iPhone两秒出图,目前已知的最快移动端Stable Diffusion模型来了
前言 近日,Snap 研究院推出最新高性能 Stable Diffusion 模型,通过对网络结构、训练流程、损失函数全方位进行优化,在 iPhone 14 Pro 上实现 2 秒出图(512x512),且比 SD-v1.5 取得更好的 CLIP score。这是目前已知最快的端上 Stable Diffusion 模型!
本文转载自机器之心
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
Stable Diffusion (SD)是当前最热门的文本到图像(text to image)生成扩散模型。尽管其强大的图像生成能力令人震撼,一个明显的不足是需要的计算资源巨大,推理速度很慢:以 SD-v1.5 为例,即使用半精度存储,其模型大小也有 1.7GB,近 10 亿参数,端上推理时间往往要接近 2min。
为了解决推理速度问题,学术界与业界已经开始对 SD 加速的研究,主要集中于两条路线:(1)减少推理步数,这条路线又可以分为两条子路线,一是通过提出更好的 noise scheduler 来减少步数,代表作是 DDIM [1],PNDM [2],DPM [3] 等;二是通过渐进式蒸馏(Progressive Distillation)来减少步数,代表作是 Progressive Distillation [4] 和 w-conditioning [5] 等。(2)工程技巧优化,代表作是 Qualcomm 通过 int8 量化 + 全栈式优化实现 SD-v1.5 在安卓手机上 15s 出图 [6],Google 通过端上 GPU 优化将 SD-v1.4 在三星手机上加速到 12s [7]。
尽管这些工作取得了长足的进步,但仍然不够快。
近日,Snap 研究院推出最新高性能 Stable Diffusion 模型!

核心方法
Stable Diffusion 模型分为三部分:VAE encoder/decoder, text encoder, UNet,其中 UNet 无论是参数量还是计算量,都占绝对的大头,因此 SnapFusion 主要是对 UNet 进行优化。具体分为两部分:(1)UNet 结构上的优化:通过分析原有 UNet 的速度瓶颈,本文提出一套 UNet 结构自动评估、进化流程,得到了更为高效的 UNet 结构(称为 Efficient UNet)。(2)推理步数上的优化:众所周知,扩散模型在推理时是一个迭代的去噪过程,迭代的步数越多,生成图片的质量越高,但时间代价也随着迭代步数线性增加。为了减少步数并维持图片质量,我们提出一种 CFG-aware 蒸馏损失函数,在训练过程中显式考虑 CFG (Classifier-Free Guidance)的作用,这一损失函数被证明是提升 CLIP score 的关键!
下表是 SD-v1.5 与 SnapFusion 模型的概况对比,可见速度提升来源于 UNet 和 VAE decoder 两个部分,UNet 部分是大头。UNet 部分的改进有两方面,一是单次 latency 下降(1700ms -> 230ms,7.4x 加速),这是通过提出的 Efficient UNet 结构得到的;二是 Inference steps 降低(50 -> 8,6.25x 加速),这是通过提出的 CFG-aware Distillation 得到的。VAE decoder 的加速是通过结构化剪枝实现。

下面着重介绍 Efficient UNet 的设计和 CFG-aware Distillation 损失函数的设计。
(1)Efficient UNet
我们通过分析 UNet 中的 Cross-Attention 和 ResNet 模块,定位速度瓶颈在于 Cross-Attention 模块(尤其是第一个 Downsample 阶段的 Cross-Attention),如下图所示。这个问题的根源是因为 attention 模块的复杂度跟特征图的 spatial size 成平方关系,在第一个 Downsample 阶段,特征图的 spatial size 仍然较大,导致计算复杂度高。
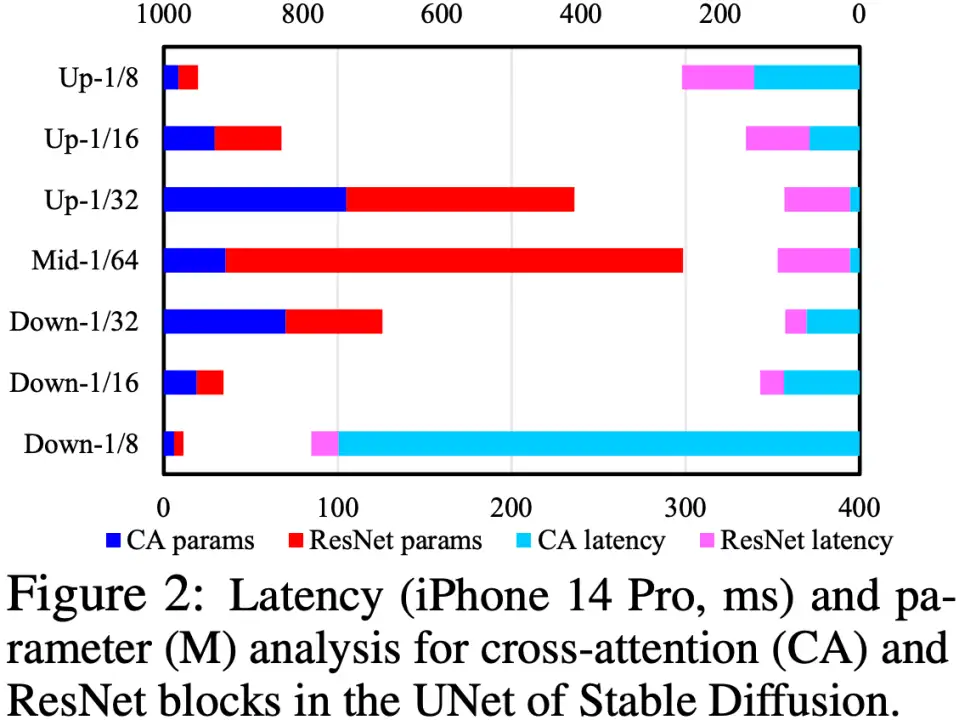
为了优化 UNet 结构,我们提出一套 UNet 结构自动评估、进化流程:先对 UNet 进行鲁棒性训练(Robust Training),在训练中随机 drop 一些模块,以此来测试出每个模块对性能的真实影响,从而构建一个 “对 CLIP score 的影响 vs. latency” 的查找表;然后根据该查找表,优先去除对 CLIP score 影响不大同时又很耗时的模块。这一套流程是在线自动进行,完成之后,我们就得到了一个全新的 UNet 结构,称为 Efficient UNet。相比原版 UNet,实现 7.4x 加速且性能不降。
(2)CFG-aware Step Distillation
CFG(Classifier-Free Guidance)是 SD 推理阶段的必备技巧,可以大幅提升图片质量,非常关键!尽管已有工作对扩散模型进行步数蒸馏(Step Distillation)来加速 [4],但是它们没有在蒸馏训练中把 CFG 纳入优化目标,也就是说,蒸馏损失函数并不知道后面会用到 CFG。这一点根据我们的观察,在步数少的时候会严重影响 CLIP score。
为了解决这个问题,我们提出在计算蒸馏损失函数之前,先让 teacher 和 student 模型都进行 CFG,这样损失函数是在经过 CFG 之后的特征上计算,从而显式地考虑了不同 CFG scale 的影响。实验中我们发现,完全使用 CFG-aware Distillation 尽管可以提高 CLIP score, 但 FID 也明显变差。我们进而提出了一个随机采样方案来混合原来的 Step Distillation 损失函数和 CFG-aware Distillation 损失函数,实现了二者的优势共存,既显著提高了 CLIP score,同时 FID 也没有变差。这一步骤,实现进一步推理阶段加速 6.25 倍,实现总加速约 46 倍。
除了以上两个主要贡献,文中还有对 VAE decoder 的剪枝加速以及蒸馏流程上的精心设计,具体内容请参考论文。
实验结果
SnapFusion 对标 SD-v1.5 text to image 功能,目标是实现推理时间大幅缩减并维持图像质量不降,最能说明这一点的是下图:
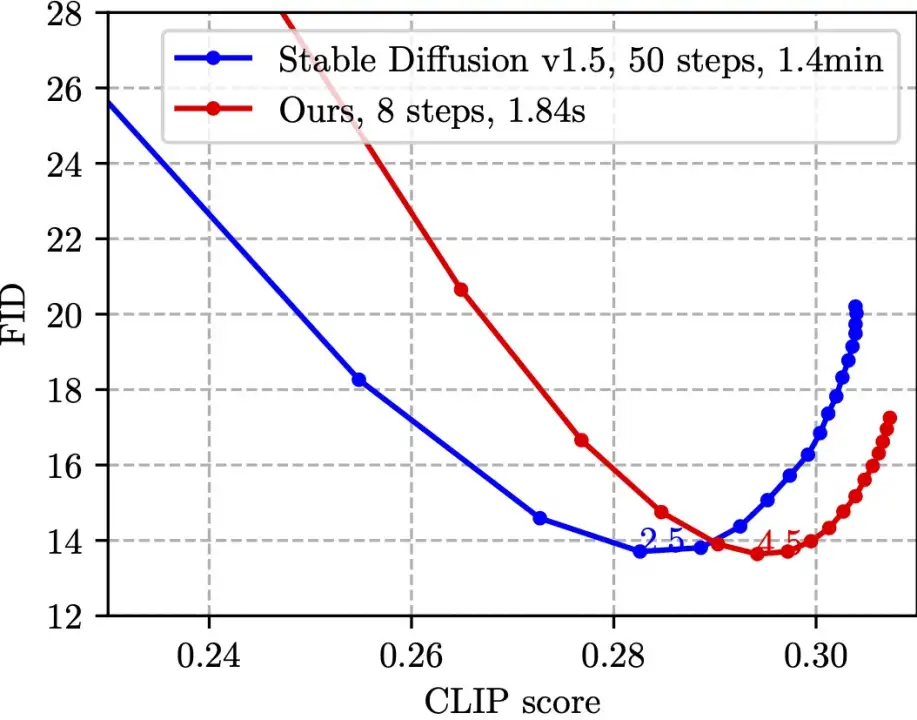
该图是在 MS COCO’14 验证集上随机选取 30K caption-image pairs 测算 CLIP score 和 FID。CLIP score 衡量图片与文本的语义吻合程度,越大越好;FID 衡量生成图片与真实图片之间的分布距离(一般被认为是生成图片多样性的度量),越小越好。图中不同的点是使用不同的 CFG scale 获得,每一个 CFG scale 对应一个数据点。从图中可见,我们的方法(红线)可以达到跟 SD-v1.5(蓝线)同样的最低 FID,同时,我们方法的 CLIP score 更好。值得注意的是,SD-v1.5 需要 1.4min 生成一张图片,而 SnapFusion 仅需要 1.84s,这也是目前我们已知最快的移动端 Stable Diffusion 模型!
下面是一些 SnapFusion 生成的样本:

更多样本请参考文章附录。
除了这些主要结果,文中也展示了众多烧蚀分析(Ablation Study)实验,希望能为高效 SD 模型的研发提供参考经验:
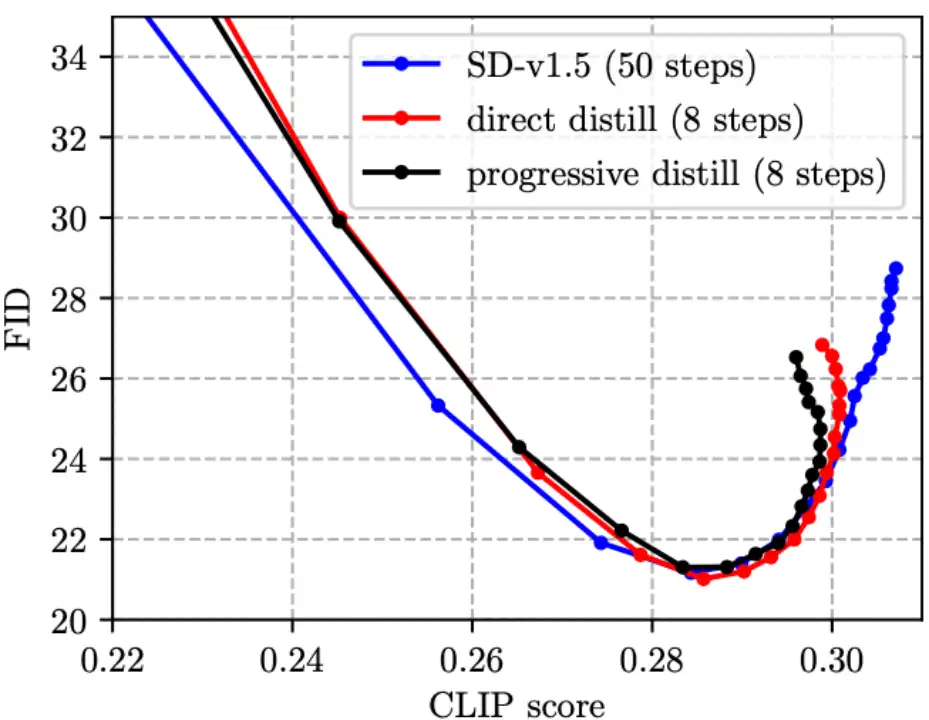
(1)之前 Step Distillation 的工作通常采用渐进式方案 [4, 5],但我们发现,在 SD 模型上渐进式蒸馏并没有比直接蒸馏更有优势,且过程繁琐,因此我们在文中采用的是直接蒸馏方案。
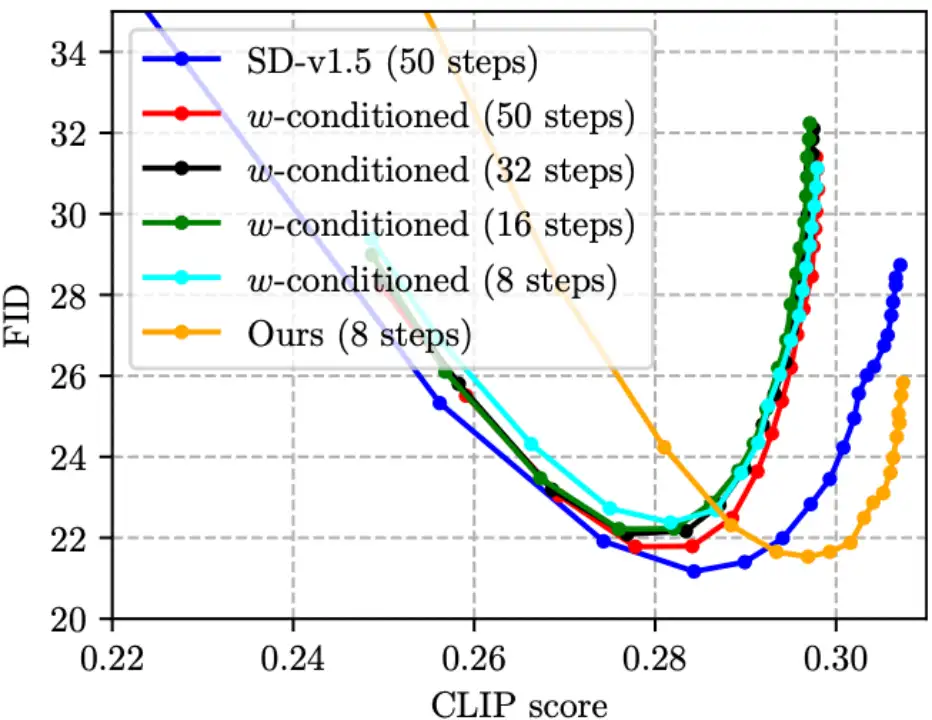
(2)CFG 虽然可以大幅提升图像质量,但代价是推理成本翻倍。今年 CVPR’23 Award Candidate 的 On Distillation 一文 [5] 提出 w-conditioning,将 CFG 参数作为 UNet 的输入进行蒸馏(得到的模型叫做 w-conditioned UNet),从而在推理时省却 CFG 这一步,实现推理成本减半。但是我们发现,这样做其实会造成图片质量下降,CLIP score 降低(如下图中,四条 w-conditioned 线 CLIP score 均未超过 0.30, 劣于 SD-v1.5)。而我们的方法则可以减少步数,同时将 CLIP score 提高,得益于所提出的 CFG-aware 蒸馏损失函数!尤其值得主要的是,下图中绿线(w-conditioned, 16 steps)与橙线(Ours,8 steps)的推理代价是一样的,但明显橙线更优,说明我们的技术路线比 w-conditioning [5] 在蒸馏 CFG guided SD 模型上更为有效。
(3)既有 Step Distillation 的工作 [4, 5] 没有将原有的损失函数和蒸馏损失函数加在一起,熟悉图像分类知识蒸馏的朋友应该知道,这种设计直觉上来说是欠优的。于是我们提出把原有的损失函数加入到训练中,如下图所示,确实有效(小幅降低 FID)。

总结与未来工作
本文提出 SnapFusion,一种移动端高性能 Stable Diffusion 模型。SnapFusion 有两点核心贡献:(1)通过对现有 UNet 的逐层分析,定位速度瓶颈,提出一种新的高效 UNet 结构(Efficient UNet),可以等效替换原 Stable Diffusion 中的 UNet,实现 7.4x 加速;(2)对推理阶段的迭代步数进行优化,提出一种全新的步数蒸馏方案(CFG-aware Step Distillation),减少步数的同时可显著提升 CLIP score,实现 6.25x 加速。总体来说,SnapFusion 在 iPhone 14 Pro 上实现 2 秒内出图,这是目前已知最快的移动端 Stable Diffusion 模型。
未来工作:
1.SD 模型在多种图像生成场景中都可以使用,本文囿于时间,目前只关注了 text to image 这个核心任务,后期将跟进其他任务(如 inpainting,ControlNet 等等)。
2. 本文主要关注速度上的提升,并未对模型存储进行优化。我们相信所提出的 Efficient UNet 仍然具备压缩的空间,结合其他的高性能优化方法(如剪枝,量化),有望缩小存储,并将时间降低到 1 秒以内,离端上实时 SD 更进一步。
参考文献
[1] Denoising Diffusion Implicit Models, ICLR’21
[2] Pseudo Numerical Methods for Diffusion Models on Manifolds, ICLR’22
[3] DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps, NeurIPS’22
[4] Progressive Distillation for Fast Sampling of Diffusion Models, ICLR’22
[5] On Distillation of Guided Diffusion Models, CVPR’23
[7] Speed Is All You Need: On-Device Acceleration of Large Diffusion Models via GPU-Aware Optimizations, CVPR’23 Workshop
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
ICLR 2023 | RevCol:可逆的多 column 网络,大模型架构设计新范式
CVPR 2023 | 即插即用的注意力模块 HAT: 激活更多有用的像素助力low-level任务显著涨点!
ICML 2023 | 轻量级视觉Transformer (ViT) 的预训练实践手册
CVPR 2023 | 神经网络超体?新国立LV lab提出全新网络克隆技术
即插即用系列 | 高效多尺度注意力模块EMA成为YOLOv5改进的小帮手
即插即用系列 | Meta 新作 MMViT: 基于交叉注意力机制的多尺度和多视角编码神经网络架构
全新YOLO模型YOLOCS来啦 | 面面俱到地改进YOLOv5的Backbone/Neck/Head
6G显存玩转130亿参数大模型,仅需13行命令,RTX2060用户发来贺电
libtorch教程(一)开发环境搭建:VS+libtorch和Qt+libtorch
NeRF与三维重建专栏(三)nerf_pl源码部分解读与colmap、cuda算子使用
NeRF与三维重建专栏(二)NeRF原文解读与体渲染物理模型
BEV专栏(一)从BEVFormer深入探究BEV流程(上篇)
可见光遥感图像目标检测(三)文字场景检测之Arbitrary

 浙公网安备 33010602011771号
浙公网安备 33010602011771号