

CVPR 2023 深挖无标签数据价值!SOLIDER:用于以人为中心的视觉
前言 在现今的各种视觉智能场景中,对图像中人的理解和分析一直都是一个非常重要的环节。SOLIDER 是 CVPR 2023 录用的一篇来自于阿里达摩院的工作,是一个专门用于支持各种人体任务的视觉预训练模型。它提供一种自监督训练方式,让我们可以充分利用市面上大量的人体无标注数据训练出一个可以通用于下游各种人体视觉任务的预训练大模型。
本文转载自我爱计算机视觉
作者 | 陈威华
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。

论文链接:https://arxiv.org/abs/2303.17602
项目链接:https://github.com/tinyvision/SOLIDER
01
背景介绍
现今以人为中心的视觉任务引起了越来越多的研究关注,因为它们在现实场景中有着广泛的应用。我们的目标是从大量未标注的人体图像中学习一个通用的人体表征。基于此,我们提出了一个自监督的学习框架,叫做SOLIDER。与现有的自我监督学习方法不同,该方法利用人体图像中的先验知识来自监督训练模型,为表征引入更多的语义信息。
此外,我们还注意到不同的下游任务通常对预训练的人体表征中语义信息和表观信息的需求程度各不相同。例如人体解析任务(human parsing)需要表征中包含更多的语义信息,而人体再识别任务(person re-identification)则需要更多的表观信息来进行不同人的识别。
因此,一个单一的人体表征并不能适用于所有下游任务。SOLIDER 通过引入一个带有语义控制器的条件神经网络来解决这个问题。待预训练模型训练完成后,用户可以通过向语义控制器输入希望表征包含语义信息的比例,让控制器调整预训练模型,以生成符合指定语义信息量的人体表征。我们可以使用包含不同语义信息量的人体表征去适应不同的下游任务。我们实验发现SOLIDER可以在六个下游人体视觉任务中超过了state of the arts。
02
主要贡献
1、[贡献一] Semantic Supervision from Human Prior:利用人体图片先验打伪标签,进行自监督训练,使得预训练模型包含更多的语义信息。
2、[贡献二] Semantic Controller:引入一个语义控制器,控制预训练模型中语义信息的含量多少,来适应不同的下游任务。
03
具体方法
3.1 Overview
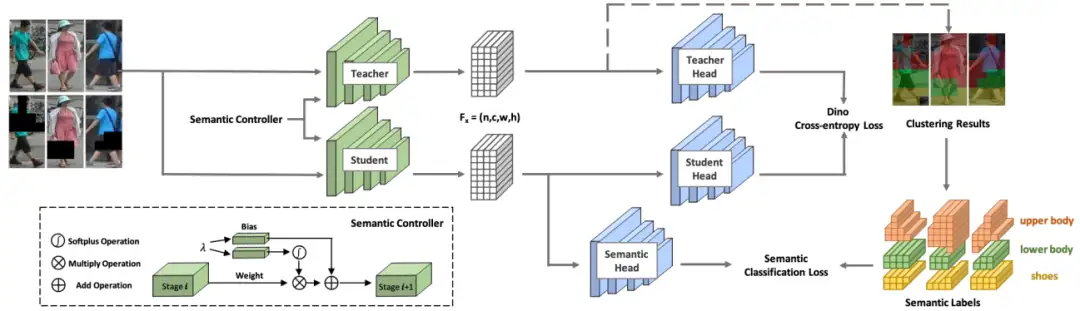
整个SOLIDER的训练流程图如图1所示:
3.2 Semantic Supervision from Human Prior
我们发现人体图片本身包含很强的先验。大部分人体图片中,人体基本占满整个图片,并且头朝上,脚朝下。这个先验之前也被很多工作使用过[1,2],因此,我们尝试用这种先验来指导模型自监督训练。简单来说,对每张图片,我们将图片像素特征进行聚类(这里我们以3类为例),沿Y轴将3类分别定义为上半身,下半身和脚。对每个像素根据其聚类结果打上伪标签,如图2(b)所示。然后进行像素级别的3分类训练。

聚类后我们发现很多时候由于噪声比较多,聚类效果并不好。为了达到更好的效果,借鉴[2]的思想,我们首先根据像素特征的模长进行2分类,将模长小的那类定义为背景类,如图2(d)所示。再对模长长的那类进行3分类聚类,得到前景中对应的三个语义part,如图2(e)所示。
除此之外,我们相信即使遮住了某个part,根据相邻语义part,模型应该有能力预测出被遮挡这个part属于哪一类。为了进一步提升语义信息的影响,我们引入MAE的思想,随机遮住某个part,然后让模型预测正确结果,进行自监督训练。
我们的框架以DINO作为baseline,模型的语义信息损失函数如下所示:
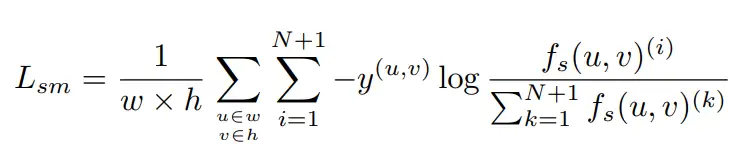
这里f_s(u,v)表示来自于student的特征图中像素点(u,v)的特征向量,y为对应像素的聚类伪标签。整体损失函数如下所示:
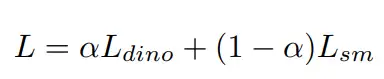
3.3 Semantic Controller
我们发现不同的下游任务对人体表征中语义信息的含量多少有着不同的需求,我们希望一次训练得到的预训练模型可以适合不同的下游任务。因此,我们引入一个语义控制器,将整个预训练模型变成一个条件网络。语义控制器如图1中所示,它被加到了backbone每个block的后面,它的输入是一个标量 λ 和前一层的特征图,这个标量λ就是用来控制表征中语义信息的含量。
在训练时,首先我们将λ设为1,送到DINO中的teacher branch,得到语义伪标签。之后,我们随机采样一个λ值(范围为0~1,文中也给出了不同采样分布的比较),得到对应的teacher和student branch的特征图f_t和f_s,用DINO的contrastive loss训练f_t和f_s,用语义伪标签训练f_s。最终公式如下所示:
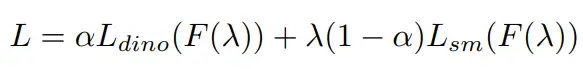
在下游使用时,针对特定任务,我们预先设定对应的λ值,比如对行人再识别任务,我们将λ设为0.2,对于人体检测和人体解析任务,我们将λ设为1.0。然后进行下游任务的全参数finetuning。
04
实验结果
4.1 语义信息验证
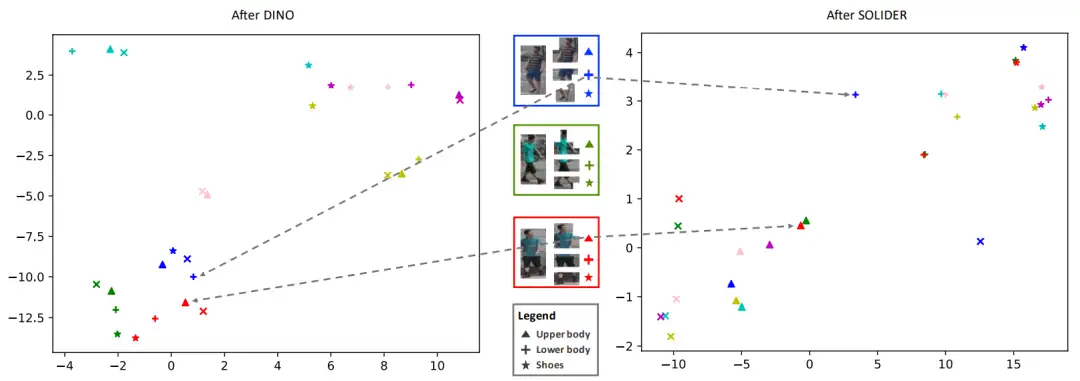
首先,我们分析SOLIDER训练的模型是否包含了更多语义信息,如图3所示,左侧为DINO训练的模型,右侧为SOLIDER训练的模型。图中不同颜色表示不同人,不同形状表示人的不同语义part。可以看到左侧图片中,同一个人的不同part都聚在一起,不区分不同part。而右侧图片中,包含相同语义的part会聚在一起,即使来自于不同人,并且,如果相同语义的part表观也相似,他们会离的很近(比如红绿三角),表观不相似会有一定的距离(比如蓝红三角)。这说明相对于DINO训练的模型,SOLIDER模型包含了更多的语义信息。
4.2 λ验证
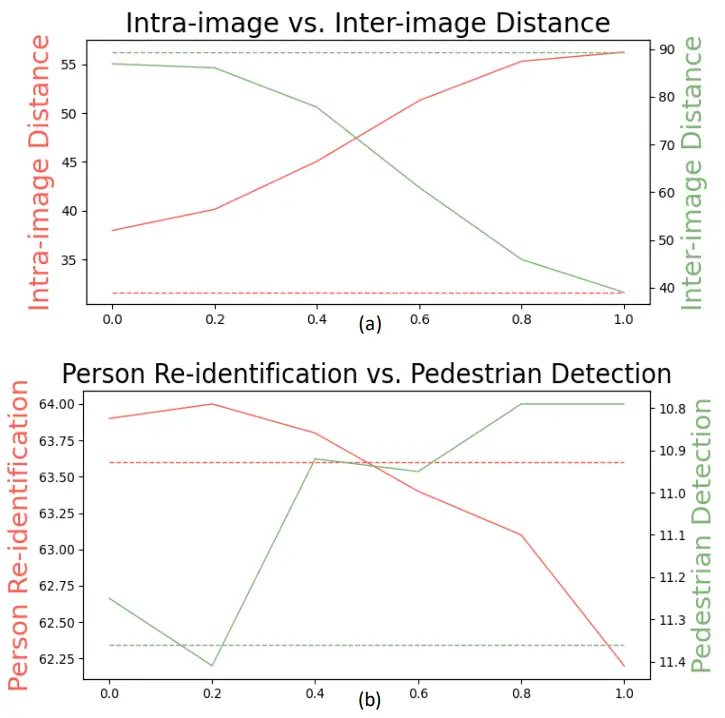
其次,我们想验证λ是否能够反映甚至控制表征中语义信息的含量。我们统计了两个距离,分别是训练集中不同图片同一个语义part之间的平均距离(inter-image distance)和同一个图片中不同语义part之间的平均距离(intra-image distance)。如图4所示,对于SOLIDER训练好的预训练模型,随着λ变大,输出特征的intra-image distance在不断变大,inter-image distance在不断变小,说明不相同语义的part在不断拉近,也就是说特征的语义表达能力越来越强。
为了进一步验证这个问题,我们尝试使用不同的λ来观察其表征在下游任务上的效果。可以看到在行人重识别任务上,随着λ增大,效果越来越差;反而对于人体检测任务,随着λ增大,效果越来越好。这也进一步说明,λ会对表征产生影响,并且可以用来控制其中语义信息对下游任务的影响。
4.3 消融实验和SOTA比较
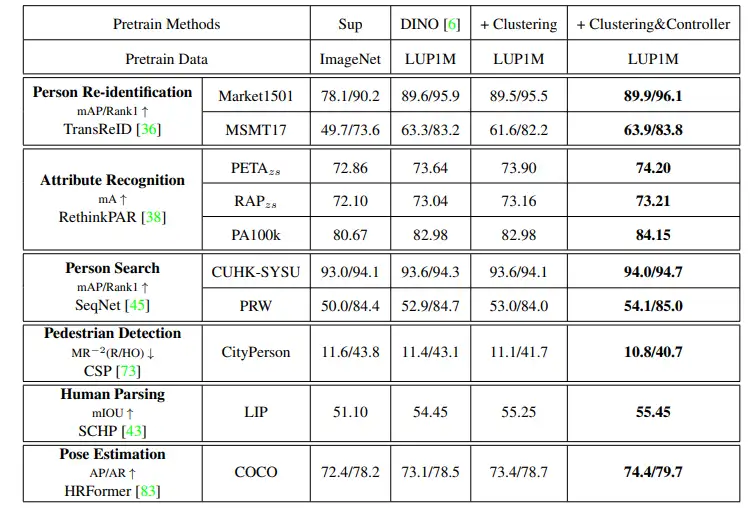
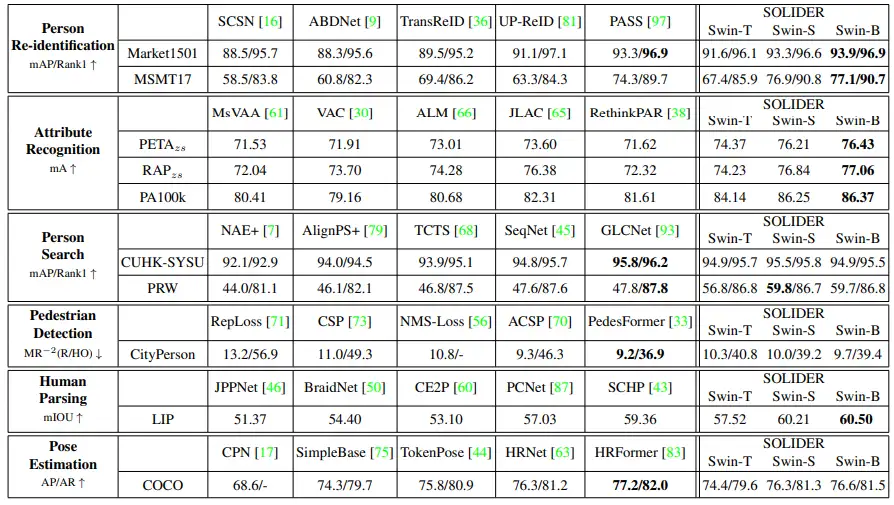
最后,我们对提供了相应的消融实验(图5)和state of the arts之间的比较(图6)。可以看到在绝大多数任务上,我们的效果要优于当前的state of the art方法。
05
一些观点
1、这里我们训练只采用了LUPerson数据集,并且能看出来效果并未达到瓶颈,随着数据量的增加,效果还能进一步提升。
2、CVPR23上OpenGVLab有一篇专注于human-centric pretrain的文章HumanBench,很惊艳的工作,很开心能看到有更多学者关注于human-centric pretrain的研究。HumanBench的工程量也非常庞大。但和我们不同的是,它更关注于multi-task的监督训练,希望模型在下游不finetune就能有个很棒的效果。而我们更侧重于自监督预训练,为了充分利用大量无标注数据。
参考文献[1] Yifan Sun, Liang Zheng, Yi Yang, Qi Tian, and Shengjing Wang. Beyond part models: Person retrieval with refined part pooling. In ECCV, 2018.[2] Kuan Zhu, Haiyun Guo, Zhiwei Liu, Ming Tang, and Jinqiao Wang. Identity-guided human semantic parsing for person re-identification. In ECCV, 2020.
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
CVPR 2023|21 篇数据集工作汇总(附打包下载链接)
CVPR 2023|两行代码高效缓解视觉Transformer过拟合,美图&国科大联合提出正则化方法DropKey
ViT-Adapter:用于密集预测任务的视觉 Transformer Adapter
CodeGeeX 130亿参数大模型的调优笔记:比FasterTransformer更快的解决方案
CVPR 2023 深挖无标签数据价值!SOLIDER:用于以人为中心的视觉
上线一天,4k star | Facebook:Segment Anything
Efficient-HRNet | EfficientNet思想+HRNet技术会不会更强更快呢?
ICLR 2023 | SoftMatch: 实现半监督学习中伪标签的质量和数量的trade-off
目标检测创新:一种基于区域的半监督方法,部分标签即可(附原论文下载)
CNN的反击!InceptionNeXt: 当 Inception 遇上 ConvNeXt
拯救脂肪肝第一步!自主诊断脂肪肝:3D医疗影像分割方案MedicalSeg
AI最全资料汇总 | 基础入门、技术前沿、工业应用、部署框架、实战教程学习


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
2022-04-15 从零搭建Pytorch模型教程(三)搭建Transformer网络