VanillaKD | 简单而强大, 对原始知识蒸馏方法的再审视
前言 本文介绍了vanilla KD方法,它在ImageNet数据集上刷新了多个模型的精度记录。
本文转载自AIWalker
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
近年来,知识蒸馏(KD)的种种改进策略不断问世,包括如何利用中间层特征和样本间的流型结构等。然而,目前大多数文章对知识蒸馏的测试仍停留在“较小数据集”和“较小模型”的水平。通常的测试方法是在CIFAR-100数据集上进行240个epoch的训练,或在ImageNet数据集上进行90个epoch的训练。这些测试存在着数据集规模过小或训练策略过弱的缺陷,无法准确评估知识蒸馏方法在复杂的实际应用场景中的性能。

华为诺亚的研究者们重新审视了近年来代表性的知识蒸馏方法,并从数据集大小、训练策略和模型参数量三个维度评估了它们对性能的影响。研究发现:
- 在大型数据集上,通过使用强训练策略进行充分训练后,原始知识蒸馏方法(vanilla KD)与现有最先进方法的性能相当。
- 在小型数据集上,无论训练策略的强弱,原始知识蒸馏方法始终显著弱于精心设计过的方法。
- 学生模型的参数量对评估结果没有显著影响。
基于这些观察,本研究仅使用vanilla KD方法,在ImageNet数据集上刷新了多个模型的精度记录,并发布了它们的模型参数:
- ResNet50:83.08%
- ViT-T:78.11%
- ViT-S:84.33%
- ConvNeXt v2-T:85.03%
知识蒸馏中的“小数据陷阱”
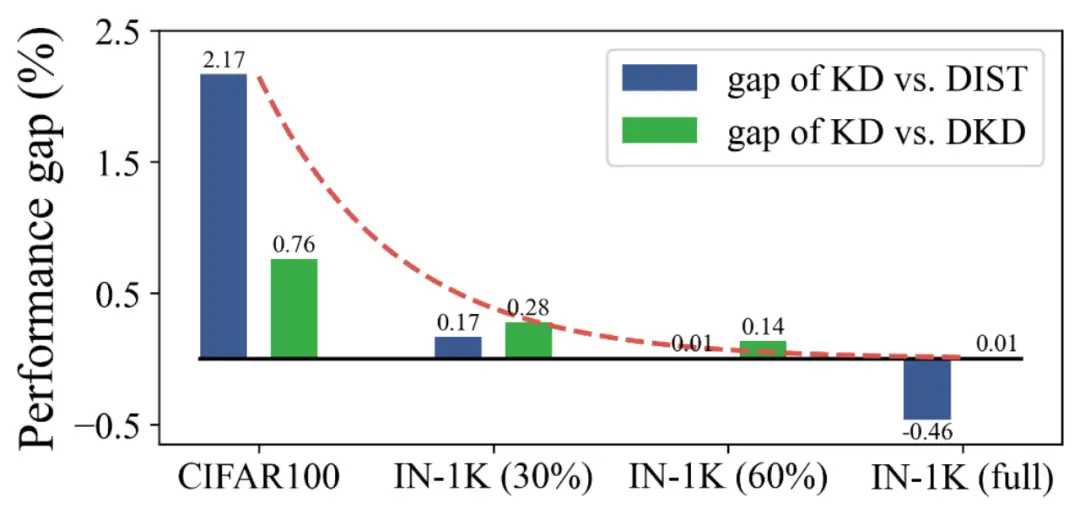
论文作者选取DKD[1]和DIST[2]作为基准知识蒸馏方法,比较了数据集大小、训练策略和模型参数量对知识蒸馏方法评估结果的影响。
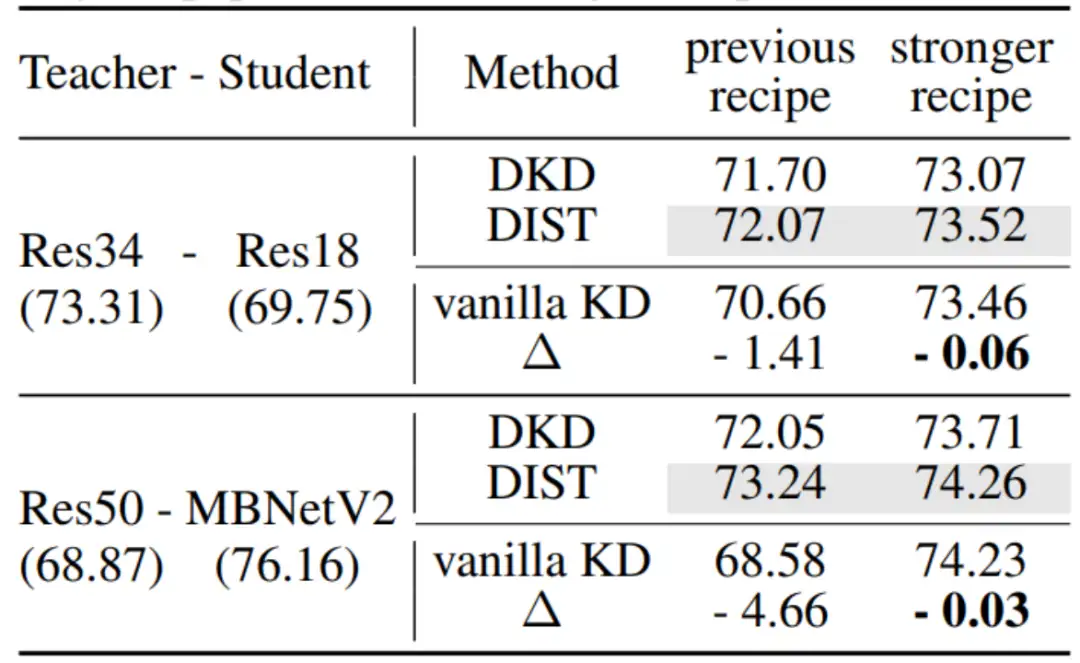
在ImageNet数据集上,使用更强的训练策略后,vanilla KD与SOTA方法之间的性能差距接近消失.
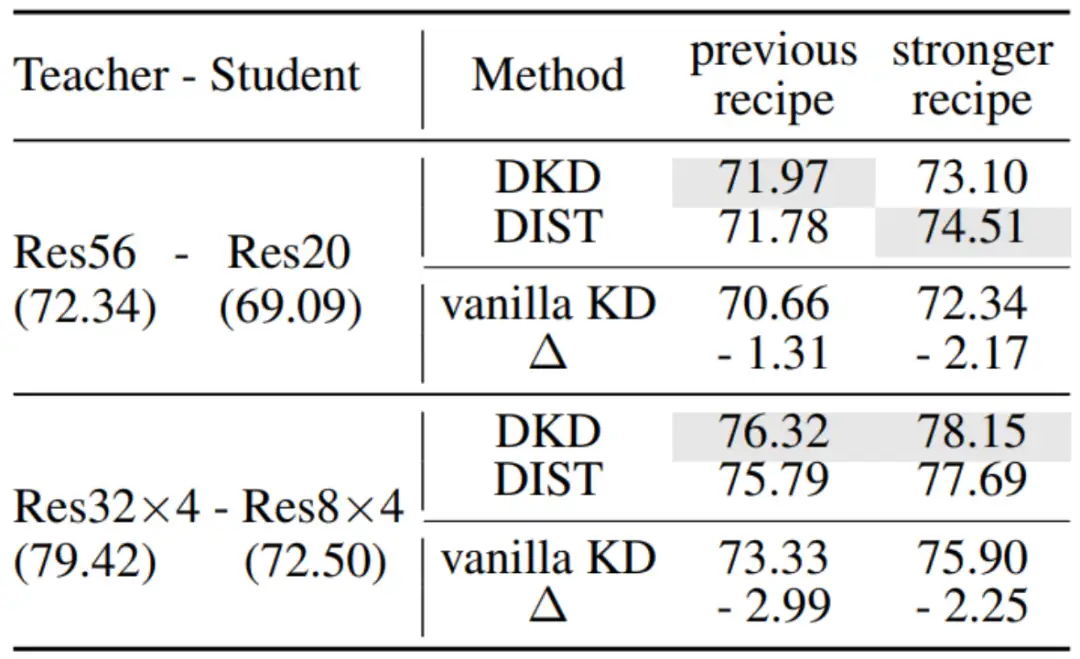
在CIFAR-100数据集上,即使增强训练策略也无法弥合vanilla KD与SOTA方法之间的性能差距.
基于以上观察,论文作者提出了小数据陷阱(small data pitfall)的概念,即仅依靠小规模数据集评估知识蒸馏方法会导致对性能的错误估计。考虑到现实应用场景中需要处理的数据规模通常远大于CIFAR-100数据集,这种错误估计可能会导致选择错误的方法,从而影响压缩后的模型性能。
探究vanilla KD的潜力
为进一步发掘vanilla KD的性能极限,作者在更多模型和KD方法上进行实验。
- 更大的学生模型
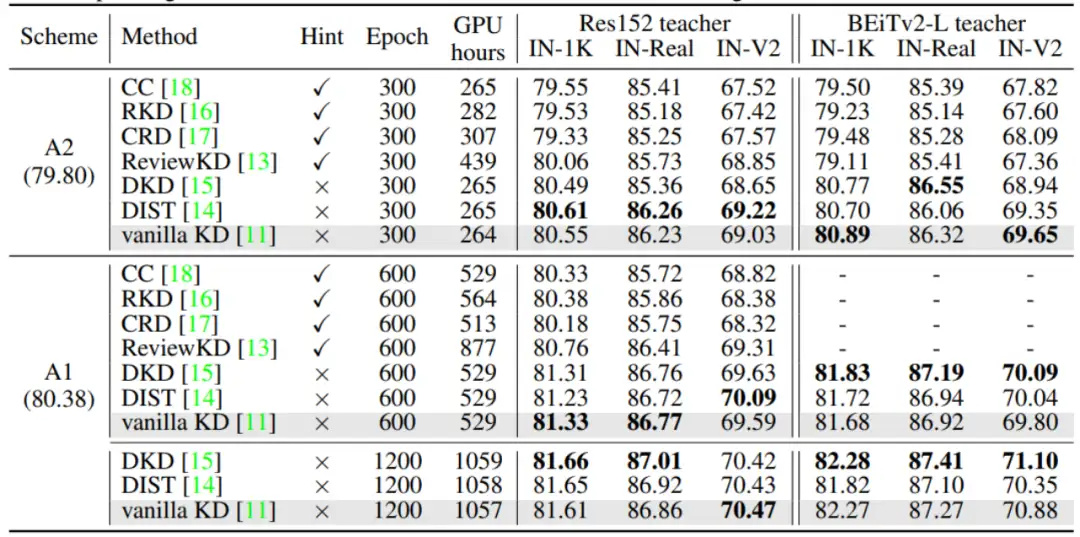
上表展示了使用ResNet50作为学生模型,ResNet152和BEiTv2-L作为教师模型时的结果。即使在更大的模型上,vanilla KD方法仍旧展现出与当前领先方法相当的性能。然而,基于Hint的中间层特征蒸馏方法的表现却不合人意。尽管该方法在计算资源方面消耗更多,但其表现明显弱于仅使用Logits的蒸馏方法。此外对比ResNet50和ResNet18作为学生模型得到的结论相似,表明了学生模型的参数量对评估结果没有显著影响。
- 更多的模型种类
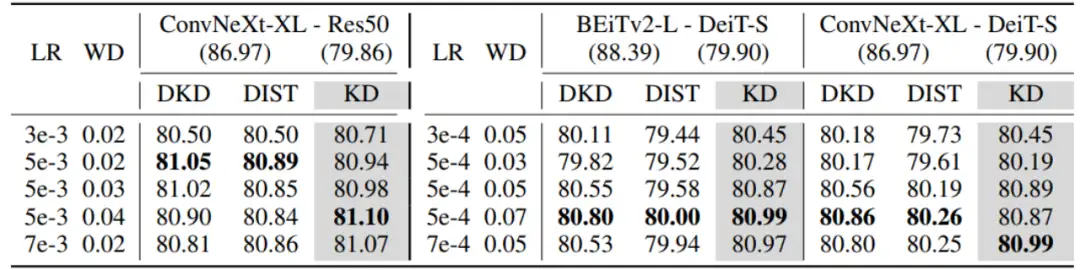
上表展示了更多教师模型与学生模型组合的结果。vanilla KD的表现优于DKD和DIST,说明前述结论并不局限于单一模型结构。
- 更长的训练轮数
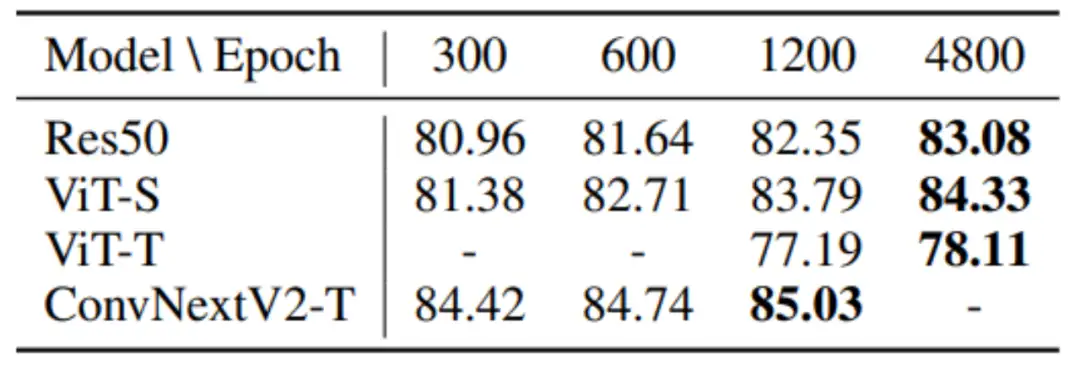
为了进一步探究vanilla KD的性能极限,论文作者使用ResNet50作为学生模型,BEiTv2-B作为教师模型,进一步增大了训练轮数设置。经过更加充分的训练后,作者们得到了ResNet50,ViT-T,ViT-S,和ConvNeXt v2-T模型在ImageNet上的新SOTA。
- 与MIM相比
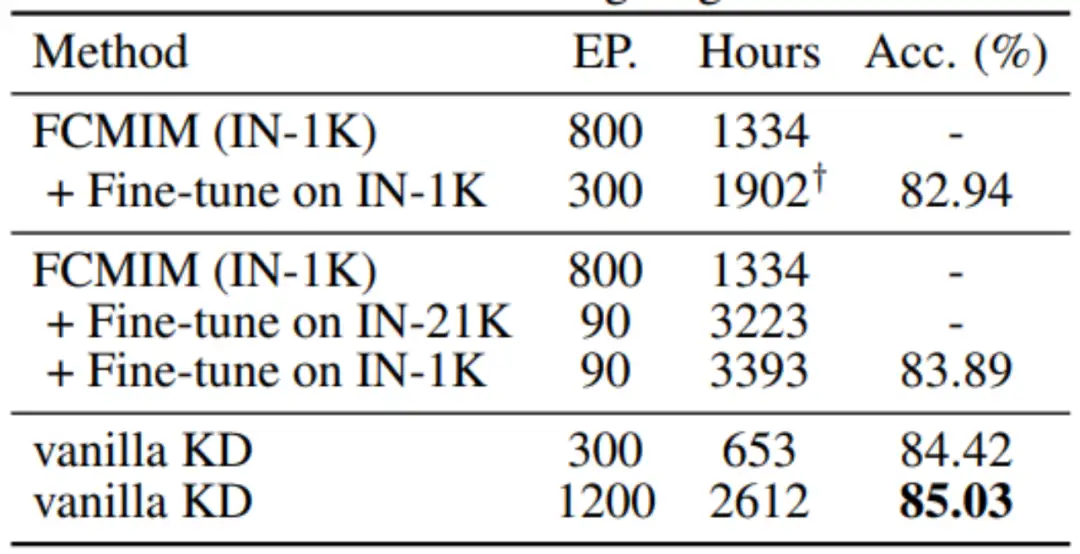
Mask image modeling(MIM)作为近期火热的预训练方法,能够使微调后模型达到更高精度。论文作者使用ConvNeXt v2-T作为学生模型,BEiTv2-B作为教师模型,将vanilla KD与MIM进行了比较。上表中的结果表明在同样的计算资源消耗下,vanilla KD能够取得显著优于MIM的结果。
- 迁移到下游任务
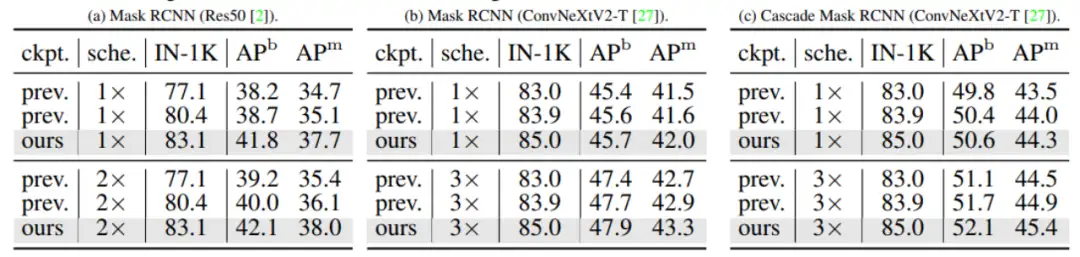
作者在COCO 2017 val上评估了使用vanilla KD蒸馏的backbone对性能的影响。如上表所示,学生模型在分类任务上得到的性能提升能够有效迁移到下游任务。
结论
本文从数据集大小、训练策略和模型参数量三个维度重新审视了知识蒸馏方法的评估过程,发现原始的知识蒸馏方法受到源自小规模数据和不充分训练策略的低估。在采用更强的数据增强和更大的数据集后,仅使用原始知识蒸馏方法训练的ResNet50,ViT-T,ViT-S,和ConvNeXt v2-T模型取得了新的SOTA性能,说明了原始的知识蒸馏方法尽管设计简单,却有实际应用的巨大潜力。
参考文献
- [1] Borui Zhao, Quan Cui, Renjie Song, Yiyu Qiu, and Jiajun Liang. Decoupled knowledge distillation. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
- [2] Tao Huang, Shan You, Fei Wang, Chen Qian, and Chang Xu. Knowledge distillation from a stronger teacher. In Advances in Neural Information Processing Systems, 2022.
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
YOLO终结者?百度最新RT-DETR:114FPS实现54.8AP,远超YOLOv8!
全新YOLO模型YOLOCS来啦 | 面面俱到地改进YOLOv5的Backbone/Neck/Head
CVPR 2023 | 神经网络超体?新国立LV lab提出全新网络克隆技术
6G显存玩转130亿参数大模型,仅需13行命令,RTX2060用户发来贺电
libtorch教程(一)开发环境搭建:VS+libtorch和Qt+libtorch
NeRF与三维重建专栏(三)nerf_pl源码部分解读与colmap、cuda算子使用
NeRF与三维重建专栏(二)NeRF原文解读与体渲染物理模型
BEV专栏(一)从BEVFormer深入探究BEV流程(上篇)
可见光遥感图像目标检测(三)文字场景检测之Arbitrary

 浙公网安备 33010602011771号
浙公网安备 33010602011771号