ICLR 2023 | Specformer: Spectral GNNs Meet Transformers
前言 本文将为大家介绍北邮 GAMMA Lab在ICLR 2023上的最新中稿论文。该工作提出了一种新的图神经网络架构,称为"Specformer",可以在处理图结构数据时结合频谱滤波器和Transformer模型的优势。
本文转载自北邮 GAMMA Lab
作者 | 薄德瑜
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
论文名称: Specformer: Spectral Graph Neural Networks Meet Transformers
发表会议: ICLR 2023
论文地址: https://openreview.net/pdf?id=0pdSt3oyJa1
1 摘要
图神经网络已经在机器学习领域取得了巨大的成功。根据图信号的处理方式,图神经网络可以大致分为两类,即空域图神经网络和谱域图神经网络。空域图神经网络通常采用消息传递的框架,在节点域通过传播图上的局部信息来学习有用的图表示;谱域图神经网络则通过图滤波器在频谱域对特征进行滤波,通常能够学习到非局部的信息。一个更详细的讨论可以见论文“A Survey on Spectral Graph Neural Networks”。虽然空域图神经网络已经在许多领域取得了令人印象深刻的表现,但是谱域图神经网络仍然没有被充分研究。
谱域图神经网络未能赶上的原因有两个。首先,大多数现有的图滤波器本质上是标量到标量的函数。特别地,它们把一个单一的特征值作为输入,并对所有特征值应用相同的滤波函数。这种滤波机制可能忽略了嵌入在频谱中的丰富信息,即特征值的集合属性。例如,从谱图理论中我们知道,特征值0的代数重数代表着图中连通分量的数量。然而,这样的信息不能被标量到标量的滤波器所捕获。第二,频谱滤波器通常是通过固定(或截断)的正交基近似的,例如切比雪夫多项式和图小波,避免了昂贵的谱分解。虽然正交性是一个很好的属性,但这种截断的近似方法的表现力较差,可能会严重限制图表示学习。
为了提升谱域图神经网络,一个自然的问题是我们如何构建能够有效利用频谱信息且富有表现力的频谱滤波器?,为了回答这个问题,我们首先注意到图拉普拉斯算子的特征值表示频率,即相应特征向量的总变差(total variation)。因此,频率的幅值传达了丰富的信息。此外,两个特征值之间的相对差异也反映了重要的信息,即谱间隙(spectral gap)。为了学习到频率的幅值和频率的相对大小,我们提出了一种基于Transformer的集合到集合图谱滤波器,称为Specformer。它首先通过位置嵌入对特征值进行编码,然后利用自注意力机制从特征值集合中学习相关信息。依靠学习到的特征值表示,我们还设计了一个带有一组可学习基的解码器。最后,通过组合这些基,Specformer可以构造一个置换等变和非局部图卷积。
2 方法
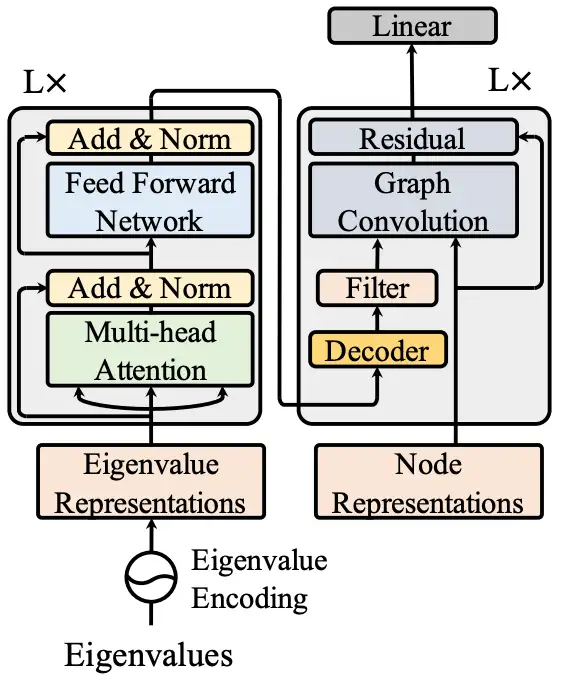
2.1 特征值编码
我们利用Transformer中的自注意力机制来完成特征值之间的交互,以利用所有特征值的幅值和相对差异。然而,如果我们直接使用标量特征值来计算自注意力,其拟合能力将受到严重限制。因此,重要的是找到一个合适的函数来将每个特征值从标量映射乘有意义的向量。我们使用如下特征值编码函数:
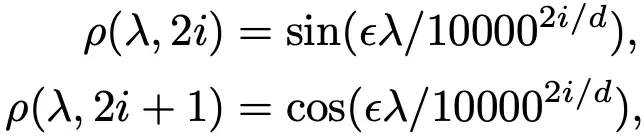
经过特征值编码后,我们将其输入到标准的Transformer网络中进行学习
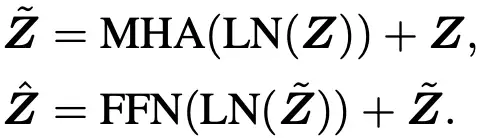
2.2 特征值解码
将Transformer作为编码器对特征值表示进行学习后,解码器可以解码出新的特征值进行滤波。最近的研究表明,为每个特征维度分配一个独立的滤波器可以提高图神经网络的性能。受这一发现的启发,我们的解码器首先解码出几个基滤波器,然后使用神经网络组合这些基以构建最终的图卷积。
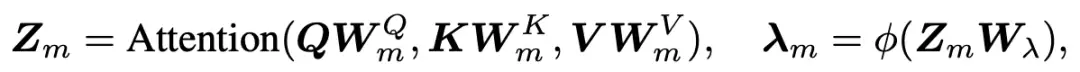
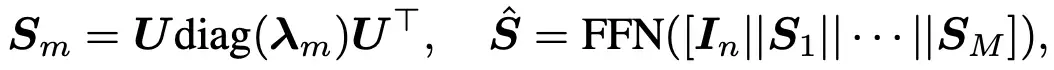
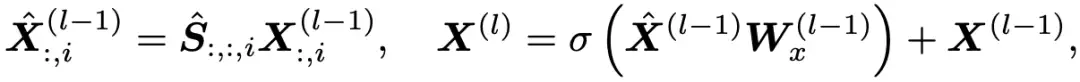
2.3 实验
我们在合成数据的回归任务、节点级别任务和图级别任务上做了大量的实验,验证了模型的有效性。
2.3.1 合成数据
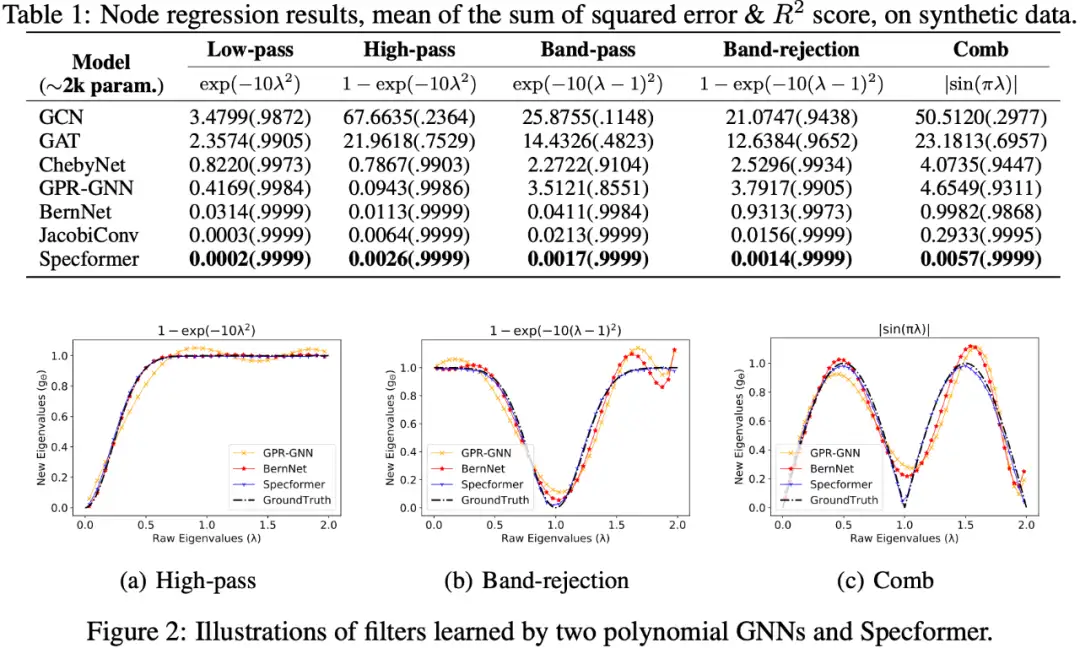
2.3.2 节点级别任务
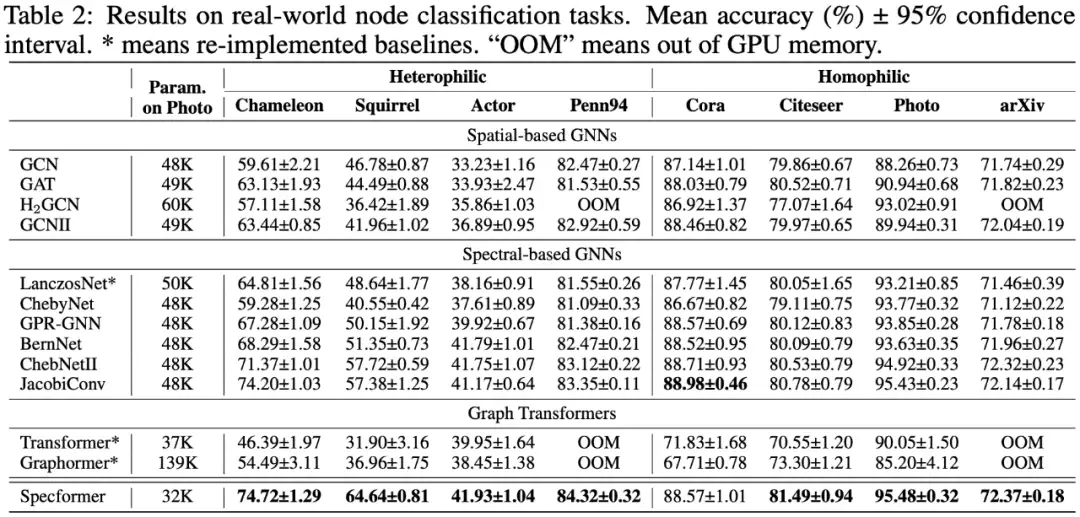
2.3.3 图级别任务
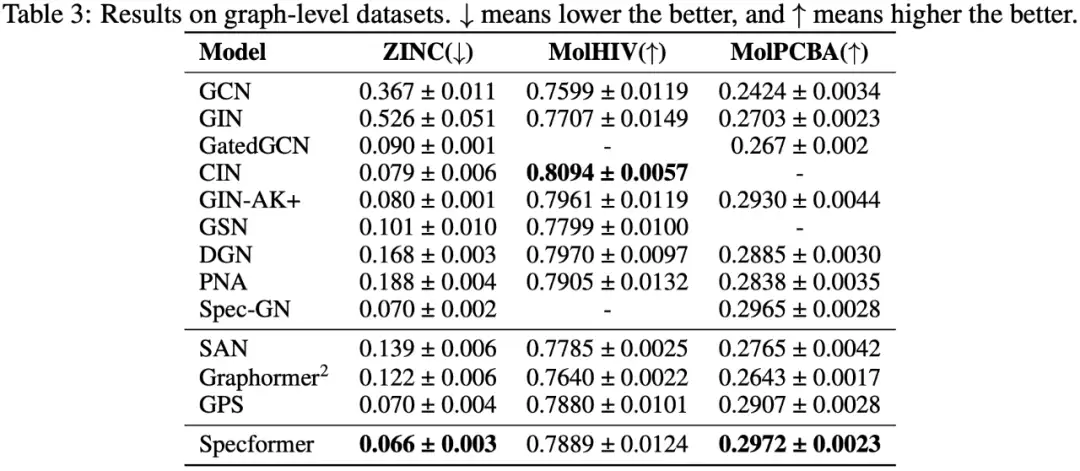
2.3.4 消融实验
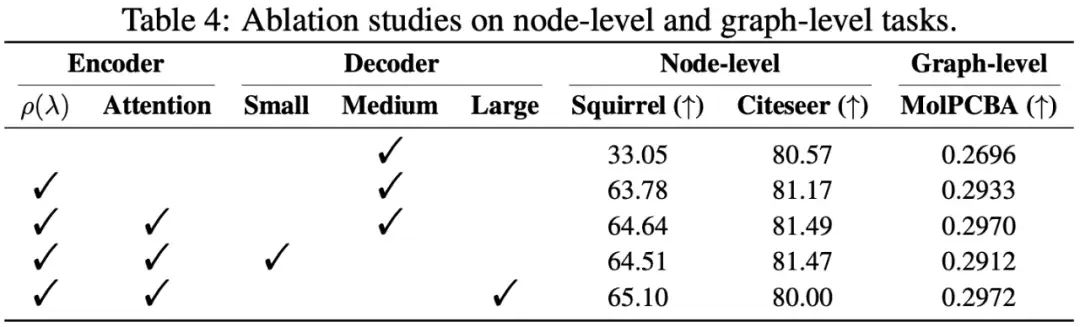
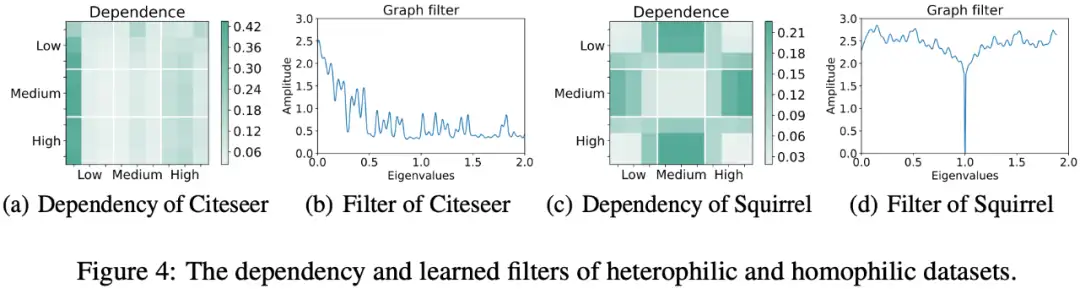
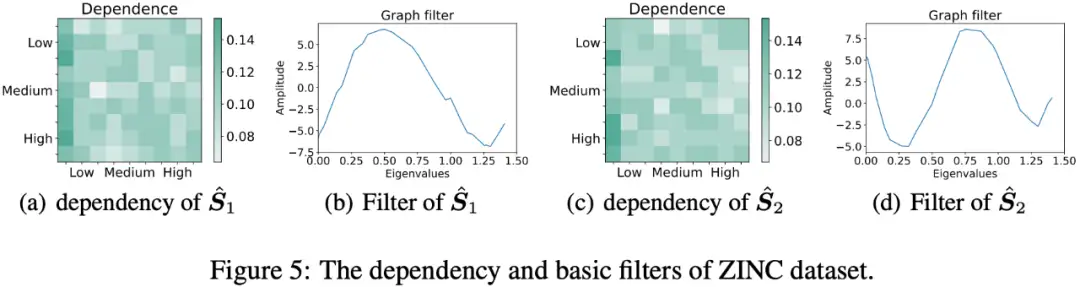
2.3.5 可视化实验
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
CVPR 2023 | 基于Token对比的弱监督语义分割新方案!
比MobileOne还秀,Apple将重参数与ViT相结合提出FastViT
CVPR 2023 | One-to-Few:没有NMS检测也可以很强很快
AAAI 2023 | 打破NAS瓶颈,AIO-P跨任务网络性能预测新框架
目标检测Trick | SEA方法轻松抹平One-Stage与Two-Stage目标检测之间的差距
CVPR 2023 | 标注500类,检测7000类!清华大学等提出通用目标检测算法UniDetector
CVPR 2023 | 超越MAE!谷歌提出MAGE:图像分类和生成达到SOTA!
CVPR2023 | 书生模型霸榜COCO目标检测,研究团队解读公开
Vision Transformer的重参化也来啦 | RepAdpater让ViT起飞
高效压缩99%参数量!轻量型图像增强方案CLUT-Net开源
一文了解 CVPR 2023 的Workshop 都要做什么
CVPR'23 最新 70 篇论文分方向整理|包含目标检测、图像处理、人脸、医学影像、半监督学习等方向
目标检测无痛涨点新方法 | DRKD蒸馏让ResNet18拥有ResNet50的精度
CVPR2023最新Backbone | FasterNet远超ShuffleNet、MobileNet、MobileViT等模型
CVPR2023 | 集成预训练金字塔结构的Transformer模型
AAAI 2023 | 一种通用的粗-细视觉Transformer加速方案

 浙公网安备 33010602011771号
浙公网安备 33010602011771号