ICCV 2023 | 超越SAM!EntitySeg:更少的数据,更高的分割质量!
前言 在本文中,High-Quality Entity Segmentation对分割问题进行了全新的探索。
本文转载自CVer
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!

稠密图像分割问题一直在计算机视觉领域中备受关注。无论是在Adobe旗下的Photoshop等重要产品中,还是其他实际应用场景中,分割模型的泛化和精度都被赋予了极高的期望。对于这些分割模型来说,需要在不同的图像领域、新的物体类别以及各种图像分辨率和质量下都能够保持鲁棒性。为了解决这个问题,早在SAM[6]模型一年之前,一种不考虑类别的实体分割任务[1]被提出,作为评估模型泛化能力的一种统一标准。

在本文中,High-Quality Entity Segmentation对分割问题进行了全新的探索,从以下三个方面取得了显著的改进:
- 更优的分割质量
正如上图所示,EntitySeg在数值指标和视觉表现方面都相对于SAM有更大的优势。令人惊讶的是,这种优势是基于仅占训练数据量千分之一的数据训练取得的。 - 更少的高质量数据需求
相较于SAM使用的千万级别的训练数据集,EntitySeg数据集仅含有33,227张图像。尽管数据量相差千倍,但EntitySeg却取得了可媲美的性能,这要归功于其标注质量,为模型提供了更高质量的数据支持。 - 更一致的输出细粒度(基于实体标准)
从输出的分割图中,我们可以清晰地看到SAM输出了不同粒度的结果,包括细节、部分和整体(如瓶子的盖子、商标、瓶身)。然而,由于SAM需要对不同部分的人工干预处理,这对于自动化输出分割的应用而言并不理想。相比之下,EntitySeg的输出在粒度上更加一致,并且能够输出类别标签,对于后续任务更加友好。
在阐述了这项工作对稠密分割技术的新突破后,接下来的内容中介绍EntitySeg数据集的特点以及提出的算法CropFormer。

主页:http://luqi.info/entityv2.github.io/论文:https://arxiv.org/abs/2211.05776代码(已开源):https://github.com/qqlu/Entity/blob/main/Entityv2/README.md
根据Marr计算机视觉教科书中的理论,人类的识别系统是无类别的。即使对于一些不熟悉的实体,我们也能够根据相似性进行识别。因此,不考虑类别的实体分割更贴近人类识别系统,不仅可以作为一种更基础的任务,还可以辅助于带有类别分割任务[2]、开放词汇分割任务[3]甚至图像编辑任务[4]。与全景分割任务相比,实体分割将“thing”和“stuff”这两个大类进行了统一,更加符合人类最基本的识别方式。
EntitySeg数据集
由于缺乏现有的实体分割数据,作者在其工作[1]使用了现有的COCO、ADE20K以及Cityscapes全景分割数据集验证了实体任务下模型的泛化能力。然而,这些数据本身是在有类别标签的体系下标注的(先建立一个类别库,在图片中搜寻相关的类别进行定位标注),这种标注过程并不符合实体分割任务的初衷——图像中每一个区域均是有效的,哪怕这些区域无法用言语来形容或者被Blur掉,都应该被定位标注。此外,受限于提出年代的设备,COCO等数据集的图片域以及图片分辨率也相对单一。因此基于现有数据集下训练出的实体分割模型也并不能很好地体现实体分割任务所带来的泛化能力。最后,原作者团队在提出实体分割任务的概念后进一步贡献了高质量细粒度实体分割数据集EntitySeg及其对应方法。EntitySeg数据集是由Adobe公司19万美元赞助标注完成,已经开源贡献给学术界使用。项目主页:http://luqi.info/entityv2.github.io/
EntitySeg数据集有三个重要特性:
- 数据集汇集了来自公开数据集和学术网络的33,227张图片。这些图片涵盖了不同的领域,包括风景、室内外场景、卡通画、简笔画、电脑游戏和遥感场景等。
- 标注过程在无类别限制下进行的掩膜标注,并且可以覆盖整幅图像。
- 图片分辨率更高,标注更精细。如上图所示,即使相比COCO和ADE20K数据集的原始低分辨率图片及其标注,EntitySeg的实体标注更全且更精细。
最后,为了让EntitySeg数据集更好地服务于学术界,11580张图片在标注实体掩膜之后,以开放标签的形式共标注了643个类别。EntitySeg、COCO以及ADE20K数据集的统计特性对比如下:

通过和COCO以及ADE20K的数据对比,可以看出EntitySeg数据集图片分辨率更高(平均图片尺寸2700)、实体数量更多(每张图平均18.1个实体)、掩膜标注更为复杂(实体平均复杂度0.719)。极限情况下,EntitySeg的图片尺寸可达到10000以上。
与SAM数据集不同,EntitySeg更加强调小而精,试图做到对图片中的每个实体得到最为精细的边缘标注。此外, EntitySeg保留了图片和对应标注的原始尺寸,更有利于高分辨率分割模型的学术探索。
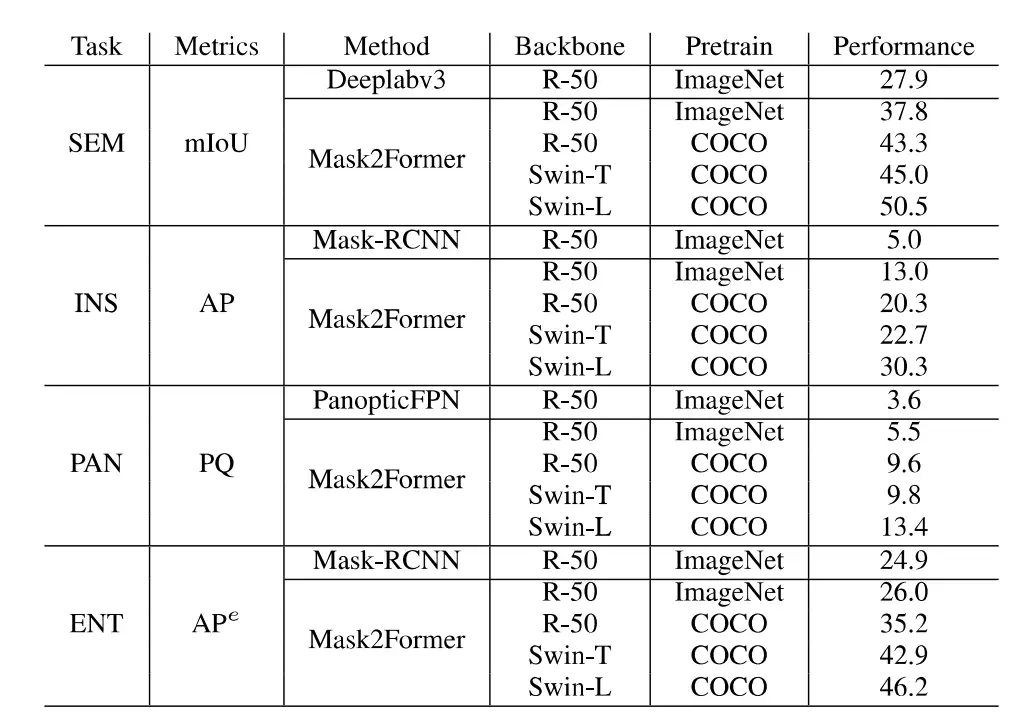
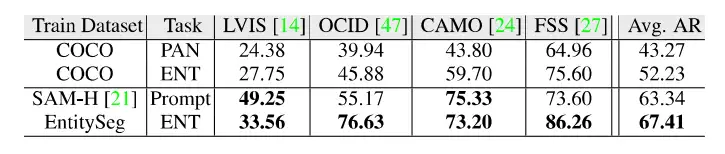
基于EntitySeg数据集,作者衡量了现有分割模型在不同分割任务(无类别实体分割,语义分割,实例分割以及全景分割)的性能以及和SAM在zero-shot实体级别的分割能力。
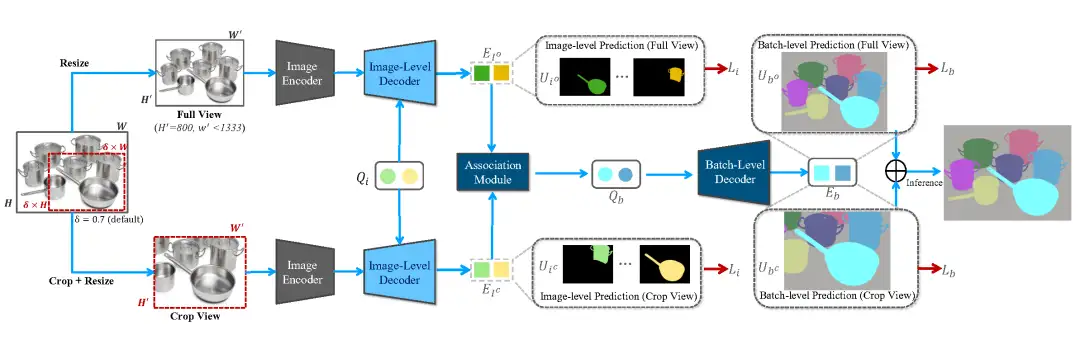
CropFormer算法框架
除此之外,高分辨率图片和精细化掩膜给分割任务带来了新的挑战。为了节省硬件内存需求,分割模型需要压缩高分辨率图片及标注进行训练和测试进而导致分割质量的降低。为了解决这一问题,作者提出了CropFormer框架来解决高分辨率图片分割问题。CropFormer受到Video-Mask2Former[5]的启发, 利用一组query连结压缩为低分辨率的全图和保持高分辨率的裁剪图的相同实体。因此,CropFormer可以同时保证图片全局和区域细节属性。CropFormer是根据EntitySeg高质量数据集的特点提出的针对高分辨率图像的实例/实体分割任务的baseline方法,更加迎合当前时代图片质量的需求。
最后在补充材料中,作者展示了更多的EntitySeg数据集以及CropFormer的可视化结果。下图为更多数据标注展示:

下图为CropFormer模型测试结果:

[1] Open-World Entity Segmentation. TAPMI 2022.
[2] CA-SSL: Class-agnostic Semi-Supervised Learning for Detection and Segmentation. ECCV 2022.
[3] Open-Vocabulary Panoptic Segmentation with MaskCLIP. ICML 2023.
[4] SceneComposer: Any-Level Semantic Image Synthesis. CVPR 2023.
[5] Masked-attention Mask Transformer for Universal Image Segmentation. CVPR 2022.
[6] Segment Anything. ICCV 2023.
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
LSKA注意力 | 重新思考和设计大卷积核注意力,性能优于ConvNeXt、SWin、RepLKNet以及VAN
CVPR 2023 | TinyMIM:微软亚洲研究院用知识蒸馏改进小型ViT
ICCV2023|涨点神器!目标检测蒸馏学习新方法,浙大、海康威视等提出
ICCV 2023 Oral | 突破性图像融合与分割研究:全时多模态基准与多交互特征学习
HDRUNet | 深圳先进院董超团队提出带降噪与反量化功能的单帧HDR重建算法
南科大提出ORCTrack | 解决DeepSORT等跟踪方法的遮挡问题,即插即用真的很香
1800亿参数,世界顶级开源大模型Falcon官宣!碾压LLaMA 2,性能直逼GPT-4
SAM-Med2D:打破自然图像与医学图像的领域鸿沟,医疗版 SAM 开源了!
GhostSR|针对图像超分的特征冗余,华为诺亚&北大联合提出GhostSR
Meta推出像素级动作追踪模型,简易版在线可玩 | GitHub 1.4K星
CSUNet | 完美缝合Transformer和CNN,性能达到UNet家族的巅峰!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号