比MobileOne还秀,Apple将重参数与ViT相结合提出FastViT
前言 本文介绍了 FastViT,这是一种混合ViT架构,可获得最先进的延迟-准确性权衡。它引入了一种新颖的token混合运算符 RepMixer,是 FastViT 的构建块,使用结构重新参数化通过删除网络中的跳过连接来降低内存访问成本。进一步应用训练时间过度参数化和大核卷积来提高准确性,并根据经验表明这些选择对延迟的影响最小。
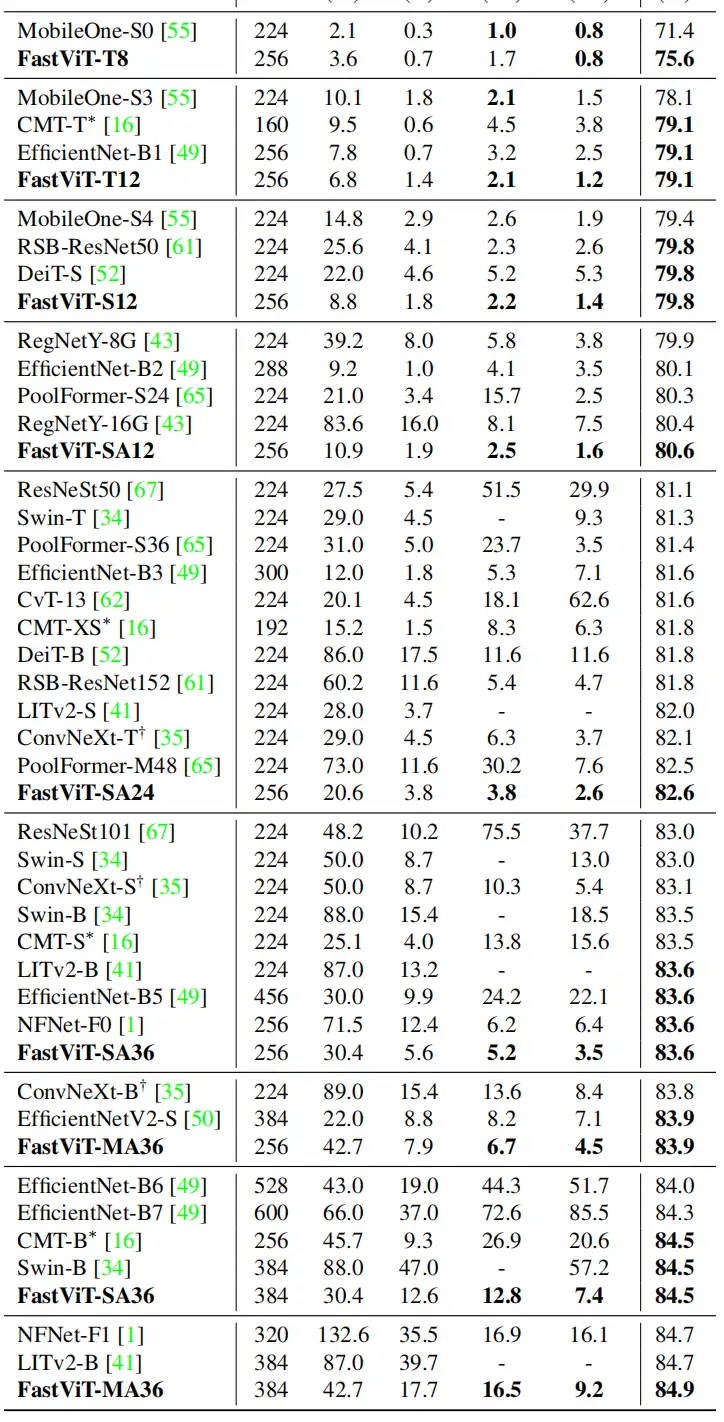
FastViT,模型比 CMT 快 3.5 倍,比 EfficientNet 快 4.9 倍,比移动设备上的 ConvNeXt 快 1.9 倍,在 ImageNet 上的 Top-1 准确率比 MobileOne 高 4.2%。
本文转载自AIWalker
作者 | Happy
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。

论文地址:https://arxiv.org/pdf/2303.14189.pdf
本文提出了一种Hybrid Vision Transformer架构FastViT,它取得了更优的延时-精度均衡。具体来说,
- 提出了一种新的Token Mixing操作RepMixer作为FastViT的基础部件,它采用结构重参数机制移除跳过连接以降低访存占用
- 引入重参数机制与大核卷积进一步提升模型性能;
- 在同等延迟下,相比MobileOne,FastViT精度高出4.2%;在同等精度下,FastViT比EfficientNet快4.9倍,比ConvNeXt快1.9倍。
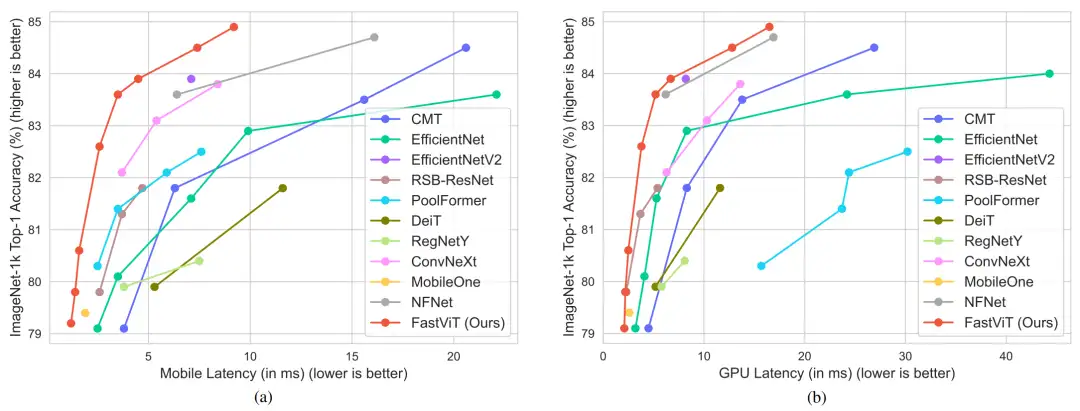
本文方案
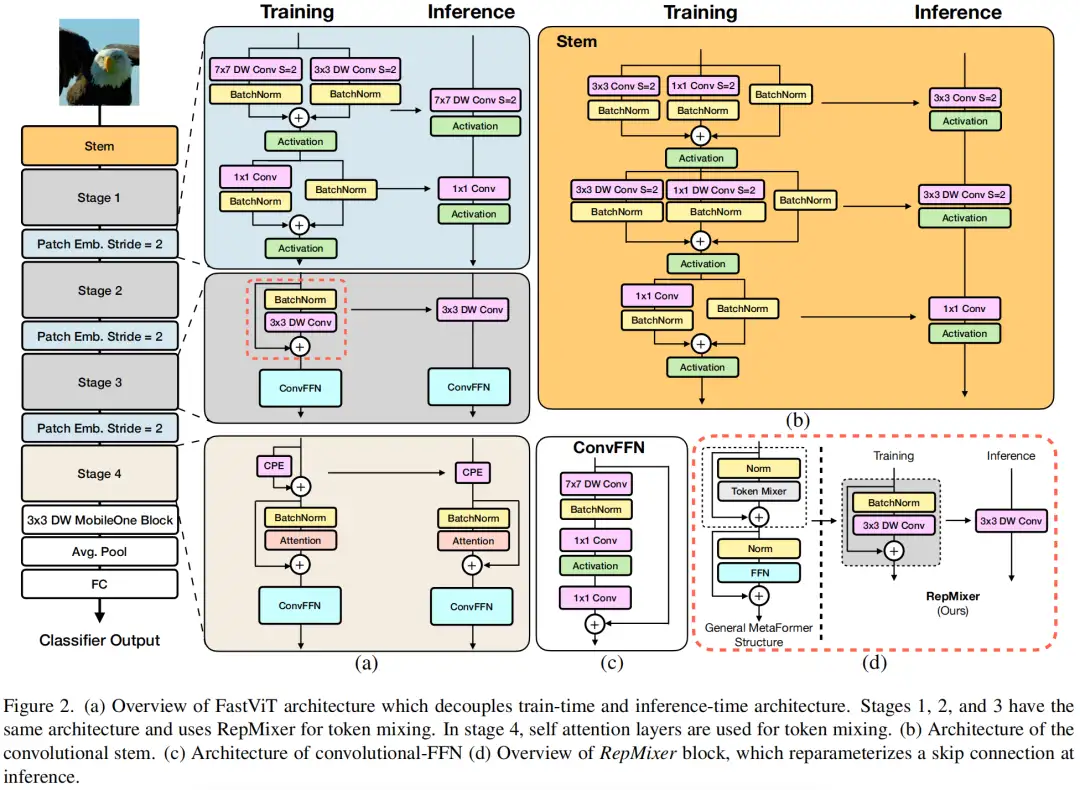
上图给出了本文方案架构示意图,非常经典的4-stage架构。
- 它采用RepMixer作为基础部件,RepMixer采用结构重参数机制移除跳过连接,进而缓解了访问占用消耗(见上图d)。
- 为进一步改善效率与性能,作者将stem与下采样模块的稠密卷积进行拆解并引入重参数机制。
- 自注意力机制在高分辨率阶段计算度过高,作者采用大核卷积作为替代,仅在第4阶段使用自注意力。
RepMixer
ConvMixer采用如下方式进行Token Mixing处理
作者再次基础上进行了简单的重排并移除非线性激活函数
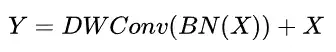
很明显,上述操作在推理阶段可以折叠为简单的DWConv操作。
Empirical Analysis
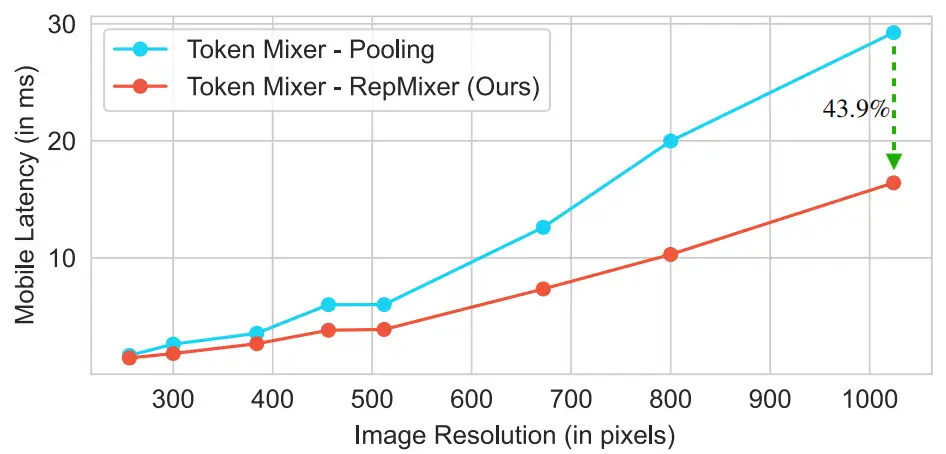
上图对Poolformer与RepMixer进行对比分析,可以看到:相比Pool操作,RepMixer可以大幅改善推理效率。
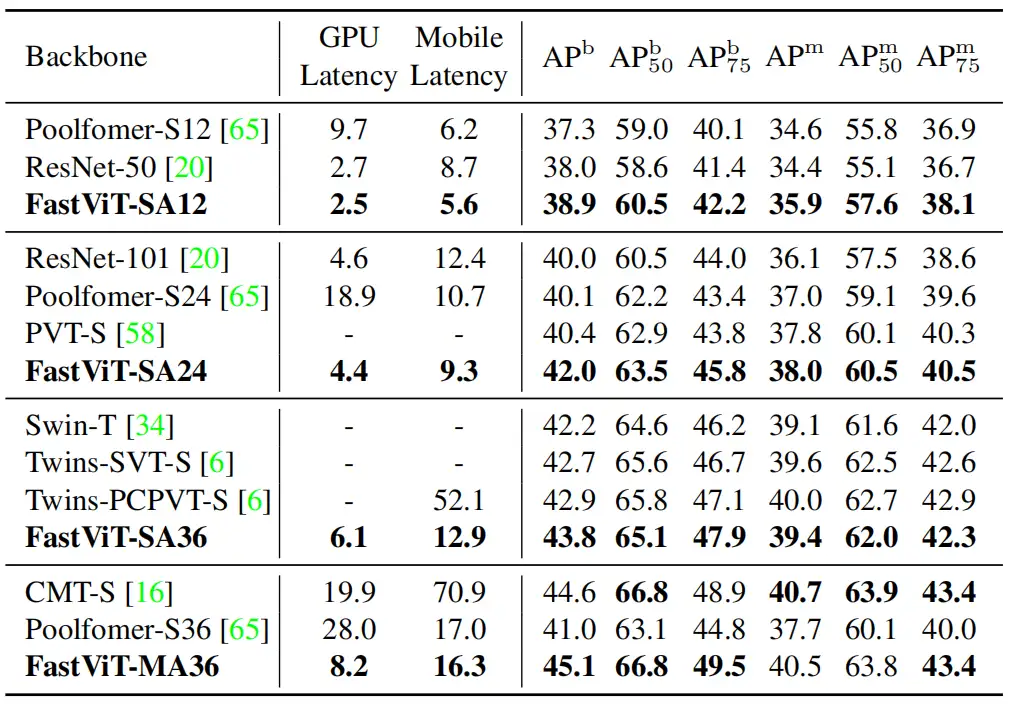
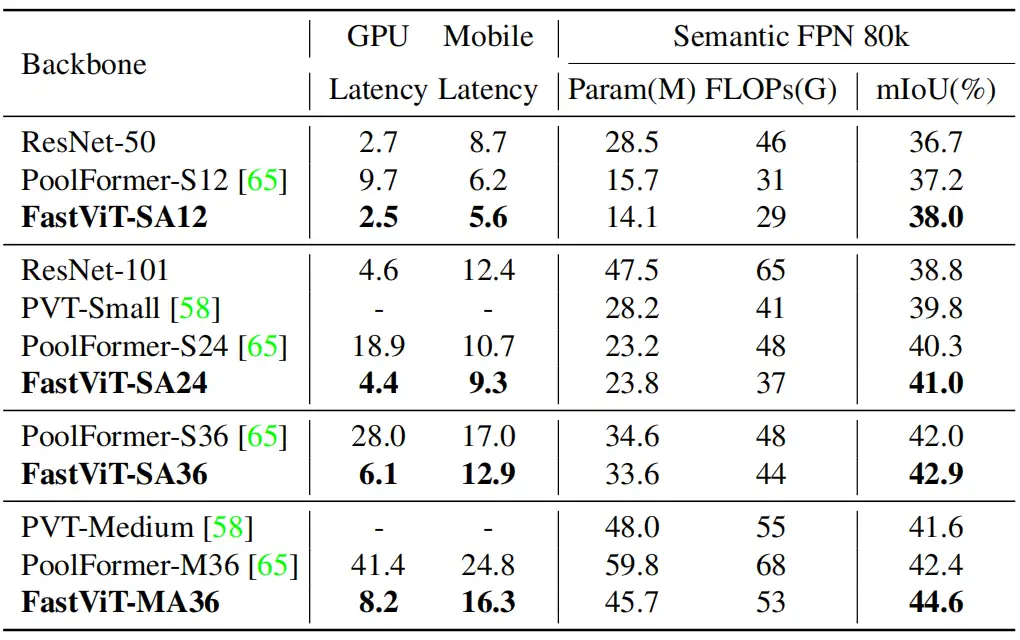
本文实验
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
TSCD:弱监督语义分割新方法,中科院自动化所和北邮等联合提出
如何用单个GPU在不到24小时的时间内从零开始训练ViT模型?
CVPR 2023 | 基于Token对比的弱监督语义分割新方案!
CVPR 2023 | One-to-Few:没有NMS检测也可以很强很快
ICLR 2023 | Specformer: Spectral GNNs Meet Transformers
AAAI 2023 | 打破NAS瓶颈,AIO-P跨任务网络性能预测新框架
目标检测Trick | SEA方法轻松抹平One-Stage与Two-Stage目标检测之间的差距
CVPR 2023 | 标注500类,检测7000类!清华大学等提出通用目标检测算法UniDetector
CVPR 2023 | 超越MAE!谷歌提出MAGE:图像分类和生成达到SOTA!
CVPR2023 | 书生模型霸榜COCO目标检测,研究团队解读公开
Vision Transformer的重参化也来啦 | RepAdpater让ViT起飞
高效压缩99%参数量!轻量型图像增强方案CLUT-Net开源
一文了解 CVPR 2023 的Workshop 都要做什么
CVPR'23 最新 70 篇论文分方向整理|包含目标检测、图像处理、人脸、医学影像、半监督学习等方向
目标检测无痛涨点新方法 | DRKD蒸馏让ResNet18拥有ResNet50的精度
CVPR2023最新Backbone | FasterNet远超ShuffleNet、MobileNet、MobileViT等模型
CVPR2023 | 集成预训练金字塔结构的Transformer模型
AAAI 2023 | 一种通用的粗-细视觉Transformer加速方案

 浙公网安备 33010602011771号
浙公网安备 33010602011771号