
田渊栋新作:打开1层Transformer黑盒,注意力机制没那么神秘
前言 AI理论再进一步,破解ChatGPT指日可待?
本文转载自新智元
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
Transformer架构已经横扫了包括自然语言处理、计算机视觉、语音、多模态等多个领域,不过目前只是实验效果非常惊艳,对Transformer工作原理的相关研究仍然十分有限。
其中最大谜团在于,Transformer为什么仅依靠一个「简单的预测损失」就能从梯度训练动态(gradient training dynamics)中涌现出高效的表征?
最近田渊栋博士公布了团队的最新研究成果,以数学严格方式,分析了1层Transformer(一个自注意力层加一个解码器层)在下一个token预测任务上的SGD训练动态。

论文链接:https://arxiv.org/abs/2305.16380
这篇论文打开了自注意力层如何组合输入token动态过程的黑盒子,并揭示了潜在的归纳偏见的性质。
具体来说,在没有位置编码、长输入序列、以及解码器层比自注意力层学习更快的假设下,研究人员证明了自注意力就是一个判别式扫描算法(discriminative scanning algorithm):
从均匀分布的注意力(uniform attention)开始,对于要预测的特定下一个token,模型逐渐关注不同的key token,而较少关注那些出现在多个next token窗口中的常见token
对于不同的token,模型会逐渐降低注意力权重,遵循训练集中的key token和query token之间从低到高共现的顺序。
有趣的是,这个过程不会导致赢家通吃,而是由两层学习率控制的相变而减速,最后变成(几乎)固定的token组合,在合成和真实世界的数据上也验证了这种动态。
田渊栋博士是Meta人工智能研究院研究员、研究经理,围棋AI项目负责人,其研究方向为深度增强学习及其在游戏中的应用,以及深度学习模型的理论分析。先后于2005年及2008年获得上海交通大学本硕学位,2013年获得美国卡耐基梅隆大学机器人研究所博士学位。

曾获得2013年国际计算机视觉大会(ICCV)马尔奖提名(Marr Prize Honorable Mentions),ICML2021杰出论文荣誉提名奖。
曾在博士毕业后发布《博士五年总结》系列,从研究方向选择、阅读积累、时间管理、工作态度、收入和可持续的职业发展等方面对博士生涯总结心得和体会。
揭秘1层Transformer
基于Transformer架构的预训练模型通常只包括非常简单的监督任务,比如预测下一个单词、填空等,但却可以为下游任务提供非常丰富的表征,实在是令人费解。
之前的工作虽然已经证明了Transformer本质上就是一个通用近似器(universal approximator),但之前常用的机器学习模型,比如kNN、核SVM、多层感知机等其实也是通用近似器,这种理论无法解释这两类模型在性能上的巨大差距。
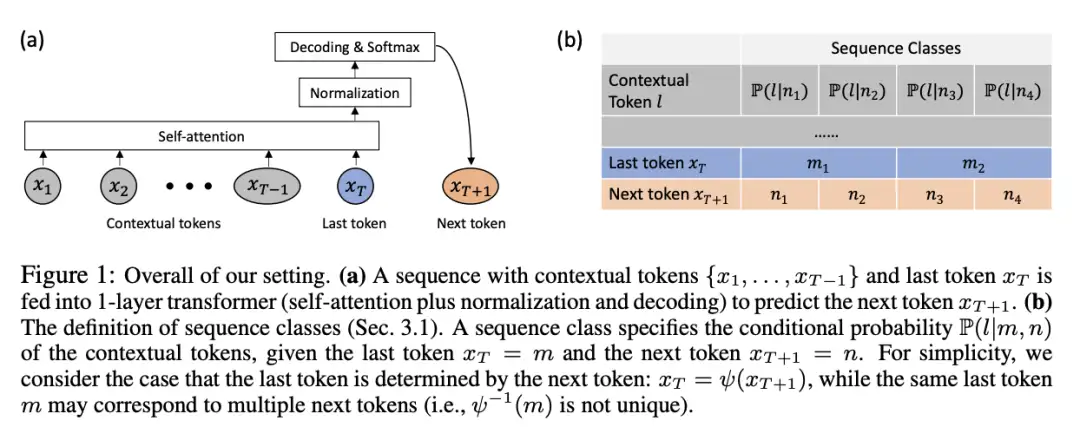
研究人员认为,了解Transformer的训练动态(training dynamics)是很重要的,也就是说,在训练过程中,可学习参数是如何随时间变化的。
文章首先以严谨数学定义的方式,形式化描述了1层无位置编码Transformer的SGD在下一个token预测(GPT系列模型常用的训练范式)上的训练动态。
1层的Transformer包含一个softmax自注意力层和预测下一个token的解码器层。
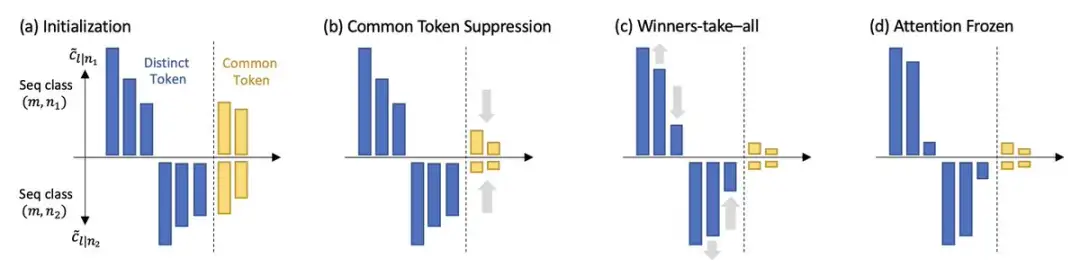
在假设序列很长,而且解码器的学习速度比自注意力层快的情况下,证明了训练期间自注意力的动态行为:
1. 频率偏差Frequency Bias
模型会逐渐关注那些与query token大量共现的key token,而对那些共现较少的token降低注意力。
2. 判别偏差Discrimitive Bias
模型更关注那些在下一个要预测的token中唯一出现的独特token,而对那些在多个下一个token中出现的通用token失去兴趣。
这两个特性表明,自注意力隐式地运行着一种判别式扫描(discriminative scanning)的算法,并存在归纳偏差(inductive bias),即偏向于经常与query token共同出现的独特的key token
此外,虽然自注意力层在训练过程中趋向于变得更加稀疏,但正如频率偏差所暗示的,模型因为训练动态中的相变(phase transition),所以不会崩溃为独热(one hot)。

学习的最后阶段并没有收敛到任何梯度为零的鞍点,而是进入了一个注意力变化缓慢的区域(即随时间变化的对数),并出现参数冻结和学会(learned)。
研究结果进一步表明,相变的开始是由学习率控制的:大的学习率会产生稀疏的注意力模式,而在固定的自注意力学习率下,大的解码器学习率会导致更快的相变和密集的注意力模式。
研究人员将工作中发现的SGD动态命名为扫描(scan)和snap:
扫描阶段:自注意力集中在key tokens上,即不同的、经常与下一个预测token同时出现的token;其他所有token的注意力都下降。
snap阶段:注意力全中几乎冻结,token组合固定。
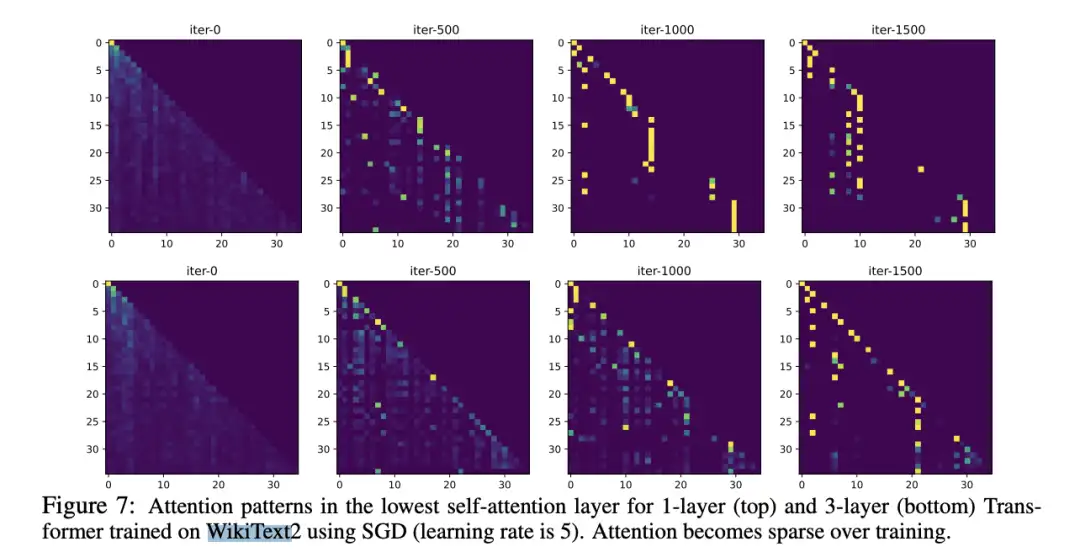
这一现象在简单的真实世界数据实验中也得到验证,使用SGD在WikiText上训练的1层和3层Transformer的最低自注意力层进行观察,可以发现即使在整个训练过程中学习率保持不变,注意力也会在训练过程中的某一时刻冻结,并变得稀疏。
参考资料:https://arxiv.org/abs/2305.16380
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
ICLR 2023 | RevCol:可逆的多 column 网络,大模型架构设计新范式
CVPR 2023 | 即插即用的注意力模块 HAT: 激活更多有用的像素助力low-level任务显著涨点!
ICML 2023 | 轻量级视觉Transformer (ViT) 的预训练实践手册
CVPR 2023 | 神经网络超体?新国立LV lab提出全新网络克隆技术
即插即用系列 | 高效多尺度注意力模块EMA成为YOLOv5改进的小帮手
即插即用系列 | Meta 新作 MMViT: 基于交叉注意力机制的多尺度和多视角编码神经网络架构
全新YOLO模型YOLOCS来啦 | 面面俱到地改进YOLOv5的Backbone/Neck/Head
6G显存玩转130亿参数大模型,仅需13行命令,RTX2060用户发来贺电
libtorch教程(一)开发环境搭建:VS+libtorch和Qt+libtorch
NeRF与三维重建专栏(三)nerf_pl源码部分解读与colmap、cuda算子使用
NeRF与三维重建专栏(二)NeRF原文解读与体渲染物理模型
BEV专栏(一)从BEVFormer深入探究BEV流程(上篇)
可见光遥感图像目标检测(三)文字场景检测之Arbitrary

