全网唯一复现!手机端 1ms 级延迟的主干网模型 MobileOne
前言 本文给大家介绍基于 CNN 架构中重参数化技术的轻量化主干网络 MobileOne。虽然 Apple 公司在其项目 ml-mobileone 中已经开源了 MobileOne 的代码以及权重,但并没有公开训练和推理的策略。MMClassification 通过一系列努力,已经完全复现了 MobileOne 的训练精度(全网唯一),可以查看相关 issue、复现结果。
本文转载自OpenMMLab
作者 | 带来新知识的
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
issue:
https://github.com/apple/ml-mobileone/issues/7
复现结果:
https://github.com/open-mmlab/mmclassification/tree/1.x/configs/mobileone
2021 年,旷视的 RepVGG 提出重参数化技术,模型在训练和推理时具有不同的结构,推理时结构更简洁,速度更快且易于后期的部署和算子优化。目前重参数化技术已经被广泛使用,如检测任务的 YOLOv6 以及 YOLOv7,且取得了非常好的效果。
MobileOne 模型本身没有特别新颖的创新点,可以看作一个 MobileNet、 重参数技术、训练技巧的组合创新成果。其在苹果 iPhone12 上,以推理时延小于 1ms 的速度在 ImageNet1k 数据集上达到了 75.9 的 TOP1 精度,到达目前轻量级模型最优的效果。
出发点
一直以来移动设备的高效神经网络主干通常是针对计算量或参数量等指标进行优化,然而,这些指标与真实部署在移动设备上的推理延迟存在一个差距。有些模型虽然有较低的计算量和参数量,但它的推理速度仍然非常慢。
为了探索推理时延最优的模型,苹果公司通过在移动设备上部署常见的轻量级模型,分析推理时延瓶颈所在,并提供了对应缓解的方法。MobileOne 与 EfficientFormer 使用的研究方法相似,都是通过实验分析的方法。
实验分析
作者将常见的移动端轻量级模型在 iPhone12 上使用 coreML 部署,直接测试其推理时延,图 1 是所有的统计结果,可以看出 CNN 架构的模型具有明显的优势。为了定量分析计算量和参数量与推理时间的关系,作者计算了 Spearman 关联系数。图 2 展示了计算量和参数量与推理时延的 Spearman 系数,Spearman 系数值越大,代表它们的关联度越大,可以看出参数量和推理时延的关联程度较弱,计算量与推理时延的关联程度也一般。
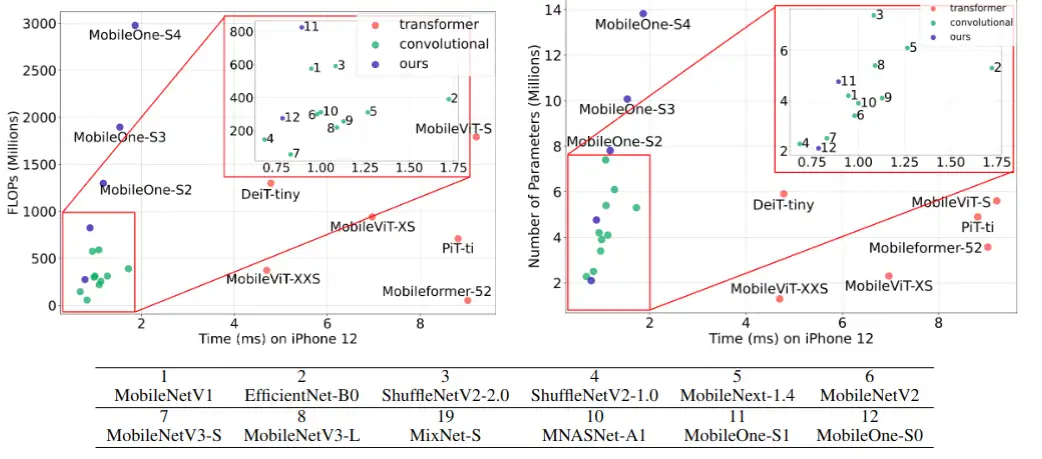
图 1 常用轻量级模型在 iPhone12 上的表现
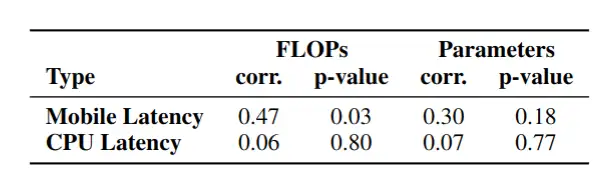
图 2 推理时延与计算量、参数量的 Spearman 关联系数
作者又分析了基本模块对推理时间的影响,主要是激活函数,残差结果以及 SE 模块的影响。图 3 展示了激活函数对推理时延的影响,使用复杂的激活函数虽然可以带来精度上的非常小的提升,但它会带来推理时延巨大增加。图 4 是 SE 模块与残差模块对推理时延的影响,它们都增加了大量的推理时延,文章中也给出了解释,这类多分支结构,会带来额外的访存开销。
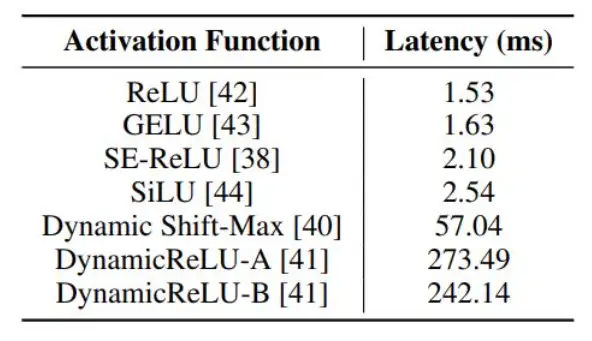
图 3 激活函数的影响
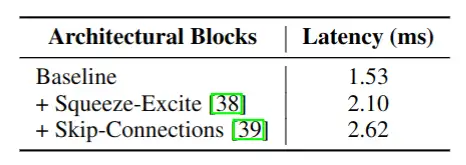
图 4 SE 模块与残差结构影响
实验结论
- CNN 结构在推理速度上有很大优势
- ReLU 的速度最快,其他激活函数速度慢,精度提升并不明显
- SE 模块与残差结构都显著的影响推理速度,应该尽量避免
MobileOne 结构
将上述实验结论作为设计指导,MobileOne 主要是基于 MobileNet 以及 RepVGG 这样的卷积神经网络,一方面为了减少残差结构的额外开销,使用 RepVGG 中的重参数技术,另一个方面只在最大的模型结构 MobileOne-s4 中才使用少量的 SE 模块。
MobileOne Block 基于深度可分离卷积,由多分支的 DepthWise 卷积模块和 PointWise 卷积模块组成,它有两种状态,训练时状态和推理时状态,图 5 左侧为训练时的状态,右侧为推理时状态。
在训练状态下,DepthWise 卷积模块有三个分支,分别为 1×1 DepthWise 卷积分支,3×3 DepthWise 卷积分支和一个 BN 层分支。PointWise 卷积模块有两个分支,分别为 1×1 卷积分支和一个 BN层 分支。
在推理状态下, DepthWise 卷积模块 和 PointWise 卷积模块只有一个 3×3 DepthWise 卷积和 1×1 PointWise 卷积,没有其他额外的分支,其中卷积和 BN 还可以进一步融合。
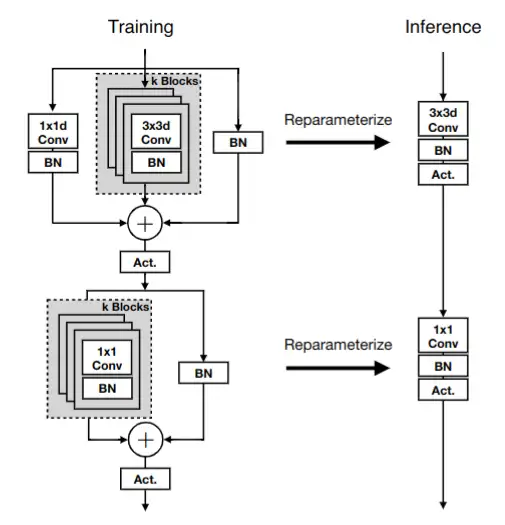
图 5 MobileOne Block 结构
主要考虑到:
- 输入分辨率的放大, 会增大计算量以及内存的消耗,这些都是对移动设备不友好的,所以所有的结构都使用 224*224 的输入分辨率。
- 模型在推理时没有多分支的结构,不会产生额外的访存,所以设计时使用了更大的通道数。
作者提出了 5 种不同大小的模型结构,如图 6 所示,整体延续了 RepVGG 的架构,一共 8 个 stage,其中 6 个 stage 的 Block Type 为 MobileOne Block,1 个 stage 的 Block Type 为 AvgPool,1 个 stage 的 Block Type 为 Linear,只在最大的 MobileOne-S4 的最后的两个 stage 上才添加 SE 模块,所有的激活函数都使用 ReLU。
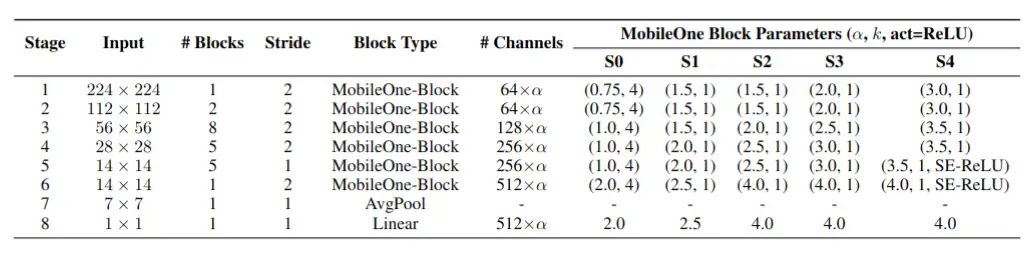
图 6 MobileOne 模型整体结构
训练技术优化

图 7 MobileOne 训练技巧消融实验
MobileOne 的训练策略整体上延续了 RepVGG,并在其基础上额外使用了 3 个特有的训练优化技巧,分别是:
- 渐进式学习策略
- 退火权重衰减系数
- 指数平均移动 EMA
渐进式学习策略是由 EfficientNetV2 提出的一种训练策略,简单来说就训练过程渐进地增大图像大小,但在增大图像同时也采用更强的正则化策略,训练的正则化策略包括数据增强和 dropout 等,MobileOne 中更强的正则化指的是采用更大的 AutoAug 的增强强度系数, 在训练的流程中,分别在 37 轮和 112 轮,增加了输入图片的分辨率以及 AutoAug 的强度系数。渐进式学习策略不仅可以加快训练速度,还可以提高模型精度。

图 8 MobileOne 训练过程数据增强
与大型模型相比,小型模型需要较少的正则化来防止过度拟合。在训练的早期阶段权重正则化(Weight-Decay)很重要,作者实验发现,相比于消除训练过程中权重正则化,对权重正则化引起的损失进行退火处理更有效。
MobileOne 使用学习率中最常见的 Cosine schedule 来退火权重衰减系数,图 9 是 MobileOne 的权重衰减曲线,从图 9 中可以看到退火权重衰减系数提高了 0.5 %。
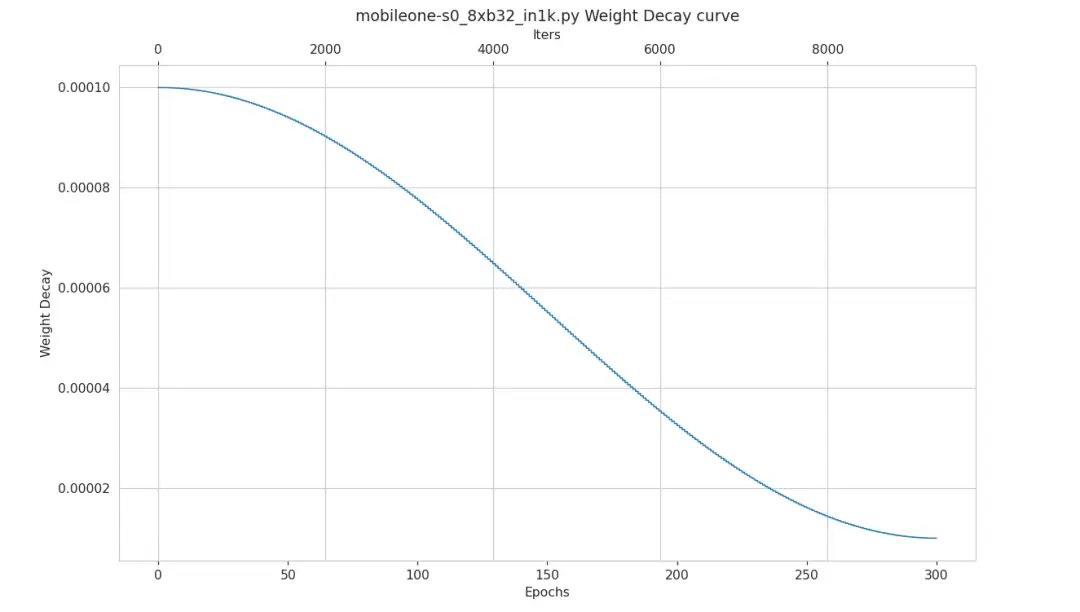
图 9 MobileOne 权重衰减曲线
EMA 是指数平均移动(Exponential moving average),目前它是深度学习领域非常常见的训练技巧,近年大量新工作使用了该训练技巧。EMA 可以看作一种模型的集成,不过这里集成的是训练迭代过程中权重。其公式非常简单,如下所示:
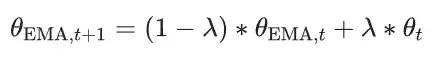
目前这几种训练优化都已经在 MMClassification 中实现,欢迎使用,配置如下:

实验结果
以下展示了桌面端以及移动端上 MobileOne 和其他轻量级模型的一些性能对比,可以看出其具有明显的性能优势。
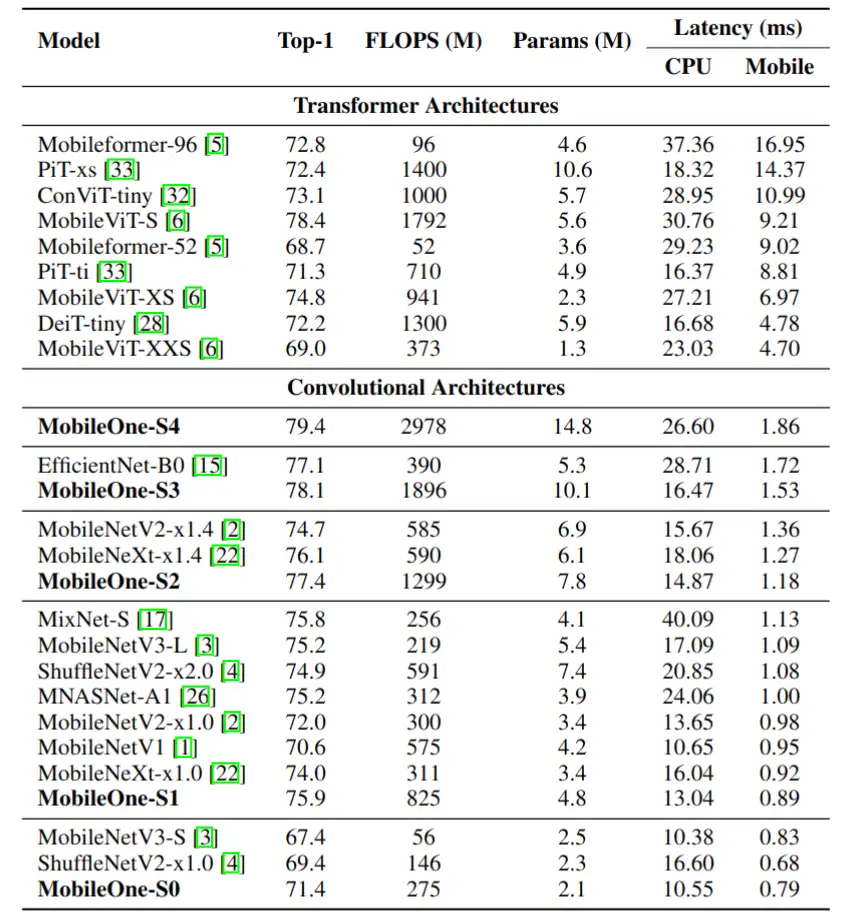
图 10 MobileOne 分类性能比较
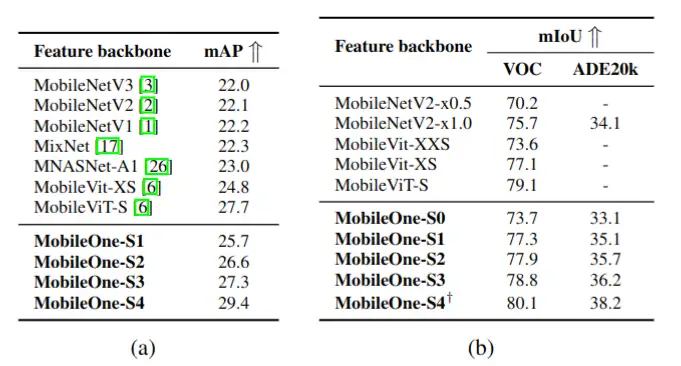
图 11 MobileOne 检测、分割任务性能比较
在分类任务上,它在速度精度综合评比中不仅超过了 CNN 架构的 MobileNet 、ShuffleNet 系列,还远超前文提到的 MobileViT 系列算法。其中 MobileOne-s1 结构更是在推理时延为 1ms 的前提下,ImageNet 数据集上精度达到 75.6。
MobileOne 不仅在分类任务上取得了速度与精度的最佳权衡,它在检测(图 11.a)和分割(图 11.b)任务中,也取得了非常不错的成果。
总结
本文介绍了最新的基于 CNN 架构的算法 MobileOne,重点主要有以下两点:
- 将重参数化技术应用到深度可分离卷积中;
- 使用了 3 个特有的训练优化技巧,分别是:渐进式学习策略;退火权重衰减系数;指数平均移动 EMA。
MobileOne 是目前精度速度综合表现最好的算法,特别适合应用到实际的业务场景中来。并且已经集成在 MMClassification 中,且已经对齐了训练精度,欢迎对相关模型感兴趣的同学尝试试用。
MobileOne:https://github.com/open-mmlab/mmclassification/tree/dev-1.x/configs/mobileone
参考文献
- An Improved One millisecond Mobile Backbone
- RepVGG: Making VGG-style ConvNets Great Again
- EfficientNetV2: Smaller Models and Faster Training
- EfficientFormer: Vision Transformers at MobileNet Speed
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
CVPR2023最新Backbone | FasterNet远超ShuffleNet、MobileNet、MobileViT等模型
CVPR2023 | 集成预训练金字塔结构的Transformer模型
AAAI 2023 | 一种通用的粗-细视觉Transformer加速方案
大核分解与注意力机制的巧妙结合,图像超分多尺度注意网络MAN已开源!
【免费送书活动】 全新轻量化模型 | 轻量化沙漏网络助力视觉感知涨点
目标检测、实例分割、旋转框样样精通!详解高性能检测算法 RTMDet
大卷积模型 + 大数据集 + 有监督训练!探寻ViT的前身:Big Transfer (BiT)
超快语义分割 | PP-LiteSeg集速度快、精度高、易部署等优点于一身,必会模型!!!
AAAI | Panini-Net | 基于GAN先验的退化感知特征插值人脸修
与SENet互补提升,华为诺亚提出自注意力新机制:Weight Excitation
最新FPN | CFPNet即插即用,助力检测涨点,YOLOX/YOLOv5均有效
消费级显卡的春天,GTX 3090 YOLOv5s单卡完整训练COCO数据集缩短11.35个小时

 浙公网安备 33010602011771号
浙公网安备 33010602011771号