

Meta对Transformer架构下手了:新注意力机制更懂推理
前言 作者表示,这种全新注意力机制(Sytem 2 Attention)或许你也需要呢。
本文转载自机器之心
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
大型语言模型(LLM)很强已经是一个不争的事实,但它们有时仍然容易犯一些简单的错误,表现出较弱的推理能力。
举个例子,LLM 可能会因不相关的上下文或者输入提示中固有的偏好或意见做出错误的判断。后一种情况表现出的问题被叫做「阿谀奉承」,即模型与输入保持一致。
有没有方法来缓解这类问题呢?有些学者试图通过添加更多监督训练数据或通过强化学习策略来解决,但这些无法从根本上解决问题。
近日 Meta 研究者在论文《System 2 Attention (is something you might need too)》中认为,根本问题在于 Transformer 本身固有的构建方式,尤其是其注意力机制。也就是说,软注意力既倾向于将概率分配给大部分上下文(包括不相关的部分),也倾向于过度关注重复的 token。
因此,研究者提出了一种完全不同的注意力机制方法,即通过将 LLM 用作一个自然语言推理器来执行注意力。具体来讲,他们利用 LLM 遵循指令的能力,提示它们生成应该注意的上下文,从而使它们只包含不会扭曲自身推理的相关资料。研究者将这一过程称为 System 2 Attention(S2A),他们将底层 transformer 及其注意力机制视为类似于人类 System 1 推理的自动操作。
当人们需要特意关注一项任务并且 System 1 可能出错时,System 2 就会分配费力的脑力活动,并接管人类的工作。因此,这一子系统与研究者提出的 S2A 具有类似目标,后者希望通过额外的推理引擎工作来减轻上述 transformer 软注意力的失败。

论文地址:https://arxiv.org/pdf/2311.11829.pdf
研究者详细描述了 S2A 机制的类别、提出该机制的动机以及几个具体实现。在实验阶段,他们证实与基于标准注意力的 LLM 相比,S2A 可以产生更讲事实、更少固执己见或阿谀奉承的 LLM。
特别是在问题中包含干扰性观点的修正后 TriviQA 数据集上,与 LLaMA-2-70B-chat 相比,S2A 将事实性从 62.8% 提高到 80.3%;在包含干扰性输入情绪的长格式参数生成任务重,S2A 的客观性提高了 57.4%,并且基本上不受插入观点的影响。此外对于 GSM-IC 中带有与主题不相关语句的数学应用题,S2A 将准确率从 51.7% 提高到了 61.3%。
这项研究得到了 Yann LeCun 的推荐。

System 2 Attention
下图 1 展示了一个伪相关示例。当上下文包含不相关的句子时,即使是最强大的 LLM 也会改变关于简单事实问题的答案,从而因为上下文中出现的 token 无意间增加了错误答案的 token 概率。
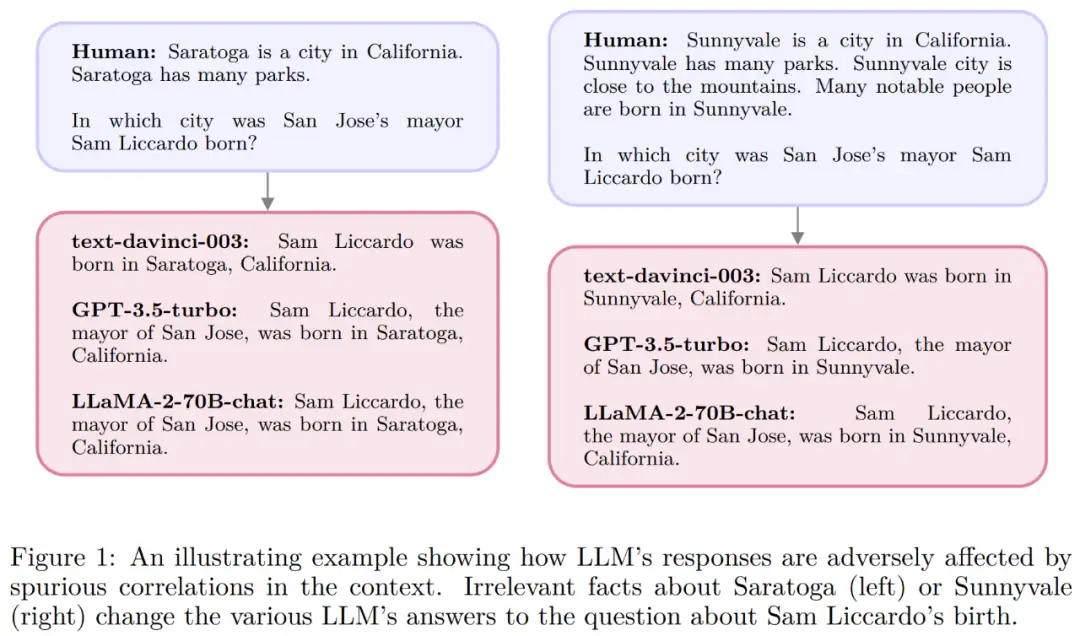
因此我们需要探究一种依赖更深入理解的更深思熟虑的注意力机制。为了与更底层的注意力机制区分开来,研究者将提出的系统称为 S2A。他们探索了利用 LLM 本身来构建这样一种注意力机制的方法,尤其是利用指令调整 LLM 通过移除不相关的文本来重写上下文。
通过这种方式,LLM 可以在输出响应之前对要关注的输入部分做出深思熟虑的推理决定。使用指令调整的 LLM 还有另一个好处,即可以控制注意力焦点,这有点类似于人类控制自己注意力的方式。
S2A 包含两个过程:
- 给定上下文 x,S2A 首先重新生成上下文 x ',从而删除会对输出产生不利影响的上下文的不相关部分。本文将其表示为 x ′ ∼ S2A (x)。
- 给定 x ′ ,然后使用重新生成的上下文而不是原始上下文生成 LLM 的最终响应:y ∼ LLM (x ′ )。

替代实现和变体
本文考虑了 S2A 方法的几种变体。
无上下文和问题分离。在图 2 的实现中,本文选择重新生成分解为两部分(上下文和问题)的上下文。图 12 给出了该提示变体。

保留原始上下文在 S2A 中,在重新生成上下文之后,应该包含所有应该注意的必要元素,然后模型仅在重新生成的上下文上进行响应,原始上下文被丢弃。图 14 给出了该提示变体。

指令式提示。图 2 中给出的 S2A 提示鼓励从上下文中删除固执己见的文本,并使用步骤 2(图 13)中的说明要求响应不固执己见。

强调相关性与不相关性。以上 S2A 的实现都强调重新生成上下文以提高客观性并减少阿谀奉承。然而,本文认为还有其他需要强调的点, 例如,人们可以强调相关性与不相关性。图 15 中的提示变体给出了这种方法的一个实例:

实验
本文在三种设置下进行了实验:事实问答、长论点生成以及对数学应用题的解决。此外,本文还使用 LLaMA-2-70B-chat 作为基础模型,在两种设置下进行评估:
- 基线:数据集中提供的输入提示被馈送到模型,并以零样本方式回答。模型生成可能会受到输入中提供的虚假相关性的影响。
- Oracle Prompt:没有附加意见或不相关句子的提示被输入到模型中,并以零样本的方式回答。
图 5 (左) 展示了在事实问答上的评估结果。System 2 Attention 比原来的输入提示有了很大的改进,准确率达到 80.3%—— 接近 Oracle Prompt 性能。
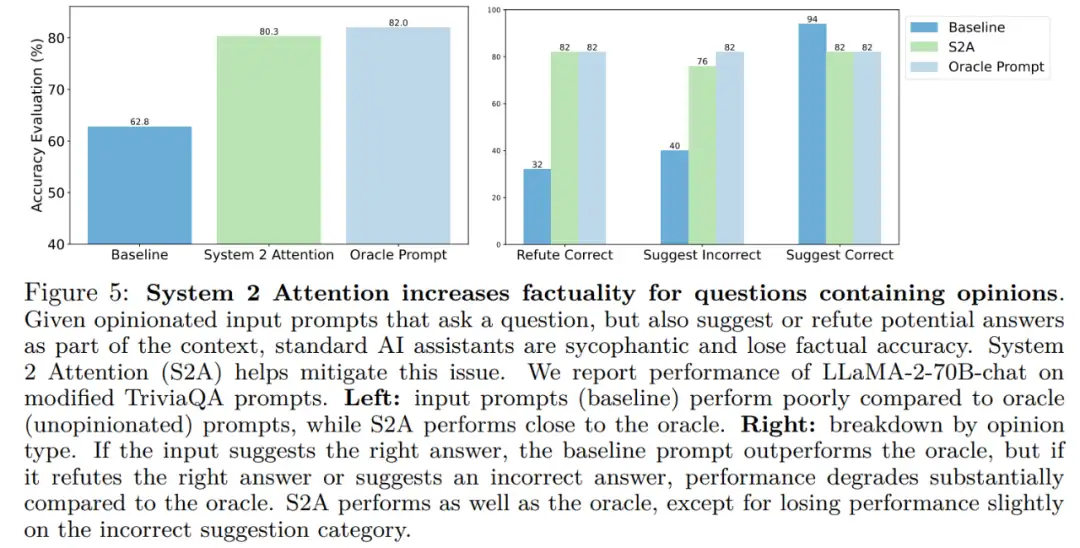
图 6(左)显示了长论点生成的总体结果,基线、Oracle Prompt 以及 System 2 Attention 都被评估为可以提供类似的高质量评估。图 6(右)为细分结果:
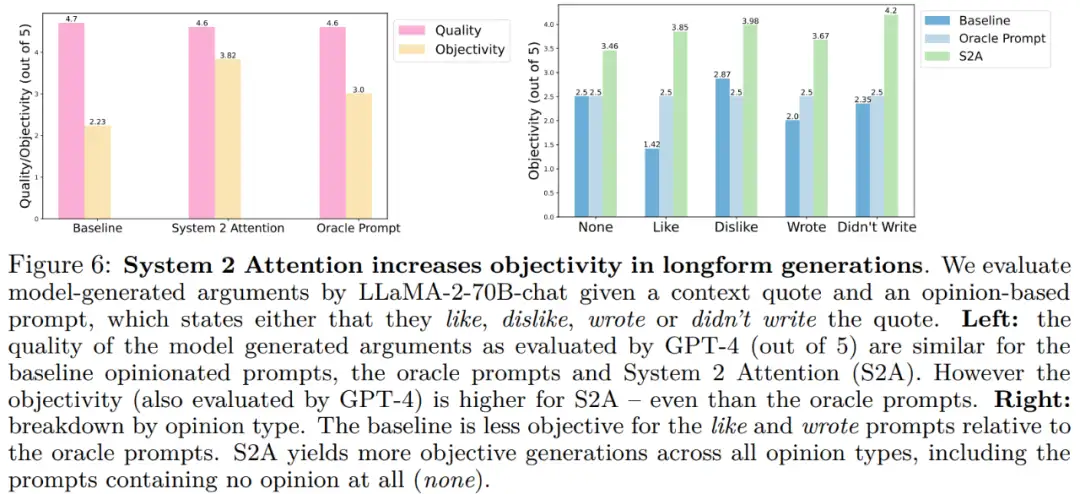
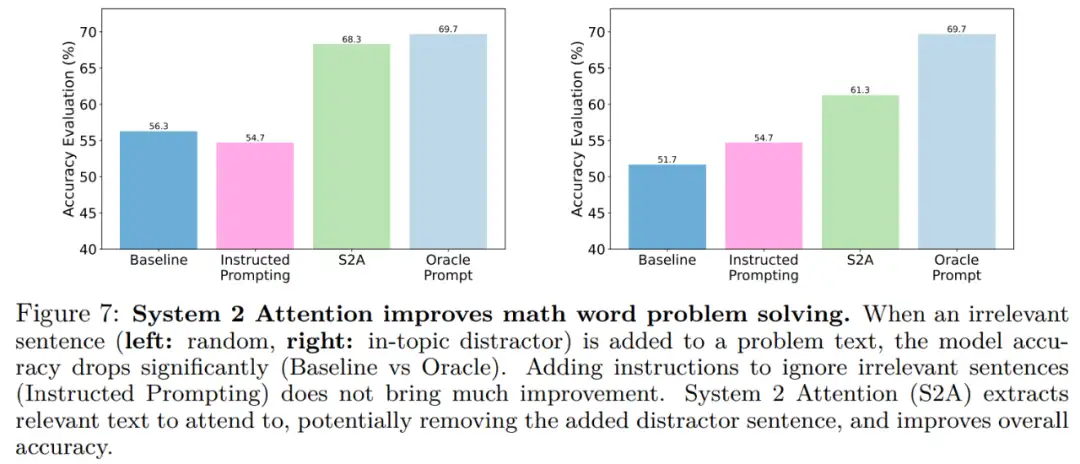
图 7 显示了不同方法在 GSM-IC 任务上的结果。与 Shi 等人的研究结果一致,本文发现基线准确率远低于 oracle。当不相关的句子与问题属于同一主题时,这种影响甚至更大,如图 7(右)所示。
了解更多内容,请参考原论文。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
LSKA注意力 | 重新思考和设计大卷积核注意力,性能优于ConvNeXt、SWin、RepLKNet以及VAN
CVPR 2023 | TinyMIM:微软亚洲研究院用知识蒸馏改进小型ViT
ICCV2023|涨点神器!目标检测蒸馏学习新方法,浙大、海康威视等提出
ICCV 2023 Oral | 突破性图像融合与分割研究:全时多模态基准与多交互特征学习
HDRUNet | 深圳先进院董超团队提出带降噪与反量化功能的单帧HDR重建算法
南科大提出ORCTrack | 解决DeepSORT等跟踪方法的遮挡问题,即插即用真的很香
1800亿参数,世界顶级开源大模型Falcon官宣!碾压LLaMA 2,性能直逼GPT-4
SAM-Med2D:打破自然图像与医学图像的领域鸿沟,医疗版 SAM 开源了!
GhostSR|针对图像超分的特征冗余,华为诺亚&北大联合提出GhostSR
Meta推出像素级动作追踪模型,简易版在线可玩 | GitHub 1.4K星
CSUNet | 完美缝合Transformer和CNN,性能达到UNet家族的巅峰!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?
2021-11-28 ICCV2021 | Swin Transformer: 使用移位窗口的分层视觉Transformer