全新注意力算法PagedAttention:LLM吞吐量提高2-4倍,模型越大效果越好
前言 吞吐量上不去有可能是内存背锅!无需修改模型架构,减少内存浪费就能提高吞吐量!
本文转载自新智元
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
虽然大型语言模型(LLM)的性能表现足够惊艳,但每次接收用户请求时都需要耗费大量显存和计算资源,一旦请求数量超出预期,就极有可能面临ChatGPT刚发布时的宕机、排队、高延迟等窘境。

想要打造一个高吞吐量的LLM服务,就需要模型在一个批次内处理尽可能多的请求,不过现有的系统大多在每次处理请求时申请大量的key-value(KV)缓存,如果管理效率不高,大量内存都会在碎片和冗余复制中被浪费掉,限制了batch size的增长。

最近,来自加州大学伯克利分校、斯坦福大学、加州大学圣迭戈分校的研究人员基于操作系统中经典的虚拟内存和分页技术,提出了一个新的注意力算法PagedAttention,并打造了一个LLM服务系统vLLM

论文链接:https://arxiv.org/pdf/2309.06180.pdf
开源链接:https://github.com/vllm-project/vllm
vLLM在KV缓存上实现了几乎零浪费,并且可以在「请求内部」和「请求之间」灵活共享KV高速缓存,进一步减少了内存的使用量。
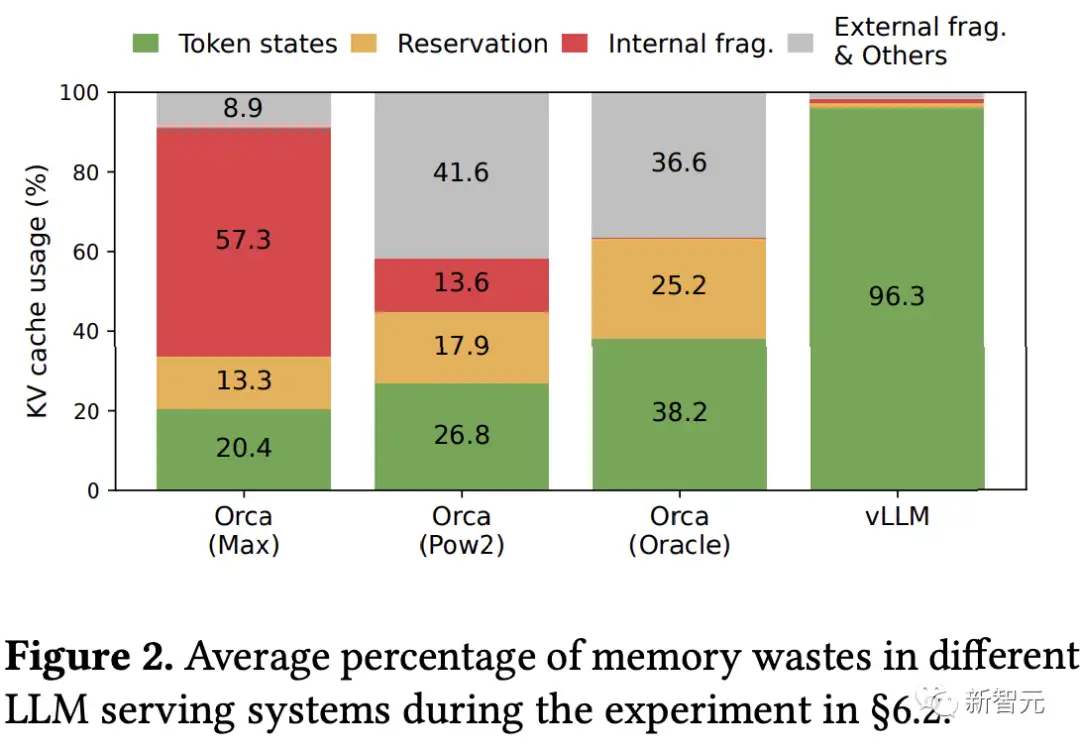
评估结果表明,vLLM可以将常用的LLM吞吐量提高了2-4倍 ,在延迟水平上与最先进的系统(如FasterTransformer和Orca)相当,并且在更长序列、更大模型和更复杂的解码算法时,提升更明显。
PagedAttention
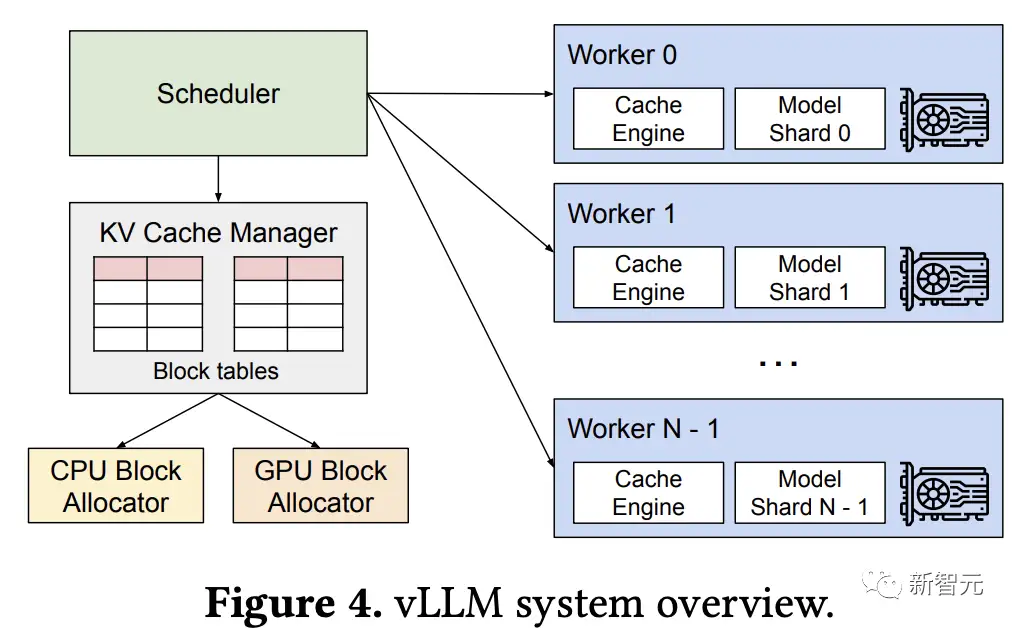
为了解决注意力机制的内存管理问题,研究人员开发了一种全新的注意力算法PagedAttention,并构建了一个LLM服务引擎vLLM,采用集中式调度器来协调分布式GPU工作线程的执行。
1. 算法
受操作系统中分页(paging)算法启发,PagedAttention将序列中KV缓存划分为KV块,其中每个块包含固定数量tokens的键(K)和值(V)向量,从而将注意力计算转换为块级运算:
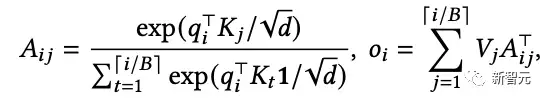
在注意力计算期间,PagedAttention内核分别识别和获取不同的KV块,比如下面的例子中,键和值向量分布在三个块上,并且三个块在物理内存上是不连续的,然后将查询向量与块中的键向量相乘得到部分注意力得分,再乘以块中的值向量得到最终注意力输出。
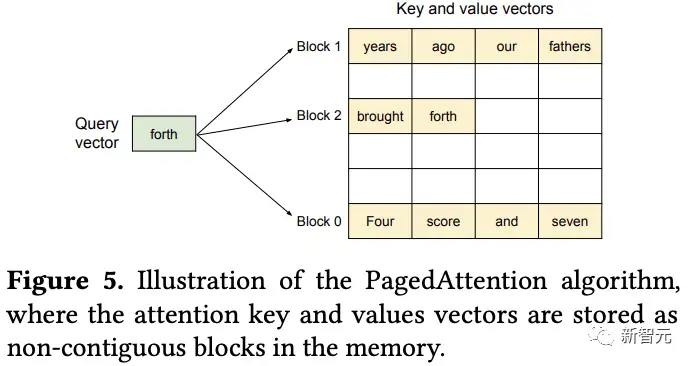
这种设计使得KV块存储在非连续物理内存中,从而让vLLM中的分页内存管理更加灵活。
2. KV缓存管理器
操作系统会将内存划分为多个固定大小的页,并将用户程序的逻辑页映射到物理页,连续的逻辑页可以对应于非连续的物理内存页,所以用户在访问内存时看起来就像连续的一样。
此外,物理内存空间不需要提前完全预留,使操作系统能够根据需求动态分配物理页。
通过PageAttention划分出的KV块,vLLM利用虚拟内存机制将KV缓存表示为一系列逻辑KV块,并在生成新token及KV缓存时,从左到右进行填充;最后一个KV块的未填充位置预留给后续生成操作。
KV块管理器还负责维护块表(block table),即每个请求的逻辑和物理KV块之间的映射。
将逻辑和物理KV块分离使得vLLM能够动态地增长KV高速缓存存储器,而无需预先将其保留给所有位置,消除了现有系统中的大多数内存浪费。
3. 解码
从下面的例子中可以看出vLLM如何在单个输入序列的解码过程中执行PagedAttention并管理内存。
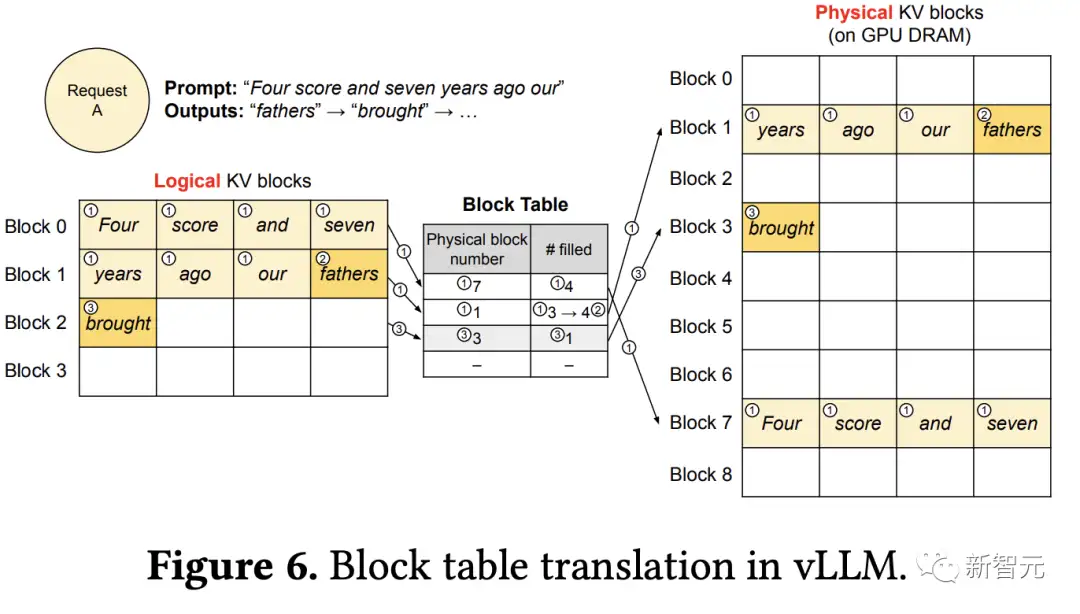
① 与操作系统的虚拟内存一样,vLLM最初不需要为最大可能生成的序列长度保留内存,只保留必要的KV块,以容纳在即时计算期间生成的KV缓存。
提示词中包含7个tokens,所以vLLM将前两个逻辑KV块(0和1)映射到2个物理KV块(7和1);在预填充(prefill)步骤中,vLLM使用自注意算法生成提示和首个输出token的KV缓存;然后将前4个token的KV缓存存储在逻辑块0中,后面3个token存储在逻辑块1中;剩余的slot被保留用于后续自回归生成。
② 在首个自回归解码步骤中,vLLM在物理块7和1上使用PagedAttention算法生成新token
由于最后一个逻辑块中仍有一个slot可用,所以将新生成的KV缓存存储在该slot,更新块表的#filled记录。
③ 在第二次解码步骤中,当最后一个逻辑块已满时,vLLM将新生成的KV缓存存储在新的逻辑块中,为其分配一个新的物理块(物理块3),并映射存储在块表中。
在LLM的计算过程中,vLLM使用PagedAttention内核访问以前以逻辑KV块形式存储的KV缓存,并将新生成的KV缓存保存到物理KV块中。
在一个KV块(块大小>1)中存储多个token使PagedAttention内核能够跨更多位置并行处理KV缓存,从而提高硬件利用率并减少延迟,但较大的块大小也会增加内存碎片。
随着生成越来越多的token及其KV缓存,vLLM会动态地将新的物理块分配给逻辑块,从左到右地填充所有块,并且只有当所有先前的块都满时才分配新的物理块,即请求的所有内存浪费限制在一个块内,可以有效地利用所有内存,从而允许更多的请求放入内存进行批处理,提高了吞吐量;一旦请求完成生成,就可以释放其KV块来存储其他请求的KV缓存。
4. 通用解码
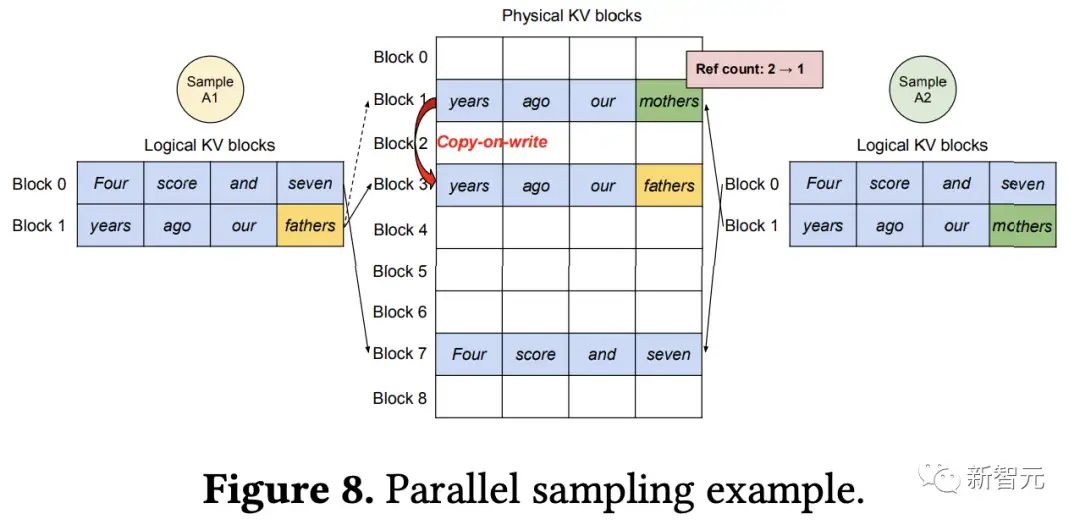
除了贪婪解码和采样,支持单个用户提示输入生成单个输出序列等基本场景外,该算法还可以支持更复杂的解码场景,如并行采样(Parallel sampling)、集束搜索(Beam Search)、共享前缀等。
5. 调度和抢占(Scheduling and Preemption)
当请求流量超过系统容量时,vLLM必须对请求子集进行优先级排序,具体采用「先来先服务」(FCFS)的调度策略,可以确保公平性并防止饥饿。
不过LLM的输入提示在长度上可能变化很大,并且输出长度是先验未知的,具体取决于输入提示和模型;随着请求及其输出数量的增长,vLLM可能会耗尽GPU的物理块来存储新生成的KV缓存。
交换(Swapping)是大多数虚拟内存算法使用的经典技术,将被释放的页复制到磁盘上的交换空间。
除了GPU块分配器之外,vLLM还包括CPU块分配器,以管理交换到CPU RAM的物理块;当vLLM耗尽新令牌的空闲物理块时,会选择一组序列来释放KV缓存并将其传输到CPU。
在这种设计中,交换到CPU RAM的块数永远不会超过GPU RAM中的物理块总数,因此CPU RAM上的交换空间受到分配给KV缓存的GPU内存的限制。
重新计算(Recomputation),当被抢占的序列被重新调度时,可以简单地重新计算KV缓存,其延迟可以显著低于原始延迟,因为解码时生成的token可以与原始用户提示连接起来作为新的提示,所有位置的KV缓存可以在一次提示阶段迭代中生成。
交换和重计算的性能取决于CPU、RAM和GPU内存之间的带宽以及GPU的计算能力。
6. 分布式执行(Distributed Execution)
vLLM支持Megatron-LM风格的张量模型并行策略,遵循SPMD(单程序多数据)执行调度,其中线性层被划分以执行逐块矩阵乘法,并且GPU通过allreduce操作不断同步中间结果。
具体来说,注意算子在注意头维度上被分割,每个SPMD过程负责多头注意中的注意头子集,不过每个模型分片仍然处理相同的输入token集合,即在同一位置需要KV缓存。
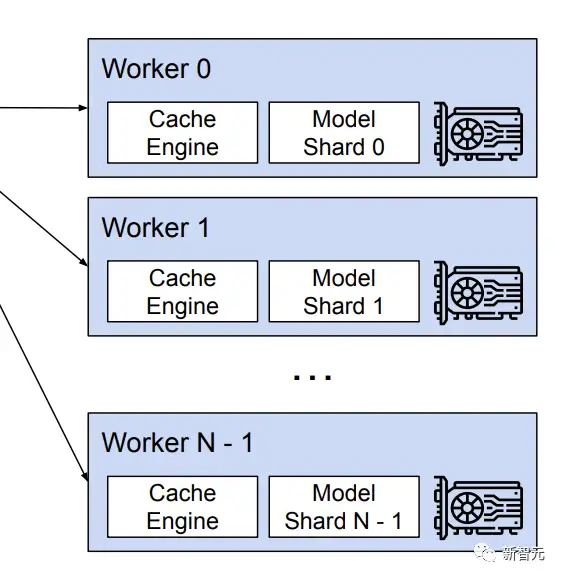
不同的GPU worker共享管理器,以及从逻辑块到物理块的映射,使用调度程序为每个输入请求提供的物理块来执行模型;尽管每个GPU工作线程具有相同的物理块id,但是一个工作线程仅为其相应的注意头存储KV缓存的一部分。
在每一步中,调度程序首先为批处理中的每个请求准备带有输入token id的消息,以及每个请求的块表;
然后调度程序将该控制消息广播给GPU worker,使用输入token id执行模型;在注意力层,根据控制消息中的块表读取KV缓存;在执行过程中,将中间结果与all-reduce通信原语同步,而无需调度程序的协调。
最后,GPU worker将该迭代的采样token发送回调度器。
评估结果
基础采样
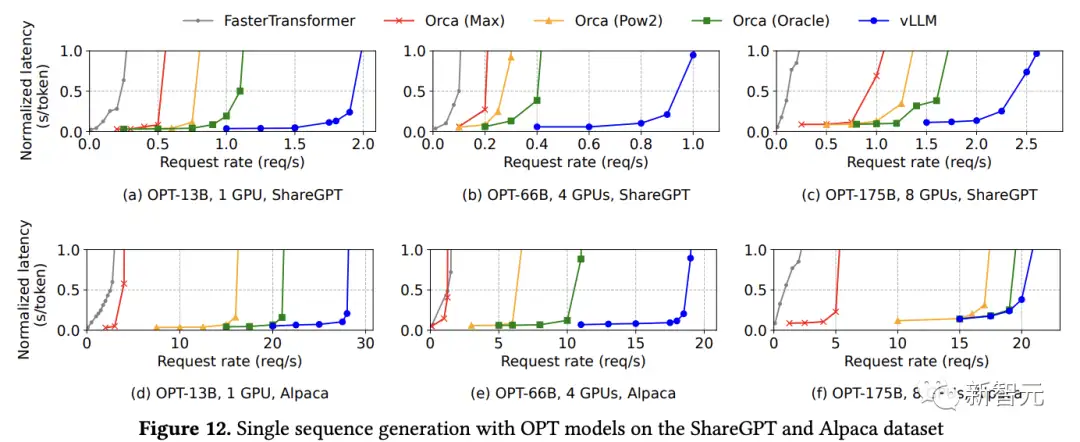
在ShareGPT数据集上,随着请求速率的增加,延迟最初缓慢增加,之后会突然激增,可能是因为当请求速率超过服务系统的容量时,导致队列长度无限增长。
vLLM可以承受比Orca高1.7倍-2.7倍的请求速率,比Orca(Max)高2.7倍-8倍的请求速率,同时保持相似的延迟,因为PagedAttention可以有效地管理内存使用,从而能够比Orca在一个批次内处理更多的请求。
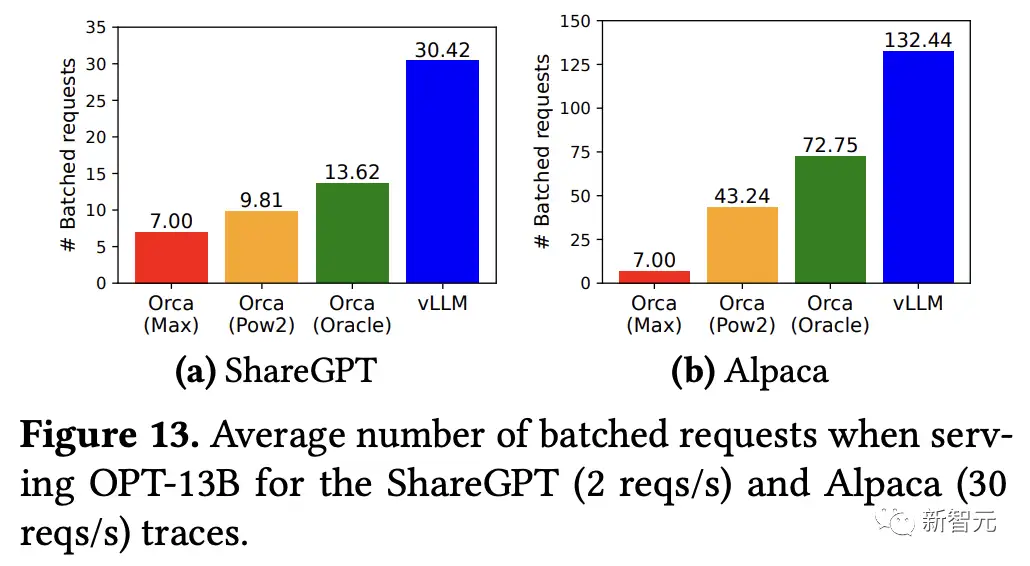
对于OPT-13B模型,vLLM同时处理的请求比Orca多2.2倍,比Orca(Max)多4.3倍。
与FasterTransformer相比,vLLM实现高达22倍的请求速率,可能是因为没有利用细粒度的调度机制,并且与Orca(Max)一样在内存管理方面很低效。
多序列
在并行采样中,请求中的所有并行序列可以共享提示符的KV缓存,随着采样序列数量的增加,vLLM实现了比Orca基线更大的提升。
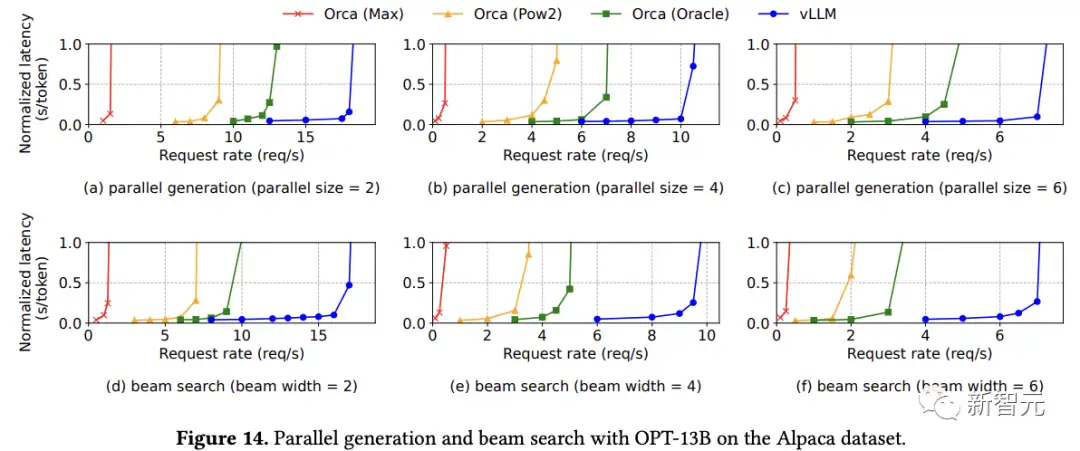
由于集束搜索中共享内容更多,vLLM展示出了更大的性能优势。
在OPT-13B和Alpaca数据集上,vLLM相对于Orca(Oracle)的改进从基本采样的1.3倍增加到宽度为6的集束搜索的2.3倍。
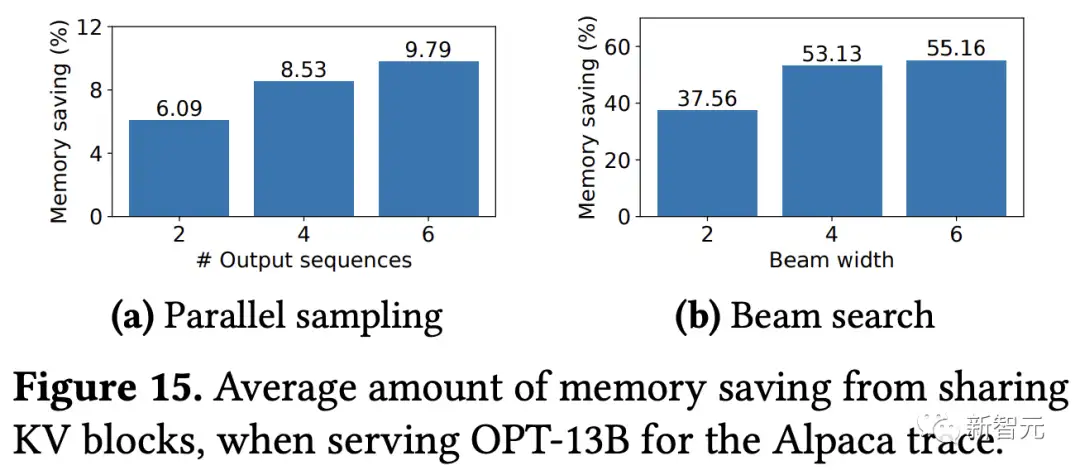
通过计算共享保存的块数除以未共享的总块数计算的存储器节省量,结果显示并行采样节省了6.1%-9.8%的内存,集束搜索节省了37.6%-55.2%的内存。
在使用ShareGPT数据集的相同实验中,可以看到并行采样节省了16.2%-30.5%的内存,集束搜索节省了44.3%-66.3%的内存。
参考资料:https://arxiv.org/abs/2309.06180
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
LSKA注意力 | 重新思考和设计大卷积核注意力,性能优于ConvNeXt、SWin、RepLKNet以及VAN
CVPR 2023 | TinyMIM:微软亚洲研究院用知识蒸馏改进小型ViT
ICCV2023|涨点神器!目标检测蒸馏学习新方法,浙大、海康威视等提出
ICCV 2023 Oral | 突破性图像融合与分割研究:全时多模态基准与多交互特征学习
HDRUNet | 深圳先进院董超团队提出带降噪与反量化功能的单帧HDR重建算法
南科大提出ORCTrack | 解决DeepSORT等跟踪方法的遮挡问题,即插即用真的很香
1800亿参数,世界顶级开源大模型Falcon官宣!碾压LLaMA 2,性能直逼GPT-4
SAM-Med2D:打破自然图像与医学图像的领域鸿沟,医疗版 SAM 开源了!
GhostSR|针对图像超分的特征冗余,华为诺亚&北大联合提出GhostSR
Meta推出像素级动作追踪模型,简易版在线可玩 | GitHub 1.4K星
CSUNet | 完美缝合Transformer和CNN,性能达到UNet家族的巅峰!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号