大卷积模型 + 大数据集 + 有监督训练!探寻ViT的前身:Big Transfer (BiT)
前言 本文回顾了在大数据集上进行预训练的范式,并且提出了一种简单的方法 Scale up 了预训练的数据集,得到的模型获得了很好的下游任务的性能,作者称之为 Big Transfer (BiT)。BiT 只需要预训练一次,后续对下游任务的微调成本很低。
本文转载自极市平台
作者 | CV开发者都爱看的
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
本文目录
1 ViT 的前奏:Scale up 卷积神经网络学习通用视觉表示
(来自谷歌,含 ViT 作者团队)
1 BiT 论文解读
1.1 背景和动机
1.2 Big Transfer 上游任务预训练
1.3 Big Transfer 下游任务迁移
1.4 上游任务预训练实验设置
1.5 下游任务迁移实验设置
1.6 标准计算机视觉 Benchmark 实验结果
1.7 单个数据集更少数据的实验结果
1.8 ObjectNet:真实世界数据集的实验结果
1.9 目标检测实验结果
太长不看版
最近偶然听到曹越老师在讲座回顾 | PaSS第二期-曹越博士-Swin Transformer和SimMIM背后的故事中提到了这篇文章 BiT (ECCV 2020)。它可以看做是 ViT 模型的前奏,其作者团队的主要成员依然是来自于谷歌大脑,并且涉及到多位 ViT 原作者。
这篇文章回顾了在大数据集上进行预训练的范式,并且提出了一种简单的方法 Scale up 了预训练的数据集,得到的模型获得了很好的下游任务的性能,作者称之为 Big Transfer (BiT)。通过组合一些精心的组件选择,并使用简单的迁移学习方法,BiT 在超过20个数据集上实现了强大的性能。
值得一提的是,本文 Scale up 预训练的模型是 ResNets。引述曹越老师的话,"这篇文章他们就选这个 ResNet 的架构并想办法 train 大。可能在这个过程中他们发现了一些困难,所以我猜测这就 motivate 他们,把这种朴素的 Transformer 的架构用到图片分类里",才使得这个团队开发出了后续的 ViT 模型。所以本文我愿称之为 "ViT 的前奏"。个人觉得 BiT 最重要的贡献是在2020年之前探索了大卷积模型 + 大数据集 + 有监督训练的暴力出奇迹的方法,并给出了这样预训练的模型在进行下游任务迁移时的一些启发和思考。
1 ViT 的前奏:Scale up 卷积神经网络学习通用视觉表示
论文名称:Big Transfer (BiT): General Visual Representation Learning (ECCV 2020)
论文地址:
https://arxiv.org/pdf/1912.11370.pdf
1.1 背景和动机
使用深度学习实现的强大性能通常需要大量 task-specific 的数据和计算。如果每个任务都经历这样的过程,就会给新任务的训练过程带来非常高昂的代价。迁移学习提供了一种解决方案:我们可以首先完成一个预训练 (Pre-train) 的阶段,即:在一个更大的,更通用的数据集上训练一次网络,然后使用它的权重初始化后续任务,这些任务可以用更少的数据和更少的计算资源来解决。
在本文中,作者重新审视了一个简单的范例,即:在大型有监督数据集上进行预训练 (注意本文是 ECCV 2020 的工作,当时的视觉模型有监督训练还是主流) ,并在目标任务上进行微调。本文的目标不是引入一个新的模型,而是提供一个 training recipe,使用最少的 trick,也能够在许多任务上获得出色的性能,作者称之为 Big Transfer (BiT)。
作者在3种不同规模的数据集上训练网络。最大的 BiT-L 是在 JFT-300M 数据集上训练的,该数据集包含 300M 噪声标记的图片。再将 BiT 迁移到不同的下游任务上。这些任务包括 ImageNet 的 ImageNet-1K,ciremote -10/100 ,Oxford-IIIT Pet,Oxford Flowers-102,以及1000样本的 VTAB-1k 基准。BiT-L 在许多这些任务上都达到了最先进的性能,并且在很少的下游数据可用的情况下惊人地有效。
重要的是,BiT 只需要预训练一次,后续对下游任务的微调成本很低。BiT 不仅需要对每个新任务进行简短的微调协议,而且 BiT 也不需要对新任务进行大量的超参数调优。作者提出了一种设置超参数的启发式方法,在多种任务中表现得很好。除此之外,作者强调了使 Big Transfer 有效的最重要的要素,并深入了解了规模、架构和训练超参数之间的相互作用。
1.2 Big Transfer 上游任务预训练
Big Transfer 上游预训练第一个要素是规模 (Scale)。众所周知,在深度学习中,更大的网络在各自的任务上表现得更好。但是,更大的数据集往往需要更大的架构才能有收益。作者研究了计算预算 (训练时间)、架构大小和数据集大小之间的相互作用,在3个大型数据集上训练了3个 BiT 模型:在 ImageNet-1K (1.3M 张图像) 上训练 BiT-S, 在 ImageNet-21K (14M 张图像) 上训练 BiT-M,在 JFT-300M (300M 张图像) 上训练 BiT-M。
Big Transfer 上游预训练第二个要素是 Group Normalization[1] 和权重标准化 (Weight Standardization, WS)[2]。在大多数的视觉模型中,一般使用 BN 来稳定训练,但是作者发现 BN 不利于 Big Transfer。
原因是:
- 在训练大模型时,BN 的性能较差,或者会产生设备间同步成本。
- 由于需要更新运行统计信息,BN 不利于下游任务的迁移。
当 GN 与 WS 结合时,已被证明可以提高 ImageNet 和 COCO 的小 Batch 的训练性能。本文中,作者证明了 GN 和WS 的组合对于大 Batch 的训练是有用的,并且对迁移学习有显著的影响。
1.3 Big Transfer 下游任务迁移
作者提出了一种适用于许多不同下游任务的微调策略。作者不去对每个任务和数据集进行昂贵的超参数搜索,每个任务只尝试一种超参数。作者使用了一种启发式的规则,BiT-HyperRule,选择最重要的超参数进行调优。作者发现,为每个任务设置以下超参数很重要:训练 Epoch、分辨率以及是否使用 MixUp 正则化。作者使用 BiT-HyperRule 处理超过20个任务,训练集从每类1个样本到超过1M个样本。
在微调中,作者使用以下标准数据预处理:将图像大小调整为一个正方形,裁剪出一个较小的随机正方形,并在训练时随机水平翻转图像。在测试时,只将图像调整为固定大小。这个固定大小作者设置为把分辨率提高一点,因为作者发现这样更适合迁移学习。
此外,作者还发现 MixUp 对于预训练 BiT 是没有用的,可能是由于训练数据比较丰富。但是,它有时对下游的迁移是有效的。令人惊讶的是,作者在下游调优期间不使用以下任何形式的正则化技术 (regularization):权值衰减到零、权值衰减到初始参数或者 Dropout。尽管网络非常大,BiT 有9.28亿个参数,但是却在没有正则化的情况下,性能惊人好。作者发现更大的数据集训练更长的时间,可以提供足够的正则化。
1.4 上游任务预训练实验设置
作者在3个大型数据集上训练了3个 BiT 模型:在 ImageNet-1K (1.3M 张图像) 上训练 BiT-S, 在 ImageNet-21K (14M 张图像) 上训练 BiT-M,在 JFT-300M (300M 张图像) 上训练 BiT-M。注意:“-S/M/L”后缀指的是预训练数据集的大小和训练时长,而不是架构的大小。作者用几种架构大小训练 BiT,最大的是 ResNet152x4。
所有的 BiT 模型都使用原始的 ResNet-v2 架构,并在所有卷积层中使用 Group Normalization + Weight Standardization。
1.5 下游任务迁移实验设置
使用的数据集分别是:ImageNet-1K, CIFAR10/100, Oxford-IIIT Pet 和 Oxford Flowers-102。这些数据集在图像总数、输入分辨率和类别性质方面存在差异,从 ImageNet 和 CIFAR 中的一般对象类别到 Pet 和 Flowers 中的细粒度类别。
为了进一步评估 BiT 学习到的表征的普遍性,作者在 Visual Task Adaptation Benchmark (VTAB) 上进行评估。VTAB 由19个不同的视觉任务组成,每个任务有1000个训练样本。这些任务被分为3组:natural, specialized and structured,VTAB-1k 分数是这19项任务的平均识别表现。
下游任务迁移实验中,大多数的超参数在所有数据集中都是固定的,但是训练长度、分辨率和 MixUp 的使用取决于任务图像分辨率和训练集大小。
1.6 标准计算机视觉 Benchmark 实验结果
作者在标准基准上评估 BiT-L,对比的结果主要有2类:Generalist SOTA 指的是执行任务独立的预训练的结果,Specialist SOTA 指的是对每个任务分别进行预训练的结果。Specialist 的表征是非常有效的,但每个任务需要大量的训练成本。相比之下,Generalist 的表征只需要一次大规模的训练,然后就只有一个廉价的微调阶段。
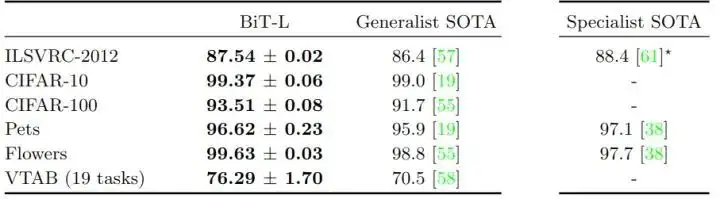
图1:标准计算机视觉 Benchmark 实验结果
受到在 JFT-300M 上训练 BiT-L 的结果的启发,作者还在公开的 ImageNet-21K 数据集上训练模型。对于 ImageNet-1K 这种大规模的数据集,有一些众所周知的,稳健的训练过程。但对于 ImageNet-21K 这种超大规模的数据集,有14,197,122张训练数据,包含21841个类别,在2020年,对于如此庞大的数据集,目前还没有既定的训练程序,本文作者提供了一些指导方针如下:
- 训练时长:增加训练时长和预算。
- 权重衰减:较低的权重衰减可以导致明显的加速收敛,但是模型最终性能不佳。这种反直觉的行为源于权值衰减和归一化层的相互作用。weight decay 变低之后,导致权重范数的增加,这使得有效学习率下降。这种效应会给人一种更快收敛的印象,但最终会阻碍进一步的进展。为了避免这种影响,需要一个足够大的权值衰减,作者在整个过程中使用10−4。
如下图2所示是与 ImageNet-1K 相比,在 ImageNet-21K 数据集上进行预训练时提高了精度,两种模型都是 ResNet152x4。
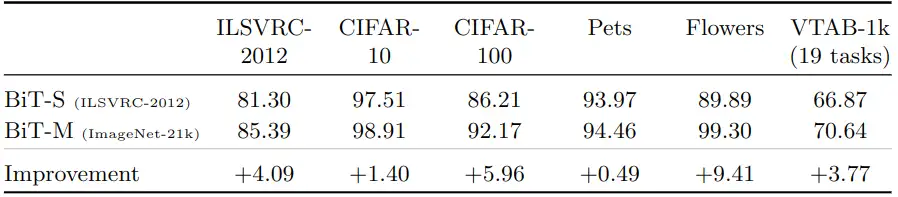
图2:与 ImageNet-1K 相比,在 ImageNet-21K 数据集上进行预训练时提高了精度,两种模型都是 ResNet152x4
1.7 单个数据集更少数据的实验结果
作者研究了成功转移 BiT-L 所需的下游数据的数量。作者使用 ImageNet-1K、CIFAR-10 和 CIFAR-100 的子集传输BiT-L,每个类减少到1个训练样本。作者还对19个 VTAB-1K 任务进行了更广泛的评估,每个任务有1000个训练样本。实验结果如下图3所示,令人惊讶的是,即使每个类只有很少的样本,BiT-L 也可以表现出强大的性能,并迅速接近全数据集的性能。特别是,在 ImageNet-1K 上,每个类只有5个标记样本时,其 top-1 的准确度达到 72.0%,而在100个样本时, top-1 的准确度达到 84.1%。在 CIFAR-100 中,我们每个类只有10个样本, top-1 的准确度达到 82.6%。
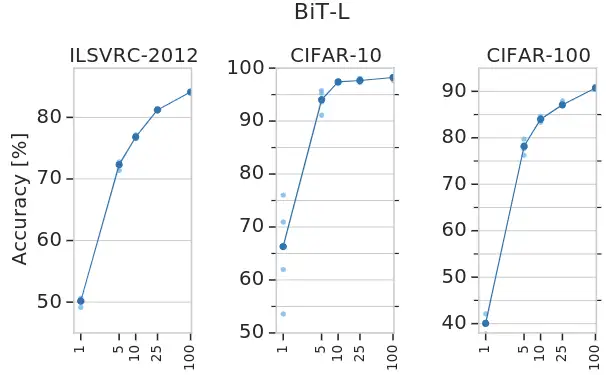
图3:单个数据集更少数据的实验结果
如下图4所示是 BiT-L 在19个 VTAB-1k 任务上的性能。在研究 VTAB-1k 任务子集的性能时,BiT 在 natural, specialized 和 structured 任务上是最好的。在上游预训练期间使用视频数据的 VIVIEx-100% 模型在结构化任务上展示出非常相似的性能。
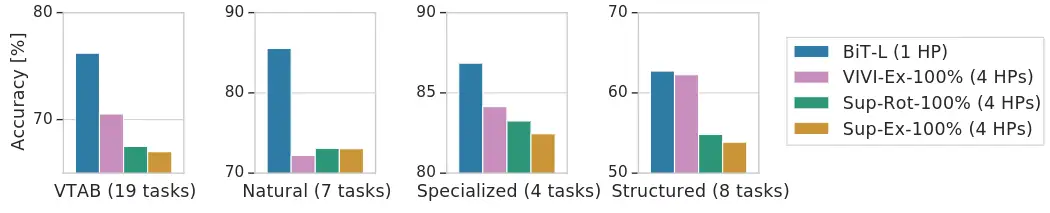
图4:BiT-L 在19个 VTAB-1k 任务上的性能
1.8 ObjectNet:真实世界数据集的实验结果
ObjectNet 数据集是一个仅包含测试集的,非常类似于现实场景的数据集,总共有313个类,其中113个与ImageNet-1K 重叠。实验结果如图5所示,更大的结构和对更多数据的预训练可以获得更高的准确性。作者还发现缩放模型对于实现 80% top-5 以上的精度非常重要。
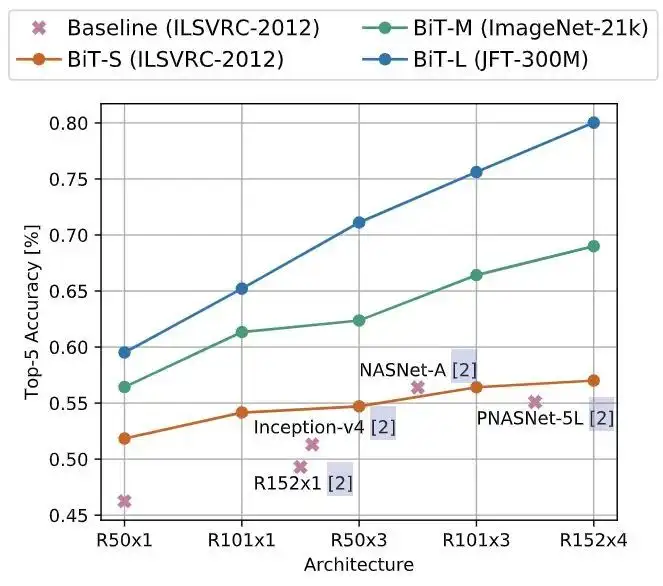
图5:ObjectNet 真实世界数据集的实验结果
1.9 目标检测实验结果
数据集使用 COCO,检测头使用 RetinaNet,使用预训练的 BiT 模型 ResNet-101x3 作为 Backbone,如下图6所示是实验结果。BiT 模型优于标准 ImageNet 预训练的模型,可以看到在 ImageNet-21K 上进行预训练,平均精度 (AP) 提高了1.5个点,而在 JFT-300M 上进行预训练,则进一步提高了0.6个点。

图6:目标检测实验结果
总结
本文回顾了在大数据集上进行预训练的范式,并且提出了一种简单的方法 Scale up 了预训练的数据集,得到的模型获得了很好的下游任务的性能,作者称之为 Big Transfer (BiT)。通过组合几个精心的组件,训练和微调的策略,并使用简单的迁移学习方法平衡复杂性和性能,BiT 在超过20个数据集上实现了强大的性能。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
超快语义分割 | PP-LiteSeg集速度快、精度高、易部署等优点于一身,必会模型!!!
AAAI | Panini-Net | 基于GAN先验的退化感知特征插值人脸修
与SENet互补提升,华为诺亚提出自注意力新机制:Weight Excitation
最新FPN | CFPNet即插即用,助力检测涨点,YOLOX/YOLOv5均有效
消费级显卡的春天,GTX 3090 YOLOv5s单卡完整训练COCO数据集缩短11.35个小时
原来Transformer就是一种图神经网络,这个概念你清楚吗?
TensorFlow 真的要被 PyTorch 比下去了吗?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号