NeRF与三维重建专栏(一)领域背景、难点与数据集介绍
前言 关于该系列专栏,主要介绍NeRF在三维重建中的应用(这里我们特指MVS,multi-view stereo,也即输入带位姿的图片,输出三维结构例如点云、mesh等;并且后面的工作也都是围绕MVS with NeRF讨论的。虽然也有without pose的NeRF,从重建的角度也可以理解为SFM with NeRF,例如ESLAM,Barf,但不是本专栏关注的重点),一方面是为了整理回顾一下现有资料,一方面是为了方便广大初学者更快了解NeRF如何应用于三维重建。
本系列专栏大致分为背景介绍、代码开发相关、主要论文讲述三部分;所用编程语言大部分为python,包含少量cuda;使用深度学习框架为pytorch lightning;需要读者有多视几何/射影几何基础知识。
本教程禁止转载。同时,本教程来自知识星球【CV技术指南】更多技术教程,可加入星球学习。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
本篇博客将会介绍三维重建背景、NeRF应用到三维重建的主要难点与相关数据集。同时会对专栏后续讲解内容做一个概述,如下图所示:
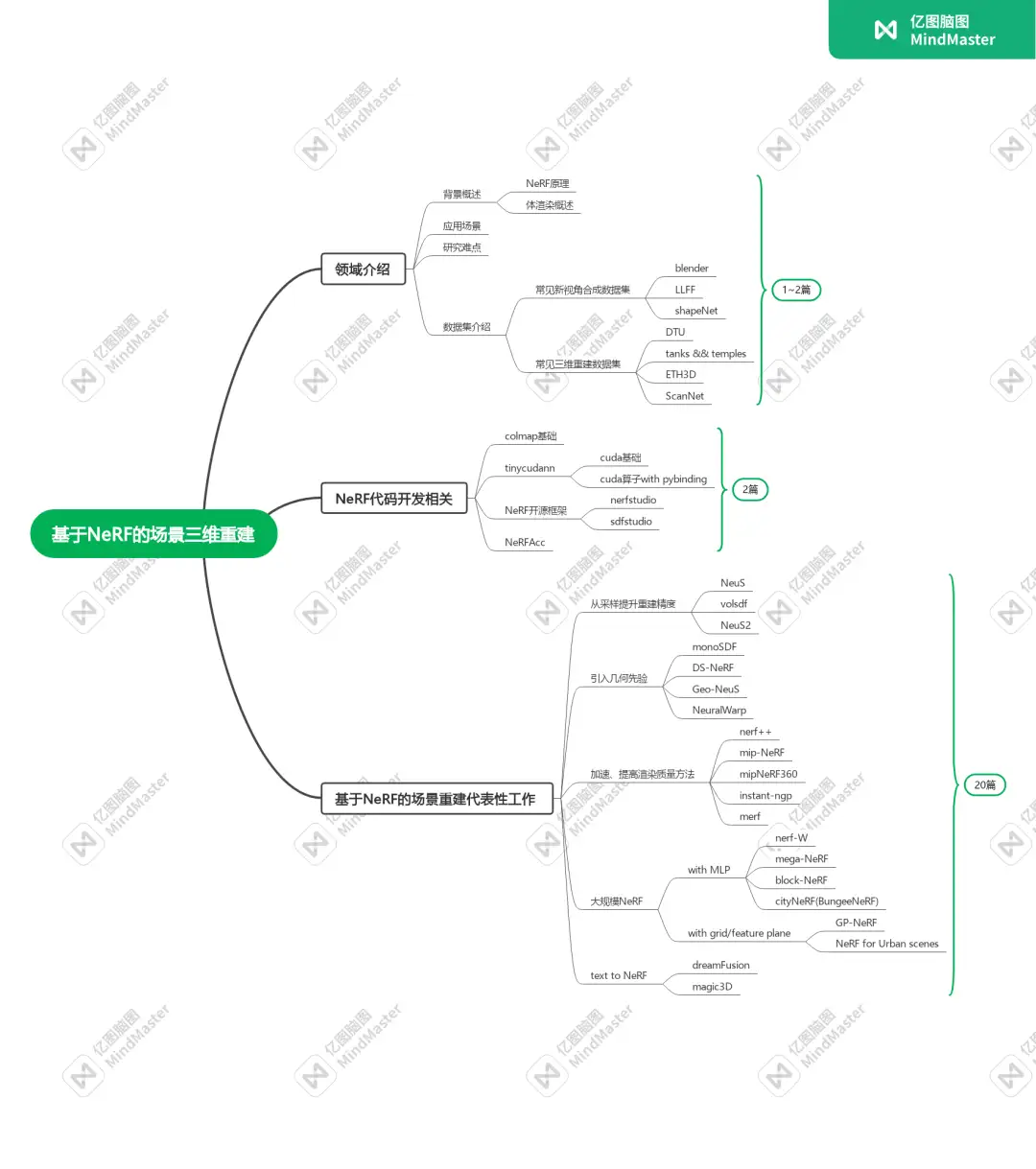
其中背景介绍部分我们将会用两篇博客来概括一下背景、应用场景、领域难点、NeRF类重建方法的常用数据集和评估指标以及NeRF原文解读和物理模型讲解;
代码开发部分我们将会用两到三篇来着重介绍一下colmap的安装、使用;tinycudann与cuda算子的安装与使用;NeRF开源框架与NeRFAcc的安装与使用;
在论文介绍部分,我们会选取20篇具有代表性的工作着重讲解其中的数学原理、思路以及效果,部分工作会解读源码。
三维重建背景
三维重建的整个pipeline可以表示为下图:
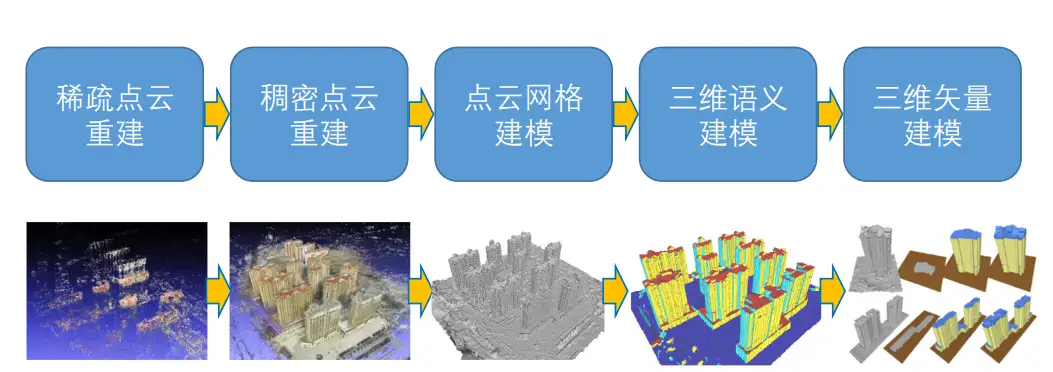
现在在稀疏点云重建中(SFM,structure from motion,通过图片、激光雷达等获得图片对应的位姿以及稀疏点云),几何方法稳居统治地位,无论是工业化程度还是sota的精度都稳居榜首;
在稠密点云重建中(MVS,multi-views stereo,通过图片、激光雷达等与对应的位姿,生成场景/物体的三维结构例如点云、mesh、深度图),该领域中已有深度学习方法在小场景上超越了几何方法,其中以MVSNet为baseline的深度学习方法和以NeRF为baseline的隐式表达+可微渲染方法为大众熟知;
三维语义建模与三维矢量建模领域中,相关研究人员相对较少,工业场景以传统几何方法为主导,学术圈以生成式方法为代表的深度学习方法为主导。
应用场景
三维重建的应用场景十分广泛,而NeRF作为一种新兴的新视图合成方法也具有很广阔的应用场景。三维重建技术可以用来创建建筑和工程项目的三维模型,以便进行设计、可视化和规划;也可以用来创建电影和游戏中的虚拟场景和角色,并实现逼真的物理效果和互动体验;同时也能用来创建机器人的三维模型,以便进行模拟和控制,同时也可以用来优化制造流程和生产线。而新视图合成可以被广泛地应用于虚拟现实、增强现实等领域。可以用来生成电影和游戏中的新视角或新视角序列,以增强视觉效果和观众体验;也能用来生成自动驾驶系统中的新视角或新视角序列,以提高车辆的感知和决策能力,同时能用来生成监控和安防摄像头在不同位置或角度下的新视角或新视角序列,以提高监测和识别的效果。


主要难点
在深度学习大火的今天,三维领域属于为数不多的传统方法还能和DL方法打个五五开的领域,但截止2023年来看,无论是重建的精度、速度还是完整性,几何方法都渐渐落后于深度学习方法。在几何方法中,主要难点为以下几点:
弱纹理/无纹理:由于传统MVS以patch Match和SGM(semi-global Matching)方法为主,这两者都需要计算局部一个小patch的NCC代价以计算深度,因此在遇到大尺度的无纹理/弱纹理区域时,不同像素点的NCC代价会趋于一致,从而影响后续计算;针对该问题,也有部分方法加入了多尺度约束以降低无纹理/弱纹理区域的歧义性,例如ACMM;
完整性:几何方法在估计完深度图之后会有filter与fusion的操作以去除置信度不高的点,这一过程会造成点云的缺失,进而影响后续mesh的构建;同时由于patch Match/SGM算法的问题,对细长物体的深度估计往往不那么准确;
重建速度:虽然大部分MVS方法都是离线重建,但也会关注重建的速度,以Gipuma为代表的并行式方法很大程度上缓解了这一问题,且显存消耗也远小于深度学习方法;
而应用于三维重建的NeRF类方法,在面对同样的场景时,会有以下难点:
弱纹理/无纹理:由于NeRF类方法采用了基于三维点采样的体渲染方法,在局部弱纹理区域,同样会面临多个采样点颜色一致导致歧义的问题(例如NeuS在对魔方的重建上);但由于神经网络自带平滑性,在完整性这一点上深度学习方法都表现的比较好;
大规模精度:虽然在小场景/室内场景上,NeRF类方法已经打平甚至超越了几何方法,但是在大场景上,由于网络学习容量/光照/图像畸变被放大等因素,NeRF类方法还没有较好的解决思路,现阶段大多是以提高渲染质量为主;
重建速度/显存消耗:vanilla NeRF训练一次的时间是以天为单位的,虽然后续有了加速方法,能实现以秒为单位的训练,但在显存开销与精度上,往往需要有所取舍。
对于NeRF重建的思想与几何重建思想有何不同,我们需要明确的是,NeRF属于可微渲染领域中的一个方法,这类方法的思路可以概括为,通过某种表达(可以是点云、mesh、图元、神经网络等)经过可微的渲染途径得到渲染图像;将渲染图像与真实图像作差得到loss;再通过梯度反向传播以修正表达,最终得到几何一致的三维表达与photo-realistic的渲染图像:
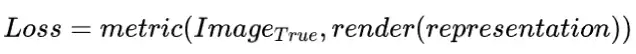
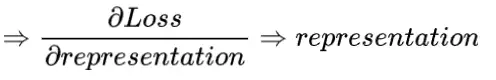
而几何重建(这里主要指基于深度图融合的方法,例如patch match,semi-global matching)是利用多视几何相关理论,通过NCC匹配代价确定两幅/多幅图像的同名像素点,从而估计出深度,这个过程是不可微的(当然也有深度学习方法将其可微化例如MVSNet,但这里不是我们的重点)。
相关数据集以及评估指标
本节将会介绍新视图合成与三维重建的常用数据集以及评估指标:
相关数据集
1.Blender
准确来说这不是一个数据集而是一个图形学工具,可以用于3D 建模、UV 映射、纹理、数字绘图、光栅图形编辑等。对于新视图合成来说其意义在于用已经成熟的渲染管线来检验方法的有效性,但由于是合成图像,真实空间特有的噪声等数据没办法模拟,对于重建来说其意义不大,因此这里不多赘述。NeRF所使用的合成数据集可以参考这里
2.LLFF
LLFF由手持手机摄像头拍摄的 24 个真实场景组成。每张图像都面向中心对象。每个场景包含 2030 张图,并采用COLMAP来估计每一张图像的位姿。该项目同样提供了如何构建自己拍摄的数据集教程。通过仓库中的download_data.sh可以下载其数据集。也可以点击此处
LLFF论文

3.ScanNet
ScanNet是一个大型真实RGB-D多模式数据集,包含超过250万张室内场景图片,1500个场景,带有相应的相机位姿、mesh模型、语义标签、实例标签和CAD模型。深度图以640×480分辨率拍摄,RGB图像以1296×968分辨率拍摄。3D模型由BundleFusion重建得到。
使用该数据集需要向作者申请,然后会收到一个python脚本,按照仓库中的README提示做就可以了。(CSDN上也有脚本可以下载,但是在公共平台发表相关成果时一定要发邮件)
ScanNet主页

4.DTU
DTU数据集是一个使用安装有相机和结构光扫描仪的6轴工业机器人拍摄的MVS数据集。机器人提供了精确的相机定位。使用MATLAB校准工具箱仔细校准相机位姿与内参。由结构光扫描仪提供稠密点云。原始论文的数据集由80个场景组成,每个场景包含49个视图,这些视图在围绕中心对象的半径为50厘米的球体上采样。对于其中的21个场景,在65厘米的半径范围内对另外15个摄像机位置进行了采样,总共有64个视图。整个数据集包含44个额外的场景,这些场景以90度间隔旋转和扫描了四次。场景照明使用16个LED进行变化,具有七种不同的照明条件。图像分辨率为1600×1200
DTU论文

5.tanks and temples
Tanks and Temples 数据集是视频数据集的3D重建。它由14个场景组成,包括“坦克”和“火车”等单个物体,以及“礼堂”和“博物馆”等大型室内场景。3D数据真值是使用高质量工业激光扫描仪捕获的。点云真值用于使用对应点的最小二乘优化来估计相机位姿。
tanks and temples论文

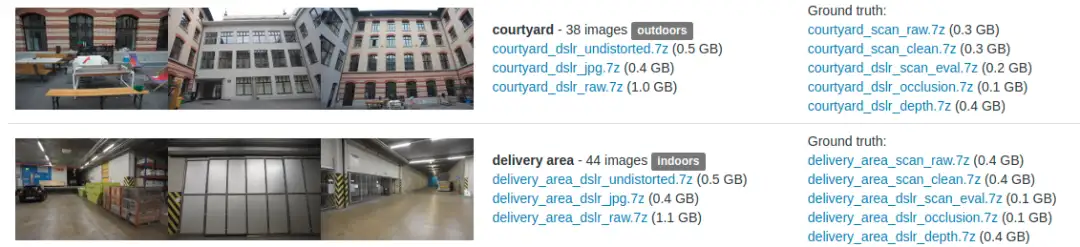
6.ETH3D
ETH3D数据集由多个不同的子数据集组成,包括建筑物、自然景观、室内场景、工业和机械场景等。每个子数据集都包含多个相机拍摄的图像序列,以及每个图像的相机参数和相对姿态信息。ETH3D还提供了一个在线评估平台,用于评估不同三维重建算法的性能。也是三维重建领域最具有挑战性的一个数据集
ETH3D论文
7.ShapeNet
ShapeNet是一个合成数据集,该数据集包含了超过50个语义类别的物体,包括家具、车辆、动物、食品等。每个物体的形状都以三维网格形式存储,每个网格由数百至数千个三角形组成。此外,ShapeNet还提供了每个物体的元数据信息,例如语义类别、尺寸、材料、颜色等。对于ShapeNet CAD模型,可以用Blender等软件来渲染虚拟相机的视图。注意使用这个数据集需要注册。
ShapeNet论文

评估指标
1.PSNR(peak signal-to-noise ratio)
PSNR是一种用于衡量图像、视频等多媒体数据重构质量的指标,它是峰值信噪比的简称。PSNR通常用于评估压缩算法的效果,也可以用于评估其他信号处理算法的效果。计算公式如下:
其中为图像的可能最大像素值,例如8位png为255,16位png为65535;为所有颜色通道上计算的像素均方误差,也即原始图像与渲染图像之间像素差的平方的平均值。该值越高,则重构质量越好,其在30-40dB之间被认为是高质量的,40dB以上则是极高质量的。
可引用第三方库skimage:
from skimage.metrics import peak_signal_noise_ratio as psnr
import cv2
import numpy as np
def load_img(filepath):
img = cv2.cvtColor(cv2.imread(filepath), cv2.COLOR_BGR2RGB)
img = img.astype(np.float32)
img = img / 255.
return img
img_render = load_img('path/to/img_render.png')
img_true = load_img('path/to/img_true.png')
psnr_loss = psnr(img_true,img_render)
2.SSIM(Structural Similarity Index)
SSIM是一种用于衡量两幅图像之间相似性的指标。SSIM通过比较两幅图像的亮度、对比度和结构信息来计算它们的相似性。它包括三个方面的信息,分别是亮度相似性、对比度相似性和结构相似性。公式如下:
其中与分别表示图像与图像的像素值均值,与表示两幅图像的像素方差,表示两幅图像的协方差,,为图像的像素值范围(8位png为255,16位png为65535),且;该值位于之间,SSIM越高,表明相似性越高。
可引用第三方库skimage:
from skimage.metrics import structural_similarity as ssim
import cv2
import numpy as np
def load_img(filepath):
img = cv2.cvtColor(cv2.imread(filepath), cv2.COLOR_BGR2RGB)
img = img.astype(np.float32)
img = img / 255.
return img
img_render = load_img('path/to/img_render.png')
img_true = load_img('path/to/img_true.png')
ssim_loss = ssim(imgtrue,img_render,channel_axis=-1)
3.LPIPS(Learned Perceptual Image Patch Similarity)
LPIPS是一种衡量图像相似性的指标,与传统的图像相似度度量方法(如PSNR和SSIM)不同,LPIPS是通过深度学习的方式学习到了一种能够更好地模拟人类视觉系统的图像相似度度量方法。具体来说,LPIPS使用了一个经过预训练的深度卷积神经网络来提取图像的特征,并根据这些特征计算图像的相似度。计算公式如下:
其中,表示像素坐标的高,表示像素坐标的宽,表示像素所在的特征层,表示第层的权重,与表示图像与图像经过特征提取网络提取后的特征,一般采用VGGNet、ResNet等网络提取。因为使用不同的特征提取会有不同的特征空间,因此LPIPS的范围不固定,但越接近0,表示两幅图像越相似
由于计算比较麻烦,可以引用第三方库lpips
pip install lpips
import lpips
import cv2
import numpy as np
def load_img(filepath):
img = cv2.cvtColor(cv2.imread(filepath), cv2.COLOR_BGR2RGB)
img = img.astype(np.float32)
img = img / 255.
return img
img_render = load_img('path/to/img_render.png')
img_true = load_img('path/to/img_true.png')
lpips_fn = lpips.LPIPS(net='alex')#加载需要的模型,可以是'alex','vgg','vgg16','vgg16_l1'等
lpips_loss = lpips_fn(img_true, img_renderg)
4.CD(Chamfer Distance)
Chamfer distance是一种常用的点云或mesh重建模型评估指标,它度量两个点集之间的距离,其中一个点集是参考点集,另一个点集是待评估点集。它的计算方法是对于每个参考点,找到距其最近的待评估点,计算它们之间的距离,并将这些距离求和,然后对于待评估点集中的每个点,同样找到距离其最近的参考点,计算它们之间的距离,并将这些距离求和,最终将两个和相加得到Chamfer distance。计算公式如下:
其中和分别表示两个点云或者mesh的点集。由于我们用NeRF类方法训练完毕后,得到的是一个网络(通常是SDF场,也即)而非mesh模型,因此我们通常需要使用marching cubes算法来提取mesh,该算法是将空间分割为分辨率为resolution的grid,grid的每个方格点会通过sdf_func得到一个对应的sdf值;若一个小voxel的八个角点有异号,则在voxel的各边通过一阶插值找到零点,将若干零点首尾连接得到近似的零水平面,因此分辨率越高,得到的mesh越精准,这个分辨率和神经网络的输入空间scale有关:
pip install mcubes
pip install trimesh
#以下参考自NeuS代码:https://github.com/Totoro97/NeuS/blob/main/models/renderer.py
import mcubes
import trimesh
import numpy as np
def extract_fields(bound_min, bound_max, resolution=512, sdf_func):
N = 64
X = torch.linspace(bound_min[0,0], bound_max[0,0], resolution).split(N)
Y = torch.linspace(bound_min[0,1], bound_max[0,1], resolution).split(N)
Z = torch.linspace(bound_min[0,2], bound_max[0,2], resolution).split(N)
u = np.zeros([resolution, resolution, resolution], dtype=np.float32)
with torch.no_grad():
for xi, xs in enumerate(X):
for yi, ys in enumerate(Y):
for zi, zs in enumerate(Z):
xx, yy, zz = torch.meshgrid(xs, ys, zs)
pts = torch.cat([xx.reshape(-1, 1), yy.reshape(-1, 1), zz.reshape(-1, 1)], dim=-1)
val = sdf_func(pts).reshape(len(xs), len(ys), len(zs)).detach().cpu().numpy()
u[xi * N: xi * N + len(xs), yi * N: yi * N + len(ys), zi * N: zi * N + len(zs)] = val
return u
def extract_geometry(bound_min, bound_max, resolution=512, threshold, sdf_func):
# threshold=2.0
print('threshold: {}'.format(threshold))
u = extract_fields(bound_min, bound_max, resolution, sdf_func)#获得体网格,网格单元为SDF值
vertices, triangles = mcubes.marching_cubes(u, threshold)#阈值一般设为0
b_max_np = bound_max.detach().cpu().numpy()
b_min_np = bound_min.detach().cpu().numpy()
vertices = vertices / (resolution - 1.0) * (b_max_np - b_min_np)[None, :] + b_min_np[None, :]
return vertices, triangles
#提取网格ply,需要提供bound_min,bound_max,sdf_func
vertices, triangles =\
extract_geometry(bound_min, bound_max, resolution=512, threshold=0,sdf_func)
mesh = trimesh.Trimesh(vertices, triangles)
mesh.export('path/to/mesh.ply')
然后若有mesh的真值,可以通过trimesh库计算CD:
import numpy as np
import trimesh
from scipy.spatial.distance import cdist
# 加载mesh
mesh_true = trimesh.load("true.ply")
mesh_learned = trimesh.load("learned.ply")
# 得到mesh顶点
points_true = mesh_true.vertices
points_learned = mesh_learned.vertices
#计算mesh_true每个顶点到mesh_learned每个顶点距离
distances = cdist(points_true, points_learned)#
# 计算CD
min_distances = np.min(distances, axis=1)
chamfer_distance = np.mean(np.concatenate([np.min(cdist(points1, points2), axis=1), np.min(cdist(points2, points1), axis=1)]))
预告
本章大致介绍了三维重建背景、NeRF应用于三维重建的主要难点与相关数据集和评估指标,下一章我们将介绍NeRF原文,并探讨体渲染物理模型与NeRF体渲染技术的联系。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
一次性分割一切,比SAM更强,华人团队的通用分割模型SEEM来了
CVPR'23|向CLIP学习预训练跨模态!简单高效的零样本参考图像分割方法
CVPR23 Highlight|拥有top-down attention能力的vision transformer
【CV技术指南】咱们自己的CV全栈指导班、基础入门班、论文指导班 全面上线!!
CVPR 2023|21 篇数据集工作汇总(附打包下载链接)
CVPR 2023|两行代码高效缓解视觉Transformer过拟合,美图&国科大联合提出正则化方法DropKey
ViT-Adapter:用于密集预测任务的视觉 Transformer Adapter
CodeGeeX 130亿参数大模型的调优笔记:比FasterTransformer更快的解决方案
CVPR 2023 深挖无标签数据价值!SOLIDER:用于以人为中心的视觉
上线一天,4k star | Facebook:Segment Anything

 浙公网安备 33010602011771号
浙公网安备 33010602011771号