CVPR 2023 | 腾讯优图实验室21篇论文入选,含多模态、工业异常检测、动态表情识别、活体检测等领域
前言 今年腾讯优图实验室共有21篇论文入选CVPR2023,内容涵盖了多模态、工业异常检测、动态表情识别、活体检测等研究方向,展示了腾讯优图在人工智能领域的技术能力和学术成果。本文介绍了腾讯优图实验室入选论文及方法概述。
本文转载自腾讯优图
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
计算机视觉三大顶级会议之一CVPR 2023 论文接收结果出炉!近年来,CVPR投稿数量正持续增加,今年更是收到有效投稿9155篇,创下历史新高!最终,大会收录论文2360篇,接收率为 25.78 %。
本次,腾讯优图实验室共有21篇论文入选,内容涵盖多模态、工业异常检测、动态表情识别、活体检测等多个领域。
以下为入选论文简介:
01
再思考梯度投影连续学习:稳定性/塑性特征空间解耦
Rethinking Gradient Projection Continual Learning: Stability / Plasticity Feature Space Decoupling
*本文由腾讯优图实验室和华东师范大学共同完成
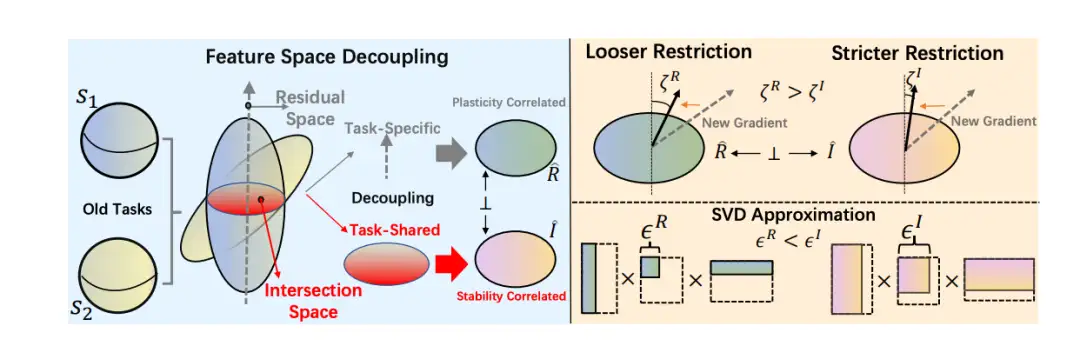
持续学习的目的是随着时间的推移逐步学习新的课程,同时不忘记所学的知识。最近的研究发现,如果更新的梯度与特征空间正交,学习不会忘记。然而,先前的方法要求梯度与整个特征空间完全正交,导致塑性差,因为当任务不断到来时,可行的梯度方向变窄,即特征空间无限扩展。在本文中,我们提出了一种空间解耦(SD)算法,将特征空间解耦为一对互补子空间,即稳定性空间i和塑性空间R。R是通过寻找I的正交互补子空间来构造的,因此I主要包含更多的任务特定基。通过对R和I施加区分约束,我们的方法在稳定性和塑性之间实现了更好的平衡。通过将SD应用于梯度投影基线,进行了广泛的实验,结果表明SD与模型无关,并在公开可用的数据集上实现了SOTA结果。
02
自适应几何感知局部特征匹配
Adaptive Assignment for Geometry Aware Local Feature Matching
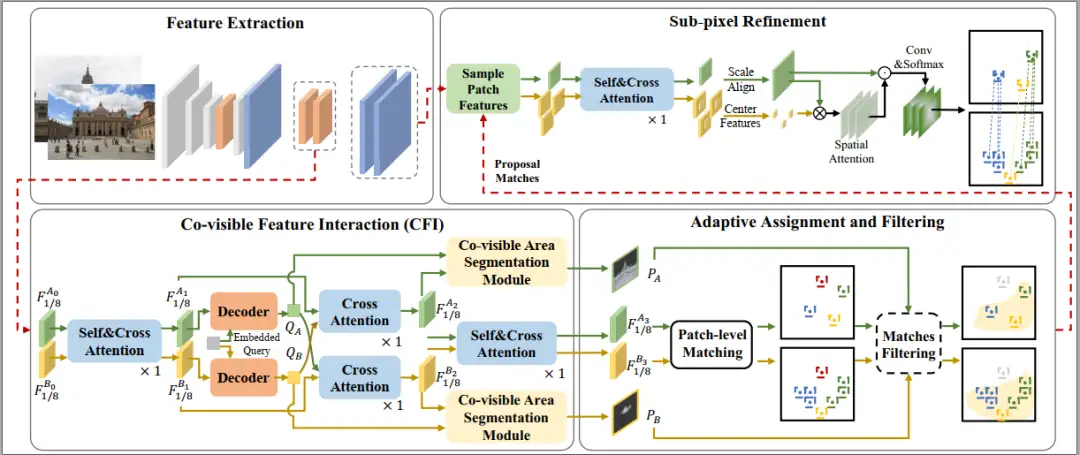
detector-free的特征匹配方法因其出色的性能而受到广泛关注。然而,在大尺度和视角变换场景下,由于匹配中应用了相互最近邻准则,该方法仍存在问题。因此我们引入了AdaMatcher,它通过精心设计的特征交互模块首先实现特征相关性和共视区域估计,然后在估计图像之间的尺度的同时对图像块进行自适应分配,最后通过尺度对齐和亚像素回归模块进一步完善共视匹配。
广泛的实验表明,AdaMatcher在公开数据集上取得了SOTA结果。此外,自适应分配和亚像素细化模块可以用作其他匹配方法(如SuperGlue)等,以进一步提高其性能。
03
基于自监督对抗噪声擦除的噪声标签学习方法
Learning with Noisy labels via Self-supervised Adversarial Noisy Masking
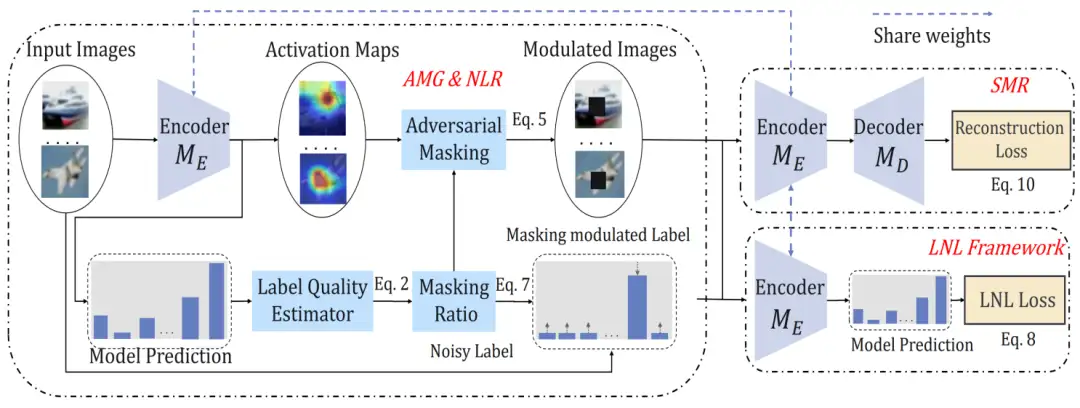
收集大规模数据集对于训练深度模型和注释数据至关重要,然而,不可避免地会产生带有噪声的标签,这给深度学习算法带来了挑战。以往的研究通过识别和删除噪声样本或根据训练样本之间的统计特性(例如损失值)来纠正它们的标签,以缓解这个问题。本文旨在从一个新的角度解决这个问题,深入研究深度特征图,我们实证发现,使用干净和错误标记的样本训练的模型表现出具有可区分性的激活特征分布。从这个观察中,我们提出了一种新的鲁棒性训练方法,称为对抗性噪声掩模。其思想是使用一个标签质量引导的掩蔽方案来规范深度特征,该方案自适应地调节输入数据和标签,防止模型过度拟合噪声样本。此外,我们设计了一个辅助任务来重构输入数据,它提供了无噪声的自监督信号,以增强深度模型的泛化能力。我们提出的方法简单高效,已在合成和真实世界的噪声数据集上进行了测试,在之前的先进方法上取得了显著的改进。
论文下载地址:
https://arxiv.org/pdf/2302.06805.pdf
04
DMLP:基于解耦的标签元纠正器的
噪声标签学习方法
Learning from Noisy Labels with Decoupled Meta Label Purifier
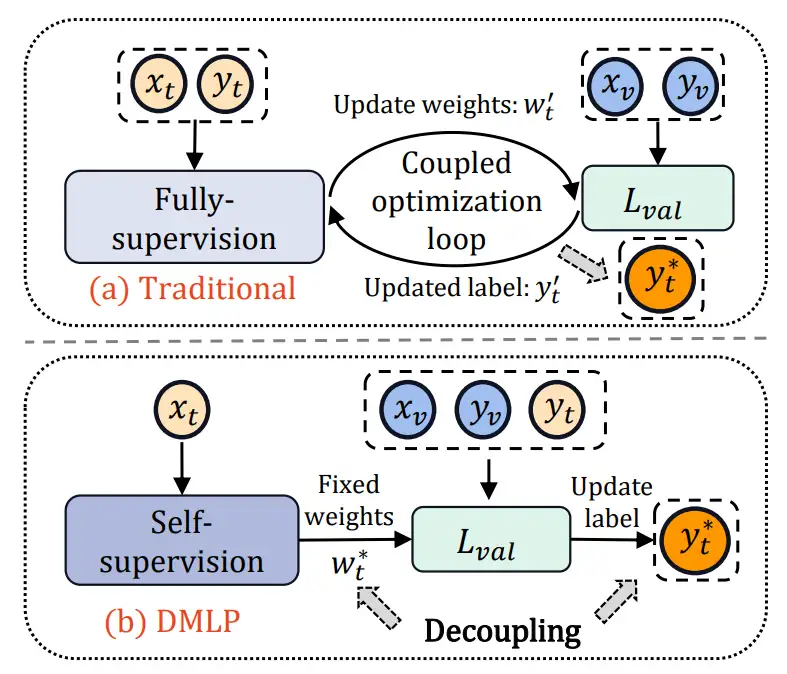
使用含有标签噪声的数据上训练深度神经网络非常具有挑战性,因为DNN很容易记住含有噪声的标签,从而导致其泛化能力差。最近,采用基于元学习的标签纠正策略广泛应用于解决此问题,通过借助一小部分干净的验证数据来识别和纠正潜在的噪声标签。虽然使用纯净的标签进行训练可以有效提高性能,但解决元学习问题不可避免地涉及模型权重和超参数(即标签分布)之间的双层优化嵌套循环。作为一种退而求其次的方法,先前的论文采用交替更新的耦合学习过程。本文实证发现,这种同时对模型权重和标签分布进行优化的优化方式无法达到最优效果,从而限制了主干网络的表示能力和标签校正器的准确性。基于这一观察,提出了一种新的多阶段标签净化器,称为DMLP。DMLP将标签校正过程分解为无标签表示学习和简单的元标签校正器,从而可以专注于在两个不同的阶段中提取高效特征和校正标签。DMLP是一种即插即用的标签净化器,净化后的标签可以直接在原始的端到端网络中进行重新训练或其他鲁棒学习方法中结合使用,我们的方法在多个合成和真实的噪声数据集中获得了最先进的结果,特别是在高噪声水平下。
论文下载地址:
https://arxiv.org/pdf/2302.06810.pdf
05
MixTeacher:
基于混合尺度教师模型的半监督目标检测
MixTeacher: Mining Promising Labels with Mixed Scale Teacher for Semi-supervised Object Detection
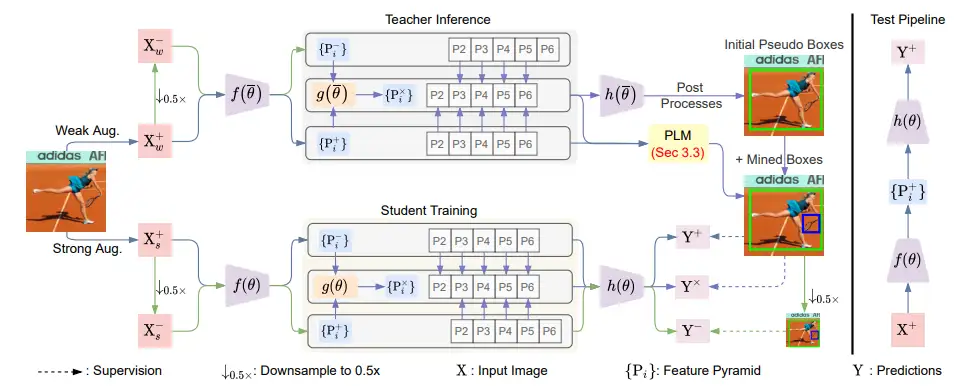
实例间的尺度变化是目标检测中的一个关键挑战。虽然现代检测模型在处理尺度变化方面取得了显著进展,但在半监督情况下仍然存在问题。大多数现有的半监督目标检测方法依赖于严格的条件来筛选网络预测中的高质量伪标签。然而,我们观察到具有极端尺度的目标往往具有较低的置信度,这使得这些目标的正向监督缺失。在本文中,我们深入探讨了尺度变化问题,并提出了一种新的框架,通过引入混合尺度教师来改进伪标签生成和尺度不变学习。此外,由于混合尺度特征的更好预测,我们提出利用跨尺度预测的分数的相对提升来挖掘伪标签。在不同的半监督设置下,对 MS COCO 和 PASCAL VOC 基准进行了大量实验,证明我们的方法实现了新的最先进性能。
06
基于多模态融合的工业异常检测方法
Multimodal Industrial Anomaly Detection via Hybrid Fusion
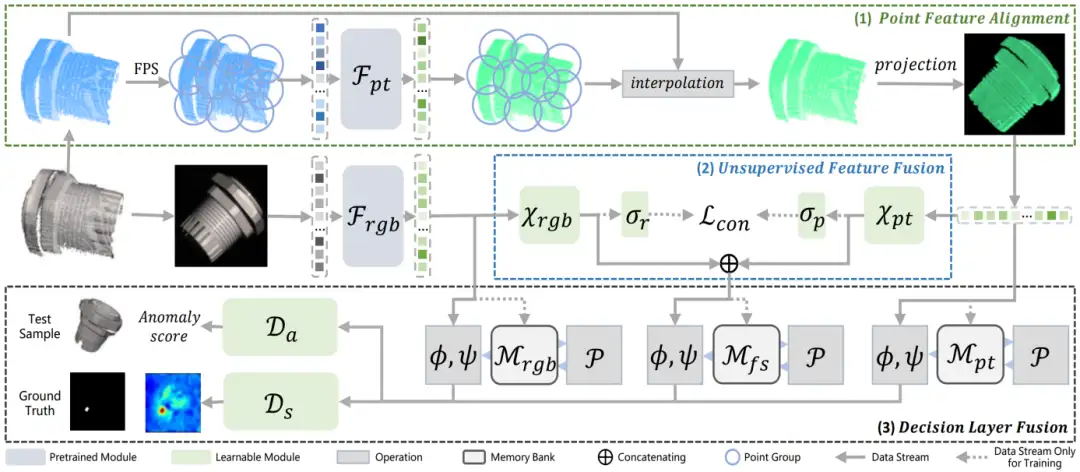
基于2D的工业异常检测已经被广泛研究,然而基于3D点云和RGB图像的多模态工业异常检测仍有许多未涉及的领域。现有的多模态工业异常检测方法直接连接多模态特征,这导致特征之间发生强干扰并损害检测性能。本文提出了一种新的多模态异常检测方法Multi-3D-Memory (M3DM),采用多模态融合方案:首先,我们设计了一种无监督特征融合方法,采用基于图像块的对比学习来促进不同模态特征之间的交互;其次,我们使用多个存储器库的决策层融合来避免信息丢失,并使用额外的分类器来做出最终决策。我们进一步提出了一种点特征对齐操作,以更好地对齐点云和RGB特征。大量的实验表明,我们的多模态工业异常检测模型在MVTec-3D AD数据集上的检测和分割精度均优于现有的最先进方法。
论文下载地址:
https://arxiv.org/pdf/2303.00601.pdf
07
基于热图蒸馏的标记化人体姿态估计
DistilPose: Tokenized Pose Regression with Heatmap Distillation
*本文由腾讯优图实验室和厦门大学共同完成
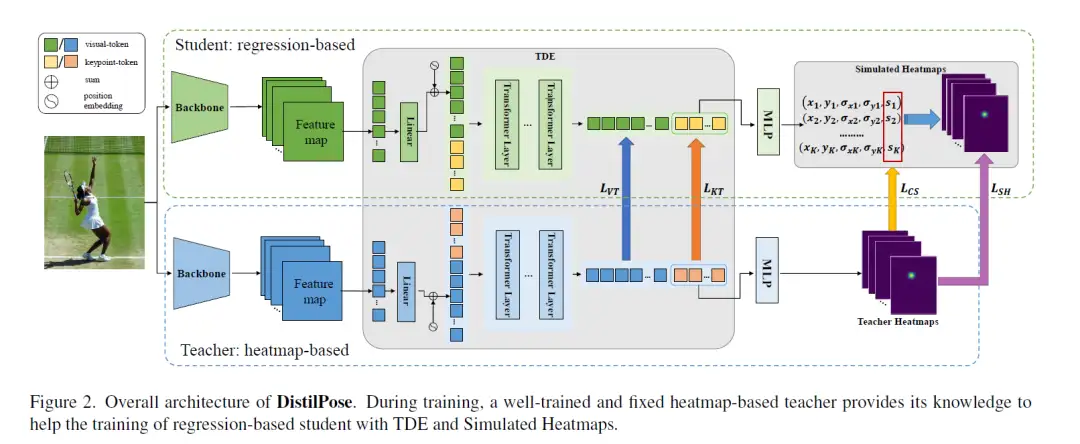
在人体姿态估计领域,基于回归的方法在速度方面占据优势,而基于热图的方法在性能方面领先。如何结合这两种方案的优势仍然是一个具有挑战性的问题。在本文中,我们提出了一种名为DistilPose的新型人体姿势估计框架,它弥合了基于回归和基于热图的方法之间的差距。具体来说,DistilPose通过标记蒸馏编码器 (TDE) 和模拟热图最大限度地将知识从教师模型(热图模型)转移到学生模型(回归模型)。TDE 通过引入标记化来对齐基于热图和基于回归的模型的特征空间,而模拟热图将分布和置信度从教师热图转移到学生模型中。实验表明,我们提出的 DistilPose 可以在保持速度的同时显着提高基于回归的模型的性能。
具体来说,在MSCOCO验证数据集上,DistilPose-S获得了71.6%的mAP,参数为5.36M,GFLOPs为2.38,FPS为40.2,节省了12.95×,7.16×计算成本,比其教师模型快 4.9 倍,性能仅下降 0.9 分。此外,DistilPose-L 在 MSCOCO 验证数据集上获得了 74.4% 的 mAP,在基于回归的主要模型中实现了SOTA结果。
论文下载地址:
https://arxiv.org/pdf/2303.02455.pdf
08
基于概率融合的人脸知识蒸馏
Probabilistic Knowledge Distillation of Face Ensembles
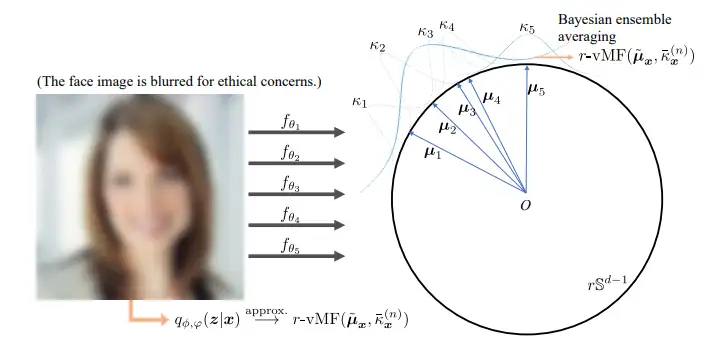
平均集成(即对多个模型的预测进行平均)是机器学习中的一种常用技术,可提高每个模型的性能。我们将其形式化为开放式人脸识别中集成的特征对齐,并通过概率建模的视角将其推广到贝叶斯集成平均 (BEA)。这种概括带来了现有方法无法提供的两个实际好处:
(1)人脸图像的不确定性可被评估并进一步分解为任意不确定性和认知不确定性,后者可以用作对面部分布检测;
(2)BEA统计量可证明地反映了人脸图像的任意不确定性,作为人脸图像质量的度量以提高识别性能。
为了在不损失推理效率的情况下继承BEA的不确定性估计能力,我们提出了BEA-KD,这是一种从BEA中提取知识的学生模型。BEA-KD模仿合奏成员的整体行为并且在各种具有挑战性的基准测试中始终优于SOTA知识蒸馏方法。
09
Sibling-Attack:重新思考针对人脸任务的对抗样本迁移性提升方法
Sibling-Attack: Rethinking Transferable Adversarial Attacks against Face Recognition
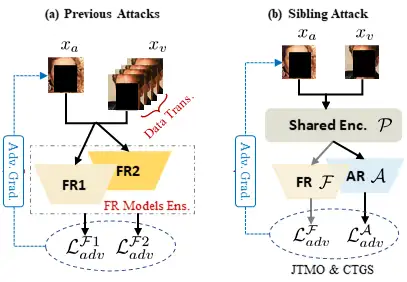
目前对抗样本的迁移性仍有较大提升空间,针对该问题,我们提出了一种新的人脸识别对抗样本迁移性提升技术Sibling-Attack,本技术首次从多任务视角对迁移性黑盒攻击进行了探索,利用人脸识别的相关任务带来的额外信息来提升对抗样本的迁移性。具体而言,Sibling-Attack首先选择了一组与人脸相关的任务作为候选,并根据理论和实验分析最终确定人脸属性识别任务作为Sibling-Attack中使用的辅助相关任务。
基于此,开发了一个全新的迁移性黑盒对抗攻击框架,该框架通过以下方式融合对抗性梯度信息:(1)将跨任务特征约束在同一空间下,(2)增强任务间梯度兼容性的联合任务元学习框架(Joint Task Meta Optimization),以及(3)减轻攻击期间振荡效应的跨任务稳定梯度(Cross Task Gradient Stabilization)训练方式。最终的实验表明,在不同类型的人脸识别模型下,Sibling-Attack取得更好的迁移性。
10
基于多示例学习的动态表情识别
Rethinking the Learning Paradigm for Dynamic Facial Expression Recognition
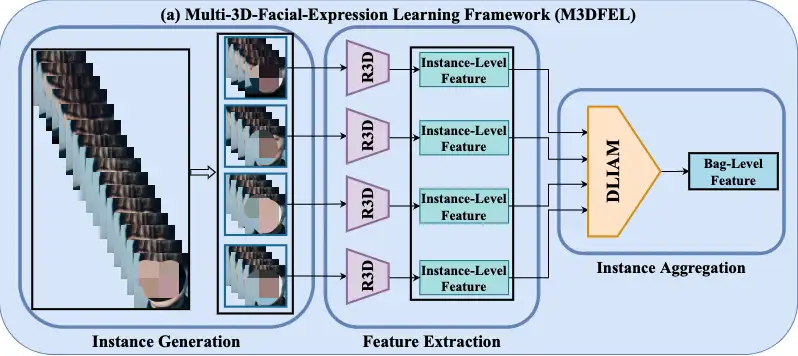
动态面部表情识别(DFER)是一个新兴领域,通过视频识别面部表情。以前的工作注意到视频中存在大量的非目标帧,并将它们建模为噪声帧。
在本文中,我们重新思考了DFER的学习范式,并提出它应该被定义为一个弱监督的问题。我们进一步发现,在DFER中,短期和长期的时间关系是不平衡的。为此,我们提出了一个简单而有效的专用框架,即多实例三维动态面部表情学习(M3DFEL),通过多实例学习(MIL)来学习不确切的标签。M3DFEL通过生成三维实例和使用3DCNN来提取它们的特征来建立强大的短期时间关系。此外,动态长时序聚合模块(DLIAM)被提出来,在动态聚合实例的同时学习长期时间关系。在DFEW和FERV39K上进行的大量实验表明,在朴素的R3D18主干上,所提出的M3DFEL优于目前DFER中最先进的方法。
11
基于样本感知域泛化的人脸活体检测
Instance-Aware Domain Generalization for Face Anti-Spoofing
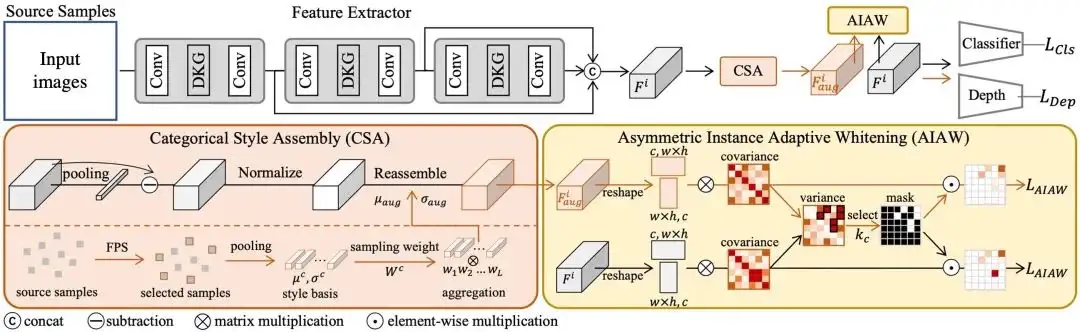
基于域泛化(DG)的人脸活体检测(FAS)技术在近年来被广泛研究,用以提高人脸活体检测模型在未知场景的泛化性。现有的方法通常依赖域标签来对齐每个域的分布以学习域不变特征表示。然而,这种人工定义的域标签是十分粗粒度且主观定义的,不能准确地反映真实的领域分布。此外,这种领域感知的域泛化方法主要关注域级的对齐,其对齐粒度不够细,无法确保学习到的表征对域风格不敏感。
为了解决这些问题,本文针对DG FAS任务提出了一个新的视角:通过在样本级别进行特征对齐并且不再依赖于任何域标签,从而实现域泛化活体检测。针对性地,本文提出了样本感知的域泛化人脸活体检测框架,通过弱化对样本风格的特征敏感性来学习可泛化特征。具体而言,本文提出了非对称实例自适应白化算法消除风格敏感的特征相关性以增强泛化性。此外,本文提出了动态卷积核生成器和类别风格重组模块,首先提取样本特定的特征,然后生成具有较大风格偏移的多样化风格特征,以进一步促进对风格不敏感特征的学习。大量的实验和分析证明了所提方法的有效性,并且在多个数据集取得最优效果。
12
鉴别器协作的特征图知识蒸馏方法
Discriminator-Cooperated Feature Map Distillation for GAN Compression
*本文由腾讯优图实验室和厦门大学共同完成
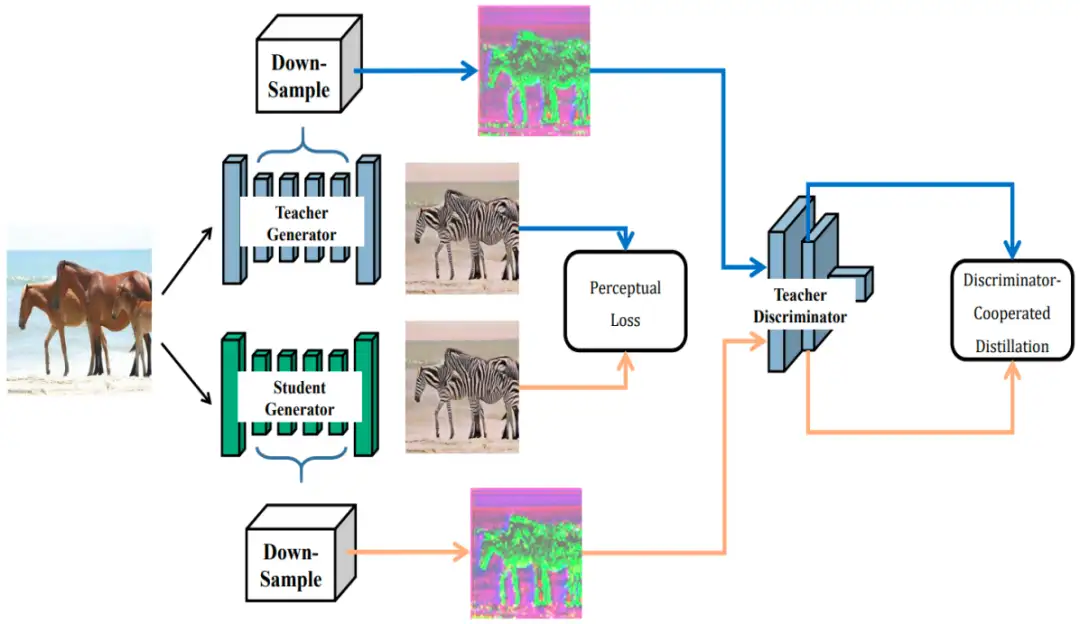
在图像生成的场景下,生成对抗网络(GANs)可以获得非常卓越的生成结果,但受困于其巨大的存储和密集的计算要求而难以广泛应用。
而知识蒸馏作为一个有效的性能弥补手段,被证明在探索轻量化模型性能提升方面特别有效。在本文中,我们研究了教师鉴别器的不可替代性,并提出了一种鉴别器协同蒸馏方法,简称DCD,以从生成器中提炼出更好的特征映射。与传统的特征图蒸馏中像素之间一一对应的匹配方法相比,我们的DCD利用教师鉴别器作为特征抽取器,驱动学生生成器的中间结果在感知上接近教师生成器的相应输出。此外,为了减轻GAN压缩中的模式崩溃,我们构建了一个协作对抗训练范式,其中教师鉴别器从零开始,与我们的DCD学生网络共同训练。与现有的GAN压缩方法相比,我们的DCD显示出了更好的结果。例如,在减少了CyclelGAN的40多倍MACs和80多倍参数后,我们可以很好地将FID度量从61.53降低到48.24,而目前的SOTA方法仅仅取得51.92。
论文下载地址:
https://arxiv.org/abs/2212.14169
13
视频多层级时序切分测试基准: NewsNet
NewsNet: A Novel Benchmark for Hierarchical Temporal Segmentation
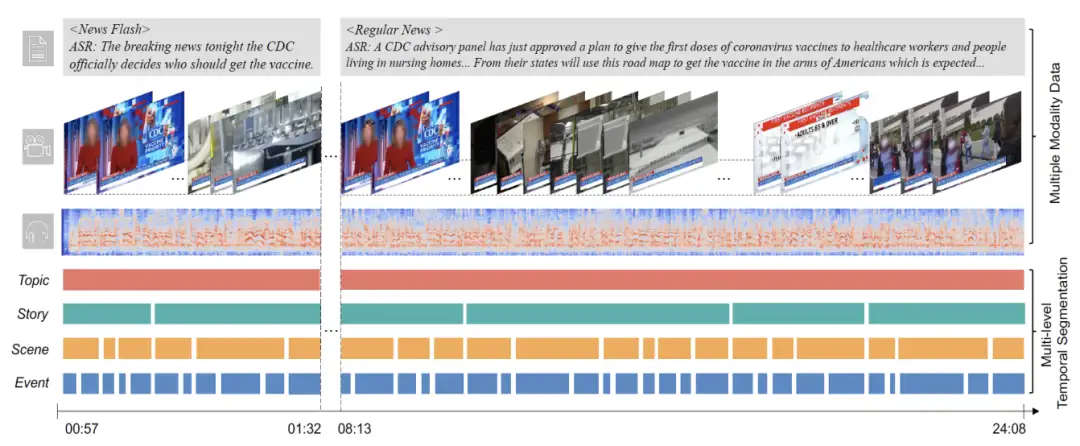
长视频理解算法的分析需要进行视频时序切分作为基础,其目的是将长视频分解为更短的片段以供后续的下游理解任务使用。最近的一些研究探究了不同粒度下对长视频进行切分,如镜头、事件和场景维度等。虽然这些切分任务有各自不同的语义,但是对于复杂且结构化的视频来说,它们缺乏更深层次的理解。因此,我们提出了更抽象的两个语义切分单元,并将其与现有的细粒度层级单元进行合并。随后,我们构建了一个名为NewsNet的视频时序切分测试基准,涵盖了多层级的时序视频分割任务,包含若干个不同的主题新闻,并带有对齐的音频、视觉和文本模态数据,以及四种层级的时序标注。对NewsNet的研究将促进对复杂结构化视频的理解,同时为短视频创作、个性化广告、数字教学和教育等领域带来更多的收益。
14
协同噪声标签清理器:
基于预告片场景感知的多模态电影高光检测方法
Collaborative Noisy Label Cleaner:
Learning Scene-aware Trailers for Multi-modal Highlight Detection in Movies
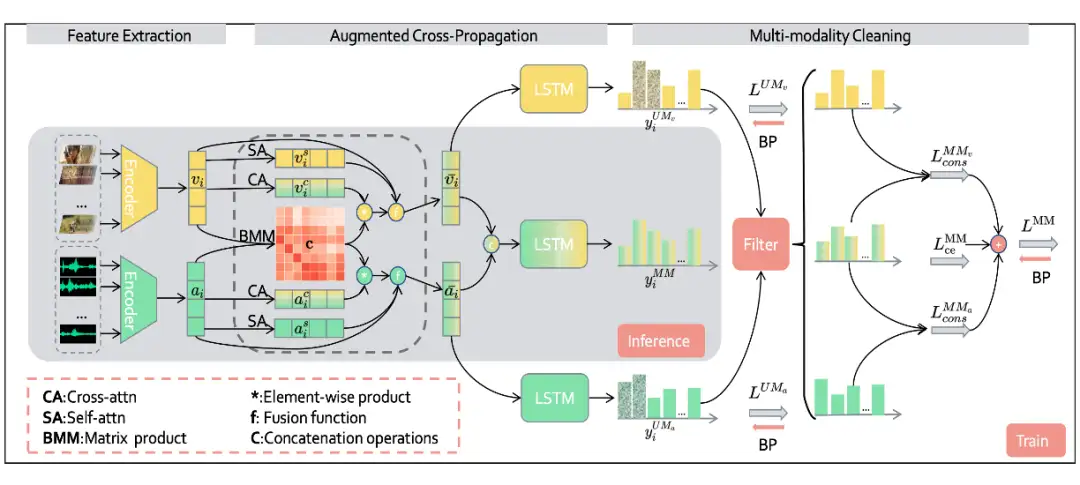
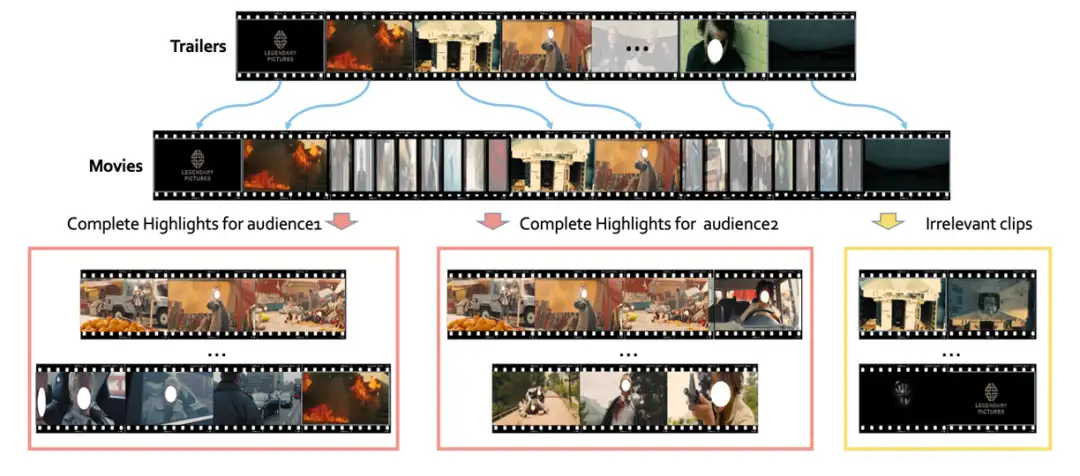
电影精彩片段能让观众高效浏览电影的剧情,并在社交媒体平台上对电影的传播发挥着至关重要的作用。我们认为当前的精彩片段检测方案存在以下两个问题:
(1)对于不同的标注者而言,标记精彩片段具有不确定性,这导致标注不准确且耗时。
(2)除了常见的有监督或无监督设定外,一些现有的视频资料库也很有价值,例如电影预告片,但它们通常带有噪音并且剧情不完整,无法覆盖全部精彩片段。
在本工作中,我们研究了一个更实用和更有前景的设定,即将精彩片段检测重新定义为带噪标签的学习。此设定不需要耗时的人工手动标注,并能充分利用现有丰富的视频语料库。首先,基于电影预告片,我们利用场景分割获得完整的精彩片段镜头,这些镜头被视为带噪声的标签。然后,我们提出了一种协同式噪声标签清理器 (CLC) 框架,以从带噪的精彩片段中学习。CLC 由两个模块组成:增强交叉传播 (ACP) 和多模态清洗 (MMC)。前者旨在利用密切相关的视听信号并将它们融合以学习统一的多模态表示。后者旨在通过观察不同模态之间损失的变化来筛选出干净的精彩片段标签。为了验证 CLC 的有效性,我们在公开数据集的综合实验证明了CLC的有效性。
15
基于CLIP模型的场景文本检测方法
Turning a CLIP Model into a Scene Text Detector
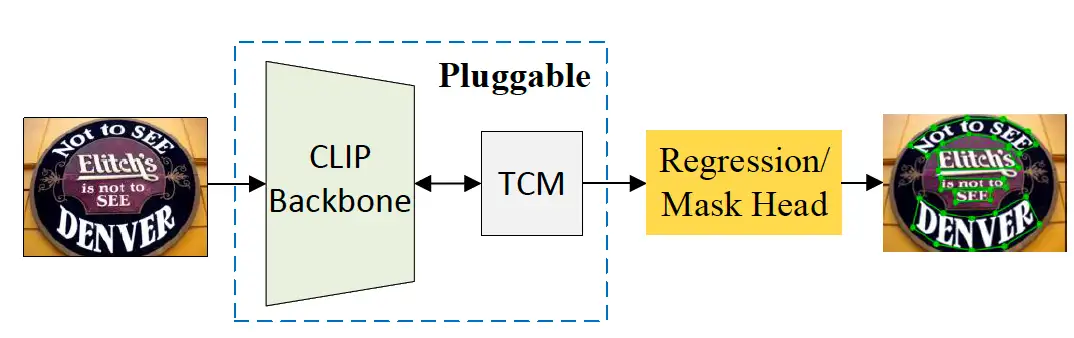
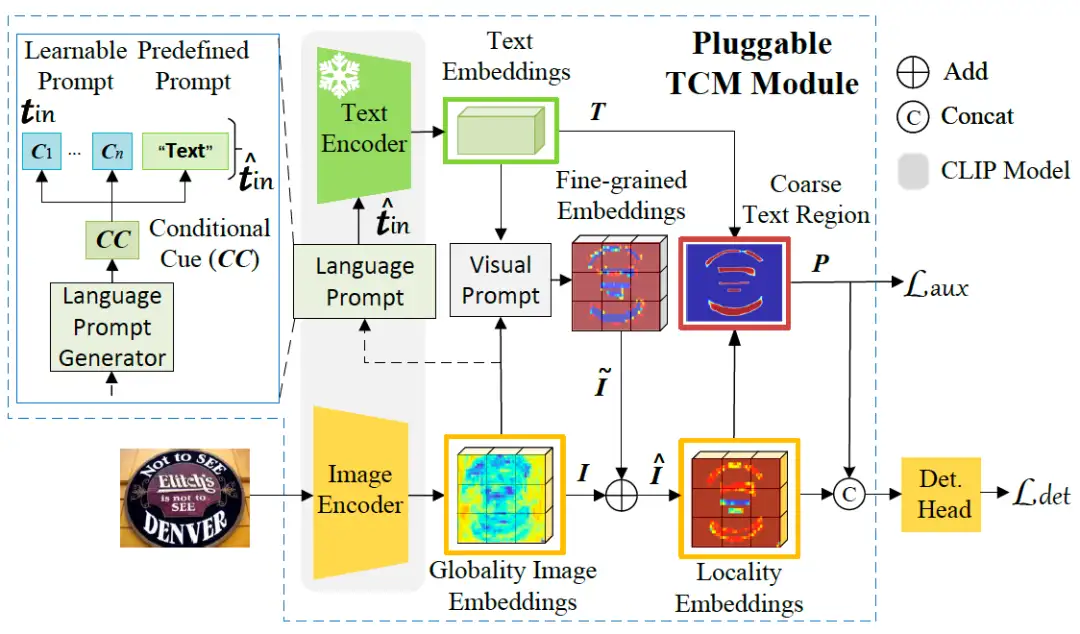
大规模对比语言-图像预训练(CLIP)模型通过利用预训练的视觉和语言知识,在各种下游任务中显示出巨大的潜力。场景文本包含丰富的文本和视觉信息,与类CLIP的模型有着内在的联系。近年来,基于视觉语言模型的预训练方法在文本检测领域取得了有效的进展。与这些工作相比,本文提出了一种新的方法,称为TCM,本方法无需预训练过程,直接利用CLIP模型进行文本检测。
我们所提出的TCM的优点如下:
(1)我们框架的基本原理可以应用于改进现有的场景文本检测器。
(2)促进了现有方法基于少样本训练的能力。比如,通过使用10%的标记数据,我们显著提高了基线方法的性能;在4个基准上的F-measure平均提高了22%。
(3)通过将CLIP模型转变为现有的场景文本检测方法,我们进一步实现了更好的域适应能力。
16
OSAN:统一多模态对齐和无监督领域自适应的
一阶段对齐网络
OSAN: A One-Stage Alignment Network to Unify Multimodal Alignment
and Unsupervised Domain Adaptation
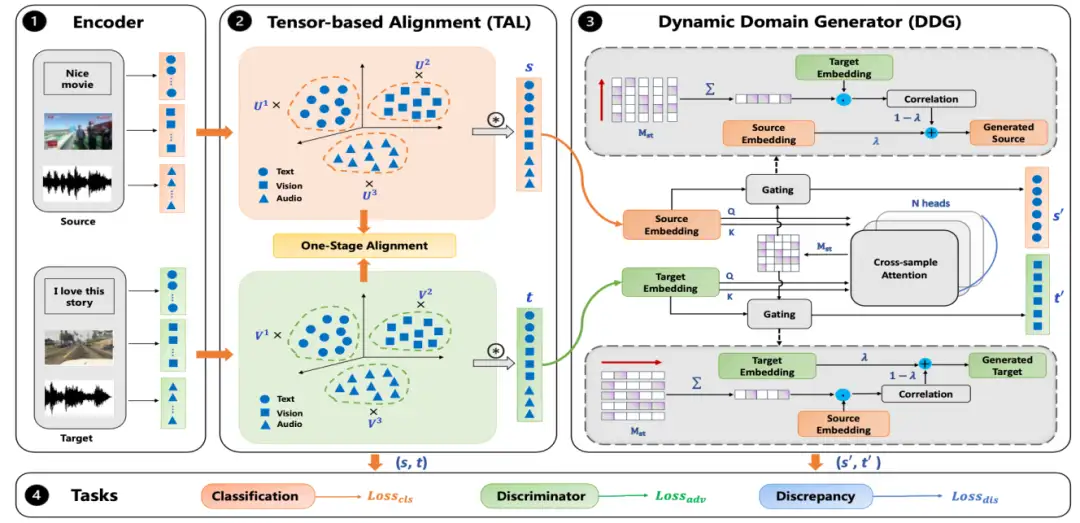
将无监督领域自适应由单模态迁移到多模态是一个非常具有挑战性的问题。其中包含两个主要问题:领域自适应以及模态对齐。传统的方法通过两个单独的阶段去处理这两个问题:首先进行模态对齐,其次进行领域自适应,或者反过来。然而,在传统的两阶段方法中领域和模态并没有联合到一起,二者之间的关系并没有充分挖掘。
本论文中,我们将两个问题统一成一个阶段,在我们的方法中,模态对齐和领域对齐能够同时完成。我们的方法提出一种基于张量的对齐模块(TAL),TAl能够挖掘领域和模态之间的关系,通过这种关系,领域和模态能够充分交互并且能够给对方提供补充信息。此外,为了能够对领域间建立一个桥梁,我们提出一个动态领域生成器(DDG)去生成混合样本,此类样本通过自监督的方式混合两个领域之间的公共信息,能够帮助我们的模型学习一个领域无差异的公共表征空间。大量的实验标明我们的方法能够取得SOTA的效果。
17
基于人脸原型场学习的可解耦的3D人脸建模
Learning Neural Proto-face Field for Disentangled 3D Face Modeling In the Wild
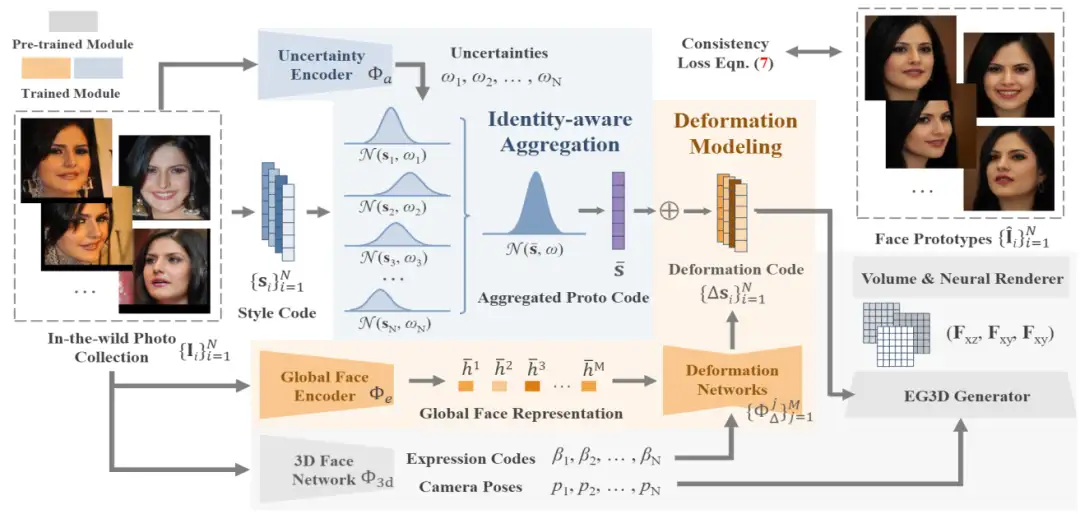
生成模型近来在3D人脸建模方便表现出了巨大潜力。尽管能够获得一定的重建细节和较高的分辨率,这些模型由于缺乏可靠的人脸先验,在面对极端姿态、阴影和表观纹理的情况下,无法获得准确的结果。为处理该问题,本文提出一种新的人脸原型场(Neural Proto-face Field, NPF)学习框架,能够从开放的人像集合中挖掘ID一致性信息。
具体来说,NPF首先利用不确定性建模的方式,自适应地聚合了人脸风格编码,学习人脸原型以表达ID一致的3D脸型。然后,利用表情一致性损失重建对应的个性化表情,完成表情和ID的解耦。最后,在得到的人脸原型的基础上,提出合理的正则化方法,优化生成模型使其适配于目标人脸,完成贴合原图的3D人脸重建。通过上述方法,我们使生成模型真正受益于多图的ID一致性先验信息。在公开数据集上的大量实验表明,NPF能够获得当前最优的几何、纹理重建结果。
18
基于表征空间学习的点云重建损失
Learning to Measure the Point Cloud Reconstruction Loss in a Representation Space
*本文由腾讯优图实验室和浙江大学共同完成
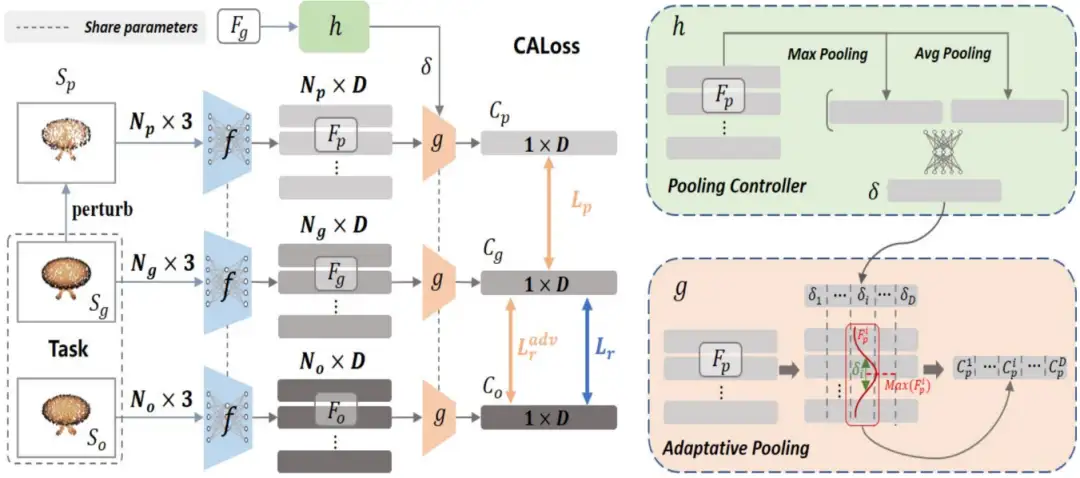
对于点云重建相关的任务来说,用于判断形状差异的重建损失是训练重建网络的关键。大多数方法采用点对点距离损失,但这些人工预定义的准则无法准确衡量真实的形状差异。尽管一些基于学习的方法被提出,用以弥补这些准则的缺点,这些方法依然在欧式空间中进行计算,具有一定的局限性。本文提出一种新的基于学习的对比对抗损失(Contrastive Adversarial Loss, CA-Loss),来动态地在非线性表征空间学习点云的误差准则。具体来说,我们使用对比约束在表征空间学习形状的相似性,利用对抗损失衡量重建结果与GT的差异。在公开数据集上的大量实验表明,CA-Loss 能够显著提升重建效果。
19
基于空间变化模糊估计的盲图像超分辨率
Better "CMOS" Produces Clearer Images: Learning Space-Variant Blur Estimation for Blind Image Super-Resolution
*本文由腾讯优图实验室和浙江大学共同完成
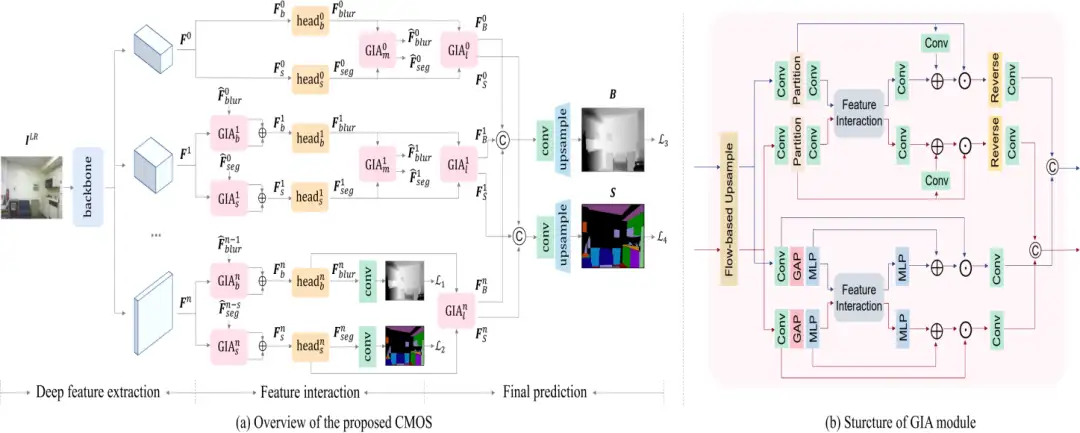
现有的大多数盲图像超分辨率(SR)方法都假设下采样过程中的模糊核是空间不变的。然而,在实际应用中,由于物体运动、失焦等因素,所涉及的模糊核通常会发生空间变化,导致先进的SR方法性能下降严重。为了解决这一问题,我们首先引入了两个新的失焦模糊数据集,即NYUv2-BSR和Cityscapes-BSR,为针对空间可变模糊的盲SR方法的进一步研究提供支持。基于上述数据集,我们设计了一种新的跨模态融合网络(CMOS)来估计空间可变的模糊。
具体而言,CMOS包含两个核心部分:首先,它同时预测语义和模糊,这对于模糊估计和SR过程都有利。其次,它涉及一个特征分组交互注意(GIA)模块,能够使两个模态更有效地交互,避免不一致性。由于其结构的多功能性,GIA还可以用于其他特征的交互。与现有方法相比,在上述数据集和真实图像上的定性和定量实验证明了该方法的优越性,例如,在NYUv2-BSR上获得的PSNR/SSIM比MANet高出+1.91/+0.0048。
20
基于多模态统一情绪空间学习的
高保真度通用情绪化说话人脸生成
High-fidelity Generalized Emotional Talking Face Generation with Multi-modal Emotion Space Learning
*本文由腾讯优图实验室和浙江大学共同完成
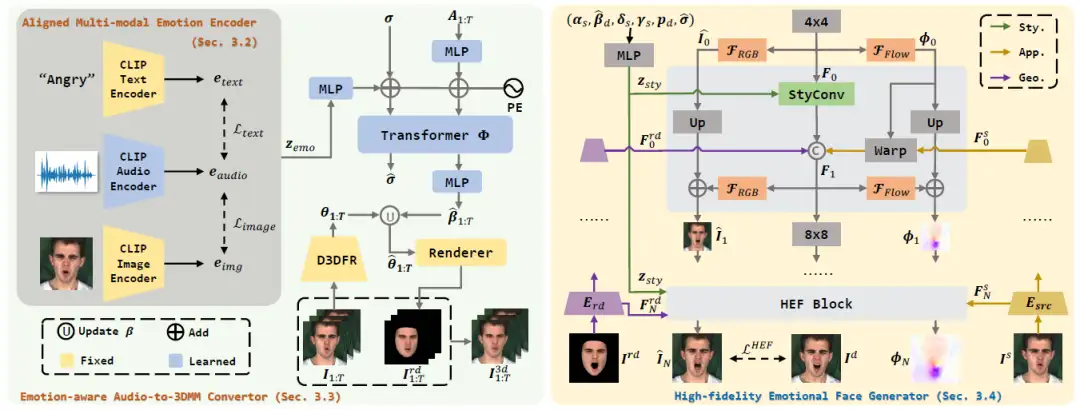
最近,情绪化说话人脸生成受到了很多关注。然而,现有方法通采用one-hot编码、或者从图像和音频中提取情绪条件,在实际应用中缺乏灵活的控制,并且由于有限的语义信息而无法处理未知的情绪风格。并且它们忽略了one-shot设置以及生成人脸的质量。因此在本文中,我们提出了一个更灵活和通用的框架。
具体来说,我们补充文本提示来表征情绪风格,并使用对齐的多模态情感编码器将文本、图像和音频情绪模态整合到一个统一的空间中,从而继承了来自CLIP的丰富语义先验。因此,多模态情绪空间学习有助于提升泛化性,即在推理时能够支持任意情绪模态以及表达未知的情绪风格。此外,一个情绪感知的音频到3DMM表情系数转换器将情绪条件和序列化音频特征映射为结构信息。后续的高保真情绪人脸生成器接收该隐式和显式的情绪相关的结构信息生成高分辨率真实人脸。该纹理生成器专注于分层地用残差方式学习空间位移场和面部扭曲,从而允许泛化到任意人脸。广泛的实验证明本文情绪控制方法的灵活性和泛化性以及高质量人脸合成的有效性。
21
基于图transformer生成网络的住宅户型生成
Graph Transformer GANs for Graph-Constrained House Generation
*本文由腾讯优图实验室和苏黎世联邦理工大学、
特伦托大学共同完成
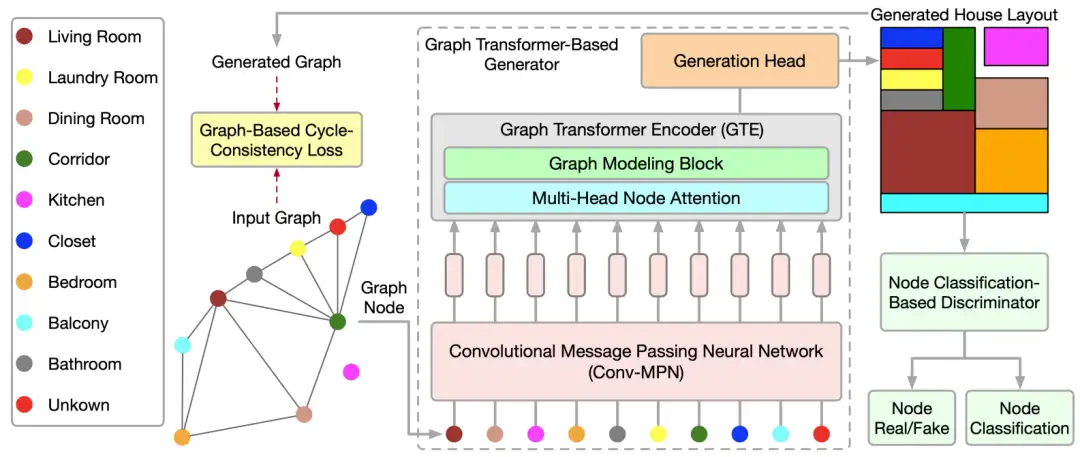
本文提出了一个新的图transformer生成网络(GTGAN)用以有效地学习图节点的关联性,生成图约束的住宅户型布局。所提出的生成模型包括一个新的图transformer编码网络,用以建模连接节点和非连接节点间的局部/全局的交互过程。具体来说,提出了连接节点注意力模型和非连接节点注意力模型来捕获上述信息。同时,提出了图建模模块,能够根据户型布局的拓扑结构进行局部节点的交互学习。进一步地,提出了一种新的基于分类的节点判别器,用来保留不同布局元素中的高阶语义信息。最后,提出了一个新的基于图的循环一致损失,用来约束图中相对的空间分布关系。在公开数据集上的大量实验表明,GTGAN能够获得当前最优的效果。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
CVPR2023最新Backbone | FasterNet远超ShuffleNet、MobileNet、MobileViT等模型
CVPR2023 | 集成预训练金字塔结构的Transformer模型
AAAI 2023 | 一种通用的粗-细视觉Transformer加速方案
大核分解与注意力机制的巧妙结合,图像超分多尺度注意网络MAN已开源!
【免费送书活动】 全新轻量化模型 | 轻量化沙漏网络助力视觉感知涨点
目标检测、实例分割、旋转框样样精通!详解高性能检测算法 RTMDet
大卷积模型 + 大数据集 + 有监督训练!探寻ViT的前身:Big Transfer (BiT)
超快语义分割 | PP-LiteSeg集速度快、精度高、易部署等优点于一身,必会模型!!!
AAAI | Panini-Net | 基于GAN先验的退化感知特征插值人脸修
与SENet互补提升,华为诺亚提出自注意力新机制:Weight Excitation
最新FPN | CFPNet即插即用,助力检测涨点,YOLOX/YOLOv5均有效

 浙公网安备 33010602011771号
浙公网安备 33010602011771号