ICLR2023|基于数据增广和知识蒸馏的单一样本训练算法
前言 本文开发了一个简单的框架,用于使用单个图像从头开始训练神经网络,并使用监督的预训练教师的知识蒸馏进行增强。
本文转载自极市平台
作者 | CV开发者都爱看的
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。

论文链接:https://openreview.net/pdf?id=6kxApT2r2i
源码链接:https://github.com/yukimasano/single-img-extrapolating
简介
本文研究关注于是否神经网络可以从单一数据训练并进行推断。
这个问题的主要难点在于:1. 当前深度学习优化的算法(SGD等)在大的数据集上设计的,不能在单一数据上推广,2. 需要关于单个数据之外的自然图像空间信息的语义类别进行推断。本文的主要思想是结合数据增广和知识蒸馏的相关算法。
数据增广算法可以通过单一图像生成大量变化,有效解决一般优化方法只在大型数据集上设计难以优化的问题1。为了解决单一数据设定难以提供语义类别相关信息的问题,本文方法选择使用有监督训练模型的输出和知识蒸馏算法。使用知识蒸馏算法提供训练过程中需要的语义类别信息。
相关工作
知识蒸馏
一般的知识蒸馏主要目标即使用一个预训练的教师模型信息辅助训练一个低学习能力的学生模型。利用教师模型获得的软预测结果获得类别间关系提升学生模型训练性能。早期方法只使用最终层输出,其他转移的特征还包括:中间层特征;空间注意力后特征,对比学习蒸馏等。
无数据知识蒸馏
无数据知识蒸馏(Data-Free Knowledge Distillation)一般用于极端巨大数据集,有隐私需求的数据集或只能获得API模型输出的需求等。原始方法一般需要训练数据集相关激活层统计信息。之后提出的方法一般不需要此类信息。使用基于生成的方法生成合成图像数据集,最大限度地激活教师最后一层的神经元。
本文方法
数据生成
在A critical analysis of self-supervision, or what we can learn from a single image研究中,一个单一的图片增广若干次生成一个固定尺寸的静态数据集。增广方法包括切割,旋转,剪切和颜色抖动( cropping, rotation,shearing,color jittering)。本文也使用相同的方法并不改变超参。这里通过添加随机噪声分析源图像选择。另外本文实验也关注了音频分类。这里选择的赠官该方法包括随机音量增加,背景噪声添加和变桨(pitch shifting)。
知识蒸馏
原始知识蒸馏算法(Distilling the knowledge in a neural network)将一个预训练的教师模型的知识迁移到一个能力较弱的学生模型。学生模型的优化目标是一个两种损失函数的加权组合:一个标准的交叉熵损失和分布匹配损失(减少与教师模型结果的分布差异)。
本文方法特殊的是对于生成的单一图像没有标签信息,这里使用学生模型结果与教师模型结果的KL散度信息:
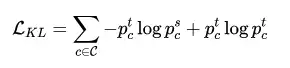
训练时按照Knowledge distillation: A good teacher is patient and consistent的功能匹配策略,教师与学生模型传入一致的增广示例。复杂增广的方法包括MixUp和CutMix。
实验
这里检查从单一图像推断到小尺寸数据集的能力。表1给出了在CIFAR10和CIFAR100数据集上的实验结果。使用源数据集在源数据集达到最高的精度,但使用单个图像得到的模型也可以达到下界。另外单一图像蒸馏甚至超过了使用CIFAR-10的10K图像指导CIFAR-100训练即使两个数据集相似。
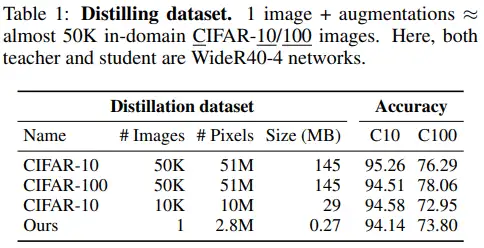
单一图像的选择 这里发现单一图像选择是重要的。随机噪声或稀疏的图像与密集标签bridge和Animal图像性能差很多。
损失函数的选择 图3(b)发现本文方法的学生模型甚至能从下降质量的学习信号下学习。即使受到的是TOP-5的预测或者最大预测(硬标签),学生模型也能在很大意义上进行推断(>91%/60%)。
增广策略选择 图3(c)给出了不同的增广策略,除了之前指出的策略:更多的增广更好。本文发现在本文的单一图像蒸馏任务上CutMix比MixUp性能更好。
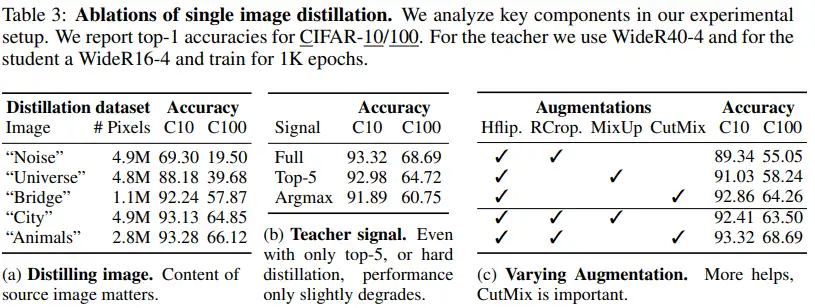
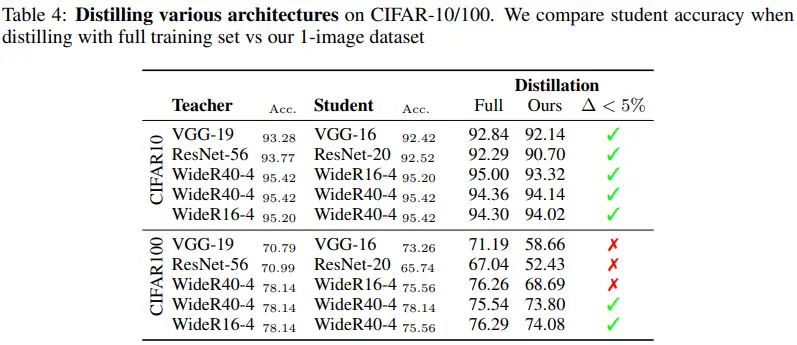
表4给出了在CIFAR-10和CIFAR100数据集上使用常用架构上的蒸馏实验比较。CIFAR10数据集上看到几乎所有的架构上性能都有相似表现,除了ResNet-56到ResNet-20的蒸馏精度下降较多,可能原因是学生模型学习能力较小。
本文也给出了本文方法在其他模态上的性能比较,在50K随机生成的端音频中蒸馏。表5给出了实验结果。比较模型是直接使用源数据集的教师模型。实验结果发现在音频模态中,单一的音频数据也能给学生模型足够的监督信号。
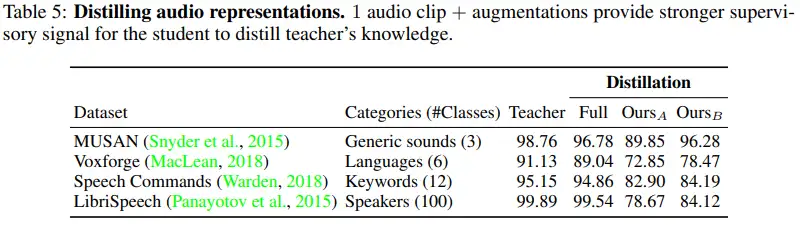
表6给出了视频模态上的实验结果。实验结果也显示单一数据也能给学生模型足够监督信号。
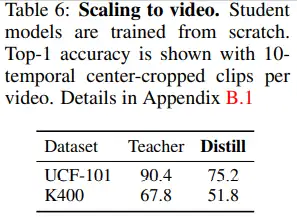
表7给出了在大型图像数据集上的实验结果。一般来说单一图像在大型数据集不足够恢复全部信息。这里发现在ImageNet验证数据集上获得了一个惊人的69%精度。

图4给出了不同学生模型(不同的深度或宽度)下的性能比较。图中所示改变宽度是一个获得更高精度的参数更高效方式。ResNet-50x2模型精度69.0%,几乎到达了教师模型69.5%的精度。
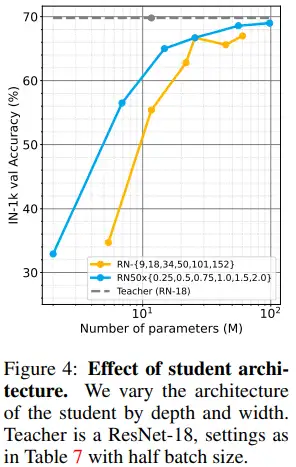
表8给出了更多样的教师-学生组合实验。根据表格结果所示:教师模型性能与最终学生模型性能不是直接相关的,例如行i和l结果所示:ResNet-50不如ResNet-18适合于蒸馏。
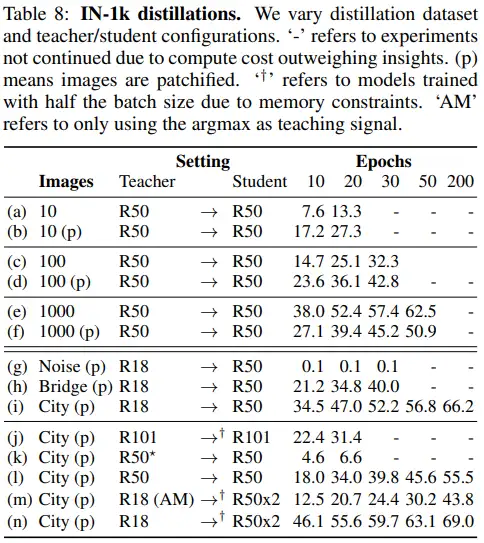
另外发现在ImageNet分类任务上单一图像选择更重要。从城市(City)转换到桥梁(Bridge),性能明显下降,如果是噪声图像(Noise)根本不训练。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
AI最全资料汇总 | 基础入门、技术前沿、工业应用、部署框架、实战教程学习
AAAI 2023 | 轻量级语义分割新范式: Head-Free 的线性 Transformer 结构
TSCD:弱监督语义分割新方法,中科院自动化所和北邮等联合提出
如何用单个GPU在不到24小时的时间内从零开始训练ViT模型?
CVPR 2023 | 基于Token对比的弱监督语义分割新方案!
比MobileOne还秀,Apple将重参数与ViT相结合提出FastViT
CVPR 2023 | One-to-Few:没有NMS检测也可以很强很快
ICLR 2023 | Specformer: Spectral GNNs Meet Transformers
AAAI 2023 | 打破NAS瓶颈,AIO-P跨任务网络性能预测新框架
目标检测Trick | SEA方法轻松抹平One-Stage与Two-Stage目标检测之间的差距
CVPR 2023 | 标注500类,检测7000类!清华大学等提出通用目标检测算法UniDetector
CVPR 2023 | 超越MAE!谷歌提出MAGE:图像分类和生成达到SOTA!
CVPR2023 | 书生模型霸榜COCO目标检测,研究团队解读公开
Vision Transformer的重参化也来啦 | RepAdpater让ViT起飞
高效压缩99%参数量!轻量型图像增强方案CLUT-Net开源
一文了解 CVPR 2023 的Workshop 都要做什么
CVPR'23 最新 70 篇论文分方向整理|包含目标检测、图像处理、人脸、医学影像、半监督学习等方向
目标检测无痛涨点新方法 | DRKD蒸馏让ResNet18拥有ResNet50的精度
CVPR2023最新Backbone | FasterNet远超ShuffleNet、MobileNet、MobileViT等模型
CVPR2023 | 集成预训练金字塔结构的Transformer模型
AAAI 2023 | 一种通用的粗-细视觉Transformer加速方案

 浙公网安备 33010602011771号
浙公网安备 33010602011771号