语义分割专栏(一)解读FCN
前言 本文将介绍全卷积神经网络(Fully Convolutional Network,简称FCN)的基础知识,包括它的网络结构、起源、应用、输入输出格式和pytorch代码实现等内容。
本教程禁止转载。同时,本教程来自知识星球【CV技术指南】更多技术教程,可加入星球学习。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
FCN网络介绍
FCN作为语义分割领域的开创者,重要性不言而喻。在FCN之前,计算机视觉领域的工作主要集中在对象检测和图像分类等方向,这些任务实现的是对图像进行分类、定位、边界框回归等操作。但是!一旦能够对输入图像进行像素级分割(像下面这样↓),这些任务就都能迎刃而解!
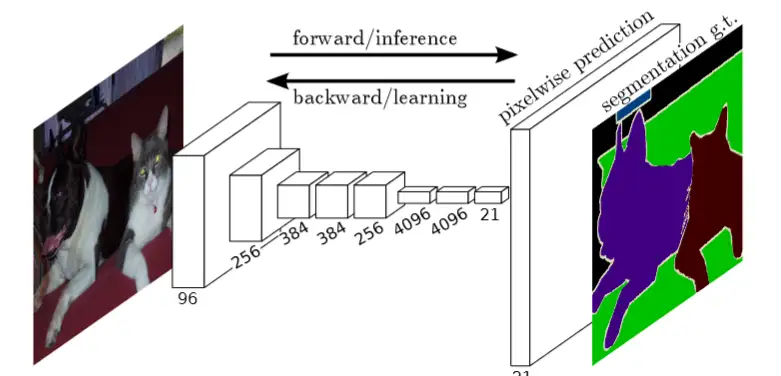
FCN的出现就解决了这个问题:采用全卷积的结构可以对任意大小的图像进行像素级别的预测和分割!
这一突破性的进展为语义分割任务的发展提供了强有力的支持和推动,使得在医学影像、自动驾驶、智能安防等领域实现高质量的语义分割成为可能。因此,可以说FCN的出现对语义分割领域的发展产生了深远的影响,具有重要的意义。
起源
FCN最初是由Jonathan Long等人在2015年提出的,旨在解决传统卷积神经网络(Convolutional Neural Network,简称CNN)只能对固定大小的图像进行分类和检测的问题。FCN采用全卷积的结构,使其能够对任意大小的图像进行像素级别的预测和分割。
输入输出格式
与传统CNN不同,FCN的输入和输出都是Tensor类型,其输出与输入大小相同,在输出中,每个像素的值表示该像素所属的类别。
举个栗子,对于以下情况:类别数一共为19,输入了5张大小为512×512的3通道图像 此刻的输出将是:5张大小为512×512的19通道图像。这里的19通道,代表了对于每一个像素点(512×512这个二维矩阵中的任意位置)对于属于某个类别的概率。既然是19个类别,并且属于每个类别都有一个确定的概率:是类别1的概率,是类别2的概率,...,是类别19的概率,(可以想象,最终结果当然是选择概率最大那个类),那么为了储存每个点像素点这19个值,自然需要19个通道。
模型结构
在论文中,FCN的网络结构如下所示:
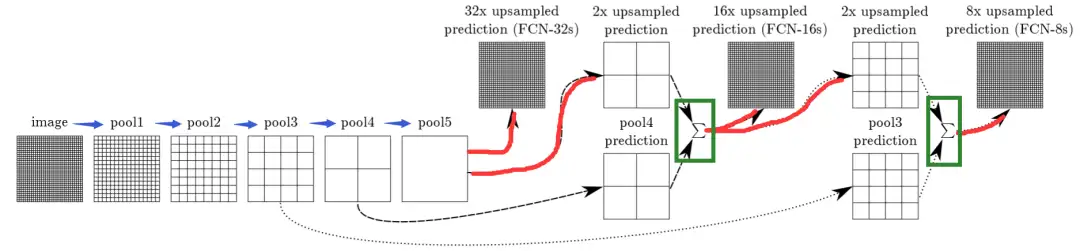
- 在蓝色箭头部分,实际上对图像进行了“卷积-BN-非线性”的集合操作,并在池化后让图像尺寸变小;
- 在红色线部分,执行的是上采样操作(在pytorch官方实现中采用的是双线性插值);
- 在绿色矩形框部分,通过元素相加的方式对不同位置的特征图进行了融合;
经过这一系列的操作,我们能够让输入输出大小保持一致,从而实现像素级别的分割。
从网络结构也能看出,每多一次 信息融合 的步骤,网络的复杂度就会更高一分,那它一定值得更高的准确率,像下面这样:
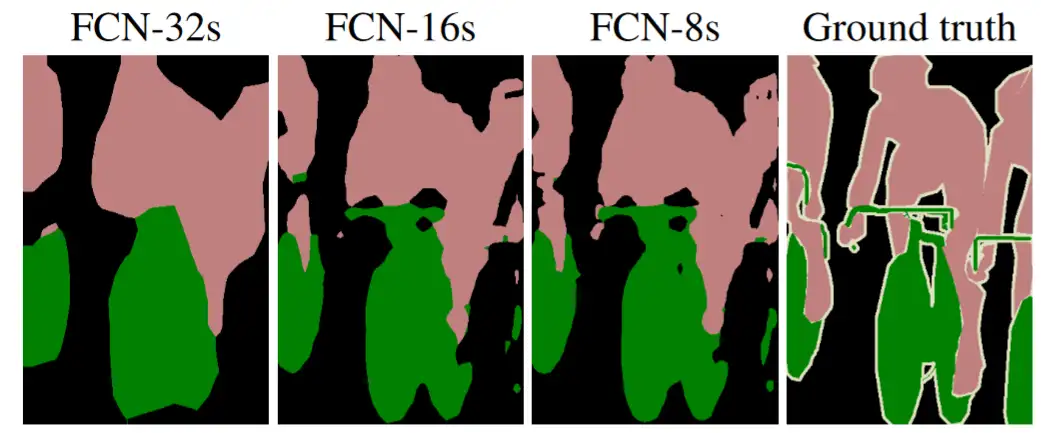
这也是将来的文章中常说的权衡:高精度和轻量化,往往是不可兼得的。
模型分类
FCN模型有以下几种分类方式:
- 32s、16s、8s 这三种分类方式,对应的是你是否要进行特征图的融合和你要怎样对特征图进行融合
- 32s
- 融合一次——16s
- 融合两次——8s
- 要融合
- 不要融合
- 骨干网络(也就是后面说的编码器)
- ResNet
- VGG
- 当然你还可以选择其他你喜欢的分类网络
下面这个表格简要展示了一些不同的FCN:
| ResNet | VGG | |
|---|---|---|
| 32s | FCN_ResNetxx_32s | FCN_VGG_32s |
| 16s | FCN_ResNetxx_16s | FCN_VGG_16s |
| 8s | FCN_ResNetxx_8s | FCN_VGG_16s |
一些开创性的工作
- FCN采用端到端的训练方式,可以直接从原始图像中学习特征和分类器,避免了传统方法中需要多个阶段、多个模型的繁琐过程。
- FCN设计了编码器-解码器(Encoder-Decoder)结构,即将输入图像通过编码器提取特征,然后通过解码器将特征图转化为输出分割图像。
- 编码器:编码器部分通常采用预训练的深度学习模型,如VGG、ResNet等,可以快速学习输入图像的特征(并且可以采用它们的预训练参数,可以避免自己从头开始训练)
- 解码器:解码器采用反卷积、双线性插值等上采样操作还原特征图的大小为输出分割图像
FCN详细代码
下面给出的是以ResNet34作为编码器的fcn_32s的代码实现
import torch
import torch.nn as nn
import torchvision.models as models
class FCN_ResNet34(nn.Module):
def __init__(self, num_classes):
super(FCN_ResNet34, self).__init__()
self.num_classes = num_classes
self.encoder = models.resnet34(pretrained=True)
self.relu = nn.ReLU(inplace=True)
# 修改ResNet的最后一层卷积层,使得输出通道数等于分类数
self.encoder.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.encoder.fc = nn.Conv2d(512, num_classes, kernel_size=1)
# 反卷积层1
self.deconv1 = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=4, stride=2, padding=1, bias=False)
# 反卷积层2
self.deconv2 = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=4, stride=2, padding=1, bias=False)
# 反卷积层3
self.deconv3 = nn.ConvTranspose2d(num_classes, num_classes, kernel_size=16, stride=8, padding=4, bias=False)
def forward(self, x):
# 前向传播编码器
x = self.encoder.conv1(x)
x = self.encoder.bn1(x)
x = self.relu(x)
x = self.encoder.maxpool(x)
x = self.encoder.layer1(x)
x = self.encoder.layer2(x)
x = self.encoder.layer3(x)
x = self.encoder.layer4(x)
# 前向传播解码器
x = self.encoder.fc(x)
x = self.relu(x)
x = self.deconv1(x)
x = self.relu(x)
x = self.deconv2(x)
x = self.relu(x)
x = self.deconv3(x)
return x
下面我们简单地看一下输入和输出的形态~
model = FCN_ResNet34(num_classes=21)
a = torch.randn(size=(8,3,224,224))
b = model(a)
print(a.shape,b.shape)
# 得到的形式是完全一样的哦~
# 输出分别为:
torch.Size([8, 3, 224, 224])
torch.Size([8, 21, 224, 224])
FCN总结
FCN是第一个全卷积神经网络,采用端到端的训练方式和编码器-解码器结构,可以实现像素级别的语义分割。并且在当年实现了接近“完美”的结果。

FCN的意义在于它开创了全卷积神经网络的研究方向,提出了一种新的解决像素级别分割任务的方法,换言之,FCN是语义分割界的“Hello World”,对深度学习在计算机视觉领域的应用产生了深远影响。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
【CV技术指南】咱们自己的CV全栈指导班、基础入门班、论文指导班 全面上线!!
CVPR 2023|21 篇数据集工作汇总(附打包下载链接)
CVPR 2023|两行代码高效缓解视觉Transformer过拟合,美图&国科大联合提出正则化方法DropKey
ViT-Adapter:用于密集预测任务的视觉 Transformer Adapter
CodeGeeX 130亿参数大模型的调优笔记:比FasterTransformer更快的解决方案
CVPR 2023 深挖无标签数据价值!SOLIDER:用于以人为中心的视觉
上线一天,4k star | Facebook:Segment Anything
Efficient-HRNet | EfficientNet思想+HRNet技术会不会更强更快呢?
ICLR 2023 | SoftMatch: 实现半监督学习中伪标签的质量和数量的trade-off
目标检测创新:一种基于区域的半监督方法,部分标签即可(附原论文下载)
CNN的反击!InceptionNeXt: 当 Inception 遇上 ConvNeXt
拯救脂肪肝第一步!自主诊断脂肪肝:3D医疗影像分割方案MedicalSeg
AI最全资料汇总 | 基础入门、技术前沿、工业应用、部署框架、实战教程学习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号