WideNet:让网络更宽而不是更深
前言 本文介绍了新加坡国立大学在2022 aaai发布的一篇论文。WideNet是一种参数有效的框架,它的方向是更宽而不是更深。通过混合专家(MoE)代替前馈网络(FFN),使模型沿宽度缩放。使用单独LN用于转换各种语义表示,而不是共享权重。
本文转载自DeepHub IMBA
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
混合专家(MoEs)
条件计算
对于每个输入,只有一部分隐藏的表示被发送到选定的专家中进行处理。与MoE一样,给定E个可训练的专家,输入用x表示,MoE模型的输出可表示为:
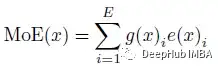
其中e(.)i是第i位专家的非线性变换。g(.)i是可训练路由器g(.)输出的第i个元素。当g(.)为稀疏向量时,只会激活部分专家。论文中通过MoE和提出的WideNet,每个专家都是一个FFN层。
路由
为了保证稀疏路由g(.),使用TopK()选择排名靠前的专家:
这里的f(.)为路由线性变换。ε为高斯噪声。当K<<E时,g(x)的大多数元素为零。
平衡加载
MoE的问题就是要确保每个专家模块都要处理基本相同数量的令牌,所以优化MoE需要解决下面2个主要问题:
1、把太多令牌分配给一个专家
2、单个专家收到的令牌太少
也就是说要保证将令牌平均分配到各个专家模块。
要解决第一个问题,可以增加缓冲区容量B。对于每个专家最多只保留B个令牌。如果超过B=CKNL,则丢弃所有剩余的令牌。
但是这个方法也只是解决了太多的问题,仍然不能保证所有的专家都能获得足够的令牌进行训练。所以论文采用了 Switch Transformer的方法,采用了一个负载平衡的并且可微的损失函数。
下面这个辅助损失会加到训练时的模型总损失中:
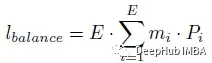
m是向量。第i个元素是分配给专家i的令牌的分数.mi的计算如下:
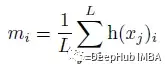
其中h(.)是TopK选择的索引向量。H (xj)i是H (xj)的第i个元素。
Pi是softmax后路由线性变换的第i个元素。
通过以上的损失函数实现均衡分配。当lbalance最小时,m和P都接近均匀分布。
WideNet
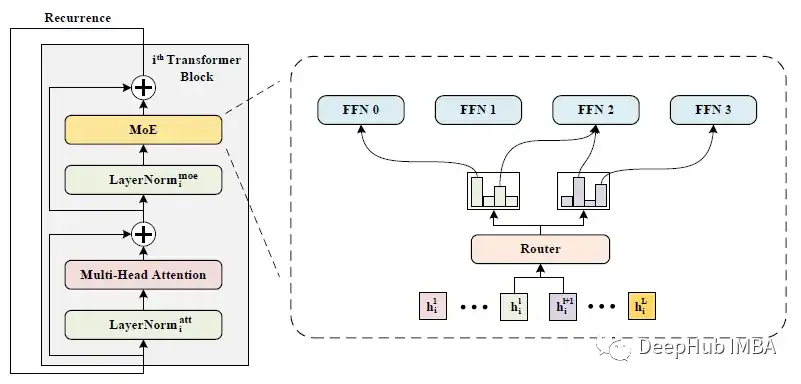
在不同的Transformer块中使用相同的路由和专家
WideNet采用跨Transformer块的参数共享来提高参数效率,采用MoE层来提高模型容量。WideNet在不同的Transformer块中使用相同的路由器和专家。
LN
目前来说,例如ALBERT使用的是参数共享的方法,在Transformer块之间共享所有权重。
而WideNet中只有多头注意层和FFN(或MoE)层是共享的,这意味着LN的可训练参数在块之间是不同的,也就是说每一层的LN的权重都不一样。
把论文中的的第i个Transformer块可以写成:
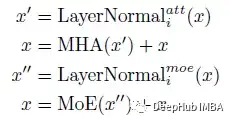
这里的LayerNormal(.)为:
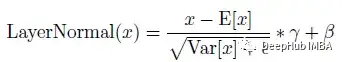
γ和β是可训练向量。LN只需要这两个小向量。
损失函数
尽管路由的可训练参数在每个Transformer块中被重用,但由于输入表示的不同,分配也会有所不同。所以给定T次具有相同可训练参数的路由操作,使用以下损失进行优化:
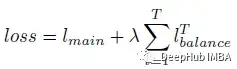
其中λ=0.01用作超参数,以确保均衡分配。lmain是Transformer的主要目标。例如,在监督图像分类中,主要是交叉熵损失。
结果(CV & NLP)
ImageNet-1K (CV)
在ImageNet-1K上,WideNet-H实现了最佳性能,显著优于ViT和ViT- moe模型。
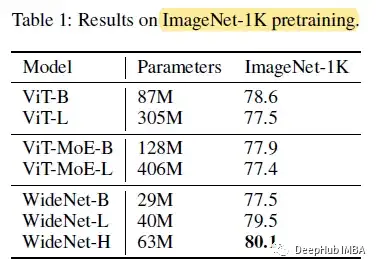
与最强基线相比,WideNet-H在可训练参数较少的情况下优于vitb 1.5%。即使对于最小的模型WideNet-B,它仍然可以与可训练参数减少4倍以上的viti - l和viti - moe - b取得相当的性能。当扩大到WideNet-L时,它已经超过了所有基线,其中vitb的可训练参数为一半,vitl的参数为0.13倍。
GLUE (NLP)
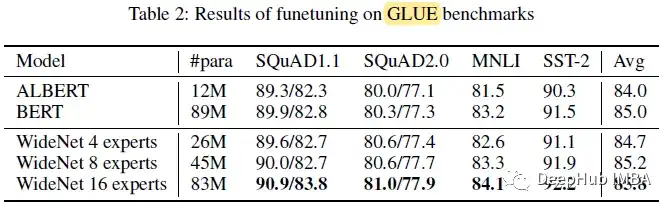
有了更多的专家,WideNet的表现远远超过ALBERT。
拥有4位专家的WideNet平均比ALBERT高出1.2%。当将专家数量E增加到16时,通过分解嵌入参数化,获得的可训练参数略低于BERT, WideNet在所有四个下游任务上的表现也优于BERT,这显示了更宽而不是更深的参数效率和有效性。
消融研究
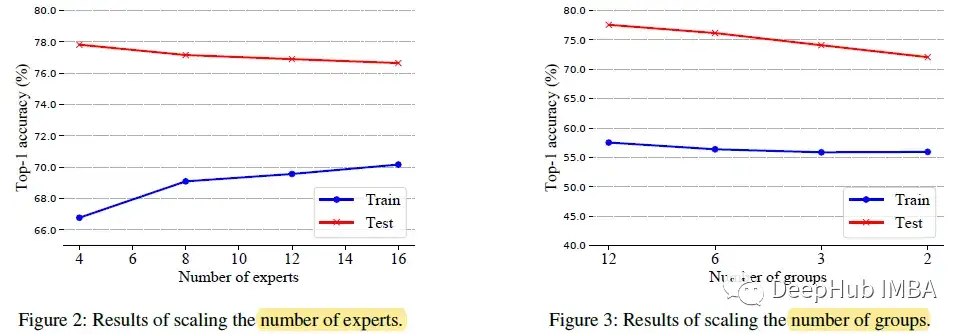
专家越多(可训练参数)导致过拟合,尽管专家越多意味着建模能力越强。更少的路由操作时,会有明显的性能下降。
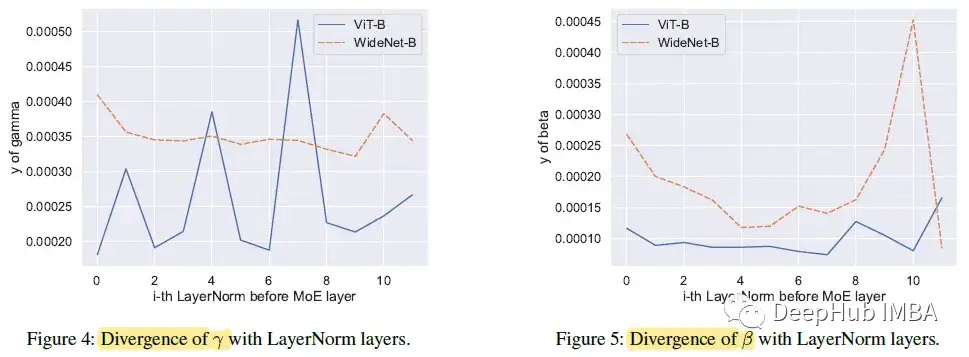
对于可训练向量的第i个元素或第j个块,计算该元素与其他块中所有向量的所有其他元素之间的距离:
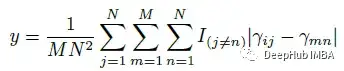
式中N为Transformer块的个数,M为向量γ或β的维数。所以WideNet中的γ和β都比ViT中的y大,这意味着MoE比ViT接受更多样化的输入。
这样的结果证明,单独的LN层可以帮助建立具有共享的大型可训练矩阵(如MoE)的各种语义模型。
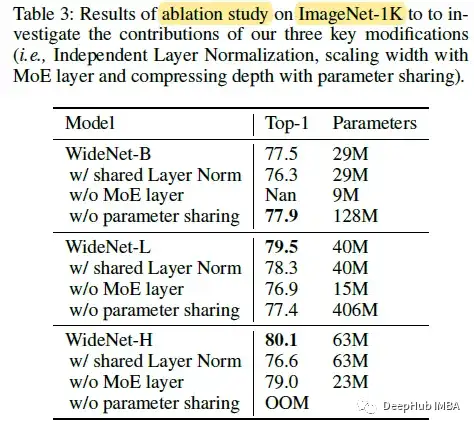
如果没有跨Transformer块的参数共享,也会有轻微的性能下降和显著的参数增量。对于没有参数共享的WideNet-H,在256个TPUv3核上训练时遇到内存不足的问题。
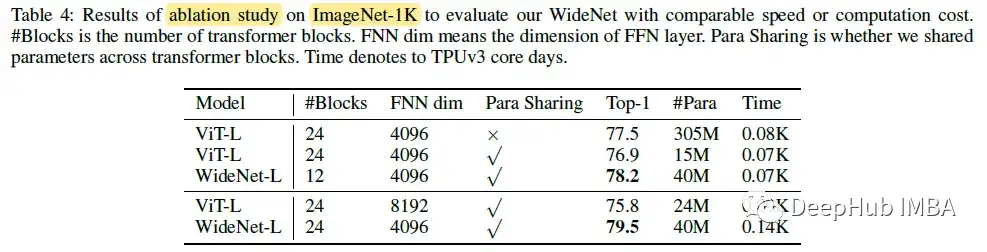
当WideNet-L比viti - l使用更少的Transformer块(即12个块)时,WideNet-L的性能比viti - l高0.7%,训练时间略少,而参数仅为13.1%,与参数共享的viti - l相比,性能则提升幅度更大。
通过使用参数共享将vitl缩放到更宽的FFN层。会有更多可训练的参数和FLOPs,但不能提高性能(4098 FFN dim到8192 FFN dim)。
论文地址:
Go Wider Instead of Deeper
https://ojs.aaai.org/index.php/AAAI/article/view/20858/20617
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
中科院自动化所发布FastSAM | 精度相当,速度提升50倍!!!
大核卷积网络是比 Transformer 更好的教师吗?ConvNets 对 ConvNets 蒸馏奇效
MaskFormer:将语义分割和实例分割作为同一任务进行训练
CVPR 2023 VAND Workshop Challenge零样本异常检测冠军方案
沈春华团队最新 | SegViTv2对SegViT进行全面升级,让基于ViT的分割模型更轻更强
刷新20项代码任务SOTA,Salesforce提出新型基础LLM系列编码器-解码器Code T5+
CVPR最佳论文颁给自动驾驶大模型!中国团队第一单位,近10年三大视觉顶会首例
最新轻量化Backbone | FalconNet汇聚所有轻量化模块的优点,成就最强最轻Backbone
libtorch教程(一)开发环境搭建:VS+libtorch和Qt+libtorch
NeRF与三维重建专栏(三)nerf_pl源码部分解读与colmap、cuda算子使用
NeRF与三维重建专栏(二)NeRF原文解读与体渲染物理模型
BEV专栏(一)从BEVFormer深入探究BEV流程(上篇)
可见光遥感图像目标检测(三)文字场景检测之Arbitrary

 浙公网安备 33010602011771号
浙公网安备 33010602011771号