CVPR'23|向CLIP学习预训练跨模态!简单高效的零样本参考图像分割方法
前言 本文提出了一种zero-shot的Referring image segmentation方法,该方法利用了来自CLIP的pre-train的跨模态知识。所提方法的性能明显优于所有基线方法和监督较弱的方法。
本文转载自极市平台
作者 | CV开发者都爱看的
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!

原文链接:https://arxiv.org/abs/2303.17811v1
代码链接:https://github.com/Seonghoon-Yu/Zero-shot-RIS
2. 引言
深度学习的最新进展彻底改变了计算机视觉和自然语言处理,并解决了视觉和语言领域的各种任务。CLIP 等多模态模型最近取得成功的一个关键因素是对大量图像和文本对进行对比图像文本预训练。尽管预训练的多模态模型具有良好的可迁移性,但处理密集的预测任务(例如对象检测和图像分割)并不简单。像素级密集预测任务具有挑战性,因为图像级对比预训练任务与像素级下游任务(如语义分割)之间存在很大gap。
Referring image segmentation是在给定描述区域的自然语言文本的情况下在图像中找到特定区域的任务,它是众所周知的具有挑战性的视觉和语言任务之一。为该任务收集注释更具挑战性,因为该任务需要收集目标区域的精确引用表达式及其密集的mask的标注。但是现有的仍然需要与目标数据集的图像相配对的注释才能够完成这一任务,并且该方法的性能远不及全监督方法。
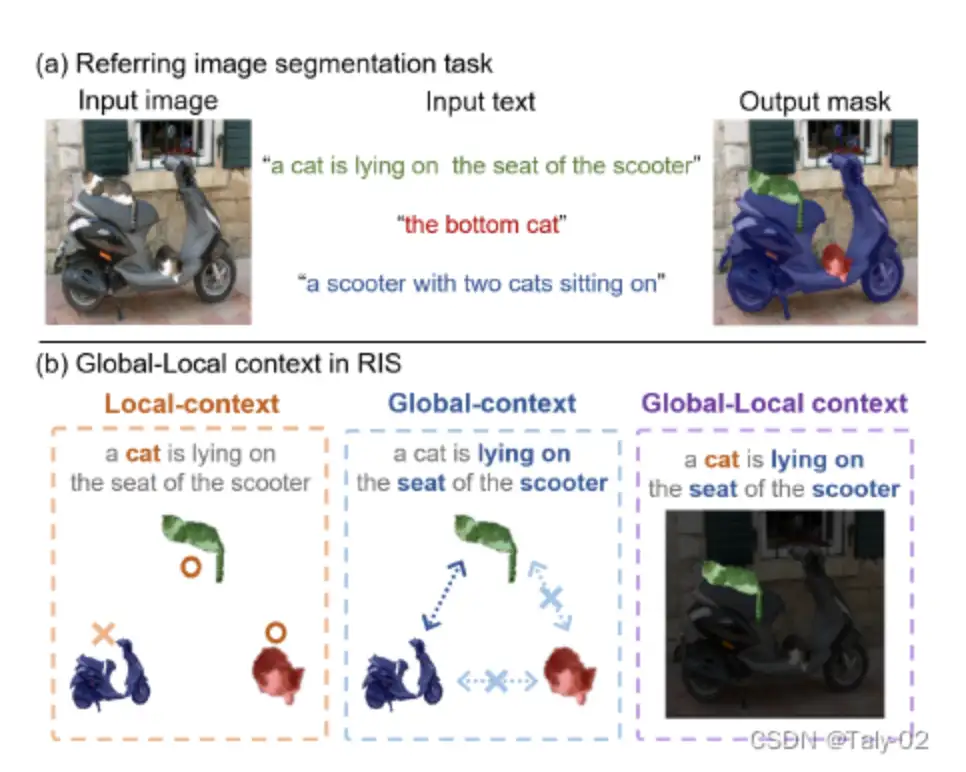
为了解决这个问题,在本文中,作者专注于从 CLIP 的预训练知识到参考图像分割任务的零样本迁移。此外,这项任务需要对语言的高层次理解和对图像的全面理解,以及密集的实例级预测。zero-shot的语义分割已经有几项工作,但它们不能直接扩展到zero-shot的Referring image segmentation任务,因为它具有不同的特征。具体来说,语义分割任务不需要区分实例,但参考图像分割任务应该能够预测实例级分割掩码。此外,在同一个类的多个实例中,只能选择表达式描述的一个实例。例如,在图 1 中,输入图像中有两只猫。如果输入文本为“一只猫躺在座位上的踏板车”,带有绿色面具的猫是正确的输出。要找到这个正确的mask,我们需要了解对象之间的关系(即“躺在座位上”)及其语义(即“猫”、“滑板车”)。
在本文中,我们使用来自 CLIP 的预训练模型完成了zero-shot的referring image segmentation,其中以一致的方式处理图像和表达式的global和local的context。为了在给定文本引用表达式的情况下定位图像中的object mask,我们提出了一种mask-guided visual encoder,该encoder在给定mask的情况下捕获图像的global和local的context需不需。我们还提出了一个global-local的text encoder,其中局部上下文由目标名词短语捕获,全局上下文由表达式的整个句子捕获。通过结合两个不同上下文级别的特征,我们的方法能够理解目标对象的综合知识和特定特征。请注意,虽然我们的方法不需要对 CLIP 模型进行任何额外的训练,但它优于所有基线和弱监督的参考图像分割方法,并且有很大的优势。
3. 方法
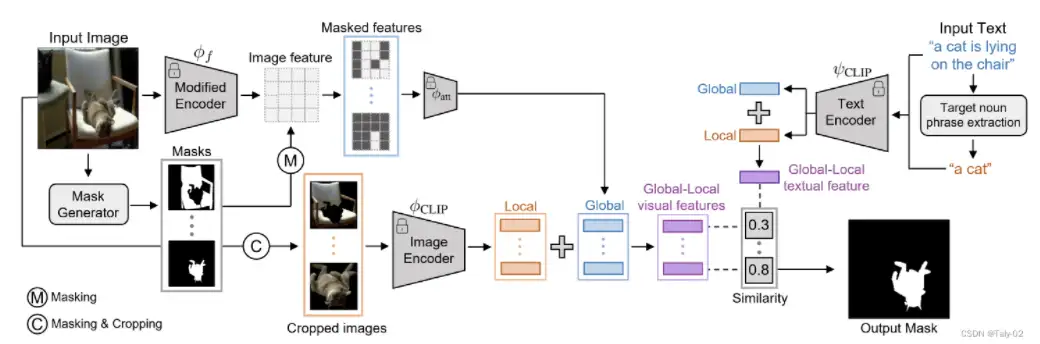
3.1 整体框架
本文提出了一种用于引用图像分割的框架,该框架使用CLIP在共享嵌入空间中学习图像和文本表示。该框架包括全局局部视觉编码器和全球局部自然语言编码器,用于全面表示被屏蔽区域和周围区域,并从句子中提取关键名词短语以聚焦目标对象本身。
我们的框架由两部分组成,如图上图 所示:
- 用于视觉表示的全局-局部视觉编码器
- 用于引用representation的全局-局部自然语言编码器。
给定一组由无监督mask生成器生成的mask proposals,我们首先为每个mask proposals提取global context和local context的两个视觉特征,然后将它们组合成一个feature。我们的global context可以全面表示mask区域以及周围区域,而local context可以捕获特定mask区域的表示。这在参考图像分割任务中起着关键作用,因为我们需要使用目标的综合表达来聚焦一个小的特定目标区域。同时,给定一个表达目标的句子,我们的text的特征由 CLIP 的text encoder提取。
对于优化目标,则是把text的feature和多个聚合起来的特征进行对齐:
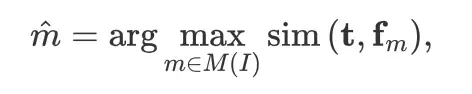
3.2 Mask-guided Global-local Visual Features
为了分割与指代目标表达相关的目标proposal,必须了解图像中多个对象之间的全局关系以及目标的局部语义信息。在本节中,将演示如何使用 CLIP 提取全局和局部上下文特征,以及如何融合它们。
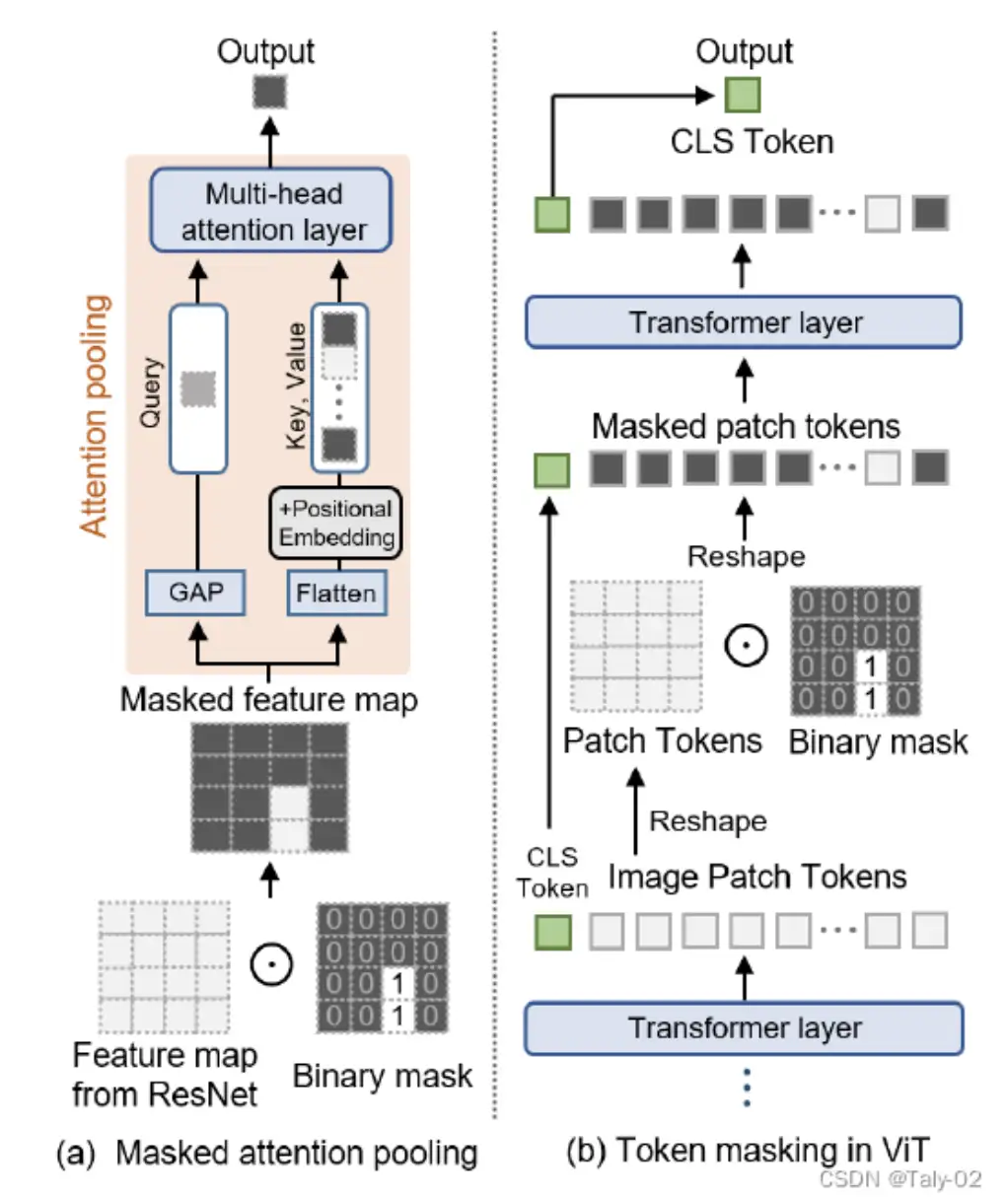
Global-context Visual Features:对于每个mask proposals,我们首先使用 CLIP 预训练模型提取全局上下文视觉特征。然而,CLIP 的原始视觉特征旨在生成一个单一的特征向量来描述整个图像。为了解决这个问题,我们修改了 CLIP 的visual encoder,以提取包含不仅来自屏蔽区域而且包含周围区域信息的特征,以理解多个对象之间的关系:
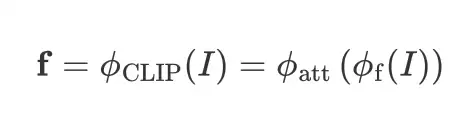
Local-context Visual Features:为了在给定掩码建议的情况下获得局部上下文视觉特征,我们首先mask image 然后裁剪图像以获得仅围绕 mask proposal 区域的新图像。裁剪和屏蔽图像后,它被传递到 CLIP 的视觉编码器以提取我们的Local-context Visual Features:
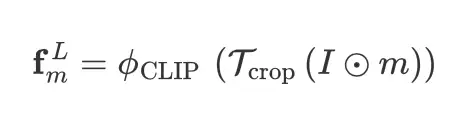
Global-local Context Visual features:
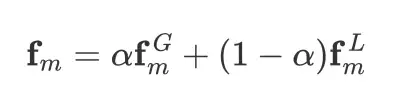
3.3 Global-local Textual Features
与视觉特征类似,重要的是要理解给定表达式中的整体含义以及目标对象名词。
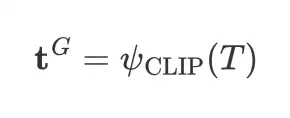
尽管 CLIP 文本编码器可以提取与图像级表示对齐的文本表示,但很难将注意力集中在表达式中的目标名词上,因为该任务的表达式是由包含多个从句的复杂句子构成的,例如 “脚凳后面的深棕色真皮沙发,上面有一台笔记本电脑”。
为了解决这个问题,我们利用 spaCy (一种大语言模型) 的依赖解析来找到目标名词短语 ,给定文本表达式 。为了找到目标名词短语,我们首先找到表达式中的所有名词短语,然后选择包含句子根名词的目标名词短语。在识别输入句子中的目标名词短语后,我们从 CLIP 文本编码器中提取局部上下文文本特征:
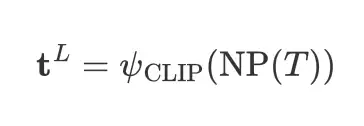
最后,我们的全局-局部上下文文本特征是通过等式 1 中描述的全局和局部文本特征的加权和来计算的。
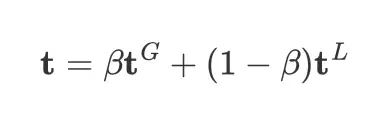
4. 实验
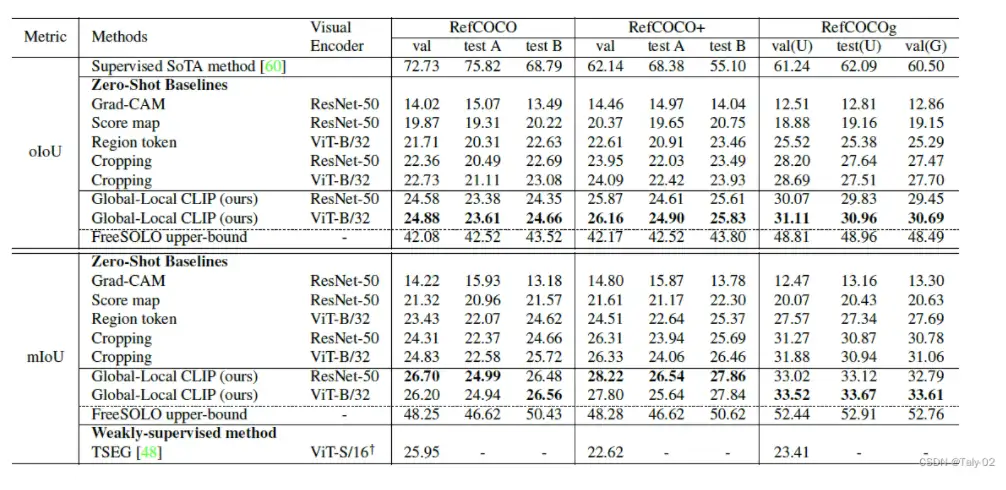
本文使用RefCoco、refCoco+和refCocog数据集来评估拟议的零镜头参考图像分割方法,这些数据集使用来自MS-COCO数据集的图像和mask进行注释。本文还使用COCO实例 GT 的mask将所提出的方法的性能与其他基准方法进行比较。
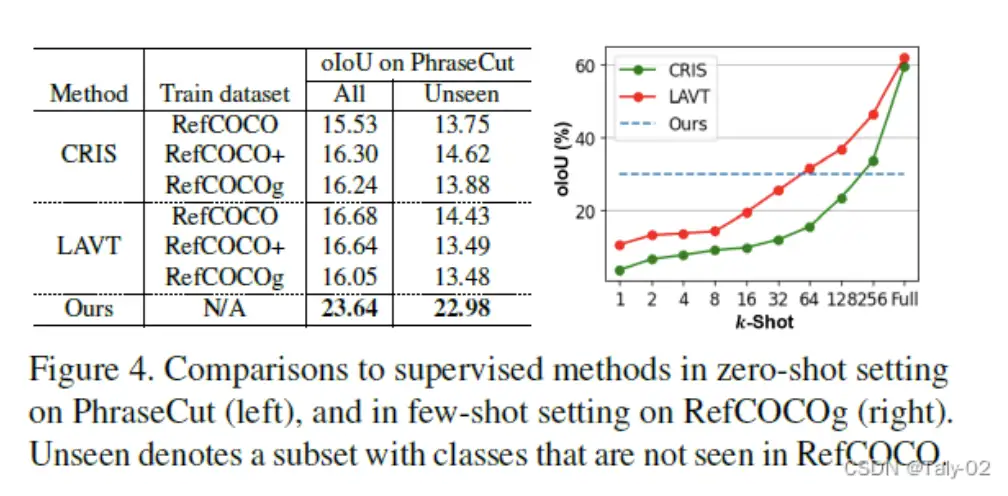
本文报告了拟议的零镜头参考图像分割方法的结果,并将其与RefCoco、refCoco+和refCocog数据集上的几种基准方法在oiou和miOU指标方面进行了比较。实验结果表明,在miOU方面,所提出的方法优于其他具有较大边距的基线方法,甚至超过了监督较弱的参考图像分割方法。该论文还报告了所提出的方法在MC-ACC和cc-oiou指标方面的详细结果。
对于指标,MC-ACC(掩码等级精度)和 cc-oioU(类别条件的 OioU)指标通过测量预测掩码相对于地面真相掩码的精度,帮助评估预测的掩码类别正确时的实例定位性能。MC-ACC 测量地面真相掩码和预测掩码之间匹配对象类别的比率。cc-oiou 测量预测掩码类别正确的一部分示例的实际掩码和预测掩码之间的交叉点 (iOU)。这些指标有助于评估所提出的方法在实例本地化精度方面的性能。

提出的全局局部功能允许通过捕获目标对象语义以及对象之间的关系来利用视觉和文本特征。全局功能捕获了整个输入表达式的复杂句子级语义,而局部功能则侧重于依赖关系解析器提取的目标名词短语。通过结合这些特征,所提出的方法获得了较高的MC-ACC和cc-OIOU分数,从而显著提高了最终的OioU。这是因为全局局部功能可以更好地捕获输入表达式和图像的上下文信息,从而获得更准确的分割掩码。
5. 讨论

本文提出了几项未来的工作,包括探索使用更高级的实例分割方法,研究视觉编码器使用不同的预训练模型,以及探索使用深度和光流等其他模式来提高分割性能。该论文还建议探索使用更复杂的文本编码器,并整合其他语言特征,例如句法和语义信息,以便为引用表达式奠定更好的基础。最后,本文建议探索将所提出的方法用于其他相关任务,例如参考表达式理解和视觉问答。
本文提出了一种zero-shot的Referring image segmentation,该方法利用了来自CLIP的预先训练的跨模态知识。尽管所提出的方法显示出令人鼓舞的结果,但该研究存在一些局限性,包括:
- 提议的方法依赖于现成的实例分段方法,这些方法可能并不总是能提供准确的实例掩码。
- 所提出的方法没有考虑图像中不同物体之间的关系,这可能会限制其精确分割复杂场景的能力。
- 所提出的方法是在有限数量的数据集上进行评估的,其推广到其他数据集和领域的可能性尚未得到充分探讨。
- 本文没有详细分析所提出的方法的计算复杂性和效率,这可能会限制其在现实场景中的实际适用性。
6. 结论
本文提出了一种zero-shot的Referring image segmentation方法,该方法利用了来自CLIP的pre-train的跨模态知识。所提出的方法使用掩码引导的视觉编码器来获得基于输入文本的分段掩码,并使用全局局部文本编码器来捕获整个输入表达式的复杂句子级语义。该方法的性能明显优于所有基线方法和监督较弱的方法。因此,本文的结论是,所提出的方法对于参考图像分割任务是有效的。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
【CV技术指南】咱们自己的CV全栈指导班、基础入门班、论文指导班 全面上线!!
CVPR 2023|21 篇数据集工作汇总(附打包下载链接)
CVPR 2023|两行代码高效缓解视觉Transformer过拟合,美图&国科大联合提出正则化方法DropKey
ViT-Adapter:用于密集预测任务的视觉 Transformer Adapter
CodeGeeX 130亿参数大模型的调优笔记:比FasterTransformer更快的解决方案
CVPR 2023 深挖无标签数据价值!SOLIDER:用于以人为中心的视觉
上线一天,4k star | Facebook:Segment Anything
Efficient-HRNet | EfficientNet思想+HRNet技术会不会更强更快呢?
ICLR 2023 | SoftMatch: 实现半监督学习中伪标签的质量和数量的trade-off
目标检测创新:一种基于区域的半监督方法,部分标签即可(附原论文下载)
CNN的反击!InceptionNeXt: 当 Inception 遇上 ConvNeXt
拯救脂肪肝第一步!自主诊断脂肪肝:3D医疗影像分割方案MedicalSeg
AI最全资料汇总 | 基础入门、技术前沿、工业应用、部署框架、实战教程学习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号