CLIP:语言-图像表示之间的桥梁
前言 CLIP的多模态架构通过在相同的潜在空间中学习语言和视觉表现在二者之间建立了桥梁。因此,CLIP允许我们利用其他架构,使用它的“语言-图像表示”进行下游任务。它是一个基于超大数据量的pair-wise 预训练模型但是在它的下游任务DalleE-2,Stable-Diffusion中,CLIP也是其中打通文本和图像的核心模块,比如开源的SD2就是使用了OpenCLIP来学习二者的表示,因此了解CLIP是深入了解后续扩散模型非常重要的一环,所以本文主要介绍一下CLIP。
本文转载自DeepHub IMBA
作者 | P**nHub兄弟网站
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
最近GPT4的火爆覆盖了一个新闻:midjourney v5发布,DALLE2,midjourney都可以从文本中生成图像,这种模型要求人工智能同时理解语言和图像数据。
传统的基于人工智能的模型很难同时理解语言和图像。因为自然语言处理和计算机视觉一直被视为两个独立的领域,这使得机器在两者之间进行有效沟通具有挑战性。
Contrastive Language-Image Pre-training (CLIP)利用自然语言描述图像的数据,训练了一个同时对图像和文本具有深度理解能力的神经网络模型。通过使用自然语言作为监督信号,CLIP 可以自然地跨越多个视觉和语言数据集,且具有较强的可迁移性。CLIP 可以与最先进的视觉和语言模型相媲美,且可以在多个视觉和语言任务上进行零样本学习。
架构
CLIP架构由两个主要组件组成:图像编码器和文本编码器。每个编码器都能够分别理解来自图像或文本的信息,并将这些信息嵌入到向量中。CLIP的思想是在图像-文本对的大型数据集中训练这些编码器,并使嵌入变得相似。
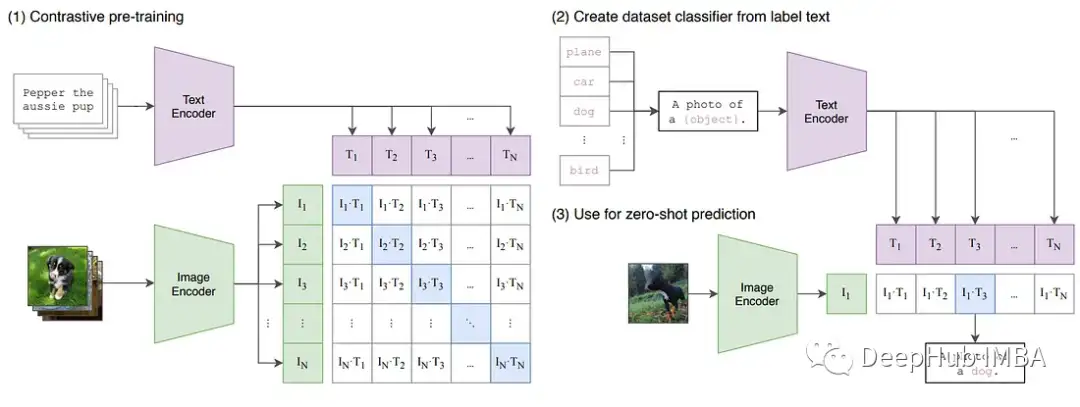
“给定一批N(图像,文本)对,CLIP被训练来预测一批中N × N个可能的(图像,文本)对中哪一个是真实的实匹配。”它通过联合训练编码器来学习多模态嵌入空间,对N个图像和文本嵌入进行余弦相似度的计算,最大小化正确的匹配,最大化不正确的匹配。
由于CLIP是在一个大的预训练数据集上训练的,它可以很好地泛化许多下游任务。CLIP为我们提供了两个编码器,可以将文本和图像嵌入到相同的潜在空间中,所以我们可以有效地将其用于许多应用程序。
应用
以下是一些使用CLIP的下游任务示例:
1、图像分类
CLIP可用于图像分类任务,CLIP将图像与其对应的文本描述相关联的能力使其能够很好地泛化到新的类别,并与其他图像分类模型相比提高性能。
比如说HuggingFace提供了的这个简单的例子
from PIL import Image
import requests
from transformers import CLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # this is the image-text similarity score
probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
2、图像描述
CLIP可用于图像描述任务,利用它将图像与相应的文本描述相关联的能力,我们可以将CLIP与其他序列到序列模型结合起来,使用CLIP的嵌入来生成标题等。我们可以参考我们的CoCa(对比字幕),或者CLIPCap,它将CLIP与GPT模型结合起来生成字幕。
3、文本到图像
CLIP在文本到图像生成上下文中的一个有趣应用是潜在扩散模型。该模型使用CLIP作为一种方法来指导从文本描述中生成逼真的图像。
在潜在扩散模型中使用CLIP有几个优点。首先,它允许模型生成更忠实于文本描述的图像,因为CLIP可以就生成的图像和文本描述之间的语义相似性提供反馈。其次,它允许模型生成更多样化和更有创造性的图像,因为CLIP可以引导生成过程朝着不太常见但仍然合理的图像表示。
CLIP处理图像和文本输入的能力及其预训练过程使其成为各种领域中下游任务的多功能和强大的工具。
总结
CLIP 将语言和图像表示合二为一的能力为许多应用打开了大门。虽然我们人类可以感知不同类型的数据,包括文本、数据、音频等。但是过去基于 AI 的模型已经显示出它们只能理解一种模态的弱点。有了 CLIP,我们可以想象一个未来,人工智能模型可以像我们一样“理解”这个世界。
论文:https://arxiv.org/abs/2103.00020
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
AAAI 2023 | 打破NAS瓶颈,AIO-P跨任务网络性能预测新框架
目标检测Trick | SEA方法轻松抹平One-Stage与Two-Stage目标检测之间的差距
CVPR 2023 | 标注500类,检测7000类!清华大学等提出通用目标检测算法UniDetector
CVPR 2023 | 超越MAE!谷歌提出MAGE:图像分类和生成达到SOTA!
CVPR2023 | 书生模型霸榜COCO目标检测,研究团队解读公开
Vision Transformer的重参化也来啦 | RepAdpater让ViT起飞
高效压缩99%参数量!轻量型图像增强方案CLUT-Net开源
一文了解 CVPR 2023 的Workshop 都要做什么
CVPR'23 最新 70 篇论文分方向整理|包含目标检测、图像处理、人脸、医学影像、半监督学习等方向
目标检测无痛涨点新方法 | DRKD蒸馏让ResNet18拥有ResNet50的精度
CVPR2023最新Backbone | FasterNet远超ShuffleNet、MobileNet、MobileViT等模型
CVPR2023 | 集成预训练金字塔结构的Transformer模型
AAAI 2023 | 一种通用的粗-细视觉Transformer加速方案
大核分解与注意力机制的巧妙结合,图像超分多尺度注意网络MAN已开源!
【免费送书活动】 全新轻量化模型 | 轻量化沙漏网络助力视觉感知涨点

 浙公网安备 33010602011771号
浙公网安备 33010602011771号