一文带你掌握轻量化模型设计原则和训练技巧!
前言 本文将回顾轻量级模型的最新工作:EfficientFormer 和 TinyViT,分别从模型设计原则和模型训练技巧两个方面,对轻量化基础模型展开了详细的探索。
本文转载自OpenMMLab
作者 | 带来新知识的
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
EfficientFormer:
轻量级模型设计的经验指南
在实际应用中,一个可部署模型的实际推理速度是非常重要的,尤其是像 ViT 这类模型的部署是非常具有挑战的。该工作系统性地分析了 ViT 系列模型的架构和算子,基于分析结果提出了一系列提升推理速度的模型设计准则。最后,作者基于这些设计准则提出了推理速度与性能俱佳的 EfficientFormer 模型。
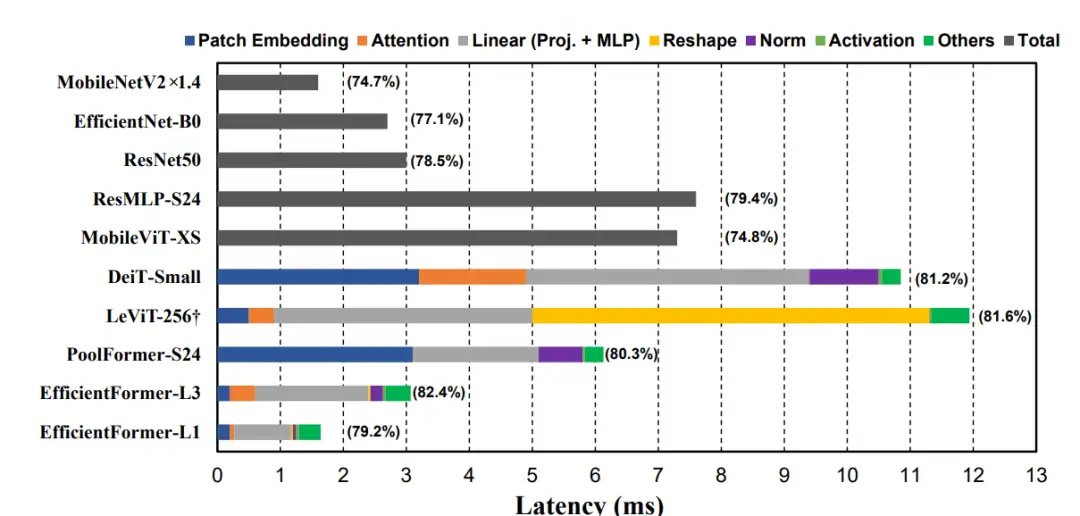
图 1:基于 iPhone12 CoreML 的模型延迟分析
不同视觉模型在端侧设备上的延迟分析
观察一:使用 large kernel 和 stride 的 patch embedding 层在移动设备上会是速度瓶颈。
作者发现相比于在 patch embedding layer 使用大卷积核 (k=16)DeiT-Small 或者 PoolFormer-S24,LeViT 中使用小 kernel size 构建的 patch embedding layer 具有更小的延迟。造成这一现象的主要原因是目前主流的端侧设备,无法很好地支持大卷积核的卷积操作。因此,使用多个 3x3 卷积堆叠来构建 patch embedding layer 会使得模型在端侧设备上具备更高的推理效率。
观察二:token mixer 中各个操作的特征维度的一致性是非常重要的。
Reshape 操作过多会影响推理速度。对比 PoolFormer 和 LeViT,前者始终使用 4D tensor,后者在 4D tensor 和 3D tensor 之间来回切换,会带来额外的推理延迟。对比 LeViT 和 DeiT,后者计算量要比前者更大,但由于 DeiT 的 token mixer 中都是 3D tensor,相比 LeViT 并没有显著的速度下降,再一次证明了特征维度的一致性十分重要。因此,在模型中尽量保持维度的一致性,减少 reshape 操作。
观察三:CONV-BN 操作相比 LN(GN)-Linear 操作会具有更好的速度-精度平衡。
MLP 是 Transformer 类模型的重要组成部分,通常其实现为 layer normalization(LN) + Linear 操作。在推理中, LN 或者 GN 需要计算当前数据的统计量,所以会占据带来的延迟。而使用卷积 (CONV)+batch normalization(BN) 的方式实现 MLP,虽然会带来轻微的精度损失,却比 LN-Linear 的延迟更低(推理时 BN 可以被融合进卷积操作中) 。因此,论文推荐使用 CONV-BN 操作来构建 MLP 层。
观察四:非线性激活函数的延迟跟硬件和编译器相关的。
论文发现在 iPhone 12 上,GeLU 并不会比 ReLU 有明显的推理延迟,但在其他设备上 GeLU 会比 ReLU 显著变慢。因此,非线性激活函数的选择需要根据硬件特点具体处理。
低延迟模型设计的具体实践:
EfficientTransformer
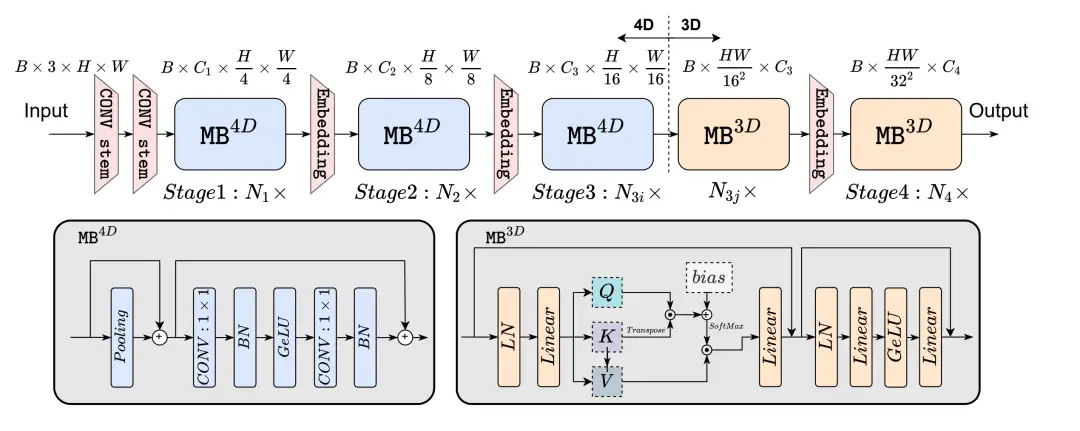
图 2:EfficientFormer 的模型结构
作者将上述观察转化为模型设计的指导思想,构建了如图 2 所示的模型结构。
- 在 EfficientFormer 中,使用了 3x3 卷积来构建 patch embedding layer。
- 为了保持每个 block 内的特征维度的一致性,同时有效地利用 attention 机制来提升模型性能,论文先用基于 4D Tensor 的卷积操作(标记为 MB^4D)构建了前 3 个 stage,再使用基于 3D Tensor 的注意力机制模块(标记为 MB^3D)完善和构建了后 2 个 stage。
- 在 MB^4D 中,作者使用了 Pooling 操作来作为 token mixer,同时使用了 CONV-BN 来构建 MLP。
- 在 MB^3D 中,作者使用了 MHSA(multi-head self-attention)作为 token mixer,使用 LN-Linear 的方式构建 MLP。
- 激活函数统一使用了 GeLU 形式。
基于延迟的模型结构搜索
论文在上述设计思路的基础之上,对模型的一些结构参数(如宽度,每个 stage 的深度)等进行了搜索。在具体的模型搜索算法上,论文使用了基于梯度的搜索算法进行模型的搜索,主要包含 3 步:
- 第 1 步:基于 Gumbel Softmax 采样算法训练一个 supernet,得到每个 stage 中各个模块的重要性得分。
- 第 2 步:收集 MB^4D 和 MB^3D 两种模块的延迟,并构建一个延迟查询表。
- 第 3 步:基于查询表,从 supernet 中确定如何对其进行瘦身。
实验结果
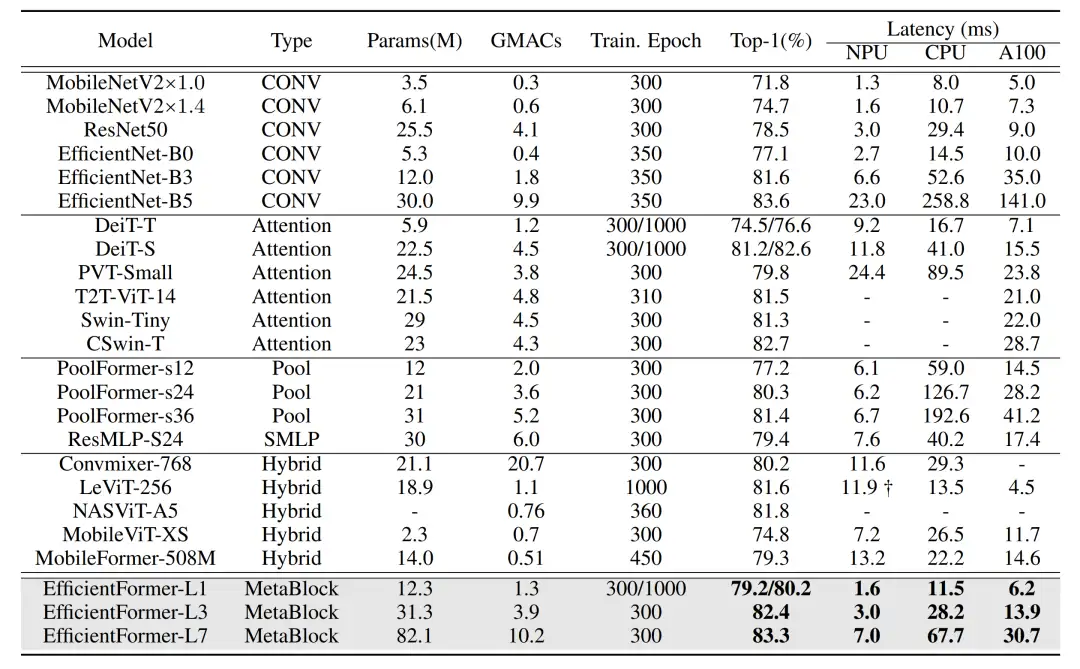
图 3:EfficientFormer 与其他模型的性能和速度对比
在 ImageNet-1K 的图像分类任务上(图 3),EfficientFormer 在实现与 MobileNetV2 类似的推理延迟下,实现了性能上的大幅提升。同时也在各类下游任务上也获得了明显的性能提升。
TinyViT:他山之石,可以攻玉
(基于蒸馏的小模型学习方案探索)
论文从模型训练的角度对轻量化模型进行了探索,研究如何有效地将已有的大模型的知识迁移到小模型上,提出了一种高效的蒸馏策略来学习轻量级的模型。同时,论文也提出了一种轻量化模型的新结构 TinyViT。
高效预训练蒸馏
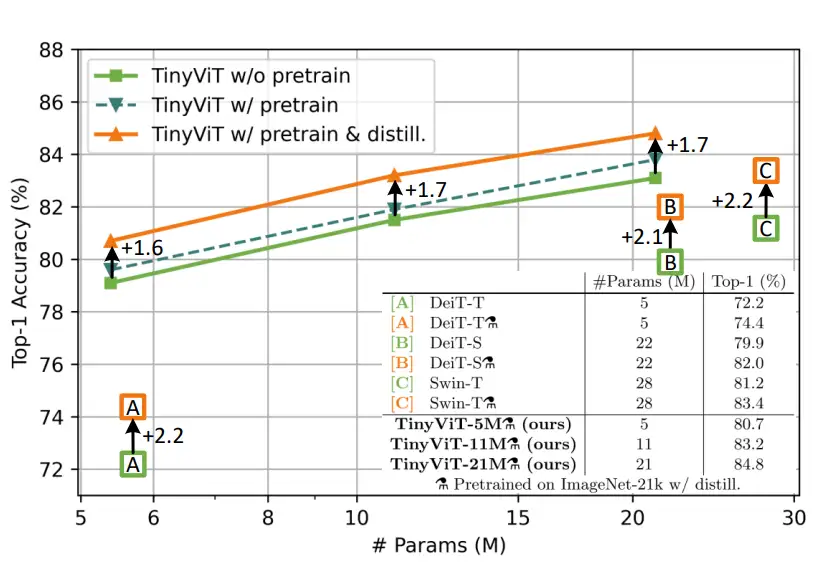
图 4:是否使用 ImageNet-21
预训练/蒸馏的性能对比
由于轻量化模型的建模能力有限,直接使用海量数据来训练小模型无法充分挖掘数据知识,提升模型性能。而在预训练小模型的同时,引入蒸馏技术,能有效提升小模型的建模能力。但是直接使用一个大模型进行在线蒸馏学习(即每个 iteration 都使用 teacher 模型来获取输入图像的预测结果)往往会耗费大量的计算资源和时间,如何实现高效的蒸馏策略是论文关心的一个主要问题。
高效蒸馏策略的核心是,避免在训练阶段显式地对每张图片都经过一遍教师模型。论文的思路是将数据增强后的数据和教师模型的预测都预先计算好存下来。
- 基于 encoder-decoder 的数据增强参数存储。由于直接存储数据增强涉及的参数会带来额外存储空间的消耗,因此论文提出来一种基于 encoder-decoder 模型的数据增强参数存储方案。具体做法是用一个 encoder 来将数据增强涉及到的参数作为输入,输出一个 single parameter 并只存储这个 single parameter,这样就可以大幅减少存储空间的消耗。在蒸馏训练阶段,使用 single parameter 即可解码出完整的数据增强参数。
- 稀疏预测 logit 蒸馏。论文提出的方法是使用 ImageNet-21K 进行模型预训练,该数据集的分类器有 21841 类。如果完整地存储教师网络的预测输出结果,将会占据海量的存储空间。因此这个工作只保留了每张图的 Top-K 个预测结果(logit),在保证蒸馏精度的同时减少存储空间的资源消耗。在具体的蒸馏操作上,论文不使用 label,只使用教师模型的稀疏预测结果来训练学生模型。
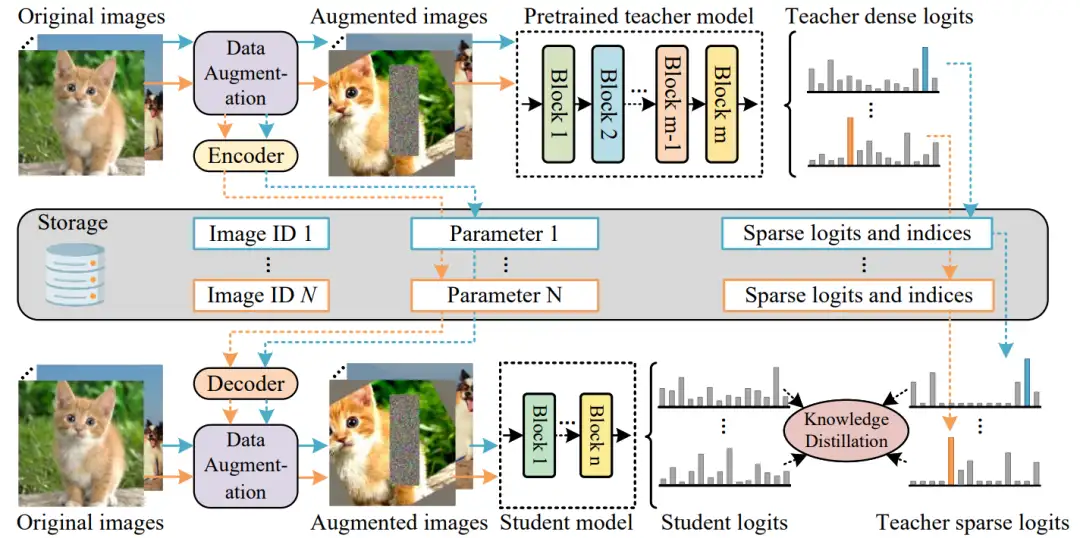
图 5:高效预训练蒸馏框架的示意图
TinyViT 的模型结构
TinyViT 沿用了与 Swin/LeViT 一样的 hierarchical 的结构,包括 4 个 stage。与 EfficientFormer 一样,TinyViT 使用 3x3 卷积层来构建 patch embedding layer。TinyViT 使用 MBConv-V3[3] 的基本模块来构建 stage-1,其他 3 个 stage 使用 window attention 来构建基本模块,使用 GeLU 作为激活函数。基于这些设置,TinyViT 构建了 5M, 11M 和 22M 三种参数量的模型。
实验与分析
论文还发现数据标注中的错误会进一步影响小模型的学习能力,并提出使用一个预训练模型来滤除 ImageNet-21K 中错误标注的数据,最后滤除了14% 的标注错误数据。
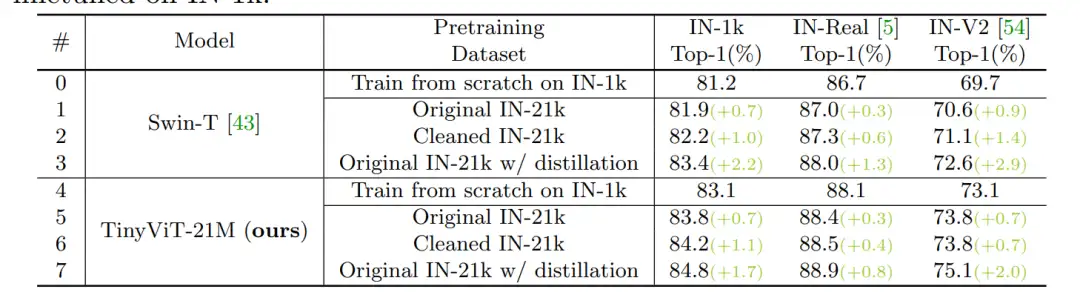
图 6:使用不同数据(清洗数据)的模型性能
实验表明:使用去噪之后的 ImageNet-21K 数据能有效提升 Swin-T 和 TinyViT-21M 的模型性能。
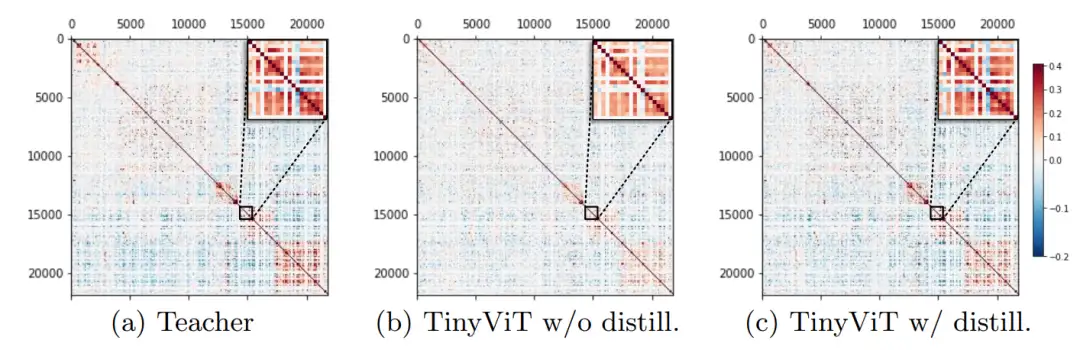
图 7:各个模型预测类别之间的 Pearson Correlation
分析表明:大模型能较好建模类别之间的相关性,而基于蒸馏的方式能帮助学生模型学到教师模型的类别关系先验。

图 8:使用不同模型架构的教师模型进行蒸馏的性能与资源消耗对比
实验表明:使用更大尺寸的预训练模型作为 teacher,能进一步提升模型在 IN-Real 和 IN-V2 上的性能
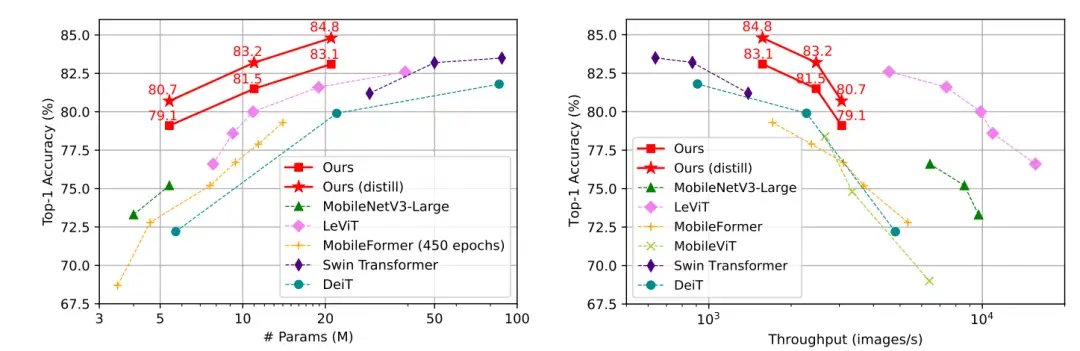
图 9:TinyViT 和其他方法的性能对比
分析表明:TinyViT 在和目前的前沿算法相比,展示出较好的速度精度平衡。
总结
本文介绍的两个模型主要在模型结构设计原则和模型学习策略上提出了改进。在具体的模型结构上,也均采用了 CNN+Attention 的架构。EfficientFormer 受益于对模型中延迟较高部分的改进,使得其在保持高性能的同时具有较高的推理速度。
TinyViT 从数据和训练目标的角度提出了高效蒸馏策略,充分挖掘了大模型的知识来帮助提升轻量化模型的性能。
以上两个模型目前已经集成在了 MMClassification 的 1.x 分支当中,欢迎对相关模型感兴趣的同学尝试。
EfficientFormer:
https://github.com/open-mmlab/mmclassification/tree/dev-1.x/configs/efficientformer
TinyViT:
https://github.com/open-mmlab/mmclassification/tree/dev-1.x/configs/tinyvit
参考文献:
- MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer. https://arxiv.org/pdf/2110.02178.pdf
- MobileNetV2: Inverted Residuals and Linear Bottlenecks: https://arxiv.org/pdf/1801.04381.pdf
- Searching for MobileNetV3.
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
与SENet互补提升,华为诺亚提出自注意力新机制:Weight Excitation
最新FPN | CFPNet即插即用,助力检测涨点,YOLOX/YOLOv5均有效
消费级显卡的春天,GTX 3090 YOLOv5s单卡完整训练COCO数据集缩短11.35个小时一层卷积能做啥?
原来Transformer就是一种图神经网络,这个概念你清楚吗?
TensorFlow 真的要被 PyTorch 比下去了吗?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号