CVPR'23 最新 70 篇论文分方向整理|包含目标检测、图像处理、人脸、医学影像、半监督学习等方向
前言 本文近期更新的CVPR 2023 论文,包含目标检测、图像处理、人脸、场景重建、医学影像、半监督学习/弱监督学习/无监督学习/自监督学习等方向,附打包下载链接。
本文转载极市平台
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
项目地址:https://www.cvmart.net/community/detail/7422
以下是最近更新的 CVPR 2023 论文,包含目标检测、图像处理、人脸、场景重建、医学影像、半监督学习/弱监督学习/无监督学习/自监督学习等方向。
检测
2D目标检测(2D Object Detection
[1]CapDet: Unifying Dense Captioning and Open-World Detection Pretraining
paper:https://arxiv.org/abs/2303.02489
[2]Enhanced Training of Query-Based Object Detection via Selective Query Recollection
paper:https://arxiv.org/abs/2212.07593
code:https://github.com/Fangyi-Chen/SQR
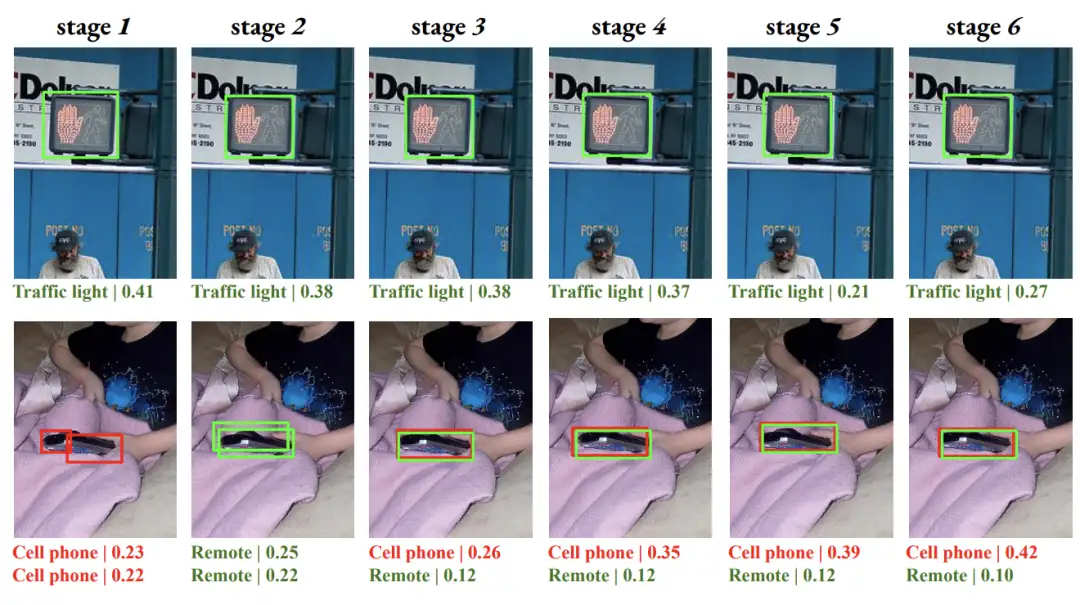
[3]DETRs with Hybrid Matching
paper:https://arxiv.org/abs/2207.13080
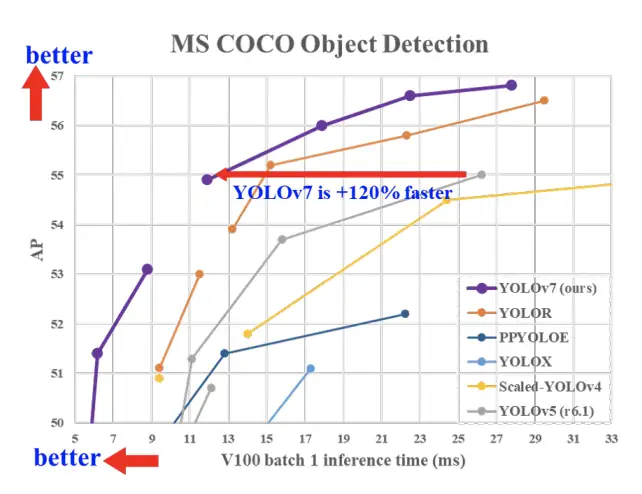
[4]YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors(YOLOv7
paper:https://arxiv.org/abs/2207.02696
code:https://github.com/WongKinYiu/yolov7
视频目标检测(Video Object Detection
[1]SCOTCH and SODA: A Transformer Video Shadow Detection Framework
paper:https://arxiv.org/abs/2211.06885
3D目标检测(3D object detection
[1]MSMDFusion: Fusing LiDAR and Camera at Multiple Scales with Multi-Depth Seeds for 3D Object Detection
paper:https://arxiv.org/abs/2209.03102
code:https://github.com/sxjyjay/msmdfusion
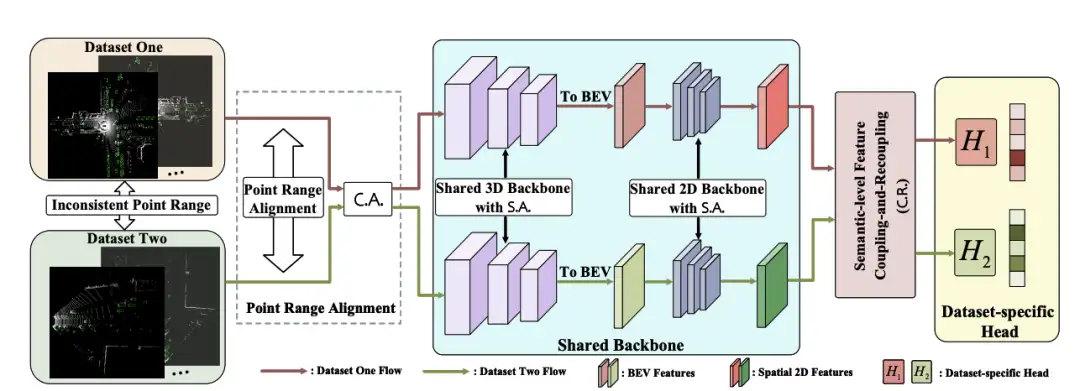
[2]Uni3D: A Unified Baseline for Multi-dataset 3D Object Detection
paper:https://arxiv.org/abs/2303.06880
code:https://github.com/PJLab-ADG/3DTrans
[3]LoGoNet: Towards Accurate 3D Object Detection with Local-to-Global Cross-Modal Fusion
paper:https://arxiv.org/abs/2303.03595
code:https://github.com/sankin97/LoGoNet
[4]ConQueR: Query Contrast Voxel-DETR for 3D Object Detection(3D 目标检测的Query Contrast Voxel-DETR
paper:https://arxiv.org/abs/2212.07289
code:https://github.com/poodarchu/ConQueR
显著性目标检测(Saliency Object Detection
[1]Texture-guided Saliency Distilling for Unsupervised Salient Object Detection
paper:https://arxiv.org/abs/2207.05921
code:https://github.com/moothes/A2S-v2
车道线检测(Lane Detection
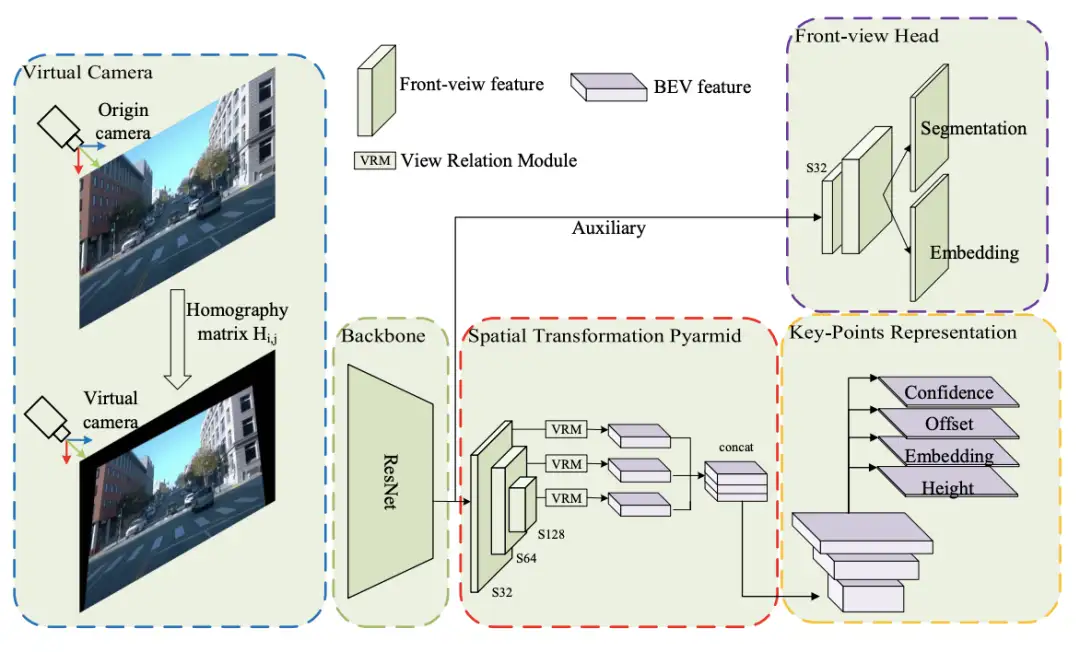
[1]BEV-LaneDet: a Simple and Effective 3D Lane Detection Baseline
paper:https://arxiv.org/abs/2210.06006
异常检测(Anomaly Detection
[1]Block Selection Method for Using Feature Norm in Out-of-distribution Detection
paper:https://arxiv.org/abs/2212.02295
[2]Lossy Compression for Robust Unsupervised Time-Series Anomaly Detection
paper:https://arxiv.org/abs/2212.02303
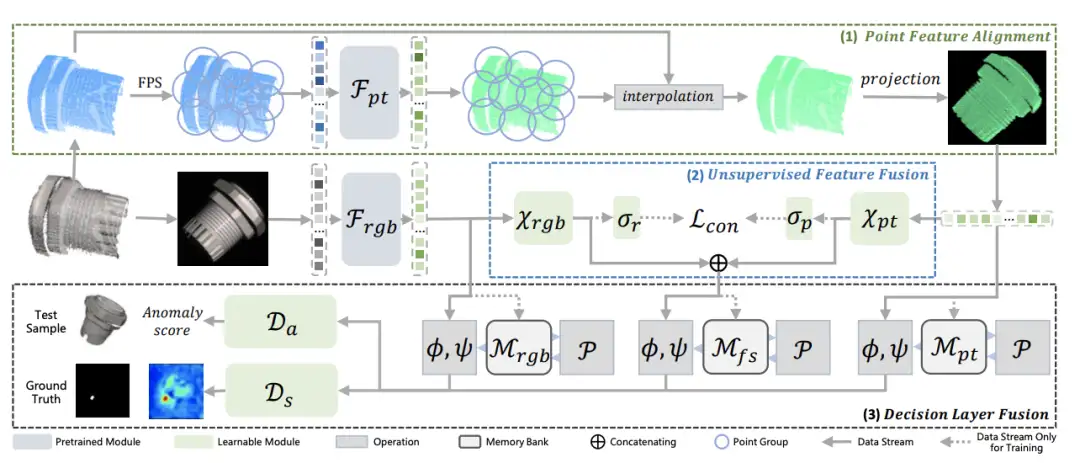
[3]Multimodal Industrial Anomaly Detection via Hybrid Fusion
paper:https://arxiv.org/abs/2303.00601
code:https://github.com/nomewang/M3DM
分割(Segmentation
图像分割(Image Segmentation
[1]MP-Former: Mask-Piloted Transformer for Image Segmentation
paper:https://arxiv.org/abs/2303.07336
code:https://github.com/IDEA-Research/MP-Former
[2]Interactive Segmentation as Gaussian Process Classification
paper:https://arxiv.org/abs/2302.14578
语义分割(Semantic Segmentation
[1]Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP
paper:http://arxiv.org/abs/2210.04150
code:https://github.com/facebookresearch/ov-seg
[2]Efficient Semantic Segmentation by Altering Resolutions for Compressed Videos
paper:https://arxiv.org/abs/2303.07224
code:https://github.com/THU-LYJ-Lab/AR-Seg

[3]SCPNet: Semantic Scene Completion on Point Cloud
paper:https://arxiv.org/abs/2303.06884
[4]On Calibrating Semantic Segmentation Models: Analyses and An Algorithm
paper:https://arxiv.org/abs/2212.12053
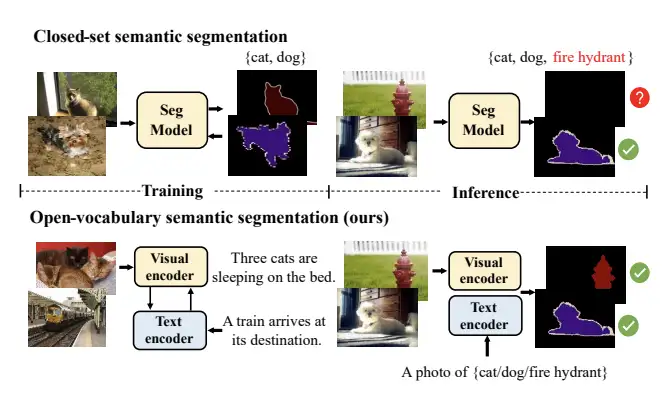
[5]Learning Open-vocabulary Semantic Segmentation Models From Natural Language Supervision
paper:https://arxiv.org/abs/2301.09121
[6]Revisiting Weak-to-Strong Consistency in Semi-Supervised Semantic Segmentation
paper:https://arxiv.org/abs/2208.09910
code:https://github.com/LiheYoung/UniMatch
[7]Foundation Model Drives Weakly Incremental Learning for Semantic Segmentation
paper:https://arxiv.org/abs/2302.14250
实例分割(Instance Segmentation
[1]ISBNet: a 3D Point Cloud Instance Segmentation Network with Instance-aware Sampling and Box-aware Dynamic Convolution
paper:https://arxiv.org/abs/2303.00246
[22]PolyFormer: Referring Image Segmentation as Sequential Polygon Generation(PolyFormer:将图像分割表述为顺序多边形生成
paper:https://arxiv.org/abs/2302.07387
目标跟踪(Object Tracking
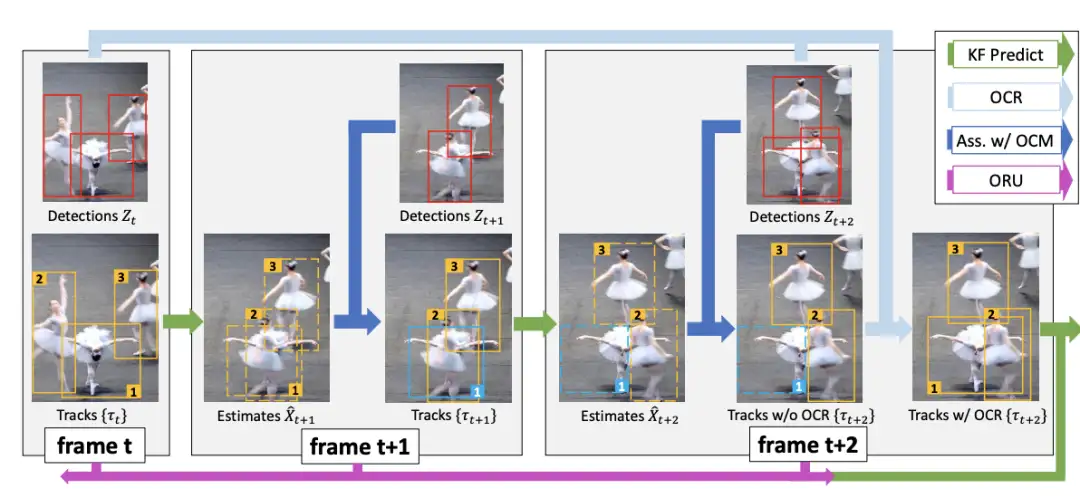
[1]Observation-Centric SORT: Rethinking SORT for Robust Multi-Object Tracking
paper:https://arxiv.org/abs/2203.14360v2
code:https://github.com/noahcao/OC_SORT
[2]Focus On Details: Online Multi-object Tracking with Diverse Fine-grained Representation
paper:https://arxiv.org/abs/2302.14589
[3]Referring Multi-Object Tracking
paper:https://arxiv.org/abs/2303.03366
[4]Simple Cues Lead to a Strong Multi-Object Tracker
paper:https://arxiv.org/abs/2206.04656
图像处理(Image Processing
超分辨率(Super Resolution
[1]Denoising Diffusion Probabilistic Models for Robust Image Super-Resolution in the Wild(野外鲁棒图像超分辨率的去噪扩散概率模型
paper:https://arxiv.org/abs/2302.07864
project:https://sihyun.me/PVDM/
图像复原/图像增强/图像重建(Image Restoration/Image Reconstruction
[1]Learning Distortion Invariant Representation for Image Restoration from A Causality Perspective
paper:https://arxiv.org/abs/2303.06859
code:https://github.com/lixinustc/Casual-IRDIL
[2]DR2: Diffusion-based Robust Degradation Remover for Blind Face Restoration
paper:https://arxiv.org/abs/2303.06885

[3]Robust Unsupervised StyleGAN Image Restoration
paper:https://arxiv.org/abs/2302.06733
[4]Raw Image Reconstruction with Learned Compact Metadata
paper:https://arxiv.org/abs/2302.12995
[5]Efficient and Explicit Modelling of Image Hierarchies for Image Restoration
paper:https://arxiv.org/abs/2303.00748
code:https://github.com/ofsoundof/GRL-Image-Restoration
[6]Imagic: Text-Based Real Image Editing with Diffusion Models
paper:https://arxiv.org/abs/2210.09276
project:https://imagic-editing.github.io/
[7]High-resolution image reconstruction with latent diffusion models from human brain activity
paper:https://www.biorxiv.org/content/10.1101/2022.11.18.517004v2
project:https://sites.google.com/view/stablediffusion-with-brain/
[8]Solving 3D Inverse Problems using Pre-trained 2D Diffusion Models
paper:https://arxiv.org/abs/2211.10655
图像去噪/去模糊/去雨去雾(Image Denoising
[1]Uncertainty-Aware Unsupervised Image Deblurring with Deep Residual Prior
paper:https://arxiv.org/abs/2210.05361
[2]Polarized Color Image Denoising using Pocoformer
paper:https://arxiv.org/abs/2207.00215
[3]Blur Interpolation Transformer for Real-World Motion from Blur
paper:https://arxiv.org/abs/2211.11423
code:https://github.com/zzh-tech/BiT
[4]Structured Kernel Estimation for Photon-Limited Deconvolution
paper:https://arxiv.org/abs/2303.03472
code:https://github.com/sanghviyashiitb/structured-kernel-cvpr23
图像编辑/图像修复(Image Edit/Inpainting
[1]LANIT: Language-Driven Image-to-Image Translation for Unlabeled Data
paper:https://arxiv.org/abs/2208.14889
code:https://github.com/KU-CVLAB/LANIT
图像质量评估(Image Quality Assessment
[1]CR-FIQA: Face Image Quality Assessment by Learning Sample Relative Classifiability
paper:https://arxiv.org/abs/2112.06592
[2]Quality-aware Pre-trained Models for Blind Image Quality Assessment
paper:https://arxiv.org/abs/2303.00521
图像配准(Image Registration
[1]Indescribable Multi-modal Spatial Evaluator
paper:https://arxiv.org/abs/2303.00369
code:https://github.com/Kid-Liet/IMSE/pulse
人脸(Face人脸生成/合成/重建/编辑(Face Generation/Face Synthesis/Face Reconstruction/Face Editing
[1]A Hierarchical Representation Network for Accurate and Detailed Face Reconstruction from In-The-Wild Images
paper:https://arxiv.org/abs/2302.14434
[2]MetaPortrait: Identity-Preserving Talking Head Generation with Fast Personalized Adaptation(MetaPortrait:具有快速个性化适应的身份保持谈话头像生成
paper:https://arxiv.org/abs/2212.08062
code:https://github.com/Meta-Portrait/MetaPortrait
人脸伪造/反欺骗(Face Forgery/Face Anti-Spoofing
[1]Physical-World Optical Adversarial Attacks on 3D Face Recognition
paper:https://arxiv.org/abs/2205.13412
医学影像(Medical Imaging
[1]Deep Feature In-painting for Unsupervised Anomaly Detection in X-ray Images
paper:https://arxiv.org/pdf/2111.13495.pdf
code:https://github.com/tiangexiang/SQUID
[2]Label-Free Liver Tumor Segmentation
paper:https://arxiv.org/pdf/2210.14845.pdf
code:https://github.com/MrGiovanni/SyntheticTumors
图像生成/图像合成(Image Generation/Image Synthesis
[1]DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
paper:https://arxiv.org/abs/2208.12242
code:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/ppdiffusers/examples/dreambooth

[2]Progressive Open Space Expansion for Open-Set Model Attribution
paper:https://arxiv.org/abs/2303.06877
code:https://github.com/tianyunyoung/pose
[3]Person Image Synthesis via Denoising Diffusion Model
paper:https://arxiv.org/abs/2211.12500
[4]Solving 3D Inverse Problems using Pre-trained 2D Diffusion Models(使用预训练的 2D 扩散模型解决 3D 逆问题
paper:https://arxiv.org/abs/2211.10655
[5]Parallel Diffusion Models of Operator and Image for Blind Inverse Problems(盲反问题算子和图像的并行扩散模型
paper:https://arxiv.org/abs/2211.10656
场景重建/视图合成/新视角合成(Novel View Synthesis
[1]3D Video Loops from Asynchronous Input
paper:https://arxiv.org/abs/2303.05312
code:https://github.com/limacv/VideoLoop3D
[2]NeRFLiX: High-Quality Neural View Synthesis by Learning a Degradation-Driven Inter-viewpoint MiXer
paper:https://arxiv.org/abs/2303.06919

[3]NeRF-Gaze: A Head-Eye Redirection Parametric Model for Gaze Estimation
paper:https://arxiv.org/abs/2212.14710
[4]Renderable Neural Radiance Map for Visual Navigation
paper:https://arxiv.org/abs/2303.00304
[5]Real-Time Neural Light Field on Mobile Devices
paper:https://arxiv.org/abs/2212.08057
project:https://snap-research.github.io/MobileR2L/
[6]Latent-NeRF for Shape-Guided Generation of 3D Shapes and Textures
paper:https://arxiv.org/abs/2211.07600
code:https://github.com/eladrich/latent-nerf
[7]NoPe-NeRF: Optimising Neural Radiance Field with No Pose Prior
paper:https://arxiv.org/abs/2212.07388
project:https://nope-nerf.active.vision/
多模态学习(Multi-Modal Learning
[1]Align and Attend: Multimodal Summarization with Dual Contrastive Losses
paper:https://arxiv.org/abs/2303.07284
code:https://boheumd.github.io/A2Summ/
[2]Towards All-in-one Pre-training via Maximizing Multi-modal Mutual Information(通过最大化多模态互信息实现一体化预训练
paper:https://arxiv.org/abs/2211.09807
code:https://github.com/OpenGVLab/M3I-Pretraining
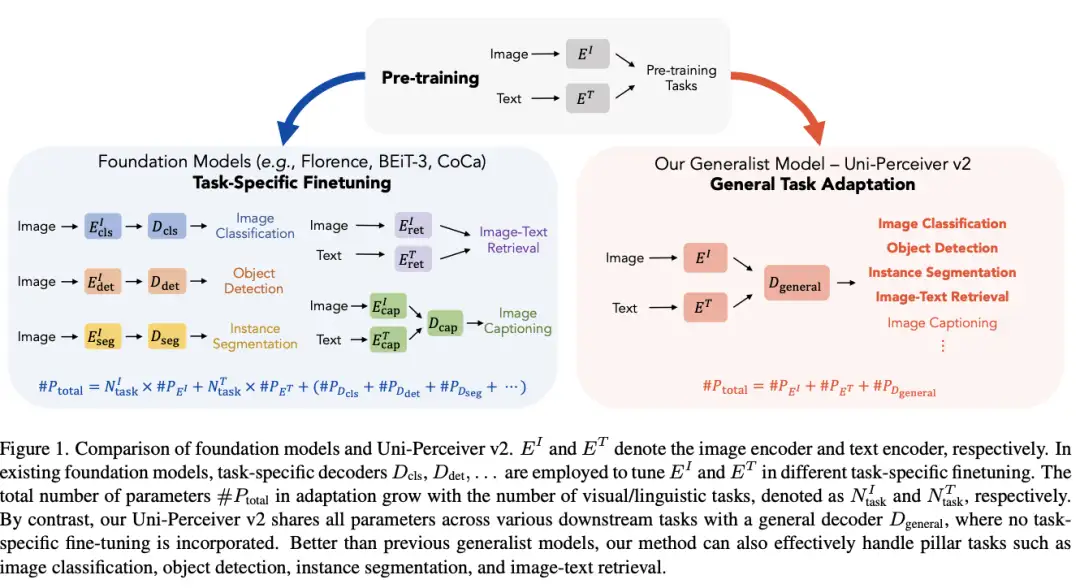
[3]Uni-Perceiver v2: A Generalist Model for Large-Scale Vision and Vision-Language Tasks(Uni-Perceiver v2:用于大规模视觉和视觉语言任务的通才模型
paper:https://arxiv.org/abs/2211.09808
code:https://github.com/fundamentalvision/Uni-Perceiver
半监督学习/弱监督学习/无监督学习/自监督学习(Self-supervised Learning/Semi-supervised Learning)
[1]The Dialog Must Go On: Improving Visual Dialog via Generative Self-Training
paper:https://arxiv.org/abs/2205.12502
code:https://github.com/gicheonkang/gst-visdial
[2]Three Guidelines You Should Know for Universally Slimmable Self-Supervised Learning
paper:https://arxiv.org/abs/2303.06870
code:https://github.com/megvii-research/US3L-CVPR2023
[3]Mask3D: Pre-training 2D Vision Transformers by Learning Masked 3D Priors
paper:https://arxiv.org/abs/2302.14746
[4]Siamese Image Modeling for Self-Supervised Vision Representation Learning
paper:https://arxiv.org/abs/2206.01204
code:https://github.com/fundamentalvision/Siamese-Image-Modeling
[5]Cut and Learn for Unsupervised Object Detection and Instance Segmentation
paper:https://arxiv.org/abs/2301.11320
project:http://people.eecs.berkeley.edu/~xdwang/projects/CutLER/
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
CVPR2023最新Backbone | FasterNet远超ShuffleNet、MobileNet、MobileViT等模型
CVPR2023 | 集成预训练金字塔结构的Transformer模型
AAAI 2023 | 一种通用的粗-细视觉Transformer加速方案
大核分解与注意力机制的巧妙结合,图像超分多尺度注意网络MAN已开源!
【免费送书活动】 全新轻量化模型 | 轻量化沙漏网络助力视觉感知涨点
目标检测、实例分割、旋转框样样精通!详解高性能检测算法 RTMDet
大卷积模型 + 大数据集 + 有监督训练!探寻ViT的前身:Big Transfer (BiT)
超快语义分割 | PP-LiteSeg集速度快、精度高、易部署等优点于一身,必会模型!!!
AAAI | Panini-Net | 基于GAN先验的退化感知特征插值人脸修
与SENet互补提升,华为诺亚提出自注意力新机制:Weight Excitation
最新FPN | CFPNet即插即用,助力检测涨点,YOLOX/YOLOv5均有效
消费级显卡的春天,GTX 3090 YOLOv5s单卡完整训练COCO数据集缩短11.35个小时

 浙公网安备 33010602011771号
浙公网安备 33010602011771号