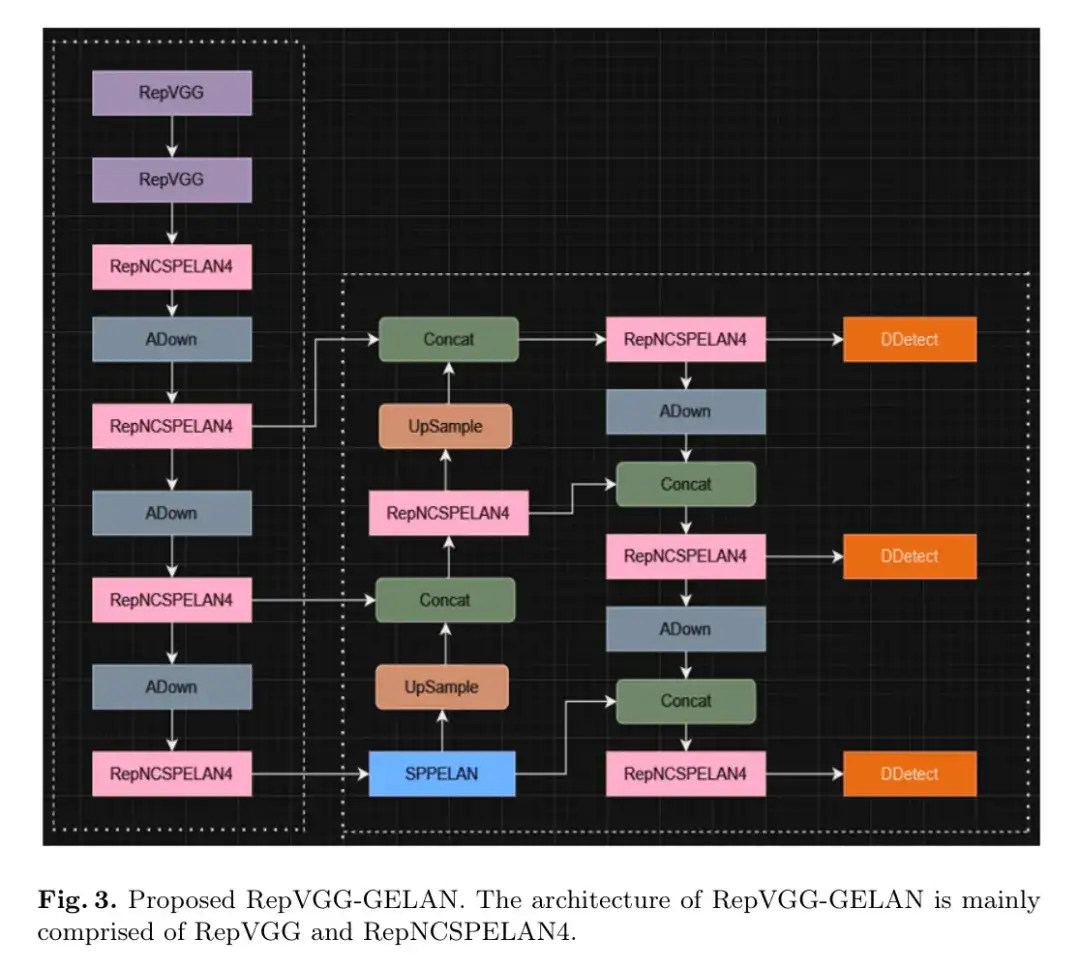
RepVGG(重参化VGG)是一种简化的卷积神经网络(CNN)架构,它结合了深度可分离卷积和残差连接。RepVGG块是RepVGG-GELAN的起点,并因其易于使用和在特征提取中的有效性而闻名。这些块将ReLU和恒等映射结合起来,替换传统的卷积层,从而提高训练的稳定性和性能。
图3:提出的RepVGG-GELAN。RepVGG-GELAN的架构主要由RepVGG和RepNCSPELAN4组成。
RepNCSPELAN4(带有跨阶段部分CSP和ELAN的Rep-Net)是一种结合了跨阶段部分(CSP)连接和ELAN的特征增强块架构。它将输入分成两部分,分别用多个RepNCSP块处理,然后在进行最终卷积层处理之前将输出连接起来。CSP连接促进了网络不同阶段之间的信息流动。ELAN通过注意力机制增强特征表示。RepNCSPELAN4通过结合高效的特征提取与注意力机制,增强特征表示。它使网络能够捕捉并强调与目标检测任务相关的关键特征。
ADown模块表示一个非对称下采样块。它接收一个输入张量x,在一半上进行平均池化,在另一半上进行最大池化,对每个池化后的张量应用卷积操作,并将结果连接起来后返回。这个块对于使用不同操作对每半部分进行下采样特征图很有用。
带ELAN的空间金字塔池化由一系列卷积操作组成,然后进行空间金字塔池化(SPP)操作,其中将特征图划分为不同大小的区域,并分别从每个区域池化特征。然后连接池化的特征并通过另一个卷积层进行处理。这个块对于从输入特征图中捕获多尺度信息很有用。
上采样和连接操作将特征图从主干网络上采样,并与之前阶段的特征连接起来。它们实现了多尺度特征融合并保留空间信息。
DDetect块通过卷积层处理输入特征图以预测边界框坐标和类别概率。它使用预定义的 Anchor 框和步长进行推理。检测Head中的偏差根据名义类别频率和图像大小进行初始化。偏差初始化有助于确保检测Head在训练开始时具有合理的预测[8, 14]。
总的来说,RepVGG-GELAN的有效目标检测架构结合了RepVGG的高效和简单性,以及通过结合两种模型优势的GELAN的高级特征聚合和处理能力。RepVGG-GELAN旨在提高在困难检测任务中的性能、效率和准确性。
4 Experiments and Results
第四部分:实验与结果
Data Collection
为了评估所提出的RepVGG-GELAN模型,作者使用了2020年脑肿瘤检测数据集(Br35H)[11],该数据集包含701幅图像,分布在两个文件夹中,分别标记为'TRAIN'和'VAL'。每个文件夹都有2个子文件夹,名为labels和images,其中每个图像的标签存储在labels文件夹中的文本文件中。文件夹dataset-Br35H中的.txt格式标注是从原始JSON格式转换而来的。在这701幅图像中,500幅被指定为训练集,剩余的201幅作为测试集。输入图像的大小设置为。脑图像的标签框进行了归一化,格式为类别,x中心,y中心,宽度和高度。
Implementation details
以下是在Google Colab上开发RepVGG-GELAN模型时所采用的配置和设置。使用的操作系统为Windows 11,CPU为Intel Iris Xe,深度学习框架为PyTorch 1.9.1,GPU为NVIDIA GeForce RTX 3090(通过Google Colab提供),具有24GB的内存容量,通过Google Colab环境使用CUDA Toolkit。模型最多训练150个周期,批次数设置为8,图像分辨率为640 x 640像素,使用随机梯度下降(SGD)优化,动量为0.937,初始学习率为0.01,权重衰减系数为0.0005。前三个周期使用线性预热。权重衰减通过向损失函数中添加惩罚项来防止过拟合,惩罚大权重。马赛克增强应用于每个训练样本,在最后15个周期关闭。Colab环境使得更有效地使用CUDA进行深度学习应用变得更容易。
模型从rcs-gelan-c.yaml文件加载配置,输入通道数('ch')为1,类别数('nc')为1 。卷积层(Conv2d())和批量归一化层(BatchNorm2d())被融合以优化推理速度。每个检测层的输入特征图 'x' 在训练期间被连接并返回。在推理期间,根据需要动态计算 Anchor 框和步长。从连接的输出中提取边界框预测和类别预测。交并比(IoU,Intersection over Union)是交叠区域面积与联合区域面积的比例,其中交叠区域面积是在取零和坐标差的最大值之后,相交区域宽度和高度乘积,联合区域面积是各个边界框面积之和减去交叠区域面积。使用下采样特征定位(DFL)层(根据学习参数调整中心坐标并缩放宽度和高度)改进边界框坐标。边界框预测经过细化以提高定位准确性。边界框坐标根据 Anchor 框和步长进行变换和缩放。类别预测通过sigmoid激活函数。最终输出包括变换后的边界框坐标和sigmoid激活的类别得分的连接预测。
Evaluation metrics
为了评估模型的优缺点,本研究采用FLOPs(浮点运算次数)、mAP50(在IoU阈值为0.5时的平均精度)、mAP50:95(在IoU阈值从0.5到0.95的平均精度)、精确度和召回率作为检测影响的比较衡量指标。以下公式用于在IoU(交并比)值为0.5时确定精确度和召回率:
其中,FP表示错误识别为阳性样本的负样本,FN表示错误识别为负样本的阳性样本,TP表示正确识别为阳性样本的阳性样本数量。FLOPs代表推理过程中所需的浮点运算次数,有助于理解在不同硬件平台上运行模型的计算成本。 mAP@0.5在特定IoU(交并比)阈值0.5下计算脑肿瘤类的平均精度,考虑了该类的精确度-召回率权衡,并计算平均精度。mAP@0.5:0.95是一个更全面的指标,它评估了模型在不同IoU阈值下的表现,为模型在不同程度与真实边界框重叠下定位物体的能力提供了更广泛的理解。
Results
表1:RCS-YOLO、YOLOv8和RepVGG-GELAN的定量结果。最佳结果以粗体显示。
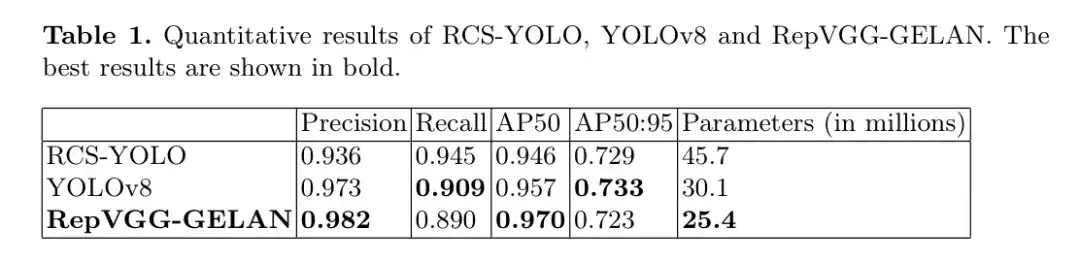
RepVGG-GELAN模型取得了杰出的精确度得分0.982,表明其在正确识别真正阳性案例的同时最小化假阳性方面的卓越能力。尽管与其他模型相比,0.890的召回率稍低,但它仍展示了模型在捕捉实际阳性案例方面的有效性。RepVGG-GELAN获得了令人印象深刻的AP50得分0.970,超过了RCS-YOLO和YOLOv8,证明了其在准确定位与 GT 边界框有足够重叠的目标方面的有效性。这一指标反映了模型在不同IoU阈值下保持高精度的能力,特别是在50%的阈值(在目标检测任务中常用)。
RepVGG-GELAN的AP50:95得分为0.723,展示了在更广泛的IoU阈值范围内的一致性能。虽然与RCS-YOLO和YOLOv8相比略有下降,但这一指标仍反映了模型在预测和 GT 边界框之间不同重叠水平下检测脑肿瘤的鲁棒性。RepVGG-GELAN的一个关键优势是其在模型大小上的效率,仅有2.54亿个参数。这种精简的架构确保了计算效率,同时不牺牲性能,使其非常适合部署。### 消融研究
与GELAN的0.964精确度相比,RepVGG-GELAN实现了更高的精确度0.982。这表明RepVGG-GELAN在正确识别阳性检测方面更为准确,从而减少了假阳性。此外,尽管与GELAN的召回率0.902相比,RepVGG-GELAN的召回率稍低,为0.89,但RepVGG-GELAN实现了更高的mAP50 0.97,表明在不同阈值下具有更好的整体检测性能。通过结合RepVGG和GELAN架构的优势,RepVGG-GELAN实现了更高的精确度和整体检测性能,使其成为一个更有效、更可靠的模型。
5 Conclusion
本研究专注于开发和评估RepVGG-YOLO模型,用于在医学成像数据中检测脑肿瘤。将GELAN架构融入RepVGG增强了模型从医学成像数据中提取相关特征的能力,从而提高了肿瘤检测的准确性。该模型在设计时注重效率,利用结构重参化和高效层聚合等技术来优化资源利用和推理速度。
参考
[1].RepVGG-GELAN: Enhanced GELAN with VGG-STYLE ConvNets for Brain Tumour Detection.
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
LSKA注意力 | 重新思考和设计大卷积核注意力,性能优于ConvNeXt、SWin、RepLKNet以及VAN
CVPR 2023 | TinyMIM:微软亚洲研究院用知识蒸馏改进小型ViT
ICCV2023|涨点神器!目标检测蒸馏学习新方法,浙大、海康威视等提出
ICCV 2023 Oral | 突破性图像融合与分割研究:全时多模态基准与多交互特征学习
HDRUNet | 深圳先进院董超团队提出带降噪与反量化功能的单帧HDR重建算法
南科大提出ORCTrack | 解决DeepSORT等跟踪方法的遮挡问题,即插即用真的很香
1800亿参数,世界顶级开源大模型Falcon官宣!碾压LLaMA 2,性能直逼GPT-4
SAM-Med2D:打破自然图像与医学图像的领域鸿沟,医疗版 SAM 开源了!
GhostSR|针对图像超分的特征冗余,华为诺亚&北大联合提出GhostSR
Meta推出像素级动作追踪模型,简易版在线可玩 | GitHub 1.4K星
CSUNet | 完美缝合Transformer和CNN,性能达到UNet家族的巅峰!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号