CVPR 2023 | 用于半监督目标检测的Active Teacher方法
前言 本文从数据初始化的角度研究师生模型,并提出了一种名为 Active Teacher 的半监督对象检测 (SSOD) 新算法。Active Teacher 将师生框架扩展到迭代版本。同时,还从信息量、多样性和难度等方面考察了样本的选择,让Active Teacher 最大限度地主动选择那些最有可能增加模型准确性的未标记样本,并将这些样本用于半监督目标检测中的训练。
在 COCO baseline上,与一组最近提出的 SSOD 方法进行的实验结果不仅验证了 Active Teacher 相对于比较方法的卓越性能增益,而且表明它使的基准网络,即 Faster-RCNN,能够以更少的标签支出实现 100% 的监督性能,即 40% 的标签MS-COCO 上的示例。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。

论文:https://arxiv.org/pdf/2303.08348.pdf
代码:https://github.com/HunterJ-Lin/ActiveTeacher
论文出发点
一些用于半监督目标检测 (SSOD) 使用 teacher-student 的知识蒸馏方法,这需要 teacher 模型为 student 网络生成高质量的伪标签。虽然自训练产生了大量的伪标签,但真实标签信息在训练初期仍然起着关键作用,它决定了伪标签的质量和教师网络的性能下限,因此,ground-truth 标签信息在 SSOD 中起着重要作用。为了探究如何在 SSOD 中为 teacher-student 选择出最佳的标签样本,作者提出了一种新的知识蒸馏方法 (Active Teacher)。
创新思路
本文提出 Active Teacher 将传统的师生框架扩展为迭代框架,其中标签集部分初始化并通过一种新颖的主动采样策略逐渐扩充。通过这种修改,Active Teacher 可以通过主动采样最大限度地发挥有限标签信息的作用,同时也可以提高伪标签的质量。并且进一步从难度、信息和多样性等方面研究了标签样本的选择,并且这些指标的值自动组合而无需超参数调整。实现通过这些指标,可以探索什么样的数据最适合 SSOD。
方法
Framework
Active Teacher 的总体框架如下图所示,该架构由一个迭代的 teacher-student 结构组成,其中初始化部分标签集并逐渐增加。每次迭代后,使用训练有素的teacher网络根据得到的指标(即信息、多样性和难度)评估未标记示例的重要性,并据此进行数据扩充。
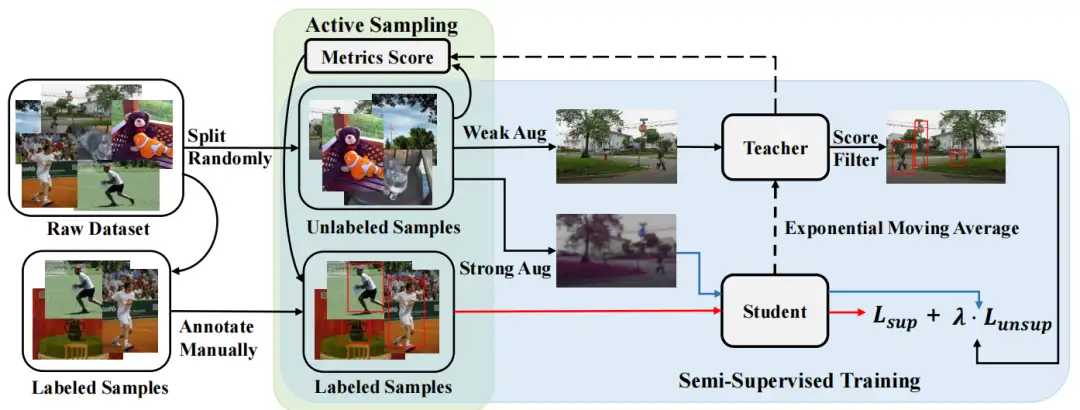
Active Teacher 包括两个检测网络,即Teacher 和 Student具有相同的配置(Faster-RCNN)。Teacher 用于生成训练 Student 的伪标签,其参数通过 EMA 从 Student 逐渐更新。Teacher 还用于估计未标记的样本以进行主动采样。损失函数
Student 模型的损失函数如下:
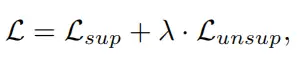
其中,Lsup 和 Lunsup分别代表学生接受了真实标签和伪标签的训练损失 。它们各自的表达式如下:
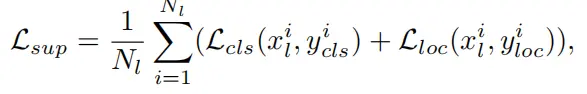
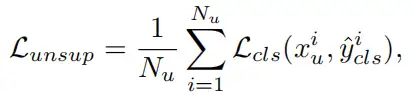
里面的内部式子如下:
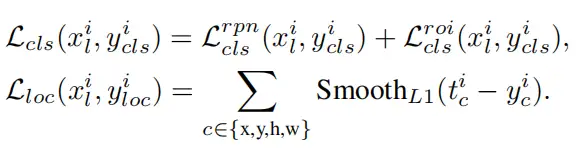
Active Sampling
在每次半监督训练后通过教师网络进行部分标签的初始化和扩充,引入了三个主动采样指标,即Difficulty、Information和Diversity,来衡量什么样的标签对检测任务至关重要。其中,Difficulty根据模型预测的概率分布的熵进行测量。较高的熵表明模型对其预测的不确定性更大,表明样本更困难;Information衡量 SSOD 未标记图像信息量的指标;Diversity衡量图像中对象类别分布的指标。
然后就是对以上三个指标进行组合,由于这些指标的取值范围差异很大,首先需要对其进行归一化。其次,构建一个三维采样空间来将每个样本的这三个指标,每个未标注样本的评价结果都可以看作是这个空间中的一个点。
结果
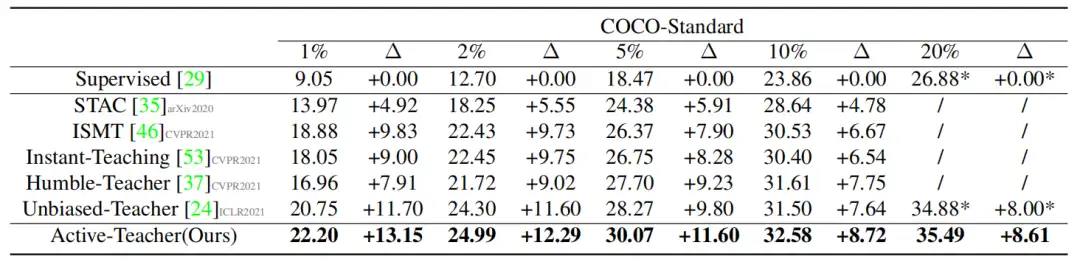
作者在COCO数据集上进行了验证,下面是所提的Active Teacher 与其他 SSOD 方法在 MS-COCO val2017 上对 mAP (50:95) 指标的比较,可以看到所提方法精度达到了SOTA
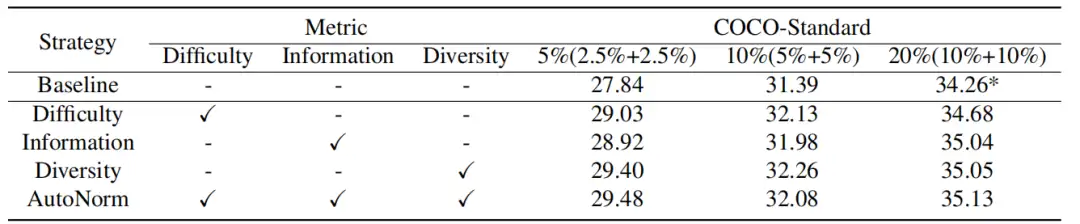
对提出的三个评价指标(Difficulty、Information和Diversity)进行的消融实验,表明它们对于 SSOD 有利
还有检测结果的可视化展示

欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
CVPR2023最新Backbone | FasterNet远超ShuffleNet、MobileNet、MobileViT等模型
CVPR2023 | 集成预训练金字塔结构的Transformer模型
AAAI 2023 | 一种通用的粗-细视觉Transformer加速方案
大核分解与注意力机制的巧妙结合,图像超分多尺度注意网络MAN已开源!
【免费送书活动】 全新轻量化模型 | 轻量化沙漏网络助力视觉感知涨点
目标检测、实例分割、旋转框样样精通!详解高性能检测算法 RTMDet
大卷积模型 + 大数据集 + 有监督训练!探寻ViT的前身:Big Transfer (BiT)
超快语义分割 | PP-LiteSeg集速度快、精度高、易部署等优点于一身,必会模型!!!
AAAI | Panini-Net | 基于GAN先验的退化感知特征插值人脸修
与SENet互补提升,华为诺亚提出自注意力新机制:Weight Excitation
最新FPN | CFPNet即插即用,助力检测涨点,YOLOX/YOLOv5均有效
消费级显卡的春天,GTX 3090 YOLOv5s单卡完整训练COCO数据集缩短11.35个小时

 浙公网安备 33010602011771号
浙公网安备 33010602011771号