

分割一切还不够,还要检测一切、生成一切,SAM二创开始了
前言 论文刚发布两天,「 二创 」就开始了。
本文转载自机器之心
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
AI 技术的迭代,已经以天为单位。所以,如果你有什么好的想法,最好赶紧做,不然睡一觉可能就被抢先了。

这个被很多人看好的 idea 源于 Meta 两天前发布的「分割一切」AI 模型(Segment Anything Model,简称 SAM)。Meta 表示,「SAM 已经学会了关于物体的一般概念,可以为任何图像或视频中的任何物体生成 mask,甚至包括在训练过程中没有遇到过的物体和图像类型。SAM 足够通用,可以涵盖广泛的用例,并且可以在新的图像『领域』即开即用,无需额外的训练。」

这一模型的发布在计算机视觉领域引发轰动,预示着 CV 也将走向「一个全能基础模型统一某个(某些?全部?)任务」的道路。当然,大家对此早有预感,但没想到这一天来得如此之快。
比基础模型迭代更快的是研究社区「二创」的速度。论文才刚刚发布两天,几位国内工程师就基于此想出了新的点子并将其付诸实践,组建出了一个不仅可以「分割一切」,还能「检测一切」、「生成一切」的视觉工作流模型。


具体来说,他们使用一个 SOTA 的 zero-shot 目标检测器(Grounding DINO)提取物体 box 和类别,然后输入给 SAM 模型出 mask,使得模型可以根据文本输入检测和分割任意物体。另外,他们还将其和 Stable Diffusion 结合做可控的图像编辑。
这个三合一模型项目名叫 Grounded Segment Anything,三种类型的模型既可以分开使用,也可以组合使用。
项目链接:https://github.com/IDEA-Research/Grounded-Segment-Anything
对于 Grounded Segment Anything 未来的用途,项目作者构想了几种可能:
- 可控的、自动的图像生成,用于构建新的数据集;
- 提供更强的基础模型与分割预训练;
- 引入 GPT-4,进一步激发视觉大模型的潜力;
- 一条自动标记图像(带 box 和 mask)并生成新图像的完整 pipeline;
- ……
安装
要实现 SAM+Stable Diffusion 需要一些安装步骤。首先该项目要求 Python 3.8 以上版本,pytorch 1.7 以上版本,torchvision 0.8 以上版本,并安装相关依赖项。项目作者还建议安装支持 CUDA 的 PyTorch 和 TorchVision。
然后,按照如下代码安装 Segment Anything:

安装 GroundingDINO:

以下是可选依赖项,这些对于掩码后处理、以 COCO 格式保存掩码、example notebook 以及以 ONNX 格式导出模型是必需的。另外,该项目还需要 jupyter 来运行 example notebook。

运行 GroundingDINO demo
下载 groundingdino 检查点:

运行 demo:

模型预测可视化将保存在 output_dir 中,如下所示:

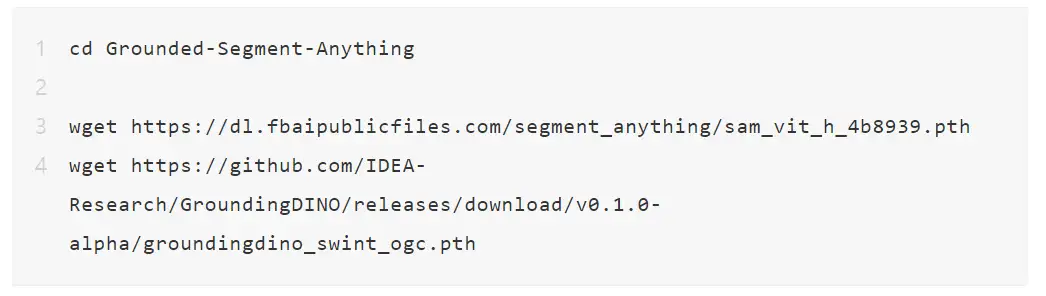
运行 Grounded-Segment-Anything Demo
下载 segment-anything 和 ground- dino 的检查点:
运行 demo:

模型预测可视化将保存在 output_dir 中,如下所示:

运行 Grounded-Segment-Anything + Inpainting Demo

运行 Grounded-Segment-Anything + Inpainting Gradio APP

参考链接:
https://zhuanlan.zhihu.com/p/620271321
https://www.zhihu.com/question/593914819/answer/2972925421
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
上线一天,4k star | Facebook:Segment Anything
Efficient-HRNet | EfficientNet思想+HRNet技术会不会更强更快呢?
ICLR 2023 | SoftMatch: 实现半监督学习中伪标签的质量和数量的trade-off
目标检测创新:一种基于区域的半监督方法,部分标签即可(附原论文下载)
CNN的反击!InceptionNeXt: 当 Inception 遇上 ConvNeXt
拯救脂肪肝第一步!自主诊断脂肪肝:3D医疗影像分割方案MedicalSeg
AI最全资料汇总 | 基础入门、技术前沿、工业应用、部署框架、实战教程学习
AAAI 2023 | 轻量级语义分割新范式: Head-Free 的线性 Transformer 结构
TSCD:弱监督语义分割新方法,中科院自动化所和北邮等联合提出
如何用单个GPU在不到24小时的时间内从零开始训练ViT模型?
CVPR 2023 | 基于Token对比的弱监督语义分割新方案!
比MobileOne还秀,Apple将重参数与ViT相结合提出FastViT
CVPR 2023 | One-to-Few:没有NMS检测也可以很强很快


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!