论文插图也能自动生成了,用到了扩散模型,还被ICLR接收
前言 如果论文中的图表不用绘制,对于研究者来说是不是一种便利呢?有人在这方面进行了探索,利用文本描述生成论文图表,结果还挺有模有样的呢!
本文转载自机器之心
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
生成式 AI 已经风靡了人工智能社区,无论是个人还是企业,都开始热衷于创建相关的模态转换应用,比如文生图、文生视频、文生音乐等等。
最近呢,来自 ServiceNow Research、LIVIA 等科研机构的几位研究者尝试基于文本描述生成论文中的图表。为此,他们提出了一种 FigGen 的新方法,相关论文还被 ICLR 2023 收录为了 Tiny Paper。

论文地址:https://arxiv.org/pdf/2306.00800.pdf
也许有人会问了,生成论文中的图表有什么难的呢?这样做对于科研又有哪些帮助呢?
科研图表生成有助于以简洁易懂的方式传播研究结果,而自动生成图表可以为研究者带来很多优势,比如节省时间和精力,不用花大力气从头开始设计图表。此外设计出具有视觉吸引力且易理解的图表能使更多的人访问论文。
然而生成图表也面临一些挑战,它需要表示框、箭头、文本等离散组件之间的复杂关系。与生成自然图像不同,论文图表中的概念可能有不同的表示形式,需要细粒度的理解,例如生成一个神经网络图会涉及到高方差的不适定问题。
因此,本文研究者在一个论文图表对数据集上训练了一个生成式模型,捕获图表组件与论文中对应文本之间的关系。这就需要处理不同长度和高技术性文本描述、不同图表样式、图像长宽比以及文本渲染字体、大小和方向问题。
在具体实现过程中,研究者受到了最近文本到图像成果的启发,利用扩散模型来生成图表,提出了一种从文本描述生成科研图表的潜在扩散模型 ——FigGen。
这个扩散模型有哪些独到之处呢?我们接着往下看细节。
模型与方法
研究者从头开始训练了一个潜在扩散模型。
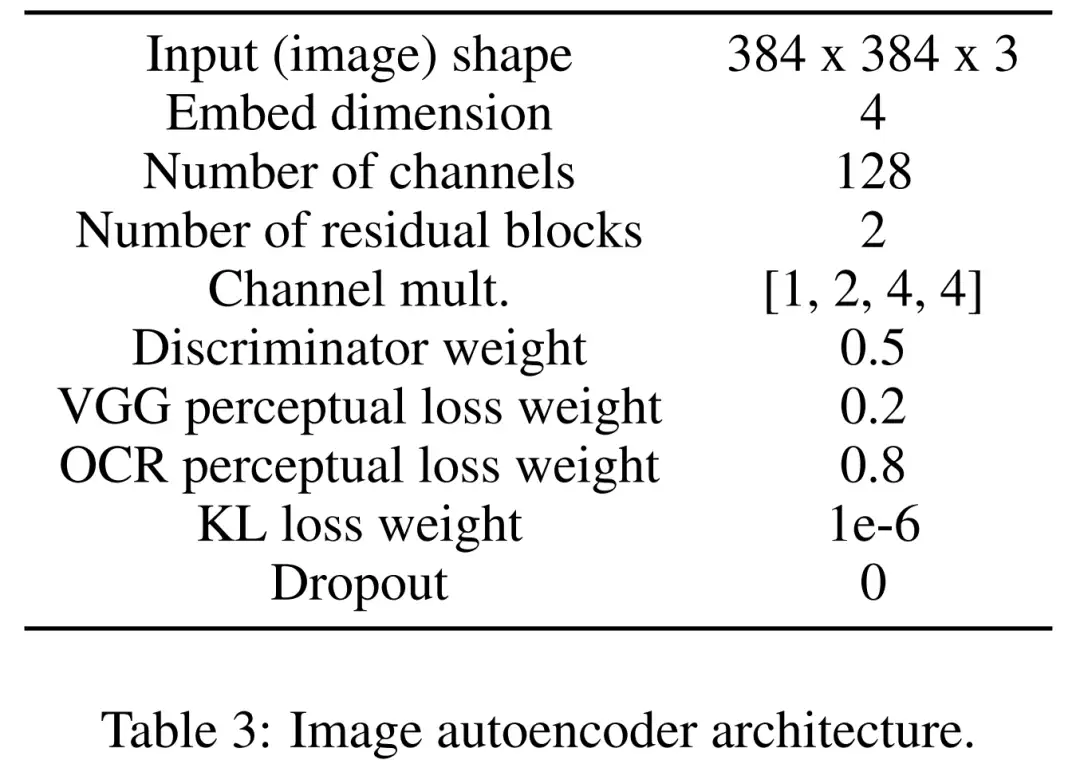
首先学习一个图像自动编码器,用来将图像映射为压缩的潜在表示。图像编码器使用 KL 损失和 OCR 感知损失。调节所用的文本编码器在该扩散模型的训练中端到端进行学习。下表 3 为图像自动编码器架构的详细参数。
然后,该扩散模型直接在潜在空间中进行交互,执行数据损坏的前向调度,同时学习利用时间和文本条件去噪 U-Net 来恢复该过程。
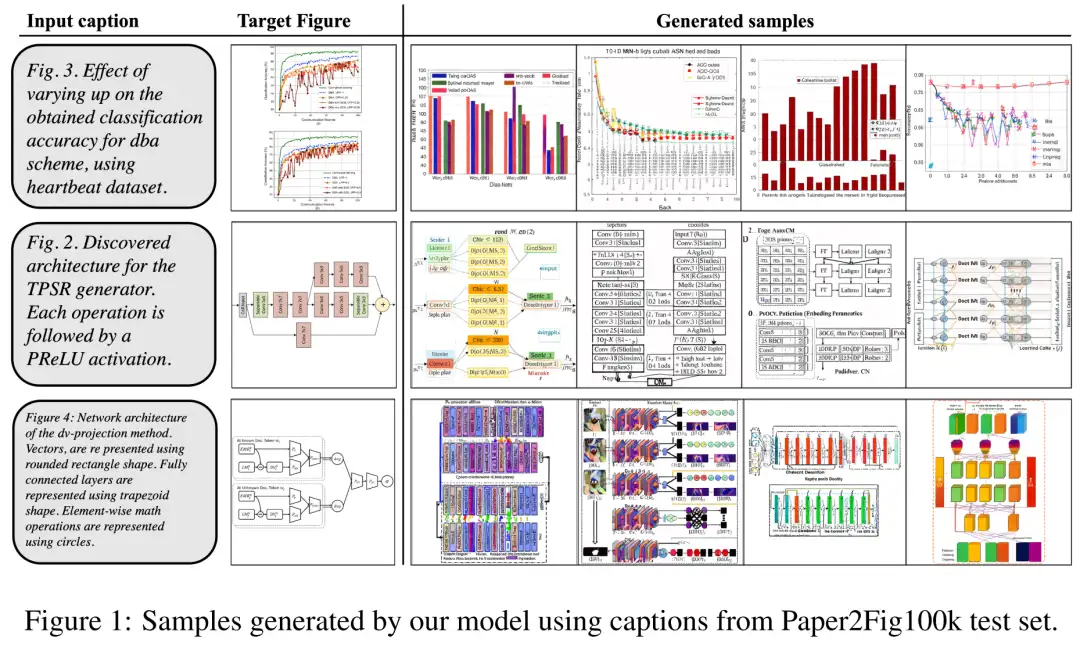
至于数据集,研究者使用了 Paper2Fig100k,它由论文中的图表文本对组成,包含了 81,194 个训练样本和 21,259 个验证样本。下图 1 为 Paper2Fig100k 测试集中使用文本描述生成的图表示例。
模型细节
首先是图像编码器。第一阶段,图像自动编码器学习一个从像素空间到压缩潜在表示的映射,使扩散模型训练更快。图像编码器还需要学习将潜在图像映射回像素空间,同时不丢失图表重要细节(如文本渲染质量)。
为此,研究者定义了一个具有瓶颈的卷积编解码器,在因子 f=8 时对图像进行下采样。编码器经过训练可以最小化具有高斯分布的 KL 损失、VGG 感知损失和 OCR 感知损失。
其次是文本编码器。研究者发现通用文本编码器不太适合生成图表任务。因此他们定义了一个在扩散过程中从头开始训练的 Bert transformer,其中使用大小为 512 的嵌入通道,这也是调节 U-Net 的跨注意力层的嵌入大小。研究者还探索了不同设置下(8、32 和 128)的 transformer 层数量的变化。
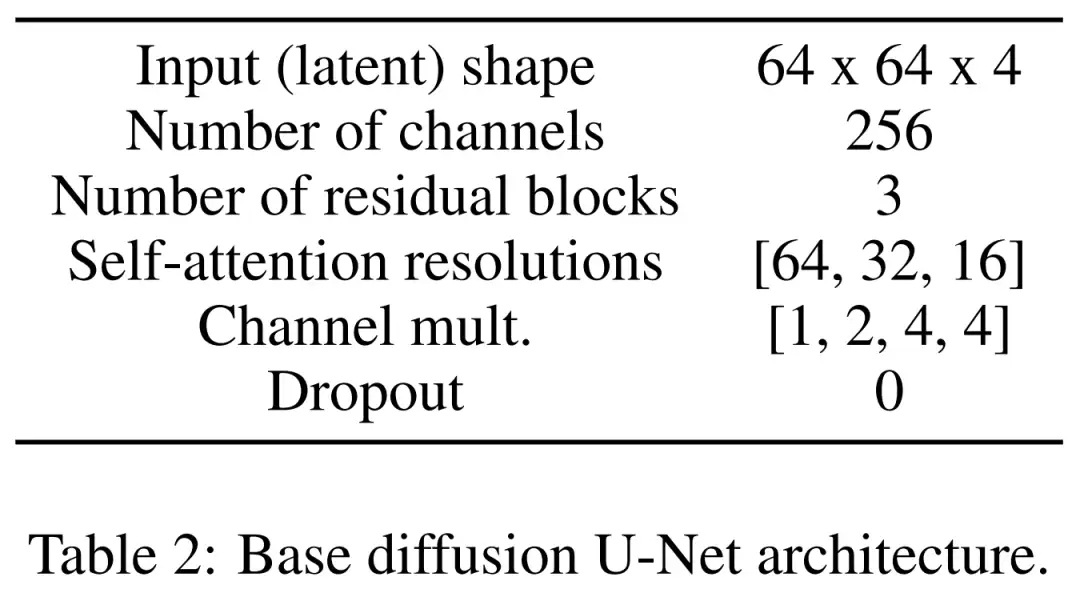
最后是潜在扩散模型。下表 2 展示了 U-Net 的网络架构。研究者在感知上等效的图像潜在表示中执行扩散过程,其中该图像的输入大小被压缩到了 64x64x4,使扩散模型更快。他们定义了 1,000 个扩散步骤和线性噪声调度。
训练细节
为了训练图像自动编码器,研究者使用了一个 Adam 优化器,它的有效批大小为 4 个样本、学习率为 4.5e−6,期间使用了 4 个 12GB 的英伟达 V100 显卡。为了实现训练稳定性,他们在 50k 次迭代中 warmup 模型,而不使用判别器。
对于训练潜在扩散模型,研究者也使用 Adam 优化器,它的有效批大小为 32,学习率为 1e−4。在 Paper2Fig100k 数据集上训练该模型时,他们用到了 8 块 80GB 的英伟达 A100 显卡。
实验结果
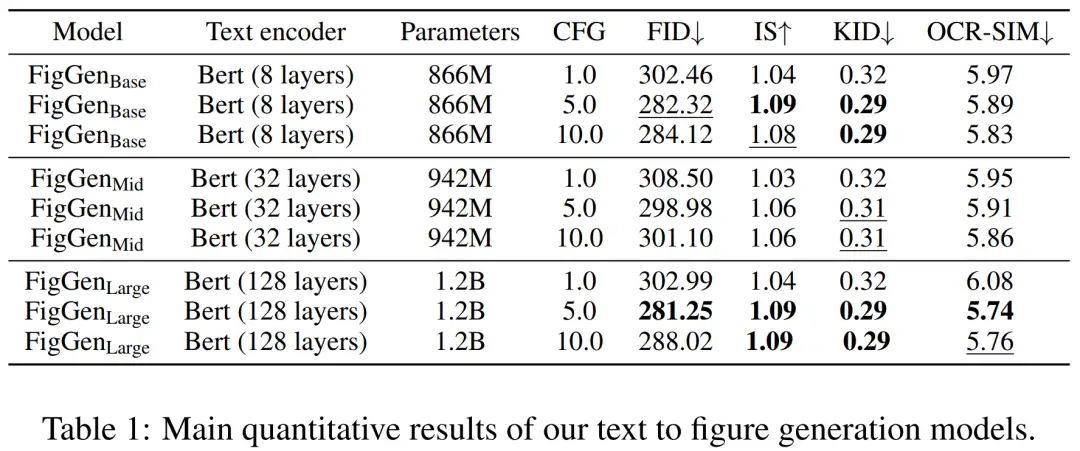
在生成过程中,研究者采用了具有 200 步的 DDIM 采样器,并且为每个模型生成了 12,000 个样本来计算 FID, IS, KID 以及 OCR-SIM1。稳重使用无分类器指导(CFG)来测试超调节。
下表 1 展示了不同文本编码器的结果。可见,大型文本编码器产生了最好的定性结果,并且可以通过增加 CFG 的规模来改进条件生成。虽然定性样本没有足够的质量来解决问题,但 FigGen 已经掌握了文本和图像之间的关系。
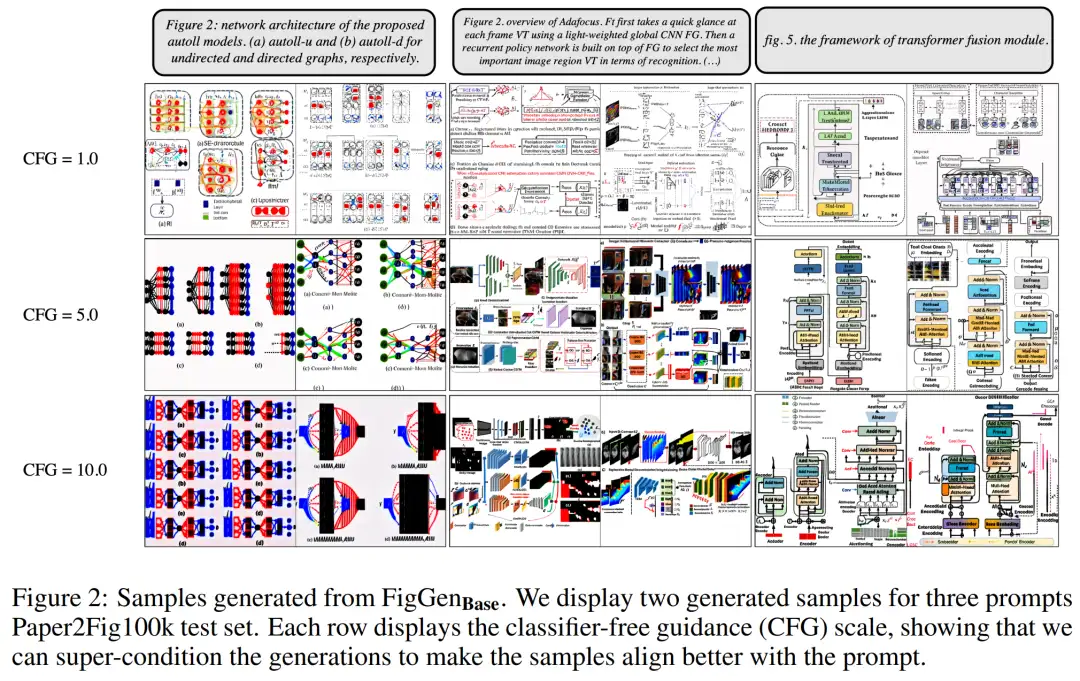
下图 2 展示了调整无分类器指导(CFG)参数时生成的额外 FigGen 样本。研究者观察到增加 CFG 的规模(这在定量上也得到了体现)可以带来图像质量的改善。
下图 3 展示了 FigGen 的更多生成示例。要注意样本之间长度的变化,以及文本描述的技术水平,这会密切影响到模型正确生成可理解图像的难度。

不过研究者也承认,尽管现在这些生成的图表不能为论文作者提供实际帮助,但仍不失为一个有前景的探索方向。
更多研究细节请参阅原论文。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
中科院自动化所发布FastSAM | 精度相当,速度提升50倍!!!
大核卷积网络是比 Transformer 更好的教师吗?ConvNets 对 ConvNets 蒸馏奇效
MaskFormer:将语义分割和实例分割作为同一任务进行训练
CVPR 2023 VAND Workshop Challenge零样本异常检测冠军方案
沈春华团队最新 | SegViTv2对SegViT进行全面升级,让基于ViT的分割模型更轻更强
刷新20项代码任务SOTA,Salesforce提出新型基础LLM系列编码器-解码器Code T5+
CVPR最佳论文颁给自动驾驶大模型!中国团队第一单位,近10年三大视觉顶会首例
最新轻量化Backbone | FalconNet汇聚所有轻量化模块的优点,成就最强最轻Backbone
libtorch教程(一)开发环境搭建:VS+libtorch和Qt+libtorch
NeRF与三维重建专栏(三)nerf_pl源码部分解读与colmap、cuda算子使用
NeRF与三维重建专栏(二)NeRF原文解读与体渲染物理模型
BEV专栏(一)从BEVFormer深入探究BEV流程(上篇)
可见光遥感图像目标检测(三)文字场景检测之Arbitrary

 浙公网安备 33010602011771号
浙公网安备 33010602011771号