CVPR2023最新Backbone |FasterNet远超ShuffleNet、MobileNet、MobileViT等模型
前言 为了设计快速神经网络,许多工作都集中在减少浮点运算(FLOPs)的数量上。然而,作者观察到FLOPs的这种减少不一定会带来延迟的类似程度的减少。这主要源于每秒低浮点运算(FLOPS)效率低下。并且,如此低的FLOPS主要是由于运算符的频繁内存访问,尤其是深度卷积。因此,本文提出了一种新的partial convolution(PConv),通过同时减少冗余计算和内存访问可以更有效地提取空间特征。
基于PConv进一步提出FasterNet,在广泛的设备上实现了比其他网络高得多的运行速度,而不影响各种视觉任务的准确性。同时,实现了令人印象深刻的83.5%的TOP-1精度,与Swin-B不相上下,同时GPU上的推理吞吐量提高了49%,CPU上的计算时间也节省了42%。
本文转载自集智书童
作者 | 小书童
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
1、简介
神经网络在图像分类、检测和分割等各种计算机视觉任务中经历了快速发展。尽管其令人印象深刻的性能为许多应用程序提供了动力,但一个巨大的趋势是追求具有低延迟和高吞吐量的快速神经网络,以获得良好的用户体验、即时响应和安全原因等。
如何快速?研究人员和从业者不需要更昂贵的计算设备,而是倾向于设计具有成本效益的快速神经网络,降低计算复杂度,主要以浮点运算(FLOPs)的数量来衡量。
MobileNet、ShuffleNet和GhostNet等利用深度卷积(DWConv)和/或组卷积(GConv)来提取空间特征。然而,在减少FLOPs的过程中,算子经常会受到内存访问增加的副作用的影响。MicroNet进一步分解和稀疏网络,将其FLOPs推至极低水平。尽管这种方法在FLOPs方面有所改进,但其碎片计算效率很低。此外,上述网络通常伴随着额外的数据操作,如级联、Shuffle和池化,这些操作的运行时间对于小型模型来说往往很重要。
除了上述纯卷积神经网络(CNNs)之外,人们对使视觉Transformer(ViTs)和多层感知器(MLP)架构更小更快也越来越感兴趣。例如,MobileViT和MobileFormer通过将DWConv与改进的注意力机制相结合,降低了计算复杂性。然而,它们仍然受到DWConv的上述问题的困扰,并且还需要修改的注意力机制的专用硬件支持。使用先进但耗时的标准化和激活层也可能限制其在设备上的速度。
所有这些问题一起导致了以下问题:这些“快速”的神经网络真的很快吗?为了回答这个问题,作者检查了延迟和FLOPs之间的关系,这由
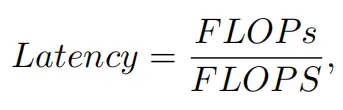
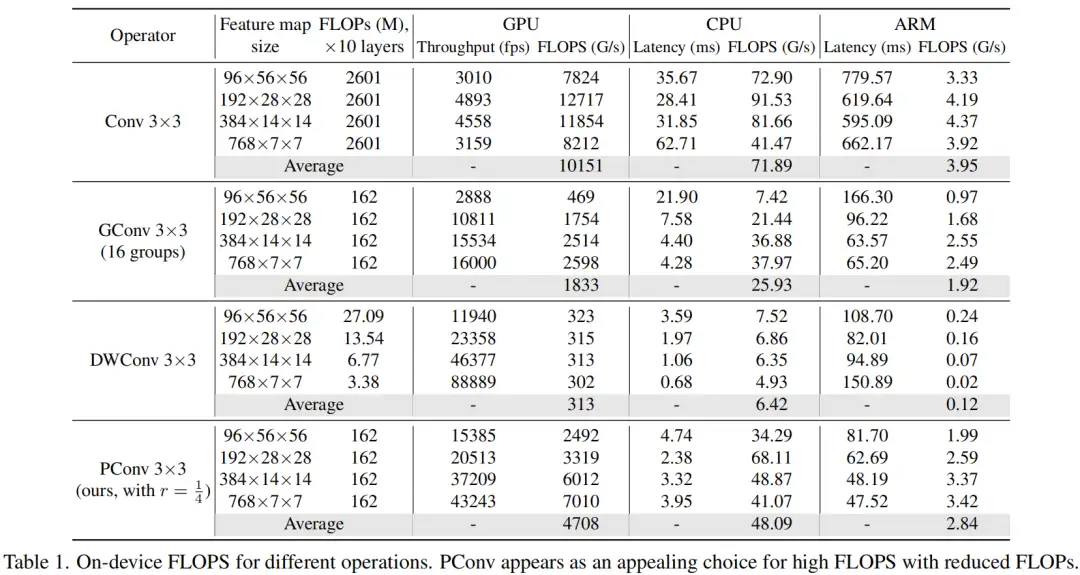
其中FLOPS是每秒浮点运算的缩写,作为有效计算速度的度量。虽然有许多减少FLOPs的尝试,但都很少考虑同时优化FLOPs以实现真正的低延迟。为了更好地理解这种情况,作者比较了Intel CPU上典型神经网络的FLOPS。
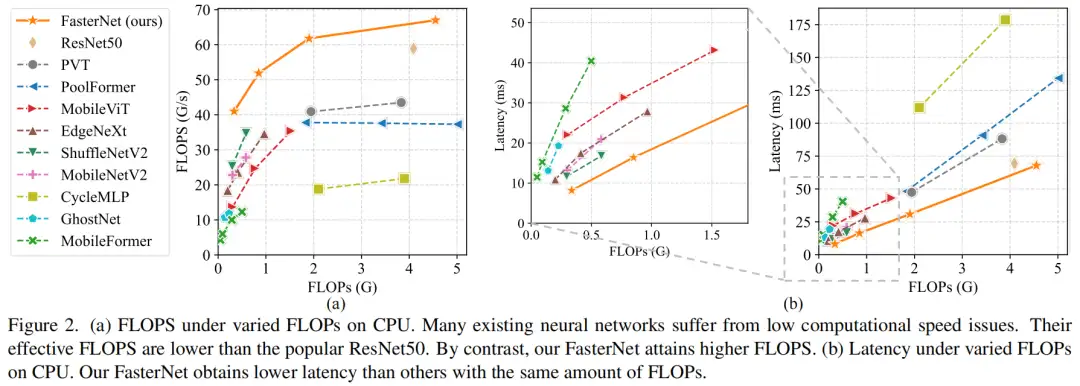
图2中的结果表明,许多现有神经网络的FLOPS较低,其FLOPS通常低于流行的ResNet50。由于FLOPS如此之低,这些“快速”的神经网络实际上不够快。它们的FLOPs减少不能转化为延迟的确切减少量。在某些情况下,没有任何改善,甚至会导致更糟的延迟。例如,CycleMLP-B1具有ResNet50的一半FLOPs,但运行速度较慢(即CycleMLPB1与ResNet50:111.9ms与69.4ms)。
请注意,FLOPs与延迟之间的差异在之前的工作中也已被注意到,但由于它们采用了DWConv/GConv和具有低FLOPs的各种数据处理,因此部分问题仍未解决。人们认为没有更好的选择。
本文旨在通过开发一种简单、快速、有效的运算符来消除这种差异,该运算符可以在减少FLOPs的情况下保持高FLOPS。
具体来说,作者重新审视了现有的操作符,特别是DWConv的计算速度——FLOPS。作者发现导致低FLOPS问题的主要原因是频繁的内存访问。然后,作者提出了PConv作为一种竞争性替代方案,它减少了计算冗余以及内存访问的数量。
图1说明了PConv的设计。它利用了特征图中的冗余,并系统地仅在一部分输入通道上应用规则卷积(Conv),而不影响其余通道。本质上,PConv的FLOPs低于常规Conv,而FLOPs高于DWConv/GConv。换句话说,PConv更好地利用了设备上的计算能力。PConv在提取空间特征方面也很有效,这在本文后面的实验中得到了验证。
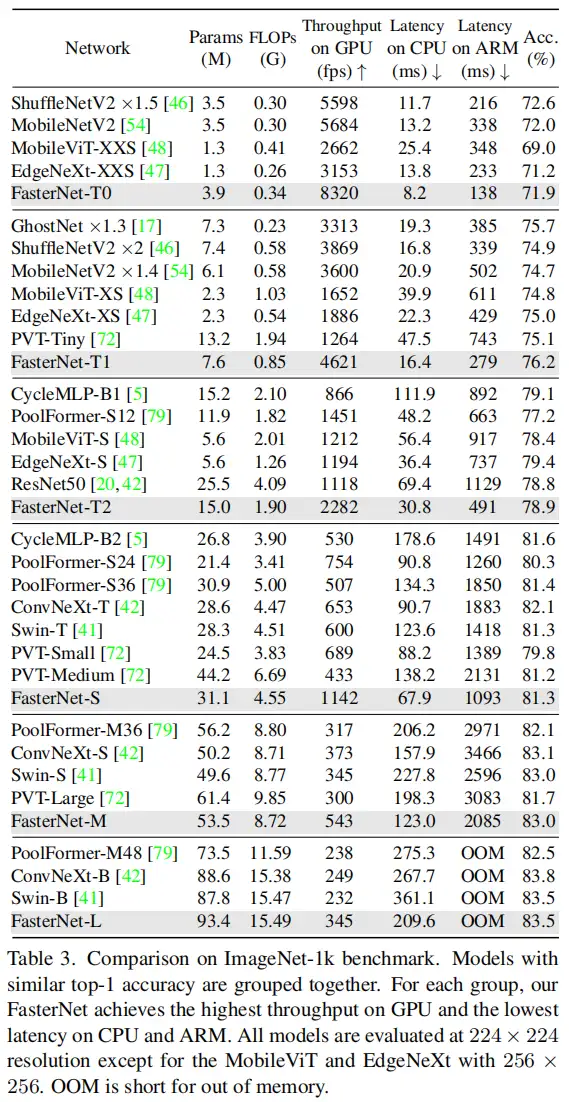
作者进一步引入PConv设计了FasterNet作为一个在各种设备上运行速度非常快的新网络家族。特别是,FasterNet在分类、检测和分割任务方面实现了最先进的性能,同时具有更低的延迟和更高的吞吐量。例如,在GPU、CPU和ARM处理器上,小模型FasterNet-T0分别比MobileVitXXS快3.1倍、3.1倍和2.5倍,而在ImageNet-1k上的准确率高2.9%。大模型FasterNet-L实现了83.5%的Top-1精度,与Swin-B不相上下,同时在GPU上提供了49%的高吞吐量,在CPU上节省了42%的计算时间。
总之,贡献如下:
- 指出了实现更高FLOPS的重要性,而不仅仅是为了更快的神经网络而减少FLOPs。
- 引入了一种简单但快速且有效的卷积PConv,它很有可能取代现有的选择DWConv。
- 推出FasterNet,它在GPU、CPU和ARM处理器等多种设备上运行良好且普遍快速。
- 对各种任务进行了广泛的实验,并验证了PConv和FasterNet的高速性和有效性。
2、PConv和FasterNet的设计
2.1、原理
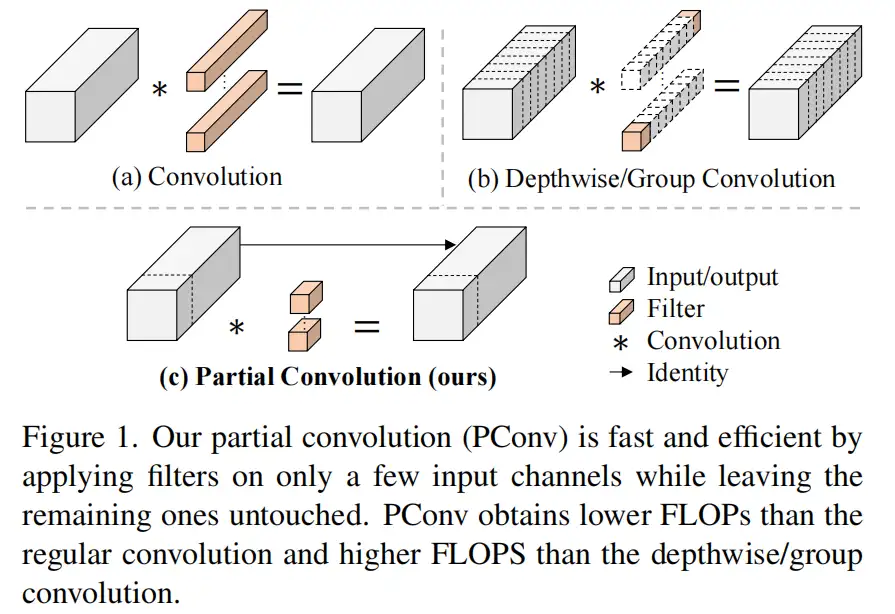
DWConv是Conv的一种流行变体,已被广泛用作许多神经网络的关键构建块。对于输入,DWConv应用个滤波器来计算输出。如图1(b)所示,每个滤波器在一个输入通道上进行空间滑动,并对一个输出通道做出贡献。
与具有的FLOPs常规Conv相比,这种深度计算使得DWConv仅仅具有的FLOPs。虽然在减少FLOPs方面有效,但DWConv(通常后跟逐点卷积或PWConv)不能简单地用于替换常规Conv,因为它会导致严重的精度下降。因此,在实践中,DWConv的通道数(或网络宽度)增加到>以补偿精度下降,例如,倒置残差块中的DWConv宽度扩展了6倍。然而,这会导致更高的内存访问,这会造成不可忽略的延迟,并降低总体计算速度,尤其是对于I/O绑定设备。特别是,内存访问的数量现在上升到
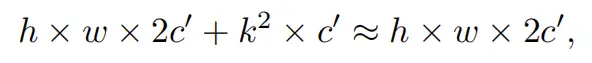
它比一个常规的Conv的值要高,即,
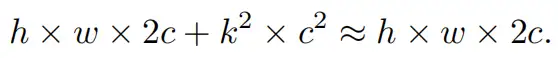
注意,内存访问花费在I/O操作上,这被认为已经是最小的成本,很难进一步优化。
2.2、PConv作为一个基本的算子

在下面演示了通过利用特征图的冗余度可以进一步优化成本。如图3所示,特征图在不同通道之间具有高度相似性。许多其他著作也涵盖了这种冗余,但很少有人以简单而有效的方式充分利用它。
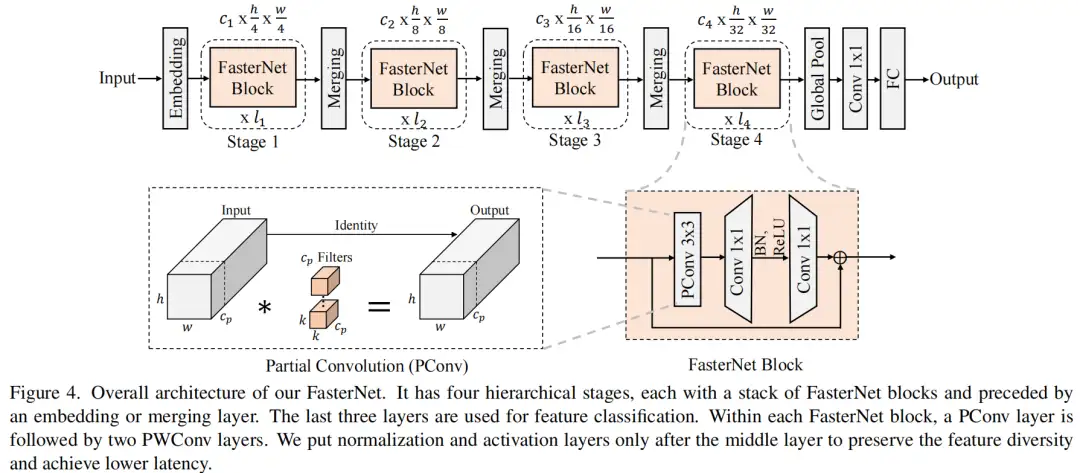
具体而言,作者提出了一种简单的PConv,以同时减少计算冗余和内存访问。图4中的左下角说明了PConv的工作原理。它只需在输入通道的一部分上应用常规Conv进行空间特征提取,并保持其余通道不变。对于连续或规则的内存访问,将第一个或最后一个连续的通道视为整个特征图的代表进行计算。在不丧失一般性的情况下认为输入和输出特征图具有相同数量的通道。因此,PConv的FLOPs仅
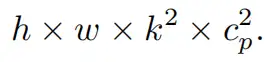
对于典型的r=1/4 ,PConv的FLOPs只有常规Conv的1/16。此外,PConv的内存访问量较小,即:
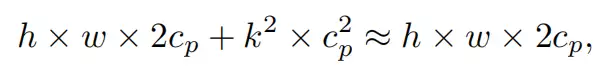
对于r=1/4,其仅为常规Conv的1/4。
由于只有通道用于空间特征提取,人们可能会问是否可以简单地移除剩余的(c−)通道?如果是这样,PConv将退化为具有较少通道的常规Conv,这偏离了减少冗余的目标。
请注意,保持其余通道不变,而不是从特征图中删除它们。这是因为它们对后续PWConv层有用,PWConv允许特征信息流经所有通道。
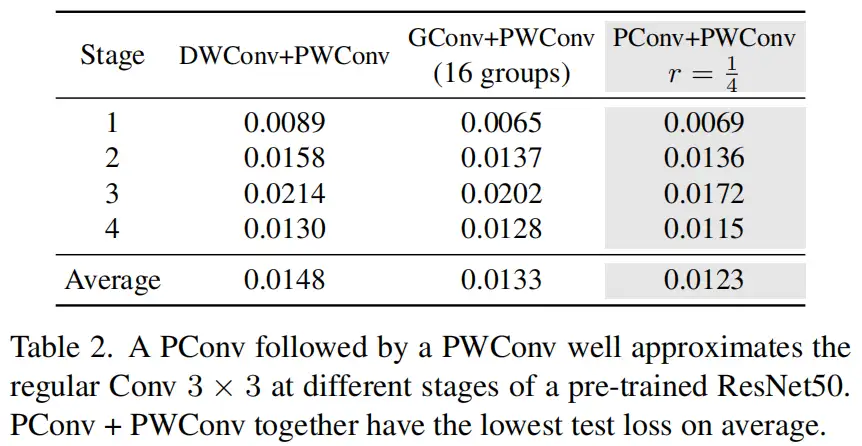
2.3、PConv之后是PWConv
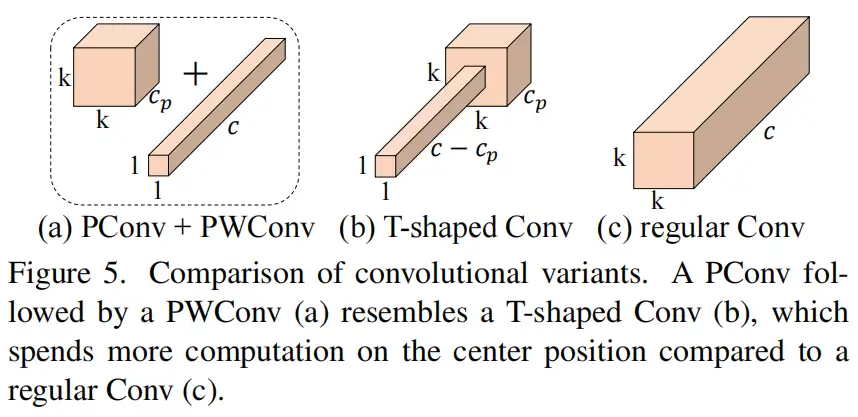
为了充分有效地利用来自所有通道的信息,进一步将逐点卷积(PWConv)附加到PConv。它们在输入特征图上的有效感受野看起来像一个T形Conv,与均匀处理补丁的常规Conv相比,它更专注于中心位置,如图5所示。为了证明这个T形感受野的合理性,首先通过计算位置的Frobenius范数来评估每个位置的重要性。
假设,如果一个职位比其他职位具有更大的Frobenius范数,则该职位往往更重要。对于正则Conv滤波器,位置处的Frobenius范数由计算,其中。
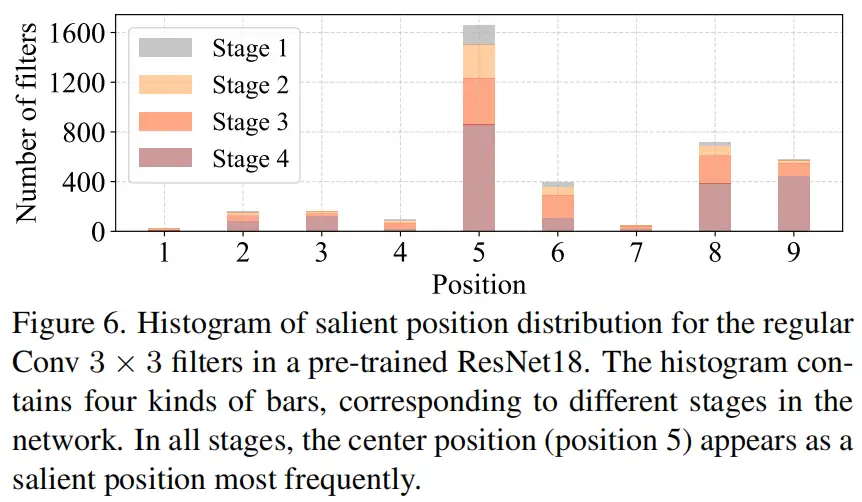
作者认为一个显著位置是具有最大Frobenius范数的位置。然后,在预训练的ResNet18中集体检查每个过滤器,找出它们的显著位置,并绘制显著位置的直方图。图6中的结果表明,中心位置是过滤器中最常见的突出位置。换句话说,中心位置的权重比周围的更重。这与集中于中心位置的T形计算一致。
虽然T形卷积可以直接用于高效计算,但作者表明,将T形卷积分解为PConv和PWConv更好,因为该分解利用了滤波器间冗余并进一步节省了FLOPs。对于相同的输入和输出,T形Conv的FLOPs可以计算为:
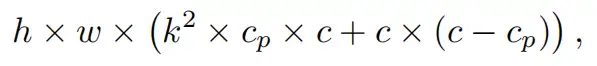
它高于PConv和PWConv的流量,即:
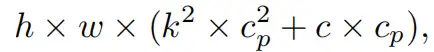
其中和(例如,当时)。此外,可以很容易地利用常规Conv进行两步实现。
2.4、FasterNet作为Backbone
鉴于新型PConv和现成的PWConv作为主要的算子,进一步提出FasterNet,这是一个新的神经网络家族,运行速度非常快,对许多视觉任务非常有效。作者的目标是使体系结构尽可能简单,使其总体上对硬件友好。

在图4中展示了整体架构。它有4个层次级,每个层次级前面都有一个嵌入层(步长为4的常规4×4卷积)或一个合并层(步长为2的常规2×2卷积),用于空间下采样和通道数量扩展。每个阶段都有一堆FasterNet块。作者观察到,最后两个阶段中的块消耗更少的内存访问,并且倾向于具有更高的FLOPS,如表1中的经验验证。因此,放置了更多FasterNet块,并相应地将更多计算分配给最后两个阶段。每个FasterNet块有一个PConv层,后跟2个PWConv(或Conv 1×1)层。它们一起显示为倒置残差块,其中中间层具有扩展的通道数量,并且放置了Shorcut以重用输入特征。
除了上述算子,标准化和激活层对于高性能神经网络也是不可或缺的。然而,许多先前的工作在整个网络中过度使用这些层,这可能会限制特征多样性,从而损害性能。它还可以降低整体计算速度。相比之下,只将它们放在每个中间PWConv之后,以保持特征多样性并实现较低的延迟。
此外,使用批次归一化(BN)代替其他替代方法。BN的优点是,它可以合并到其相邻的Conv层中,以便更快地进行推断,同时与其他层一样有效。对于激活层,根据经验选择了GELU用于较小的FasterNet变体,而ReLU用于较大的FasterNet变体,同时考虑了运行时间和有效性。最后三个层,即全局平均池化、卷积1×1和全连接层,一起用于特征转换和分类。
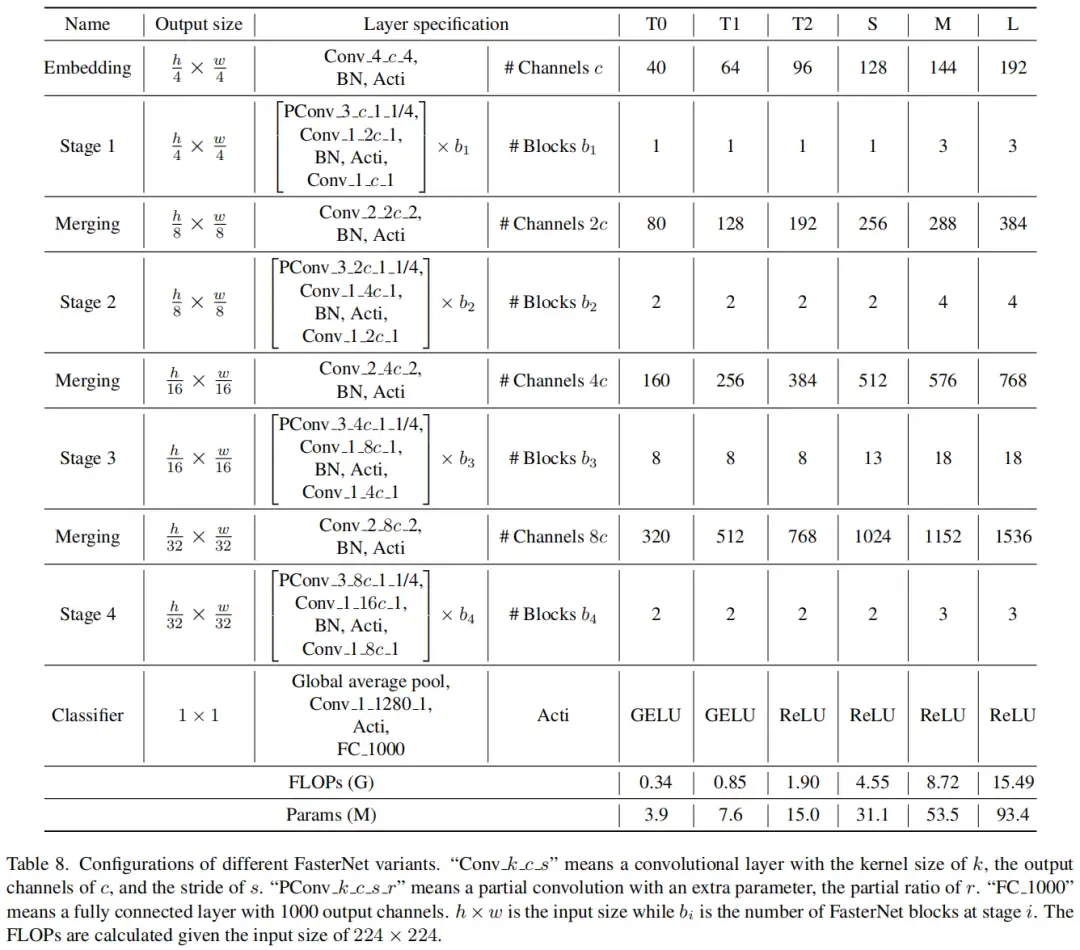
为了在不同的计算预算下提供广泛的应用,提供FasterNet的Tiny模型、Small模型、Medium模型和Big模型变体,分别称为FasterNetT0/1/2、FasterNet-S、FasterNet-M和FasterNet-L。它们具有相似的结构,但深度和宽度不同。
架构规范如下:
2.5、代码实现

3、实验
3.1、PConv的快速性与高Flops
3.2、PConv与PWConv一起有效
3.3、FasterNet on ImageNet-1k
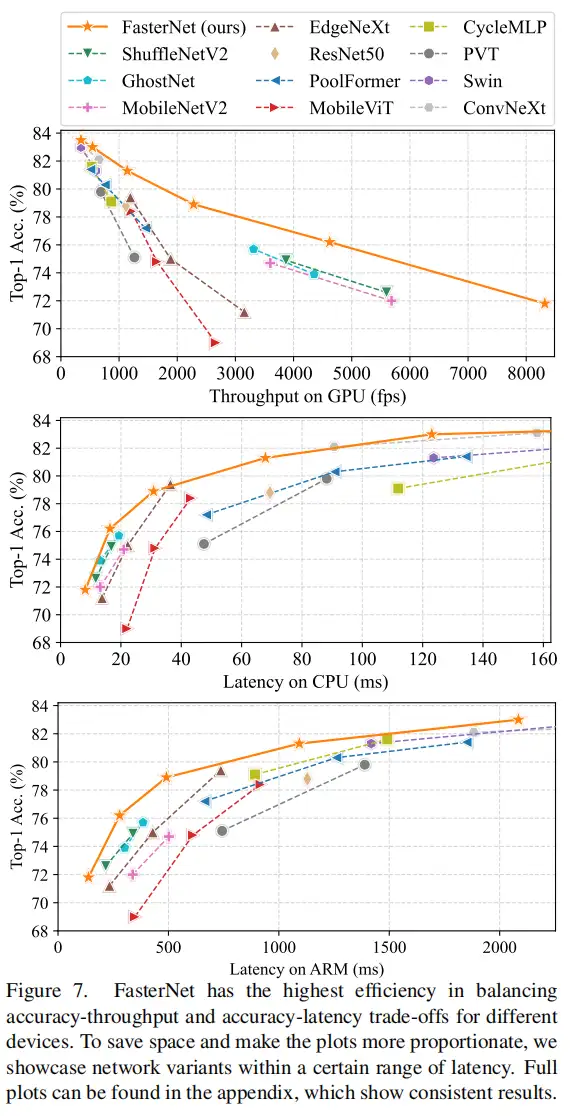
3.4、FasterNet在下游任务的表现
1、目标检测
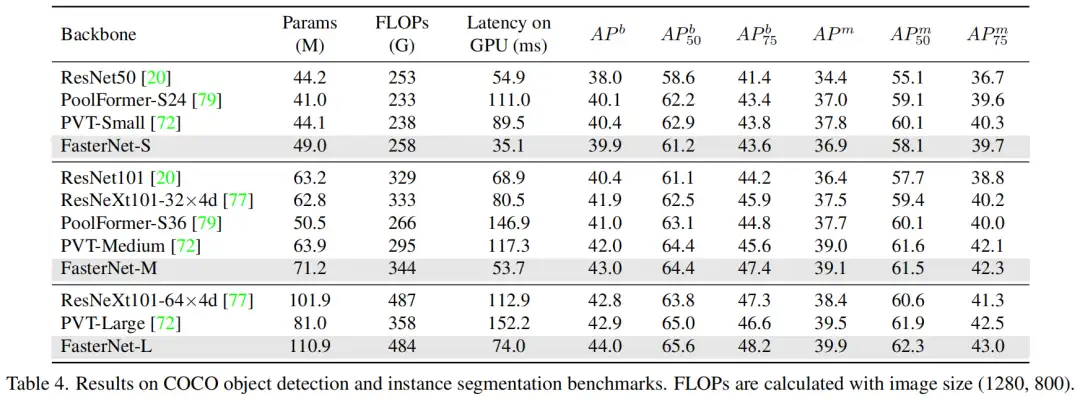
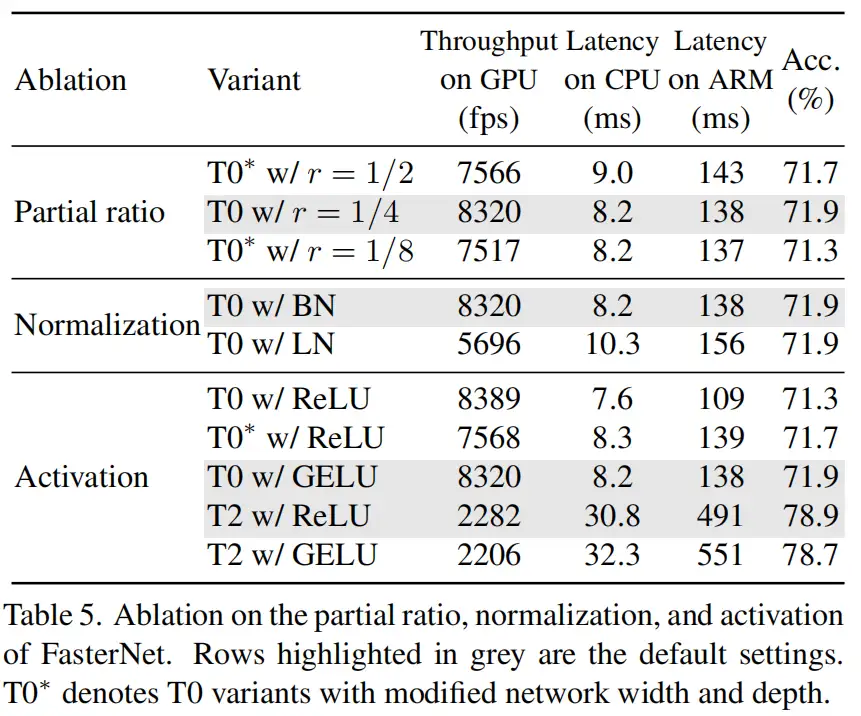
3.5、消融实验
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
AAAI 2023 | 一种通用的粗-细视觉Transformer加速方案
【免费送书活动】 全新轻量化模型 | 轻量化沙漏网络助力视觉感知涨点
目标检测、实例分割、旋转框样样精通!详解高性能检测算法 RTMDet
大卷积模型 + 大数据集 + 有监督训练!探寻ViT的前身:Big Transfer (BiT)
超快语义分割 | PP-LiteSeg集速度快、精度高、易部署等优点于一身,必会模型!!!
AAAI | Panini-Net | 基于GAN先验的退化感知特征插值人脸修
与SENet互补提升,华为诺亚提出自注意力新机制:Weight Excitation
最新FPN | CFPNet即插即用,助力检测涨点,YOLOX/YOLOv5均有效

 浙公网安备 33010602011771号
浙公网安备 33010602011771号