点云模型专栏(一)概述、特性、存储格式、数据集
前言 从本篇文章开始,咱们将带大家从最基本的点云表示、应用开始,逐步讲授深度学习中的基本模型、处理方案等。本教程将按以下目录来更新,可能日后会有所调整。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
本教程禁止转载。同时,本教程来自知识星球【CV技术指南】更多技术教程,可加入星球学习,文末可领取限时优惠券。
在智能感知任务中,视觉是一种最常见的方式,它可以很清晰地表达很多东西,例如颜色、纹理、形状、空间关系等。但它同样存在一些缺陷,例如受光线影响很大、夜晚效果极差、无法获得绝对尺度(即便有深度相机,其性能也完全不够用于现实应用)等。因此,视觉感知可以应用的领域仍然有限,而点云则很好地弥补了这些缺陷,它不受光线影响,白天黑夜都可以使用,可以获取物体的绝对尺度。在大部分人的认知里,学CV就是默认学视觉感知,但在实际应用上,视觉和点云本质上没啥区别,深度学习目前也已深入到点云处理的任务中,虽然点云仍然以传统方法为主,但深度学习的方法在以后将不可避免成为主流方案。因此,从这个角度来看,深度学习不管是处理点云、还是处理图像,本质上都没区别。
内容安排大致如下:
点云模型专栏(一)概述、基本知识
点云模型专栏(二)点云深度学习任务介绍
点云模型专栏(三)~(七)点云分类模型介绍
点云模型专栏(八)~(十二)点云检测模型介绍
点云模型专栏(十三)~(十七)点云跟踪模型介绍
点云模型专栏(十八)~(二十二)点云分割模型介绍
点云模型专栏(二十三)总结
(一)点云定义及数据获取
点云数据主要是由激光雷达扫描仪进行扫描采集得到的,从本质上来讲是点云是3D空间中无序、无结构的海量数据点的集合,每个点表达目标空间分布和目标表面特性。比如说,扫描某建筑物,得到的每个虚拟的数据点将代表窗户、楼梯、墙壁等任何表面上的真实的点,且包含了如三维坐标、颜色、强度值和入射方向等属性信息。点云数据的获取不仅只有激光雷达扫描这一种方式,还可以利用RGB-D相机同时获取多帧彩色图像和深度图,再利用相机的参数间接生成点云。

(二)点云特性
(1)无序性。二维图像中的像素点有着固定的位置,但是点云的位置采用不同顺序读入时,有着多种可能。
(2)非结构性。神经网络将二维图像数据结构化为矩阵的形式,但是点云数据是非结构化的,直接输入到网络中非常困难。
(3)密度不一致性。现实场景中包含着不同类别的物体,因此相应的点云数据空间属性也不相同。当获取的数据密度发生变化时,模型该如何处理也成为了一个研究问题。
(4)信息不完整性。由于遮挡等问题,无法获取完整的属性描述,以及低分辨率采样,包含的信息比较片面。
(三)点云数据表示形式
点云的无序性、非结构化使其与二维图像卷积存在差异,因此二维检测中研究成熟的网络不能直接用于处理点云数据,并且点云的表示形式对模型的性能有着直接影响,因此了解点云数据的表示形式是很有必要的。

(1)点表示形式。点表示形式直接对点云进行处理,采用最原始的点云作为网络的输入,利用多层感知机提取特征信息,使得全部点都包含特征信息。点表示形式保留了丰富的信息,信息损失最小,但是数据量大,运行速度较慢。上图为原始点云表示效果图。
(2)体素表示形式。体素是数字数据在三维空间上分割的最小单位,类似于二维图像的最小单位像素,可以简单地理解为是立体的像素,是量化的,大小固定的点云数据。三维卷积神经网络可以直接应用在这种表示上。体素的大小以及每个体素可容纳的点云数量需要通过参数设置,因此不可避免地会造成信息丢失,而且运算和储存开销较大,实用性相对较低,且体素大小不易确定,会产生许多冗余的体素网格,给优化带来困难。下图为点云的体素表示:

(3)图表示形式。现实生活中存在大量的非结构化数据,比如社交网络等,这些数据的节点间存在联系,可以表示为图,三维点云数据可以看作图数据的一种,在原始点云的基础上构建了局部连接关系的点,较好地适应点云的不规则性。图结构的表示方法也使得图卷积神经网络可以直接运用,依靠图中节点之间的信息传递来捕获图中的依赖关系。
(四)点云的存储格式
点云目前的主要存储格式包括:pts、LAS、PCD、.xyz 和. pcap 等。
(1)pts 点云文件格式是最简便的点云格式,直接按三维坐标(x,y,z)顺序存储点云数据, 字符数据可以是整型或者浮点型。
(2)LAS是激光雷达数据(LiDAR),存储格式比 pts 复杂,允许不同的硬件和软件提供商输出可互操作的统一格式。下图是LAS格式文件实例。其中 C代表所属类别,F代表航线号,T表示GPS 时间,I表示回波强度,R表示第几次回波,N表示回波次数,A表示扫描角,RGB为RGB 颜色值。
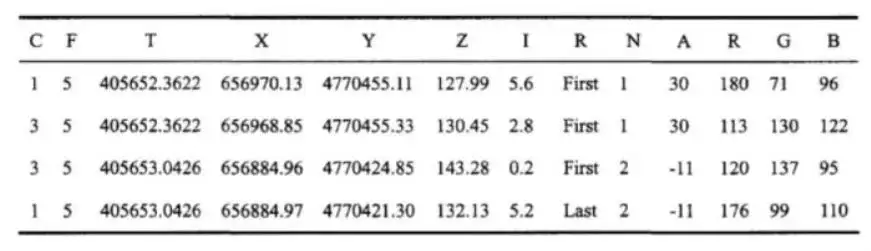
(3)PCD 存储格式是 PCL 库官方指定格式,典型的为点云量身定制的格式。优点是支持 n 维点类型扩展机制,能够更好地发挥 PCL 库的点云处理性能。文件格式有文本和二进制两种格式。
(4).xyz* 是一种文本格式,包含了3个坐标信息和法向量,数字间以空格分隔。
(5).pcap 是一种通用的数据流格式,现在流行的 Velodyne 公司出品的激光雷达默认采集数据文件格式,以二进制的形式保存。
(五)点云数据集
(1)ModelNet
论文:
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=7298801
数据集下载:http://modelnet.cs.princeton.edu
包括3个子数据集分别为ModelNet10、ModelNet40、Aligned40,其中ModelNet10、ModelNet40常用于点云分类任务中。

(2)ShapeNet
论文:
https://arxiv.org/pdf/1512.03012v1.pdf
数据集下载:https://shapenet.org/
用于点云的语义分割任务,有两个数据集分别是ShapeNetCore和ShapeNetSem数据集,其中ShapeNetCore涵盖了55个常见的类别,ShapeNetSem类别分布更广,包含270个类别并且使用了真实世界的尺寸标注、类别级别的材料成分估计值以及总体积和重量估计值进行注释。
下面两图分别是ShapeNetCore数据集中包含的类别以及每类别数量的介绍和ShapeNetSem数据集前100类及其数量的介绍。
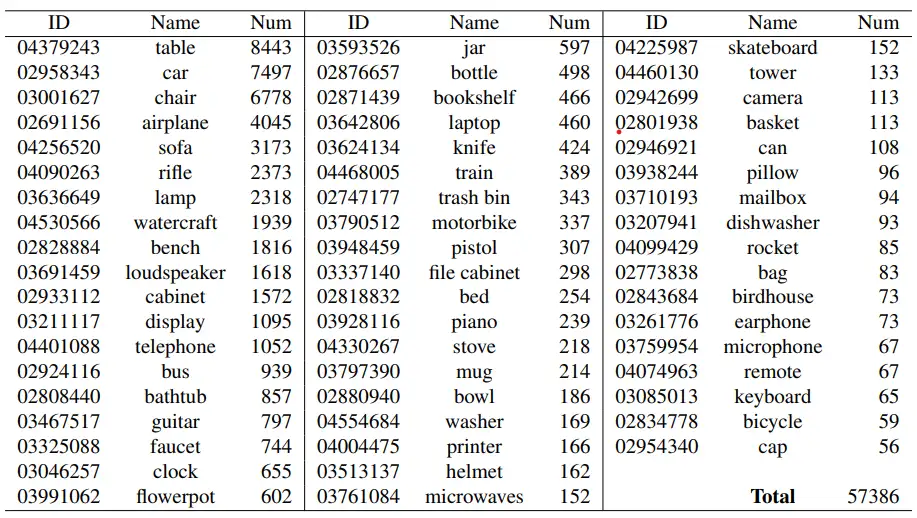
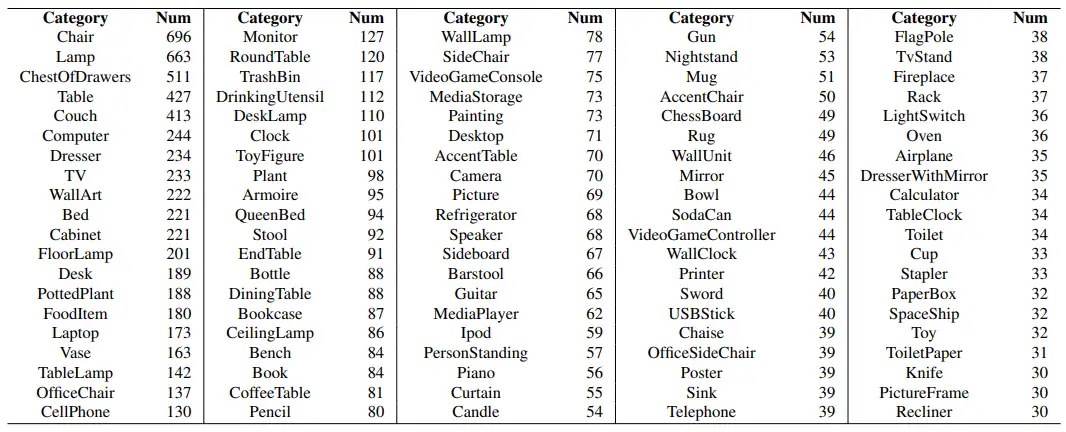
(3)ScanNet
论文:
https://arxiv.org/pdf/1702.04405.pdf
数据集下载:http://www.scan-net.org/
主要应用于三维点云分类,语义体素标注任务,该使用RGB-D摄像机采集得到室内场景数据集,一共1513个采集场景数据,共21个类别的对象。采集的数据信息包括RGB、深度、ply数据等信息,并且进行了实例级物体类别标签标注。数据集中样例展示如下图所示。

(4)KITTI
论文:
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=6248074
数据集下载:https://www.cvlibs.net/datasets/kitti/
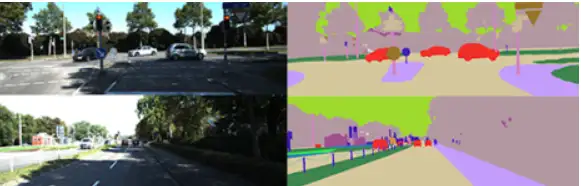
数据集针对多个不同的CV任务建立了BenchMark,可用于评测立体图像,光流,视觉测距,3D物体检测和3D跟踪等计算机视觉技术在车载环境下的性能。采集装置如下如中展示的那样,在车上配备两个高分辨率立体摄像系统(灰度和彩色),一个Velodyne HDL-64E激光扫描仪,每秒产生超过100万个3D点,一个最先进的OXTS RT 3003定位系统,结合了GPS, GLONASS, IMU和RTK校正信号,并且摄像机,激光扫描仪和定位系统都经过校准和同步。

stereo 2015 /flow 2015 /scene flow 2015
包含200个训练场景和200个测试场景(每个场景4张彩色图像,保存为png格式)。与stereo 2012和flow 2012基准相比,它包含了动态场景,其中真值框可半自动建立。
Stereo2015主要利用双目摄像头采集的信息,得出图像的立体视觉和三维重建。Optical Flow2015通过检测图像像素点的强度随时间的变化,推断出物体移动速度及方向。Scene Flow是在Flow的基础上,增加第三维信息。

深度估计任务
包含超过9.3万张深度地图,带有相应的原始激光雷达扫描和RGB图像,与KITTI数据集的原始数据保持一致。由于训练数据量大,该数据集需要训练复杂的深度学习模型来完成深度补全和单幅图像深度预测的任务。
视觉测距任务
由22个立体序列组成,保存为无损png格式,其中11个序列(00-10)是带有真值的轨迹用于训练,11个序列(11-21)用于评估。可以使用单目或立体视觉里程计、基于激光的SLAM或结合视觉和激光雷达信息的算法推算出车的行驶距离以及行驶轨迹等数据。

目标检测任务
包含了2D、3D和鸟瞰视角三种形式的数据。



跟踪任务
由21个训练序列和29个测试序列组成。可用于目标跟踪、多目标跟踪和分割(MOTS)以及分割和跟踪每个像素(STEP)任务。其中用于MOTS任务和STEP任务的数据是基于KITTI跟踪评估2012数据集,将注释进行扩展,为每个对象添加了像素级分割标签。
道路分割任务
由本田欧洲研究院Jannik Fritsch和Tobias Kuehnl合作创建。由289个训练图像和290个测试图像组成。它包含三种不同类型的道路场景:
Uu -市区无标记(98/100);
um-城市标记(95/96);umm-城市多标记车道(96/94);urban-以上三者的结合。
真值是由图像的手动注释生成的,可用于两种不同的道路地形类型。
语义实例分割任务
由200个带有语义注释的训练数据以及200个对应KITTI2015立体图像和光流测评的测试图像组成。
(5)S3DIS
论文:
数据集下载:http://buildingparser.stanford.edu/dataset.html
用于语义分割任务。该数据集收集了在 6 个大型室内区域 272 个 房间场景。共有 13 个类别。
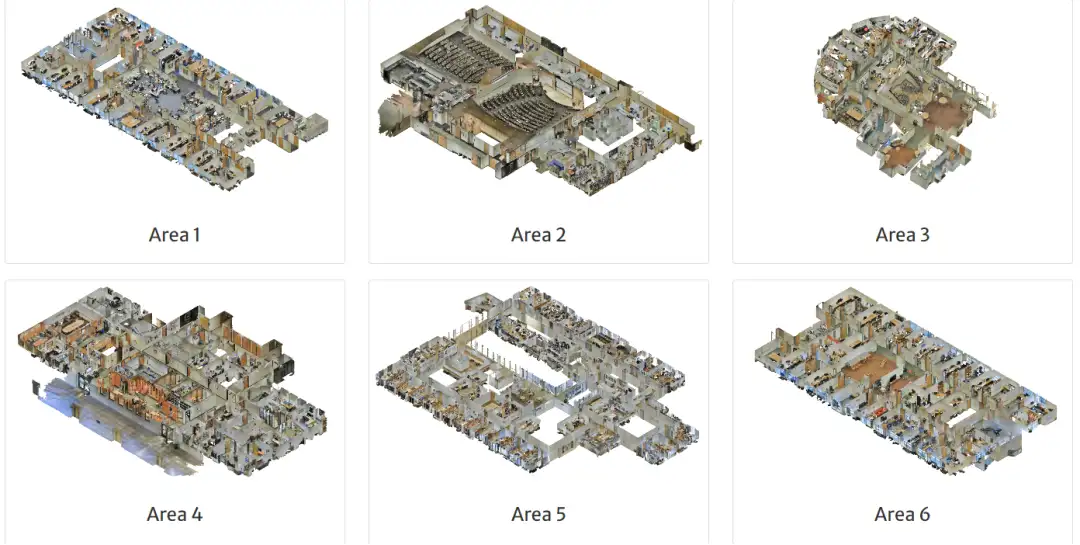
(6)Semantic3D
论文:
https://arxiv.org/pdf/1704.03847v1.pdf
数据集下载:https://semantic3d.net/
用于语义分割任务。其中包含自然场景综述超过40亿个点。涵盖了一系列不同的城市场景,如教堂,街道,铁轨,广场,村庄,足球场,城堡等等。

(六)点云数据处理办法
因为点云数据的无序性,所以处理点云数据的模型需要对数据的不同排列保持不变性,点云是在特定空间内获得的,所以点之间存在空间关系,所以对点云处理时要保证对一些空间变换保持不变性。
点云数据处理的办法可分为两大类。一是基于投影,二是直接对原始点云数据进行处理
基于投影的办法有:多视角投影和体素网格。其中多视角投影是将点云数据投影到固定的二维视角,然后再对二维图像进行处理。体素网格是将点云数据划分为有空间依赖关系的三维网格。
考虑到算法复杂性和充分利用点云数据的特性,有很多在原始点云数据上直接应用深度学习模型的方法。
下篇内容预告
下次的文章我们将要学习我们这个系列的第一个点云模型,PointNet,这是第一个将深度学习直接应用于原始点云数据的模型,也是三维目标检测的基础网络之一。
本教程来自知识星球【CV技术指南】更多技术教程,可加入星球学习,文末可领取限时优惠券。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
【免费送书活动】 全新轻量化模型 | 轻量化沙漏网络助力视觉感知涨点
目标检测、实例分割、旋转框样样精通!详解高性能检测算法 RTMDet
大卷积模型 + 大数据集 + 有监督训练!探寻ViT的前身:Big Transfer (BiT)
超快语义分割 | PP-LiteSeg集速度快、精度高、易部署等优点于一身,必会模型!!!
AAAI | Panini-Net | 基于GAN先验的退化感知特征插值人脸修
与SENet互补提升,华为诺亚提出自注意力新机制:Weight Excitation
最新FPN | CFPNet即插即用,助力检测涨点,YOLOX/YOLOv5均有效

 浙公网安备 33010602011771号
浙公网安备 33010602011771号