

DHVT:小数据集也能轻松训练!缩小VIT与CNN鸿沟,解决从零开始的训练难题
前言 VIT在归纳偏置方面存在空间相关性和信道表示的多样性两大缺陷。所以论文提出了动态混合视觉变压器(DHVT)来增强这两种感应偏差。在空间方面,采用混合结构,将卷积集成到补丁嵌入和多层感知器模块中,迫使模型捕获令牌特征及其相邻特征。在信道方面,引入了MLP中的动态特征聚合模块和多头注意力模块中全新的“head token”设计,帮助重新校准信道表示,并使不同的信道组表示相互交互。
本文转载自DeepHub IMBA
作者 | Sik-Ho Tsang
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
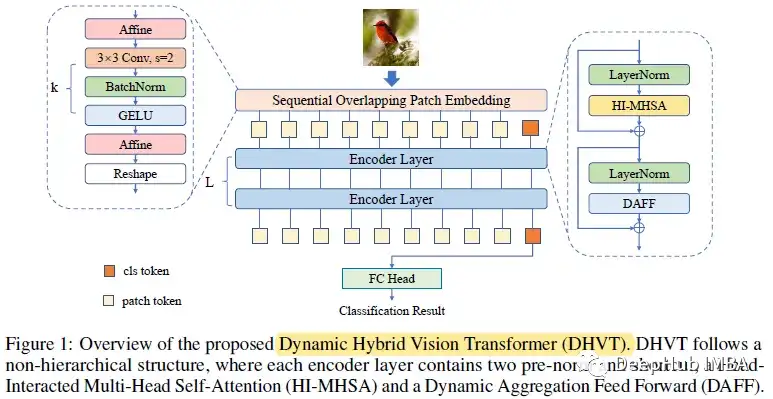
1、顺序重叠补丁嵌入 (Sequential Overlapping Patch Embedding )
改进后的补丁嵌入称为Sequential overlap patch embedding(SOPE),它包含了3×3步长s=2的卷积、BN和GELU激活的几个连续卷积层。卷积层数与patch大小的关系为P=2^k。SOPE能够消除以前嵌入模块带来的不连续性,保留重要的底层特征。它能在一定程度上提供位置信息。
在一系列卷积层前后分别采用两次仿射变换。该操作对输入特征进行了缩放和移位,其作用类似于归一化,使训练性能在小数据集上更加稳定。
SOPE的整个流程可以表述如下。
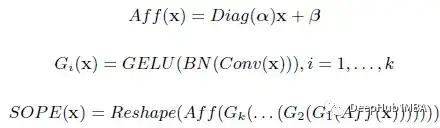
这里的α和β为可学习参数,分别初始化为1和0。
2、编码器整体架构
然后将特征映射重塑为补丁并与cls令牌连接,并发到编码器层。每个编码器包含层归一化、多头自注意力和前馈网络。将MHSA网络改进为头部交互多头自注意网络(HI-MHSA),将前馈网络改进为动态聚合前馈网络(DAFF)。在最后的编码器层之后,输出类标记将被馈送到线性头部进行最终预测。
3、动态聚合前馈 (Dynamic Aggregation Feed Forward )
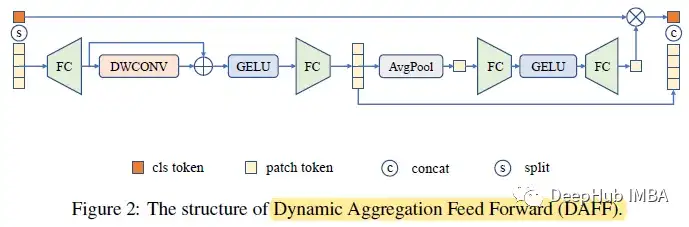
ViT 中的普通前馈网络 (FFN) 由两个全连接层和 GELU 组成。DAFF 在 FFN 中集成了来自 MobileNetV1 的深度卷积 (DWCONV)。由于深度卷积带来的归纳偏差,模型被迫捕获相邻特征,解决了空间视图上的问题。它极大地减少了在小型数据集上从头开始训练时的性能差距,并且比标准 CNN 收敛得更快。还使用了与来自 SENet 的 SE 模块类似的机制。
Xc、Xp 分别表示类标记和补丁标记。类标记在投影层之前从序列中分离为 Xc。剩余的令牌 Xp 则通过一个内部有残差连接的深度集成多层感知器。
然后将输出的补丁标记平均为权重向量 W。在squeeze-excitation操作之后,输出权重向量将与类标记通道相乘。然后重新校准的类令牌将与输出补丁令牌以恢复令牌序列。
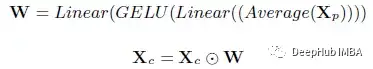
4、相互作用多头自注意(HI-MHSA)
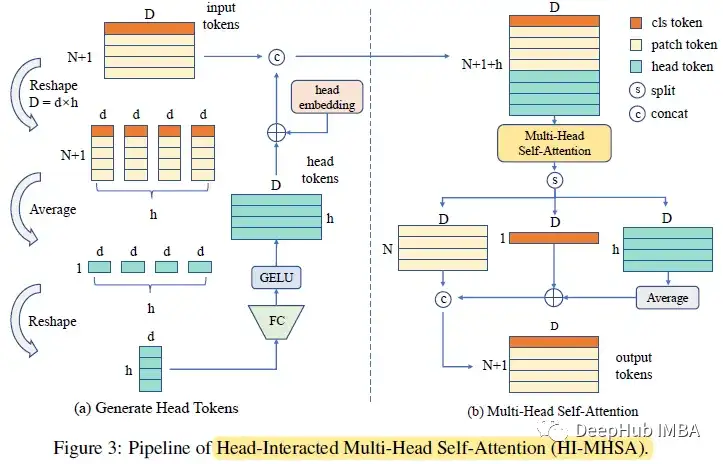
在最初的MHSA模块中,每个注意头都没有与其他头交互。在缺乏训练数据的情况下,每个通道组的表征都太弱而无法识别。
在HI-MHSA中,每个d维令牌,包括类令牌,将被重塑为h部分。每个部分包含d个通道,其中d =d×h。所有分离的标记在它们各自的部分中取平均值。因此总共得到h个令牌,每个令牌都是d维的。所有这样的中间令牌将再次投影到d维,总共产生h个头部令牌。最后,将它们与补丁令牌和类令牌连接起来。
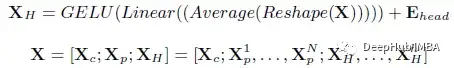
5、模型变体
DHVT-T: 12层编码器,嵌入维度为192,MLP比为4,CIFAR-100和DomainNet上的注意头为4,ImageNet-1K上的注意头为3。DHVT-S: 12层编码器,嵌入维度为384,MLP比4,CIFAR-100上注意头为8,DomainNet和ImageNet-1K上注意头为6。
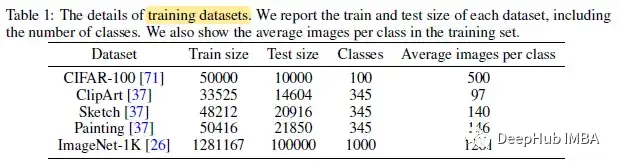
需要说明的是:论文和模型的重点是在小数据集上从零开始训练。
结果展示
1、DomainNet & ImageNet-1K

在DomainNet上,DHVT表现出比标准ResNet-50更好的结果。在ImageNet-1K上,DHVT-T的准确率达到76.47,DHVT-S的准确率达到82.3。论文说这是在VIT的最佳性能。
2、CIFAR-100
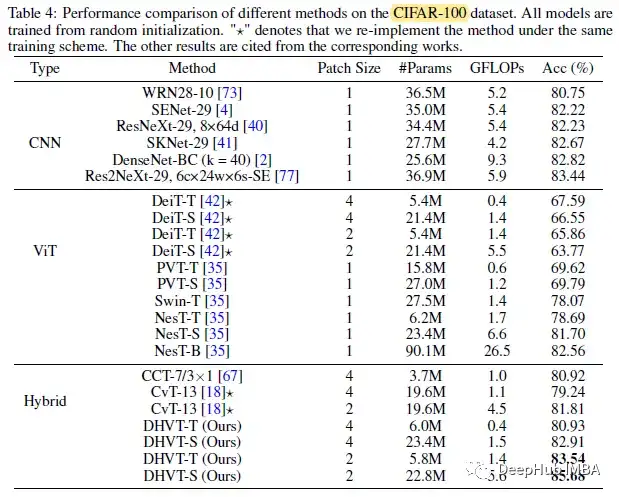
DHVT-T在5.8M参数下达到83.54。DHVT-S仅用2280万个参数即可达到85.68。与其他基于vit的模型和CNN(ResNeXt, SENet, SKNet, DenseNet和Res2Net)相比,所提出的模型参数更少,性能更高。
3、消融研究
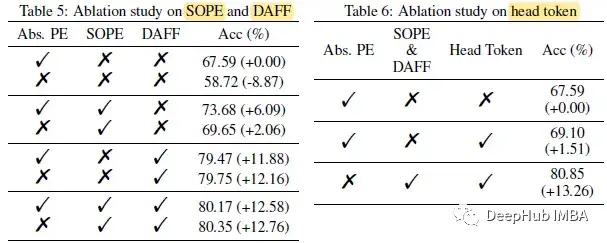
DeiT-T 4头,从头开始训练300次,基线成绩67.59。当移除绝对位置嵌入时,性能急剧下降至58.72。当采用SOPE并取消绝对位置嵌入时,性能下降幅度并不大。
同时采用SOPE和DAFF时,可以对位置信息进行全面编码,SOPE也有助于解决这里的不重叠问题,在早期保留了细粒度的底层特征。
table6发现了跨不同模型结构的head令牌带来的稳定性能增益。
当采用这三种修改时,获得了+13.26的精度增益,成功地弥合了与CNN的性能差距。
4、可视化
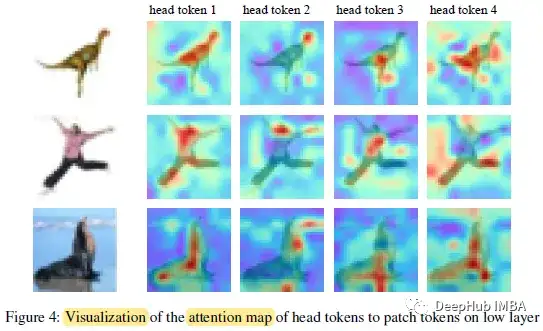
不同的head令牌在不同的补丁上激活
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
ICLR 2023 | RevCol:可逆的多 column 网络,大模型架构设计新范式
CVPR 2023 | 即插即用的注意力模块 HAT: 激活更多有用的像素助力low-level任务显著涨点!
ICML 2023 | 轻量级视觉Transformer (ViT) 的预训练实践手册
CVPR 2023 | 神经网络超体?新国立LV lab提出全新网络克隆技术
即插即用系列 | 高效多尺度注意力模块EMA成为YOLOv5改进的小帮手
即插即用系列 | Meta 新作 MMViT: 基于交叉注意力机制的多尺度和多视角编码神经网络架构
全新YOLO模型YOLOCS来啦 | 面面俱到地改进YOLOv5的Backbone/Neck/Head
6G显存玩转130亿参数大模型,仅需13行命令,RTX2060用户发来贺电
libtorch教程(一)开发环境搭建:VS+libtorch和Qt+libtorch
NeRF与三维重建专栏(三)nerf_pl源码部分解读与colmap、cuda算子使用
NeRF与三维重建专栏(二)NeRF原文解读与体渲染物理模型
BEV专栏(一)从BEVFormer深入探究BEV流程(上篇)
可见光遥感图像目标检测(三)文字场景检测之Arbitrary


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
2022-05-31 神经网络各个部分的作用 & 彻底理解神经网络