可复现、自动化、低成本、高评估水平,首个自动化评估大模型的大模型PandaLM来了
前言 随着越来越多的大模型问世,机器学习领域出现一个亟待解决的问题:如何实现保护隐私、可靠、可复现及廉价的大模型评估?
本文转载自机器之心
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
大模型的发展可谓一日千里,指令微调方法犹如雨后春笋般涌现,大量所谓的 ChatGPT “平替” 大模型相继发布。在大模型的训练与应用开发中,开源、闭源以及自研等各类大模型真实能力的评测已经成为提高研发效率与质量的重要环节。
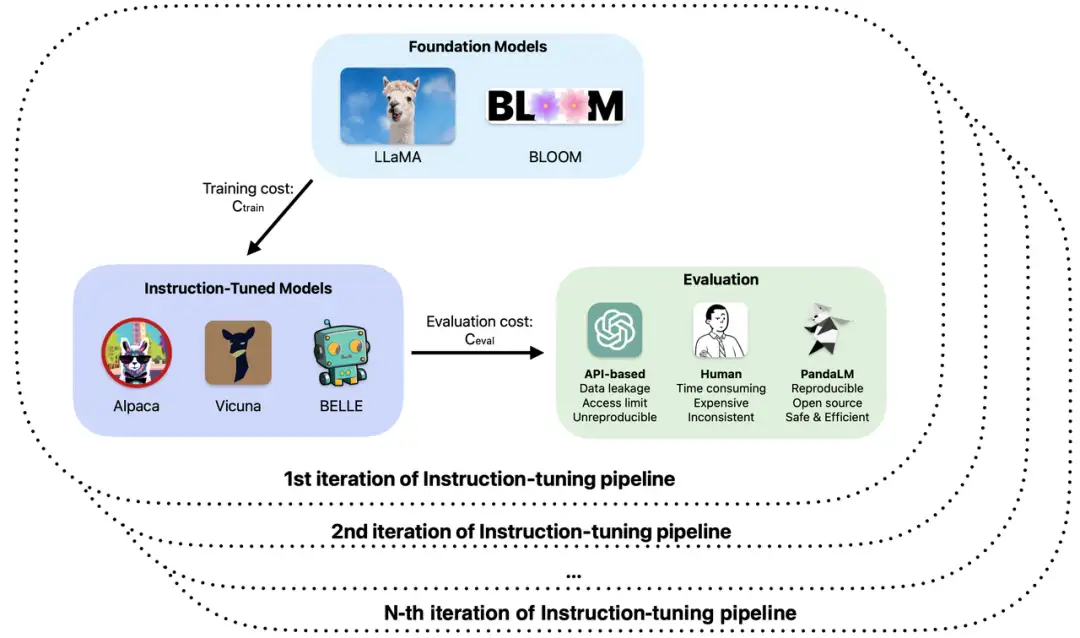
具体来说,在大模型的训练和应用中,大家可能遇到过以下问题:
1、在大模型微调或者增强预训练中使用了不同的基座和参数,根据观察到的样例效果,模型的表现在不同场景下各有优劣,如何确定在实际应用中使用哪个模型?
2、使用 ChatGPT 对模型输出进行评估,但是 ChatGPT 对相同输入在不同时间得到的评估结果不同,到底采用哪个评估结果?
3、采用人工标注对模型生成结果进行评测耗时费力,在经费预算有限和时间紧迫的情况下,如何加速评估过程并降低成本?
4、在处理机密数据时,不管用 ChatGPT/GPT4 还是标注公司进行模型评测都面临数据泄露问题,如何保证数据安全?
基于这些问题,来自北京大学、西湖大学等机构的研究者联合提出了一种全新的大模型评估范式——PandaLM。PandaLM 通过训练一个专门用于评估的大模型,对大模型能力进行自动化且可复现的测试验证。PandaLM 于 4 月 30 日在 GitHub 上发布,是全球首个评估大模型的大模型。相关论文会在近期公布。

GitHub地址:https://github.com/WeOpenML/PandaLM
PandaLM 旨在通过训练使得大模型学习到人类对不同大模型生成文本的总体偏好,并作出基于偏好的相对评价,以替代人工或基于 API 的评价方式,降本增效。PandaLM 的权重完全公开,可以在消费级硬件上运行,硬件门槛低。PandaLM 的评估结果可靠,完全可复现,并且能够保护数据安全,评估过程均可本地完成,非常适合学术界和需要保密数据的单位使用。使用 PandaLM 非常简单,只需三行代码即可调用。为验证 PandaLM 的评估能力,PandaLM 团队邀请了三位专业标注员对不同大模型的输出进行独立的优劣判断,并构建了包含 50 个领域、1000 个样本的多样化测试集。在此测试集上,PandaLM 的准确率达到了 ChatGPT 94% 的水平,且 PandaLM 产生了和人工标注相同的模型优劣结论。
PandaLM介绍
目前,主要有两种方式来评估大型模型:
(1)通过调用第三方公司的 API 接口;
(2)雇用专家进行人工标注。
然而,将数据传送给第三方公司可能导致类似三星员工泄露代码的数据泄露问题 [1];而雇佣专家标注大量数据既耗时又昂贵。一个亟待解决的问题是:如何实现保护隐私、可靠、可复现及廉价的大模型评估?
为了克服这两个评估方法的局限,该研究开发了 PandaLM,一个专门用于评估大型模型性能的裁判模型,并提供简便的接口,用户只需三行代码便可调用 PandaLM 实现隐私保护、可靠、可重复且经济的大型模型评估。关于 PandaLM 的训练细节,请参见开源项目。
为了验证 PandaLM 在评估大型模型方面的能力,研究团队构建了一个包含约 1,000 个样本的多样化人工标注测试集,其上下文和标签均由人类生成。在测试数据集上,PandaLM-7B 在准确度达到了 ChatGPT(gpt-3.5-turbo)的 94% 的水平。
如何使用 PandaLM?
当两个不同的大型模型针对相同的指令和上下文产生不同的回应时,PandaLM 的目标是比较这两个模型回应的质量,并输出比较结果、比较依据以及可供参考的回应。比较结果有三种:回应 1 更优;回应 2 更优;回应 1 和回应 2 质量相当。在比较多个大型模型的性能时,只需使用 PandaLM 进行两两比较,然后汇总这些比较结果来对模型的性能进行排名或绘制模型的偏序关系图。这样可以直观地分析不同模型之间的性能差异。由于 PandaLM 仅需在本地部署,且不需要人工参与,因此可以以保护隐私和低成本的方式进行评估。为了提供更好的可解释性,PandaLM 亦可用自然语言对其选择进行解释,并额外生成一组参考回应。
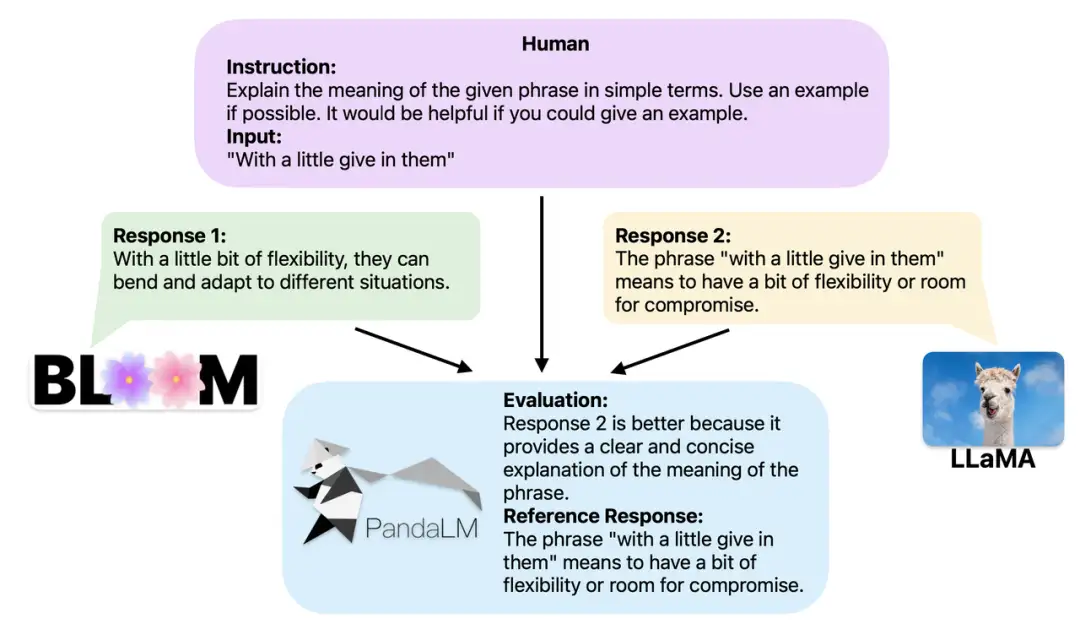
PandaLM 不仅支持使用 Web UI 以便于进行案例分析,还支持三行代码调用 PandaLM 对任意模型和数据生成的文本评估。考虑到许多现有模型和框架可能不是开源的或难以在本地进行推理,PandaLM 允许通过指定模型权重生成待评估文本,或直接传入包含待评估文本的 .json 文件。用户只需提供一个包含模型名称、HuggingFace 模型 ID 或 .json 文件路径的列表,即可利用 PandaLM 对用户定义的模型和输入数据进行评估。以下是一个极简的使用示例:

此外,为了让大家能够灵活地运用 PandaLM 进行自由评估,研究团队已在 HuggingFace 网站上公开了 PandaLM 的模型权重。通过以下命令,您可以轻松地加载 PandaLM-7B 模型:

PandaLM 的特点
PandaLM 的特点包括可复现性、自动化、隐私保护、低成本及高评估水平等。
1. 可复现性:由于 PandaLM 的权重是公开的,即使语言模型输出存在随机性,但在固定随机种子后,PandaLM 的评估结果仍会保持一致。而依赖在线 API 的评估手段由于更新不透明,其评估结果在不同时间可能不一致,且随着模型迭代,API 中的旧版模型可能无法再访问,因此基于在线 API 的评测往往不具有可复现性。
2. 自动化、隐私保护与低成本:用户只需在本地部署 PandaLM 模型,调用现成命令即可评估各类大模型,无需像雇佣专家那样需保持实时沟通且担心数据泄露问题。同时,PandaLM 整个评估过程中不涉及任何 API 费用以及劳务费用,非常廉价。
3. 评估水平:为验证 PandaLM 的可靠性,该研究雇佣了三名专家独立完成重复标注,创建了一个人工标注测试集。该测试集包含 50 个不同场景,每个场景下还包含多个任务。这个测试集是多样化、可靠且与人类对文本的偏好相一致的。测试集中的每个样本由指令与上下文,以及两个由不同大模型生成的回应组成,并由人类来比较这两个回应的质量。
该研究剔除了标注员间差异较大的样本,确保每个标注者在最终测试集上的 IAA(Inter Annotator Agreement)接近 0.85。需要注意的是,PandaLM 训练集与该研究创建的人工标注测试集完全无重叠。
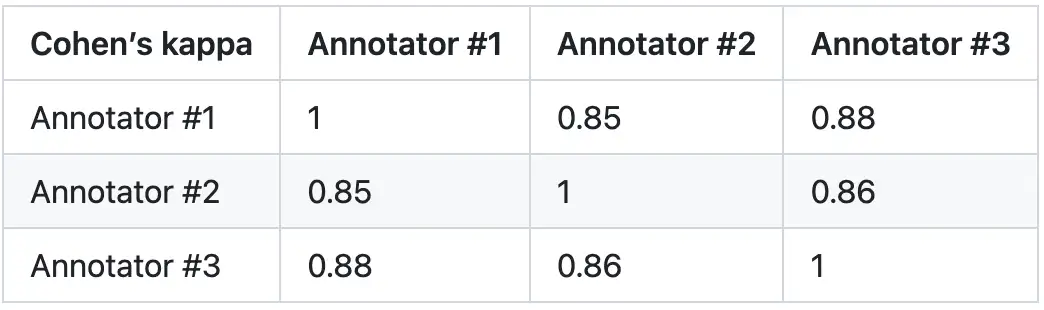
这些被过滤的样本需要额外的知识或难以获取的信息来辅助判断,这使得人类也难以对它们进行准确标注。经过筛选的测试集包含 1000 个样本,而原始未经过滤的测试集包含 2500 个样本。测试集的分布为 {0:105,1:422,2:472},其中,0 表示两个回应质量相似;1 表示回应 1 更好;2 表示回应 2 更好。
以人类测试集为基准,PandaLM 与 gpt-3.5-turbo 的性能对比如下:
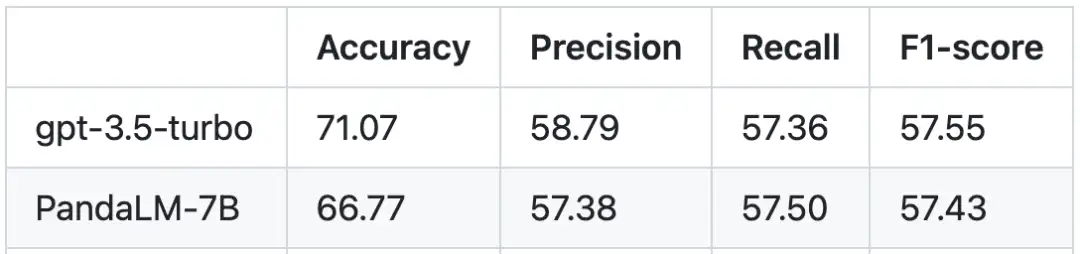
可以看到,PandaLM-7B 在准确度上已经达到了 gpt-3.5-turbo 94% 的水平,而在精确率,召回率,F1 分数上,PandaLM-7B 已于 gpt-3.5-turbo 相差无几。可以说,PandaLM-7B 已经具备了与 gpt-3.5-turbo 相当的大模型评估能力。
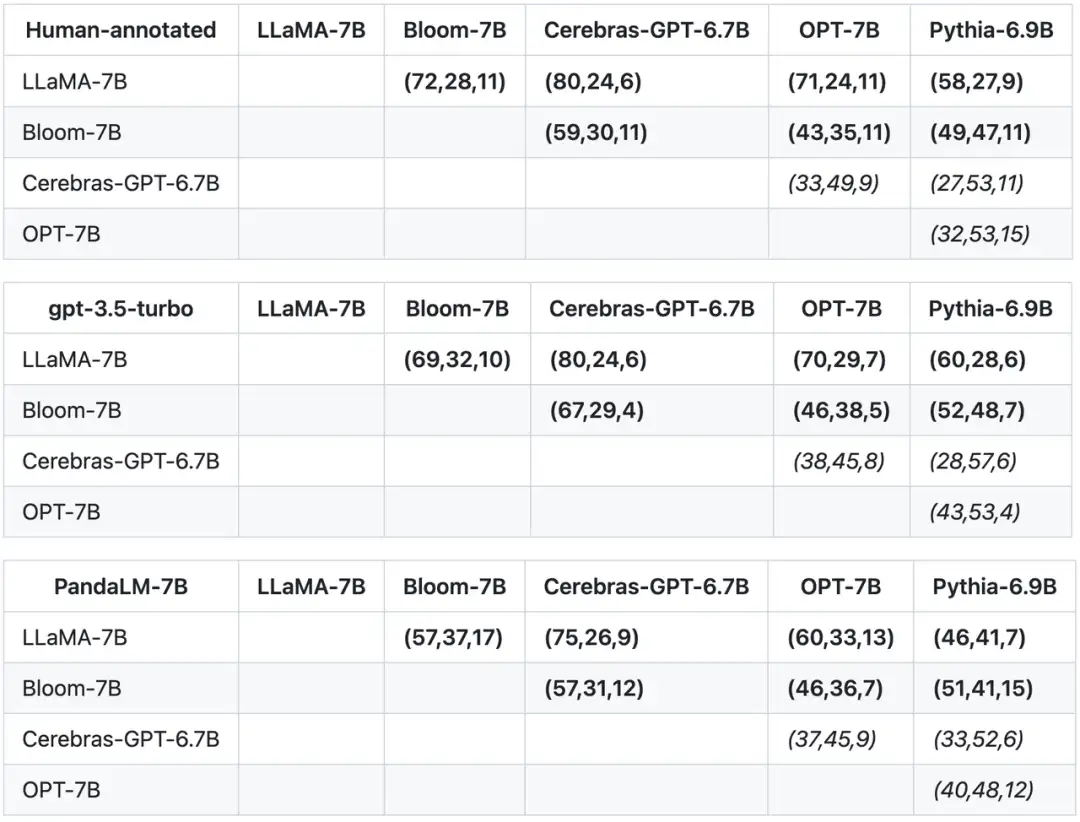
除了在测试集上的准确度,精确率,召回率,F1 分数之外,该研究还提供了 5 个大小相近且开源的大模型之间比较的结果。该研究首先使用了相同的训练数据对这个 5 个模型进行指令微调,接着用人类,gpt-3.5-turbo,PandaLM 对这 5 个模型分别进行两两比较。下表中第一行第一个元组(72,28,11)表示有 72 个 LLaMA-7B 的回应比 Bloom-7B 的好,有 28 个 LLaMA-7B 的回应比 Bloom-7B 的差,两个模型有 11 个回应质量相似。因此在这个例子中,人类认为 LLaMA-7B 优于 Bloom-7B。下面三张表的结果说明人类,gpt-3.5-turbo 与 PandaLM-7B 对于各个模型之间优劣关系的判断完全一致。
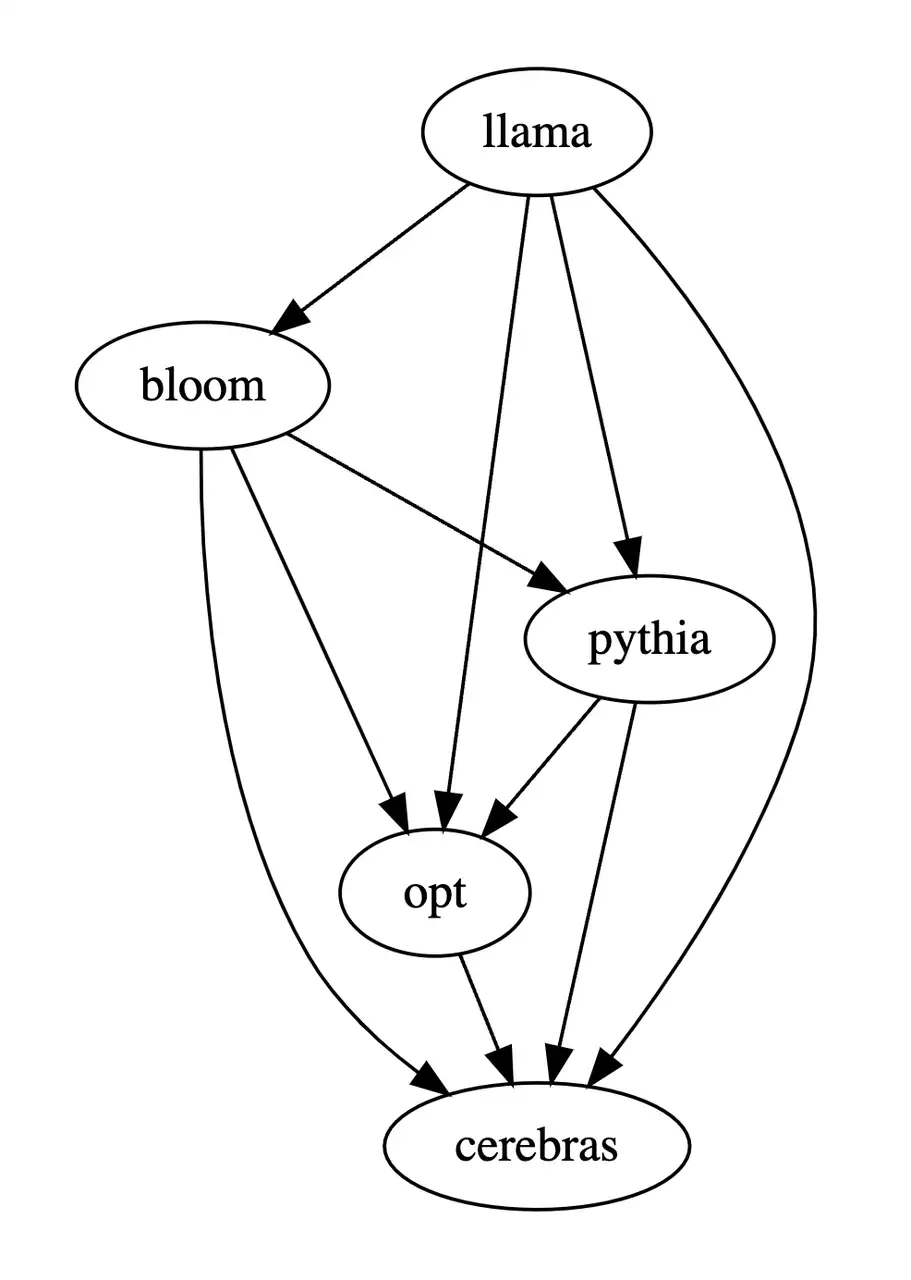
基于以上三张表,该研究生成了模型优劣的偏序图,这个偏序图构成了全序关系,可以表示为:LLaMA-7B > Bloom-7B > Pythia-6.9B > OPT-7B > Cerebras-GPT-6.7B。
总结
综上所述,PandaLM 为大模型评估提供了一种除人类评估与 第三方 API 之外的第三种选择。PandaLM 不仅具有高评估水平,而且结果具备可复现性,评估流程高度自动化,同时保护隐私且成本较低。研究团队相信 PandaLM 将推动学术界和工业界对大模型的研究,使更多人从大模型的发展中受益。欢迎大家关注 PandaLM 项目,更多的训练、测试细节、相关文章及后续工作都会公布在项目网址:https://github.com/WeOpenML/PandaLM
作者团队简介
作者团队中,王一栋* 来自北京大学软件工程国家工程中心(博士)和西湖大学(科研助理),于倬浩*、曾政然、蒋超亚、谢睿、叶蔚† 和张世琨† 来自北京大学软件工程国家工程中心,杨林易、王存翔和张岳† 来自西湖大学,衡强来自北卡莱罗纳州立大学,陈皓来自卡耐基梅隆大学,王晋东和谢幸来自微软亚洲研究院。* 表示共同第一作者,† 表示共同通讯作者。
引用
[1] https://www.infoq.cn/article/48HXL0qs8AowJxDgSpom
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
一次性分割一切,比SAM更强,华人团队的通用分割模型SEEM来了
CVPR'23|向CLIP学习预训练跨模态!简单高效的零样本参考图像分割方法
CVPR23 Highlight|拥有top-down attention能力的vision transformer
【CV技术指南】咱们自己的CV全栈指导班、基础入门班、论文指导班 全面上线!!
CVPR 2023|21 篇数据集工作汇总(附打包下载链接)
CVPR 2023|两行代码高效缓解视觉Transformer过拟合,美图&国科大联合提出正则化方法DropKey
ViT-Adapter:用于密集预测任务的视觉 Transformer Adapter
CodeGeeX 130亿参数大模型的调优笔记:比FasterTransformer更快的解决方案
CVPR 2023 深挖无标签数据价值!SOLIDER:用于以人为中心的视觉
上线一天,4k star | Facebook:Segment Anything

 浙公网安备 33010602011771号
浙公网安备 33010602011771号