大核分解与注意力机制的巧妙结合,图像超分多尺度注意网络MAN已开源!
前言 本文介绍了一种基于 CNN 的多尺度注意力网络 (MAN),它由多尺度大核注意力 (MLKA) 和门控空间注意力单元 (GSAU) 组成。
本文转载自极市平台
作者 | CV开发者都爱看的
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。

论文链接:https://arxiv.org/abs/2209.14145
代码地址:https://github.com/icandle/MAN
写在前面
本文基于大核分解和注意机制,提出应用于图像超分的多尺度注意网络MAN。通过可解释的门控空间注意单元来汇总上下文信息,利用多尺度大核注意模块获得丰富注意特征图,并聚合局部-全局信息。本文方法与现有流行方法进行了详细的实验对比,获得了竞争性的对比结果。
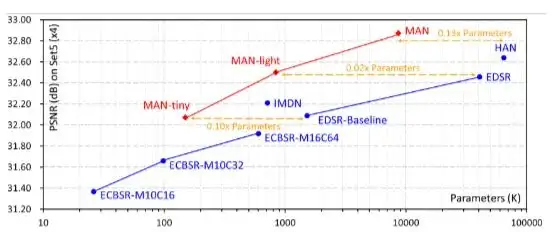
问题引入和Motivation简述
图像超分旨在从低分辨率输入重建高分辨输出。然而基于CNN的方法要么通过更大数据集来提高性能,要么引入了更复杂的网络设计,这些无疑都增加了计算成本消耗。
还记得今年2月份出炉的那篇VAN吗,VAN通过详细实验证明了大核的卷积可以被有效分解为三种卷积的组合,分别为:深度卷积、含膨胀的深度卷积、逐点卷积。这里给出VAN的分解示意图:
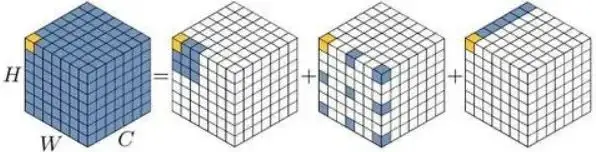
VAN的作者在文末提到,未来对VAN的改进可能包含多分支或多尺度设计的应用。在本文中,作者等人在图像超分任务中对VAN进行可行性考察,发现了一个很重要的问题:VAN的分解过程中,含膨胀的深度卷积会为超分任务带来“块状伪影(blocking artifacts)”。在损害性能的同时,固定的核大小无法充分局部-全局特征。
综上,作者将多尺度机制与大核注意机制结合来解决上述问题,并采用门控机制校准注意图,避免含膨胀的深度卷积带来的块状伪影。
可行性解释与方法剖析

如图3,作者将所提出的方法称为MAN,共有三种不同颜色的组件:浅层特征提取模块SF(最左侧白色)、深层特征提取模块DF(中间灰色的MAB)、图像重建模块(最右侧)。不难看出MAN的整体框架较简单,核大小为3×3的卷积被用在SF和DF模块,其中级联的MAB用于生成待融合的高频特征,并通过与浅层特征残差连接,生成最终的待恢复特征。整体优化使用了如下常用损失:
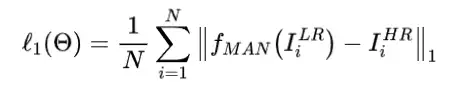
作为本文的核心模块,MAB借鉴了MetaFormer的设计风格,由多尺度大核注意(MLKA)模块和门空间注意单元(GSAU)两个组件构成。输入特征顺次经过层归一化、MLKA、GSAU,并添加残差连接保证跨层信息传播。
MLKA详细剖析
如下图所示,MLKA将多尺度思想应用于注意机制,在一定程度上抑制噪声的同时,使注意图拥有了局部-全局信息的依赖。
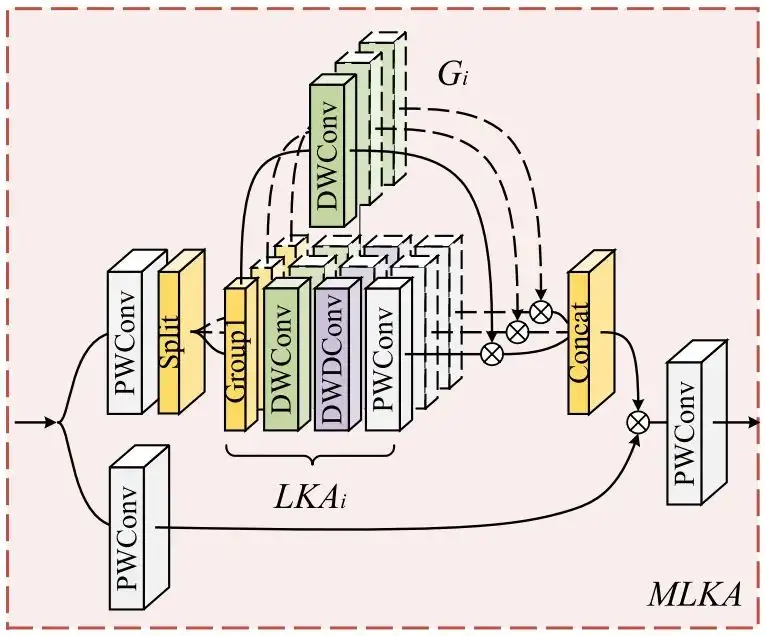
灰色的PWConv模块代表逐点卷积,用于调整维度,以便后续的逐元素乘法、残差连接等操作。
LKA是MLKA的基础特征提取组件,即图4中绿色、紫色、灰色级联的模块。设定大核尺寸为,由VAN论文提出的理论,大核被分解为:的深度卷积、的含膨胀深度卷积(膨胀率为)、逐点卷积。
为使LKA拥有更丰富的多尺度信息,引入逐组的多尺度机制。如图4的第一个分支,输入特征在经过逐点卷积调整维度后,被均匀的沿通道方向切分为n个组,每个组都应用了不同尺寸的大核分解。在本文中,作者将n设置为3,即使用了三种不同尺寸(7×7、21×21、35×35)的大核进行分解,设置膨胀率分别为{2,3,4}。
尽管此时特征已经获得了局部-全局的解释,但使用深度膨胀卷积带来的“块状伪影”问题不得不重视。因此在分组后,引入门控聚合来动态调整LKA的输出。即图4中最上面的DWConv,在对应组中,与下方深度卷积使用的核尺寸一致,并将该卷积的输出与对应组中LKA的输出做逐元素乘法。作者将这一操作称为门控聚合,在图5的可视化结果中可以明显看到,添加门控聚合后,块状伪影被移除(最下面一行的三幅图像更明显一点),MLKA的结果更为合理。
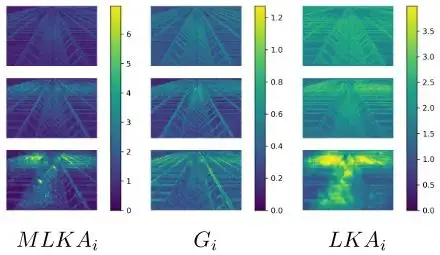
LKA具有较大的感受野,因为它是对大核的合理分解。门控聚合使用的深度卷积相对来说用于局部的感受野。因此,LKA更倾向于远距离依赖,而门控聚合使用的深度卷积保留了局部细节,二者相乘的结果抑制了块状伪影的生成。
GSAU详细剖析
为进一步增强特征表示,受PVT等方法的启发,作者将简单空间注意(SSA)和门控线性单元(GLU)集成,实现了自适应的门控机制,如下图所示。
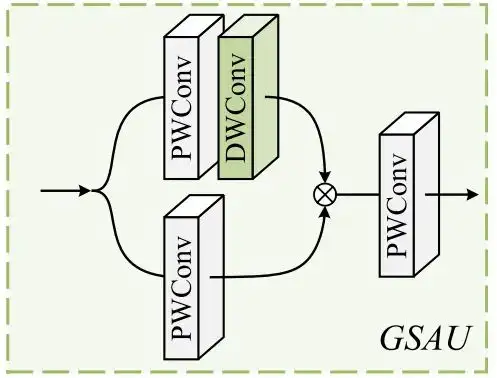
输入特征通过逐点卷积进行密集线性变换,在第一个分支中,额外添加了深度卷积来对变换结果加权,两分支的逐元素乘积进一步提升了特征表示,同时在可承受的复杂度内捕获了更丰富的局部依赖。
Large Kernel Attention Tail (LKAT)详细剖析
LKAT在图3右侧,残差连接前被应用。作者沿用以往图像超分中模型的设计范式,将一个简单的LKA应用于网络尾部,用以从提取的特征中进一步总结出更合理的信息,从而提高重建表现。其图示如下:
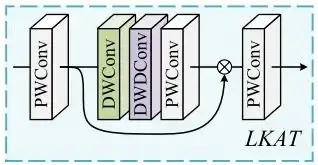
这里分解的大核尺寸为35×35,膨胀率为4。在LKA两端用逐点卷积调整维度。
实验对比
供于训练的数据集分别为DIV2K和Flicker2K。供于测试的数据集分别为:Set5、Set14、BSD100、Urban100、Manga109。
性能评估指标分别为:峰值信噪比(PSNR),结构相似性指数(SSIM)。
下表为消融研究的结果:
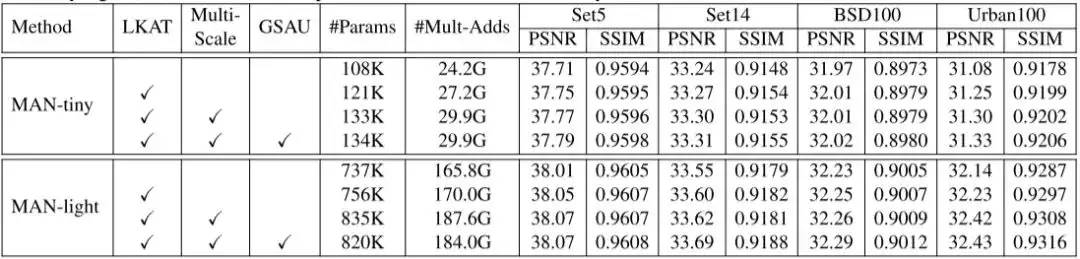
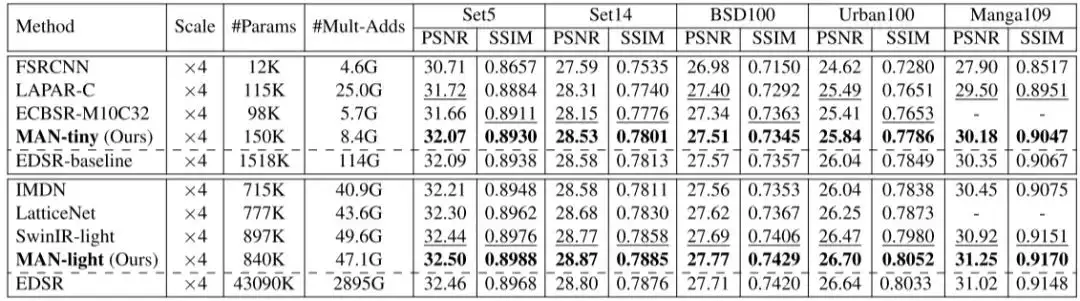
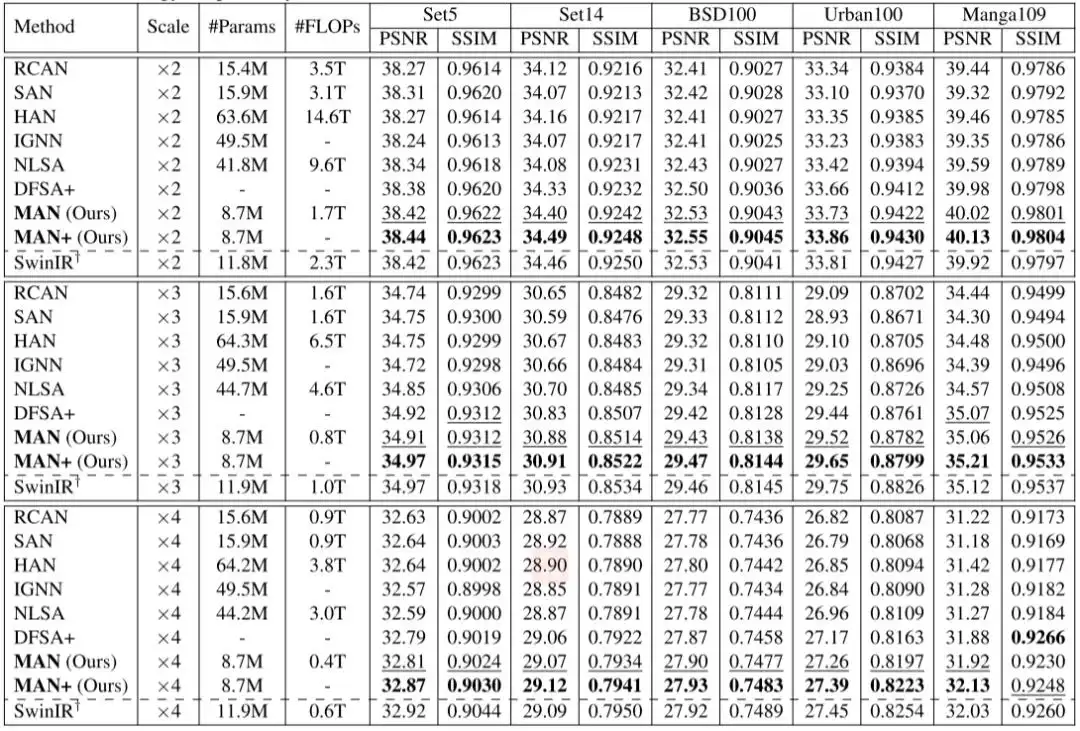
从表中可以看出,以LKA为基础,添加多尺度机制和GSAU都带来了性能提升,多尺度机制引入最多的参数量。
测试结果如下表所示:
可视化结果对比如下:

思考与总结
本文以VAN的研究为理论基础,通过门控机制解决了LKA在超分任务中的“块状伪影”问题,借鉴MetaFormer的设计风格,在多个数据集上取得了更SOTA的性能。
分组处理的思想无疑加快了计算效率,同时又与多尺度机制完美的契合,实现不同尺度信息的有效聚合,是一个非常巧妙的设计。尽管文中使用了多次逐点卷积来调整维度,但整体复杂度仍处于可接受范围内。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
CVPR2023 | 集成预训练金字塔结构的Transformer模型
AAAI 2023 | 一种通用的粗-细视觉Transformer加速方案
【免费送书活动】 全新轻量化模型 | 轻量化沙漏网络助力视觉感知涨点
目标检测、实例分割、旋转框样样精通!详解高性能检测算法 RTMDet
大卷积模型 + 大数据集 + 有监督训练!探寻ViT的前身:Big Transfer (BiT)
超快语义分割 | PP-LiteSeg集速度快、精度高、易部署等优点于一身,必会模型!!!
AAAI | Panini-Net | 基于GAN先验的退化感知特征插值人脸修
与SENet互补提升,华为诺亚提出自注意力新机制:Weight Excitation
最新FPN | CFPNet即插即用,助力检测涨点,YOLOX/YOLOv5均有效

 浙公网安备 33010602011771号
浙公网安备 33010602011771号