如何用单个GPU在不到24小时的时间内从零开始训练ViT模型?
前言 Transformers已成为计算机视觉最新进展的核心。然而,从头开始训练ViT模型可能会耗费大量资源和时间。在本文中旨在探索降低ViT模型训练成本的方法。引入了一些算法改进,以便能够在有限的硬件(1 GPU)和时间(24小时)资源下从头开始训练ViT模型。
首先,提出了一种向ViT架构添加局部性的有效方法。其次,开发了一种新的图像大小课程学习策略,该策略允许在训练开始时减少从每个图像中提取的patch的数量。最后,我们通过添加硬件和时间限制,提出了流行的ImageNet1k基准的新变体。根据这一基准评估了本文的贡献,并表明在拟定的训练预算下可以显著提高性能。
本文转载自集智书童
作者 | 小书童
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。

代码:https://github.com/BorealisAI/efficient-vit-training
1、简介
最近,Transformer架构已成为大量计算机视觉模型的关键组成部分。然而,训练大型变压器模型通常需要付出巨大的成本。例如,在4个GPU上训练像DeiT-S这样的小型ViT大约需要3天时间。
为了降低成本,作者建议探索以下问题:如何用单个GPU在不到24小时的时间内从零开始训练ViT模型。作者认为,由于多种原因,这一方向的进展可能会对计算机视觉研究和应用的未来产生重大影响。
- 加快模型开发。ML中的新模型通常通过运行和分析其上的实验来评估性能,当每次实验的训练成本过高时,这不是一种可扩展的方法。通过降低训练成本,缩短了开发周期。
- 更容易接近。大多数ViT模型都是通过使用多个GPU或TPU从头开始训练的,不幸的是,这将无法获得此类资源的研究人员排除在这一研究领域之外。通过仅使用1个GPU作为基准,显著降低了ViT的训练成本,这使得更多的研究人员能够推动这一研究方向。
- 降低环境成本。降低训练成本的一种方法是开发更高效的专用硬件或更高效的数据表示,如半精度。另一种正交方法是开发更有效的算法。
在本文中,重点讨论第二种方法。已经开发了许多方法(例如剪枝)来降低推理成本,但数量有限的工作正在探索降低训练成本的想法。有工作探索了如何在小型数据集上从头开始训练ViT。也有工作在探索如何在24小时内对文本数据训练BERT模型,但它使用8个GPU的服务器,而作者将自己限制在单个GPU。Primer建议寻找Transformer的更有效的替代品,但它侧重于NLP。作者试图将这项工作的发现应用于ViT,但没有看到任何改进。因此,仍然不清楚为NLP领域开发的改进是否也可以推广到计算机视觉应用中。
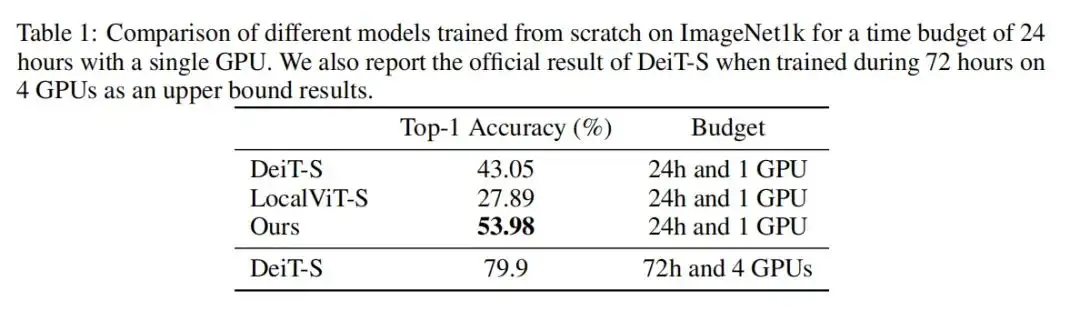
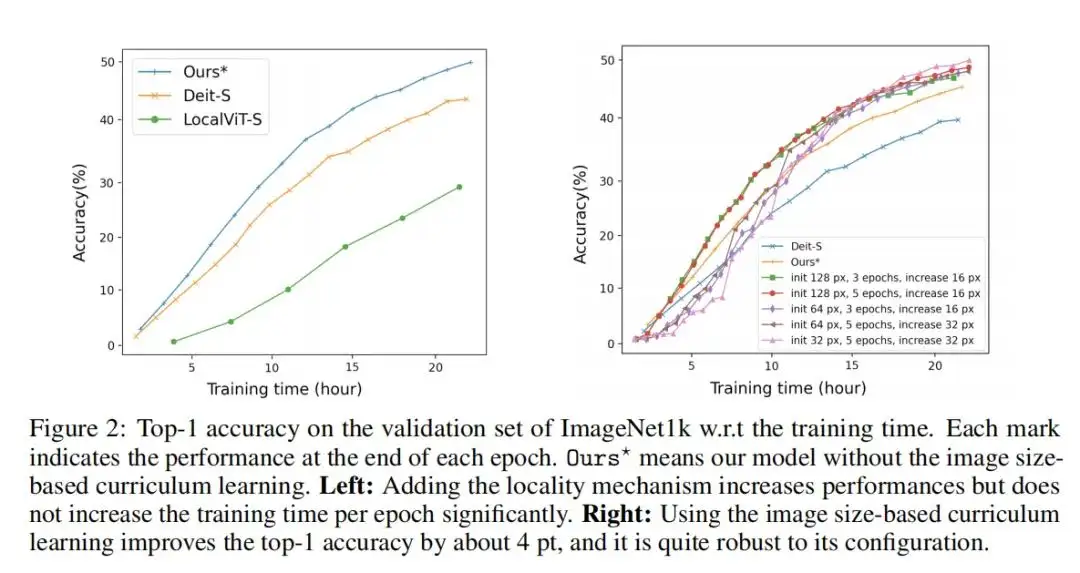
作者将目标定义为在固定预算内获得最高绩效指标。为了降低训练成本,提出了两种算法贡献。首先,作者表明,在Transformer编码器架构的每个前馈网络中添加局部机制可以显著提高给定固定资源预算的性能。其次,提出了一种基于图像大小的课程学习策略,以减少训练开始时每个时期的训练时间。训练从小图像开始,然后逐渐将大图像添加到训练中。除了为降低训练成本而引入的算法更改之外,还通过包括资源限制(1 GPU和24小时时间预算)正式定义了在ImageNet1k上的新基准,并在其上评估了模型。
2、本文方法
2.1、Locality in vision Transformer architecture
在本节中,首先解释了ViT架构,然后描述了对架构的更改,以加快训练。
(1)ViT architecture
Vanilla Transformer接收token嵌入的1D序列作为输入。为了处理2D图像,ViT模型将每个输入图像分割成一系列不重叠的reshape 2D块。用可训练的线性投影将面片映射到D维。该投影的输出通常称为patch嵌入。然后,将可学习的位置嵌入添加到块嵌入以编码图像中每个块的位置信息。嵌入向量z'的输出序列用作Transformer编码器的输入。
Transformer编码器由多头自注意力(MSA)和前馈网络(FFN)的交替层组成。在每个块之前应用LayerNorm(LN),在每个块之后应用残差连接。对于具有L个块的Transformer编码器,输出表示按照以下公式计算:
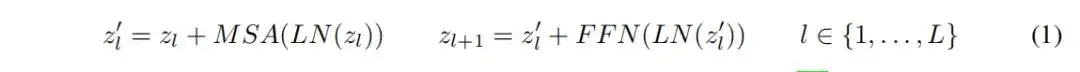
FFN由两个由GELU激活分离的线性层组成。第一个线性层将尺寸从D扩展到4D,第二个线性层则将尺寸从4D减小回D。
(2)Locality in ViT architecture
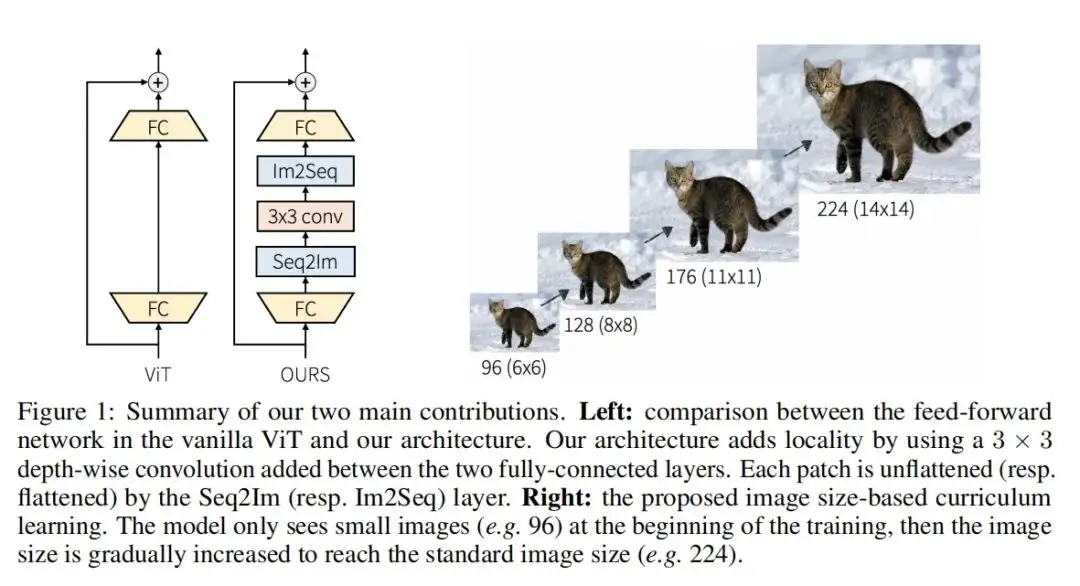
ViT的自注意力层捕获所有patch之间的全局依赖性,但它缺乏局部诱导偏差,特别是允许在局部区域内进行信息交换的机制。为了将局部性引入到vit中,这里只调整了FFN,而其他部分,如自注意力和位置编码,没有改变。作者建议通过在每个FFN中添加深度卷积层来为ViT架构添加局部性。在FFN中的两个FC层之间添加3×3深度卷积(图1)。在每个3×3深度卷积之前,使用序列到图像(Seq2Im)层将每个reshape的块表示转换为2D块表示。类似地,图像到序列(Im2Seq)层用于将每个2D面片表示转换为reshape patch表示。作者还将GELU激活层替换为h-swish。
(3)Connection with existing works
其他工作探索在ViT架构中添加局部性。他们中的大多数人分析局部机制对最终准确性的影响,没有人研究局部机制对训练速度的影响。最接近架构的工作可能是LocalViT,它也在FFN中使用卷积。LocalViT和本文的模型之间有3个主要区别。
- 首先,本文的体系结构使用LayerNorm作为标准化层,而LocalViT使用2D BatchNorm。
- 其次,在本文的架构中,扩展层和压缩层被实现为完全连接层,而LocalViT使用卷积层。
- 最后,本文的体系结构使用h-swish作为激活层,而LocalViT使用h-swish和SE模块的组合。
作者认为,本文的贡献是重要的,并带来了更高效的架构。
2.2、Image size-based curriculum learning
传统上,训练ViT是通过使用从训练数据中均匀采样的224×224 RGB图像的小批量来完成的。每个图像通常被分解为非重叠的16×16块,因此ViT的输入通常是196个扁平Patch的序列。由于注意力机制,普通ViT架构的复杂性与序列长度(即patch数)成二次关系。在本节中探索了一种减少序列长度(即patch数)以加速训练的方法。作者开发了一种基于小到大图像尺寸的课程学习策略,其中在训练开始时使用较短的patch序列。
课程学习的关键思想是从小处开始,学习任务中更容易的方面,然后逐渐提高难度。使用课程学习有不同的方法,但一种流行的方法是从简单的例子开始训练,然后逐渐添加更难的例子。
作者使用图像大小作为图像难度的代表。在训练开始时,使用低分辨率图像对ViT模型进行训练,然后每隔几个Epoch逐渐提高图像分辨率。通过调整输入图像的大小来实现这一点。图1显示了给定图像的不同图像大小(即课程学习步骤)。在每个Epoch中,所有图像都具有相同的大小,但图像大小可以在Epoch之间增加。然后,一个关键问题是如何设计一个好的策略来增加图像大小。首先,重要的是定义初始图像大小,即第一个Epoch的图像大小。然后,重要的是控制图像大小何时增大。这里使用线性规则,每N个时期将图像大小增加M个像素。在实验部分,分析了这些超参数的影响。
通过构造,vision Transformer架构中的所有层(位置嵌入除外)都可以自动适应多个序列长度。在每次图像尺寸增加之后,通过插值来更新位置嵌入。为了避免处理局部块,只使用可以分解为16×16块的图像大小。在训练期间使用多个图像大小也有助于学习更好的比例不变表示。
3、实验
参考
[1].Training a Vision Transformer from scratch in less than 24 hours with 1 GPU.
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
CVPR 2023 | 基于Token对比的弱监督语义分割新方案!
比MobileOne还秀,Apple将重参数与ViT相结合提出FastViT
CVPR 2023 | One-to-Few:没有NMS检测也可以很强很快
ICLR 2023 | Specformer: Spectral GNNs Meet Transformers
AAAI 2023 | 打破NAS瓶颈,AIO-P跨任务网络性能预测新框架
目标检测Trick | SEA方法轻松抹平One-Stage与Two-Stage目标检测之间的差距
CVPR 2023 | 标注500类,检测7000类!清华大学等提出通用目标检测算法UniDetector
CVPR 2023 | 超越MAE!谷歌提出MAGE:图像分类和生成达到SOTA!
CVPR2023 | 书生模型霸榜COCO目标检测,研究团队解读公开
Vision Transformer的重参化也来啦 | RepAdpater让ViT起飞
高效压缩99%参数量!轻量型图像增强方案CLUT-Net开源
一文了解 CVPR 2023 的Workshop 都要做什么
CVPR'23 最新 70 篇论文分方向整理|包含目标检测、图像处理、人脸、医学影像、半监督学习等方向
目标检测无痛涨点新方法 | DRKD蒸馏让ResNet18拥有ResNet50的精度
CVPR2023最新Backbone | FasterNet远超ShuffleNet、MobileNet、MobileViT等模型
CVPR2023 | 集成预训练金字塔结构的Transformer模型
AAAI 2023 | 一种通用的粗-细视觉Transformer加速方案

 浙公网安备 33010602011771号
浙公网安备 33010602011771号