

Pytorch中张量的高级选择操作
前言 在某些情况下,我们需要用Pytorch做一些高级的索引/选择,所以在这篇文章中,将介绍这类任务的三种最常见的方法:torch.index_select, torch.gather and torch.take
本文转载自Deephub Imba
作者:Oliver S
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
我们首先从一个2D示例开始,并将选择结果可视化,然后延申到3D和更复杂场景。最后以表格的形式总结了这些函数及其区别。
torch.index_select
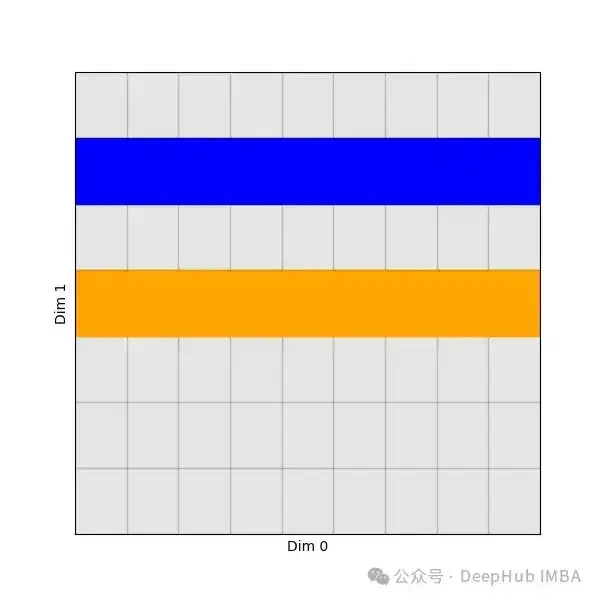
torch.index_select 是 PyTorch 中用于按索引选择张量元素的函数。它的作用是从输入张量中按照给定的索引值,选取对应的元素形成一个新的张量。它沿着一个维度选择元素,同时保持其他维度不变。也就是说:保留所有其他维度的元素,但在索引张量之后的目标维度中选择元素。
num_picks = 2
values = torch.rand((len_dim_0, len_dim_1))
indices = torch.randint(0, len_dim_1, size=(num_picks,))
# [len_dim_0, num_picks]
picked = torch.index_select(values, 1, indices)上面代码将得到的张量形状为[len_dim_0, num_picks]:对于沿维度0的每个元素,我们从维度1中选择了相同的元素。
现在我们使用3D张量,一个形状为[batch_size, num_elements, num_features]的张量:这样我们就有了num_elements元素和num_feature特征,并且是一个批次进行处理的。我们为每个批处理/特性组合选择相同的元素:
import torch
batch_size = 16
num_elements = 64
num_features = 1024
num_picks = 2
values = torch.rand((batch_size, num_elements, num_features))
indices = torch.randint(0, num_elements, size=(num_picks,))
# [batch_size, num_picks, num_features]
picked = torch.index_select(values, 1, indices)下面是如何使用简单的for循环重新实现这个函数的方法:
picked_manual = torch.zeros_like(picked)
for i in range(batch_size):
for j in range(num_picks):
for k in range(num_features):
picked_manual[i, j, k] = values[i, indices[j], k]
assert torch.all(torch.eq(picked, picked_manual))这样对比可以对index_select有一个更深入的了解
torch.gather
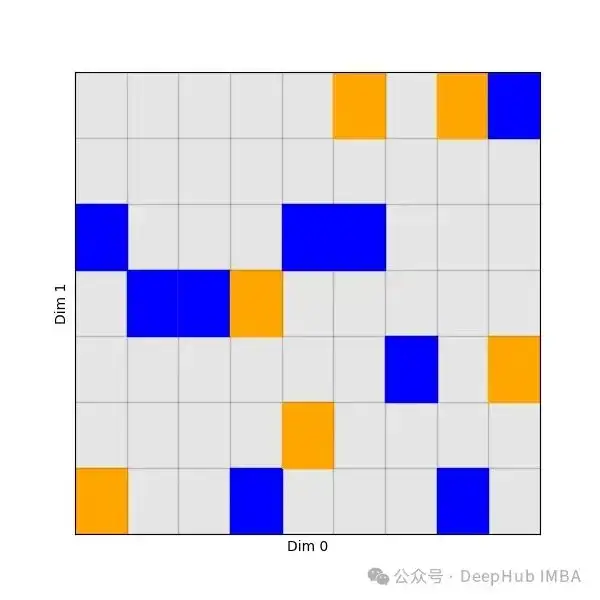
torch.gather 是 PyTorch 中用于按照指定索引从输入张量中收集值的函数。它允许你根据指定的索引从输入张量中取出对应位置的元素,并组成一个新的张量。它的行为类似于index_select,但是现在所需维度中的元素选择依赖于其他维度——也就是说对于每个批次索引,对于每个特征,我们可以从“元素”维度中选择不同的元素——我们将从一个张量作为另一个张量的索引。
num_picks = 2
values = torch.rand((len_dim_0, len_dim_1))
indices = torch.randint(0, len_dim_1, size=(len_dim_0, num_picks))
# [len_dim_0, num_picks]
picked = torch.gather(values, 1, indices)现在的选择不再以直线为特征,而是对于沿着维度0的每个索引,在维度1中选择一个不同的元素:
我们继续扩展为3D的张量,并展示Python代码来重新实现这个选择:
import torch
batch_size = 16
num_elements = 64
num_features = 1024
num_picks = 5
values = torch.rand((batch_size, num_elements, num_features))
indices = torch.randint(0, num_elements, size=(batch_size, num_picks, num_features))
picked = torch.gather(values, 1, indices)
picked_manual = torch.zeros_like(picked)
for i in range(batch_size):
for j in range(num_picks):
for k in range(num_features):
picked_manual[i, j, k] = values[i, indices[i, j, k], k]
assert torch.all(torch.eq(picked, picked_manual))torch.gather 是一个灵活且强大的函数,可以在许多情况下用于数据收集和操作,尤其在需要按照指定索引收集数据的情况下非常有用。
torch.take
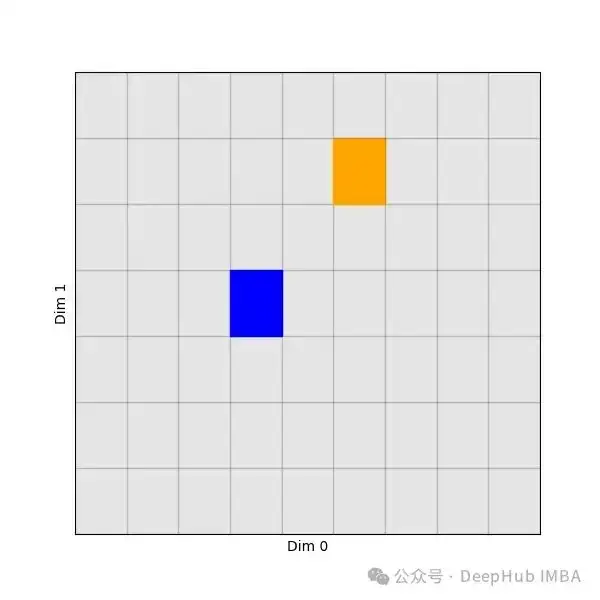
torch.take 是 PyTorch 中用于从输入张量中按照给定索引取值的函数。它类似于 torch.index_select 和 torch.gather,但是更简单,只需要一个索引张量即可。它本质上是将输入张量视为扁平的,然后从这个列表中选择元素。例如:当对形状为[4,5]的输入张量应用take,并选择指标6和19时,我们将获得扁平张量的第6和第19个元素——即来自第2行的第2个元素,以及最后一个元素。
num_picks = 2
values = torch.rand((len_dim_0, len_dim_1))
indices = torch.randint(0, len_dim_0 * len_dim_1, size=(num_picks,))
# [num_picks]
picked = torch.take(values, indices)我们现在只得到两个元素:
3D张量也是一样的这里索引张量可以是任意形状的,只要最大索引不超过张量的总数即可:
import torch
batch_size = 16
num_elements = 64
num_features = 1024
num_picks = (2, 5, 3)
values = torch.rand((batch_size, num_elements, num_features))
indices = torch.randint(0, batch_size * num_elements * num_features, size=num_picks)
# [2, 5, 3]
picked = torch.take(values, indices)
picked_manual = torch.zeros(num_picks)
for i in range(num_picks[0]):
for j in range(num_picks[1]):
for k in range(num_picks[2]):
picked_manual[i, j, k] = values.flatten()[indices[i, j, k]]
assert torch.all(torch.eq(picked, picked_manual))总结
为了总结这篇文章,我们在一个表格中总结了这些函数之间的区别——包含简短的描述和示例形状。样本形状是针对前面提到的3D ML示例量身定制的,并将列出索引张量的必要形状,以及由此产生的输出形状:
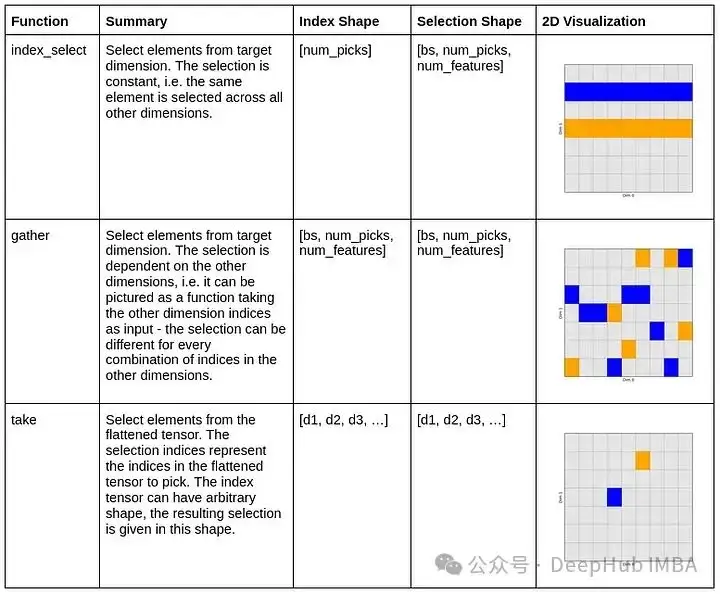
当你想要从一个张量中按照索引选取子集时可以使用torch.index_select ,它通常用于在给定维度上选择元素。适用于较为简单的索引选取操作。
torch.gather适用于根据索引从输入张量中收集元素并形成新张量的情况。可以根据需要在不同维度上进行收集操作。
torch.take适用于一维索引,从输入张量中取出对应索引位置的元素。当只需要按照一维索引取值时,非常方便。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
LSKA注意力 | 重新思考和设计大卷积核注意力,性能优于ConvNeXt、SWin、RepLKNet以及VAN
CVPR 2023 | TinyMIM:微软亚洲研究院用知识蒸馏改进小型ViT
ICCV2023|涨点神器!目标检测蒸馏学习新方法,浙大、海康威视等提出
ICCV 2023 Oral | 突破性图像融合与分割研究:全时多模态基准与多交互特征学习
HDRUNet | 深圳先进院董超团队提出带降噪与反量化功能的单帧HDR重建算法
南科大提出ORCTrack | 解决DeepSORT等跟踪方法的遮挡问题,即插即用真的很香
1800亿参数,世界顶级开源大模型Falcon官宣!碾压LLaMA 2,性能直逼GPT-4
SAM-Med2D:打破自然图像与医学图像的领域鸿沟,医疗版 SAM 开源了!
GhostSR|针对图像超分的特征冗余,华为诺亚&北大联合提出GhostSR
Meta推出像素级动作追踪模型,简易版在线可玩 | GitHub 1.4K星
CSUNet | 完美缝合Transformer和CNN,性能达到UNet家族的巅峰!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
2023-03-05 图像增强新思路:DeepLPF
2023-03-05 LCCL网络:相互指导博弈来提升目标检测精度(附源代码)
2023-03-05 一文带你掌握轻量化模型设计原则和训练技巧!
2021-03-05 CNN结构演变总结(二)轻量化模型