
最新FPN | CFPNet即插即用,助力检测涨点,YOLOX/YOLOv5均有效
前言 现有的视觉特征金字塔方法过分集中于层间特征交互,而忽略了层内特征规则。一些方法试图借助注意力机制或视觉Transformer学习紧凑的层内特征表示,但它们忽略了对密集预测任务重要的被忽略的角区域。
为了解决这个问题,在本文中提出了一种用于目标检测的集中特征金字塔(CFP),它基于全局显式集中特征规则。具体而言,首先提出了一种空间显式视觉中心方案,其中使用轻量级MLP来捕获全局长距离依赖性,并使用并行可学习视觉中心机制来捕获输入图像的局部角区域。
在具有挑战性的MS-COCO上的实验结果验证了CFP可以在最先进的YOLOv5和YOLOX对象检测基线上实现一致的性能增益。该代码已发布于:CFPNet。
本文转载自集智书童
作者 | 小书童
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。

1、简介
目标检测是计算机视觉领域最基本但最具挑战性的研究任务之一,其目的是为输入图像中的每个目标预测唯一的边界框,该边界框不仅包含位置,还包含类别信息。在过去几年中,这项任务已被广泛开发并应用于广泛的潜在应用,例如自动驾驶和计算机辅助诊断。
成功的目标检测方法主要基于卷积神经网络(CNN)作为主干,然后是两阶段(例如,Fast/Faster R-CNN)或单阶段(例如SSD和YOLO)框架。然而,由于目标尺寸的不确定性,单一的特征尺度不能满足高精度识别性能的要求。
为此,提出了基于网络内特征金字塔的方法(例如SSD和FFP),并有效地获得了令人满意的结果。这些方法背后的统一原则是用适当的上下文信息为不同大小的每个目标分配感兴趣区域,并使这些目标能够在不同的特征层中被识别。
像素或目标之间的特征交互很重要。作者认为,有效的特征交互可以使图像特征看得更宽,并获得更丰富的表示,从而目标检测模型可以学习像素/目标之间的隐式关系(即,有利的共现特征),这已被经验证明有利于视觉识别任务。
例如,FPN提出了一种自上而下的层间特征交互机制,该机制使浅层特征能够获得深度特征的全局上下文信息和语义表示。NAS-FPN试图通过网络架构搜索策略学习特征金字塔部分的网络结构,并获得可缩放的特征表示。
除了层间交互之外,受非局部/自注意力机制的启发,用于空间特征调节的更精细的层内交互方法也应用于对象检测任务,例如非局部特征和GCNet。基于上述两种交互机制,FPT进一步提出了层间跨层和层内跨空间特征调节方法,并取得了显著的性能。

尽管在目标检测方面取得了初步的成功,但上述方法基于CNN主干,而CNN主干受到固有的极限感受野的影响。如图1(a)所示,标准CNN主干特征只能定位那些最具辨别力的目标区域(例如,“飞机机身”和“摩托车踏板”)。
为了解决这一问题,最近提出了基于视觉Transformer的目标检测方法,并蓬勃发展。这些方法首先将输入图像划分为不同的图像块,然后使用块之间基于多头注意力的特征交互来完成获取全局长距离相关性的目的。
正如预期的,特征金字塔也被用于视觉Transformer,例如PVT和Swin transformer。尽管这些方法可以解决CNN中有限的感受野和局部上下文信息,但一个明显的缺点是它们的计算复杂性大。例如,与输入大小为224×224的性能可比的CNN模型RegNetY相比,Swin-B具有几乎3倍的模型FLOP(即47.0G vs 16.0G)。
此外,如图1(b)所示,由于基于视觉Transformer的方法是以全方位和无偏的学习模式实现的,因此很容易忽略一些角落区域(例如,“飞机引擎”、“摩托车车轮”和“蝙蝠”),这些区域对于密集的预测任务很重要。这些缺点在大规模输入图像上更为明显。
为此,提出了一个问题:是否有必要在所有层上使用Transformer编码?为了回答这样的问题,作者从浅层特征的分析开始。对先进方法的研究表明,浅层特征主要包含一些一般的目标特征模式,例如纹理、颜色和方向,这些通常不是全局的。相反,深度特征反映了目标特定信息,通常需要全局信息。因此,作者认为Transformer编码器在所有层中都是不必要的。
在这项工作中提出了一种用于目标检测的集中式特征金字塔(CFP)网络,该网络基于全局显式集中式规则方案。具体而言,基于从CNN主干提取的视觉特征金字塔,首先提出了一种显式视觉中心方案,其中使用轻量级MLP架构来捕获长距离依赖,并使用并行可学习视觉中心机制来聚合输入图像的局部关键区域。
考虑到最深的特征通常包含浅层特征中缺乏的最抽象的特征表示这一事实,基于所提出的规则方案,然后以自上而下的方式对提取的特征金字塔提出了全局集中的规则,其中从最深特征获得的空间显式视觉中心用于同时调节所有的前部浅特征。
与现有的特征金字塔相比,如图1(c)所示,CFP不仅能够捕获全局长距离依赖关系,而且能够有效地获得全面但有区别的特征表示。为了证明其优越性,在具有挑战性的MS-COCO数据集上进行了广泛的实验。结果验证了提出的CFP可以在最先进的YOLOv5和YOLOX目标检测基线上实现一致的性能增益。
贡献总结如下:
- 提出了一种空间显式视觉中心方案,该方案由用于捕获全局长距离依赖的轻量级MLP和用于聚集局部关键区域的可学习视觉中心组成;
- 以自上而下的方式为常用的特征金字塔提出了一个全球集中的规则;
- CFP在强目标检测基线上实现了一致的性能增益。
2、相关工作
2.1、计算机视觉中的特征金字塔
特征金字塔是现代识别系统中的一个基本Neck网络,可以有效地检测不同尺度的物体。SSD是最早使用金字塔特征层次表示的方法之一,它通过不同空间大小的网络捕获多尺度特征信息,从而提高了模型识别精度。
FPN在层次上主要依赖于自底向上的网络内特征金字塔,该金字塔从多尺度高级语义特征图构建了具有横向连接的自顶向下路径。基于此PANet进一步提出了一种基于FPN的额外的自底向上路径,以在层间特征之间共享特征信息,使得高级特征也可以在低级特征中获得足够的细节。
在神经架构搜索的帮助下,NAS-FPN使用空间搜索策略通过特征金字塔跨层连接,并获得可扩展的特征信息。M2Det通过构建多级特征金字塔来提取多级和多尺度特征,以实现跨层次和跨层特征融合。
一般来说,特征金字塔可以在不增加计算开销的情况下处理目标识别中的多尺度变化问题;提取的特征可以生成包括一些高分辨率特征的多尺度特征表示。
在这项工作中从层间特征交互和特征金字塔的层内特征规则的角度提出了一种层内特征调节,这弥补了当前方法在这方面的不足。
2.2、视觉注意学习
CNN更加关注局部区域的代表性学习。然而,这种局部表示不能满足现代识别系统对全局上下文和长期依赖性的要求。为此,提出了注意力学习机制,该机制专注于决定在图像中的何处投射更多注意力。
例如,非局部操作使用非局部神经网络直接捕获长距离依赖关系,证明了非局部建模对于视频分类、目标检测和分割任务的重要性。然而,CNN内部性质的局部表示没有得到解决,即CNN功能只能捕获有限的上下文信息。
为了解决这个问题,主要受益于多头注意力机制的Transformer最近引起了巨大轰动,并在计算机视觉领域取得了巨大成功,如图像识别。例如,代表性VIT将图像分成具有位置编码的序列,然后使用级联Transformer块提取参数化向量作为视觉表示。
在此基础上,通过进一步改进,提出了许多优秀的模型,并在计算机视觉的各种任务中取得了良好的性能。然而,基于Transformer的图像识别模型仍然具有计算密集和复杂的缺点。
2.3、计算机视觉中的MLP
为了缓解复杂Transformer模型的缺点,最近的工作表明,用MLP替换Transformer模型中基于注意力的模块仍然表现良好。这种现象的原因是MLP(例如,2个完全连接的层网络)和注意力机制都是全局信息处理模块。
一方面,MLP Mixer的引入减轻了数据布局的变化。另一方面,MLP Mixer可以通过空间特征信息和通道特征信息之间的交互,更好地建立特征的长相关性/全局关系和空间关系。尽管MLPstyle模型在计算机视觉任务中表现良好,但它们在捕获细粒度特征表示和在目标检测中获得更高的识别精度方面仍然不足。
然而,MLP在计算机视觉领域发挥着越来越重要的作用,并且具有比Transformer更简单的网络结构的优点。在本文工作中,还使用MLP来捕获输入图像的全局上下文信息和长期相关性。本文的贡献在于使用所提出的空间显式视觉中心方案来获取信息的中心性。
2.4、 目标检测
目标检测是一项基本的计算机视觉任务,旨在识别给定图像的感兴趣的目标或实例,并提供包括目标类别和位置在内的全面场景描述。近年来,随着CNN的空前发展,许多目标检测模型取得了显著进展。现有的方法可分为两阶段和单阶段两种。两阶段目标检测器通常首先使用RPN来生成区域建议的集合。然后使用学习模块提取这些区域建议的区域特征,并完成分类和回归过程。
然而,存储和重复提取每个区域提议的特征不仅在计算上昂贵,而且使得不可能捕获全局特征表示。为此,单阶段检测器通过生成边界框直接执行预测和区域分类。现有的单阶段方法在特征提取的设计中具有全局概念,并使用主干网络提取整个图像的特征图来预测每个边界框。在本文中还选择了单阶段目标检测器(即YOLOv5和YOLOX)作为基线模型。重点是增强用于这些检测器的特征金字塔的表示。
3、本文方法
在本节中将介绍所提出的集中式特征金字塔(CFP)的实现细节。首先在第III-A节中概述了CFP的架构描述。然后,在第III-B节中展示了显式视觉中心的实现细节。最后,展示了如何在图像特征金字塔上实现显式视觉中心,并在第III-C节中提出了全局集中规则。
3.1、Centralized Feature Pyramid (CFP)
尽管现有的方法主要集中于层间特征交互,但它们忽略了层内特征规则,这已被经验证明对视觉识别任务有益。在本文的工作中,受先前关于密集预测任务的工作的启发,作者提出了一种基于全局显式集中层内特征调节的CFP用于目标检测。
与现有的特征金字塔相比,提出的CFP不仅可以捕获全局的长距离依赖关系,还可以实现全面和差异化的特征表示。
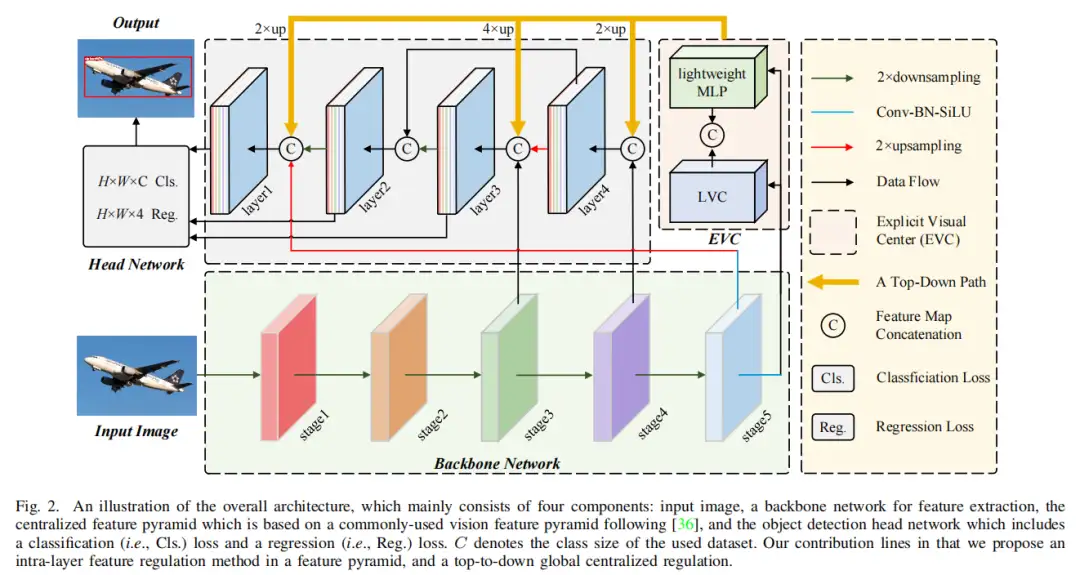
如图2所示,CFP主要由以下部分组成:输入图像、用于提取视觉特征金字塔的CNN主干、提出的显式视觉中心(EVC)、提出的全局集中规则(GCR)以及用于目标检测的去解耦head网络(由分类损失、回归损失和分割损失组成)。在图2中,EVC和GCR在提取的特征金字塔上实现。
具体来说,首先将输入图像送入主干网络(即修改后的CSP v5),以提取五级一特征金字塔X,其中每层特征的空间大小分别为输入图像的1/2,1/4,1/8,1/16,1/32。
基于这个特征金字塔CFP得以实现。提出了一种轻量级MLP架构来捕获的全局长程依赖性,其中标准Transformer编码器的多头自注意力模块被MLP层取代。与基于多头注意力机制的Transformer编码器相比,轻量级MLP架构不仅结构简单,而且体积更轻,计算效率更高。
此外,可学习的视觉中心机制与轻量级MLP一起用于聚合输入图像的局部角区域。将上述并行结构网络命名为空间EVC,其在特征金字塔的顶层(即)上实现。基于所提出的ECV,为了使特征金字塔的浅层特征能够以有效的模式同时受益于最深特征的视觉集中信息,其中从最深层内特征获得的显式视觉中心信息被用于同时调节所有前部浅特征(即至)。最后,将这些特征聚合到一个解耦头中进行分类和回归。
3.2、 Explicit Visual Center (EVC)
如图3所示,提出的EVC主要由两个并行连接的块组成,其中使用轻量级MLP来捕获顶级特征的全局长期依赖性(即全局信息)。同时,为了保留局部角区域(即,局部信息),提出在上实现可学习的视觉中心机制以聚集层内局部区域特征。
这两个块的结果特征图沿着信道维度连接在一起,作为用于下游识别的EVC的输出。在实现中,在和EVC之间,Stem块用于特征平滑,而不是直接在原始特征图上实现,如YOLOv5所示。Stem块由输出通道大小为256的7×7卷积组成,随后是批处理归一化层和激活函数层。上述过程可表述为:
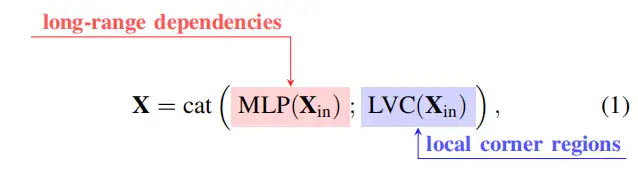
其中是EVC的输出。表示沿通道维度的特征图连接。和分别表示所使用的轻量级MLP和可学习视觉中心机制的输出特征。是阀杆组的输出,通过以下公式获得:
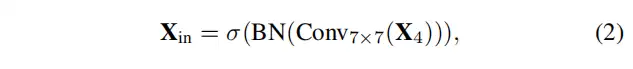
其中表示7×7与stride=1的卷积,本文的工作将通道大小设置为256。表示批处理归一化层,表示ReLU激活函数。
1、MLP
使用的轻量级MLP主要由两个残差模块组成:基于深度卷积的模块和基于通道MLP的块,其中基于MLP的模块的输入是基于深度卷积模块的输出。这两个块之后都是通道缩放操作和DropPath操作,以提高特征泛化和鲁棒性能力。
具体地,对于基于深度卷积的模块,从Stem模块输出的特征首先被馈送到深度卷积层,该深度卷积层已经通过组归一化处理(即,沿着通道维度对特征图进行分组)。与传统的空间卷积相比,深度卷积可以提高特征表示能力,同时降低计算成本。然后,实现通道缩放和droppath。之后,实现的残差连接。上述过程可表述为:
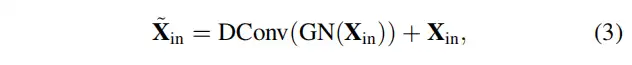
其中是基于深度卷积的模块的输出。是群归一化,而则是核大小为1×1的深度卷积。
对于基于 Channels MLP的模块,从基于深度卷积的模块输出的特征首先被馈送到a组归一化,然后在这些特征上实现Channels MLP。与空间MLP相比,Channels MLP不仅可以有效降低计算复杂性,而且可以满足一般视觉任务的要求。之后,依次实现通道缩放、下降路径和的剩余连接。上述过程表示为:
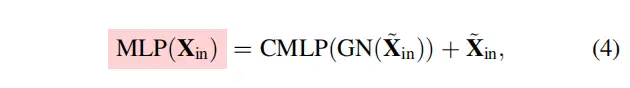
其中是Channels MLP。在论文中,为了表示方便,我们省略了等式3和等式4中的信道缩放和下降路径。
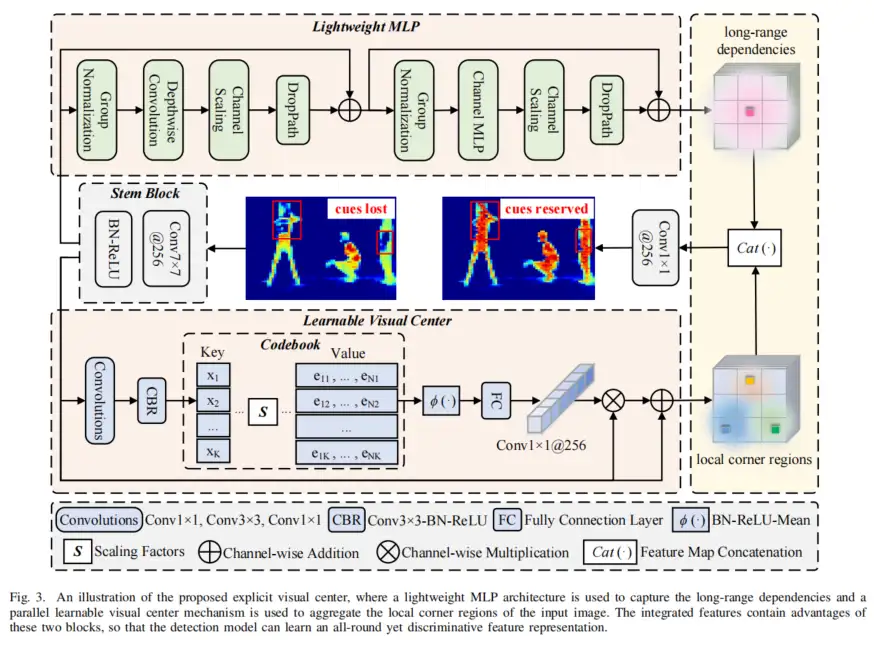
2、LCV
LVC是一种具有固有字典的编码器,具有2个组件:
- inherent Codebook:,其中是输入特征的总空间数量,其中和分别表示高度和宽度上的特征图空间大小;
- 可学习视觉中心的一组缩放因子$S={s_1,s_2,…,s_K}。
具体而言,来自Stem块的特征首先通过一组卷积层(由1×1卷积、3×3卷积和1×1卷积组成)的组合进行编码。
然后,编码特征由CBR块处理,CBR块由具有BN层的3×3卷积和ReLU激活函数组成。通过上述步骤,将编码的特征 输入到Codebook中。
为此,使用一组比例因子连续地使和映射相应的位置信息。关于第k个码字的整个图像的信息可以通过以下方式计算:
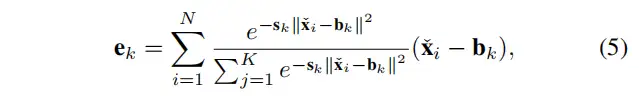
其中,是第个像素点,是第个可学习的视觉码字,是第缩放因子。是关于每个像素相对于码字的位置的信息。是视觉中心的总数。之后,使用来融合所有,其中包含具有ReLU和平均层的BN层。基于此,如下计算关于个码字的整个图像的完整信息。
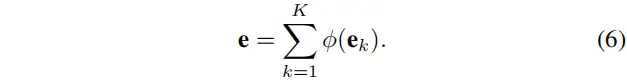
在获得码本的输出后,进一步将馈送到完全连接层和1×1卷积层,以预测突出关键类的特征。之后,使用Stem块的输入特征与缩放因子系数之间的通道乘法。上述过程表示为:
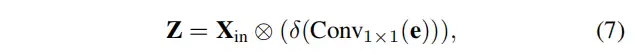
其中表示1×1卷积,是Sigmoid激活函数。是通道乘法。最后,在Stem块输出的特征n和局部区域特征之间执行逐通道相加,公式如下:
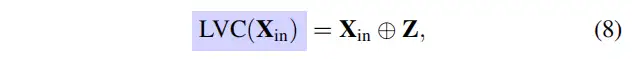
其中,是通道级的加法。
3.3、 Global Centralized Regulation (GCR)
EVC是一种广义的层内特征调节方法,它不仅可以提取全局长距离相关性,而且可以尽可能地保留输入图像的局部角区域信息,这对于密集预测任务非常重要。然而,在特征金字塔的每个级别使用EVC将导致较大的计算开销。
为了提高层内特征调节的计算效率,作者进一步以自顶向下的方式提出了特征金字塔的GCR。具体而言,如图2所示,考虑到最深的特征通常包含浅层特征中缺乏的最抽象的特征表示,空间EVC首先在特征金字塔的顶层(即)上实现。然后,所获得的包括空间显式视觉中心的特征X被用于同时调节所有的正面浅特征(即,到)。
在实现中,在每个对应的低层特征上,将在深层中获得的特征上采样到与低层特征相同的空间尺度,然后沿着通道维度连接。基于此,通过1×1卷积将级联特征下采样为256的通道大小。通过这种方式能够在自上而下的路径中显式地增加特征金字塔的每一层的全局表示的空间权重,从而CFP可以有效地实现全方位但有区别的特征表示。
4、实验
4.1、数据集和评估指标
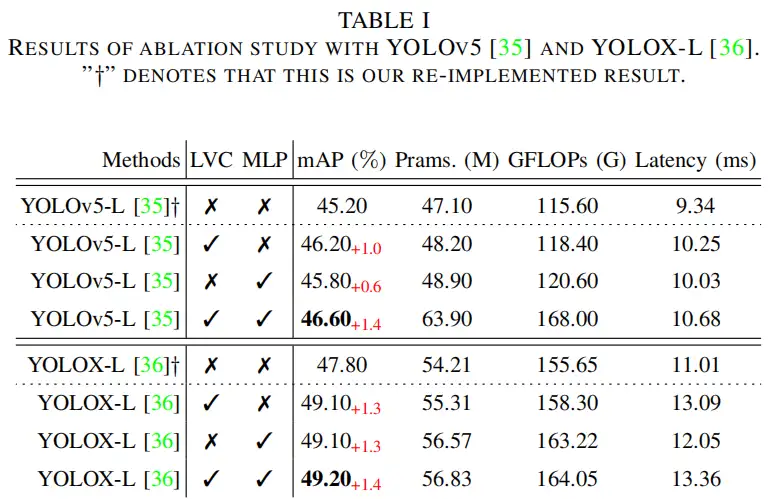
4.2、消融研究
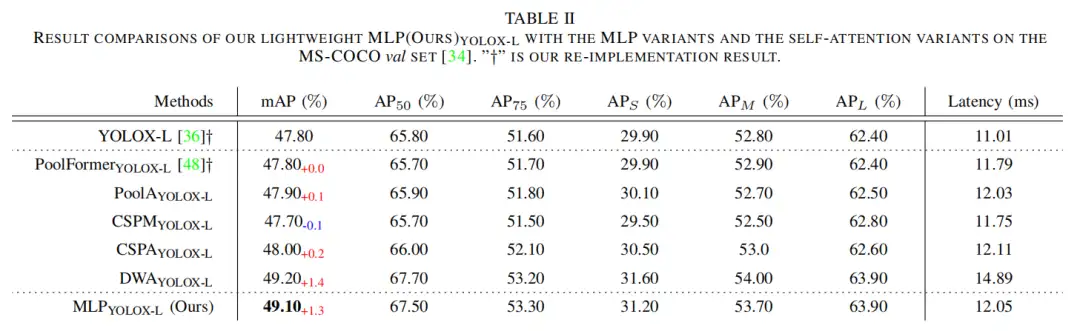
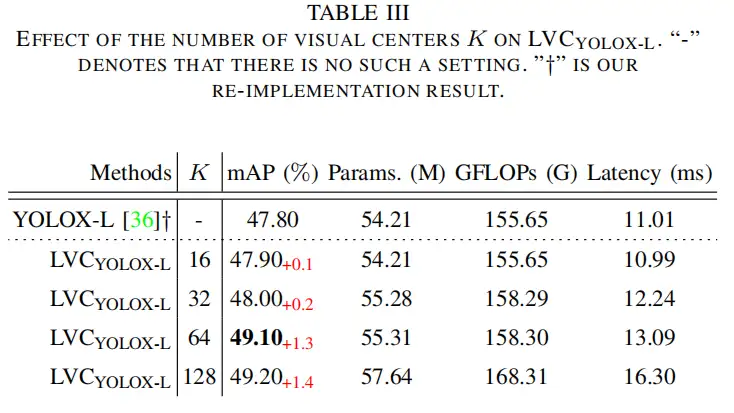
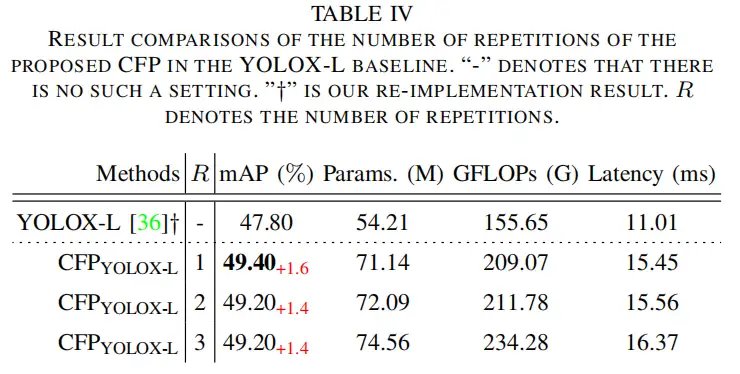
4.3、效率分析
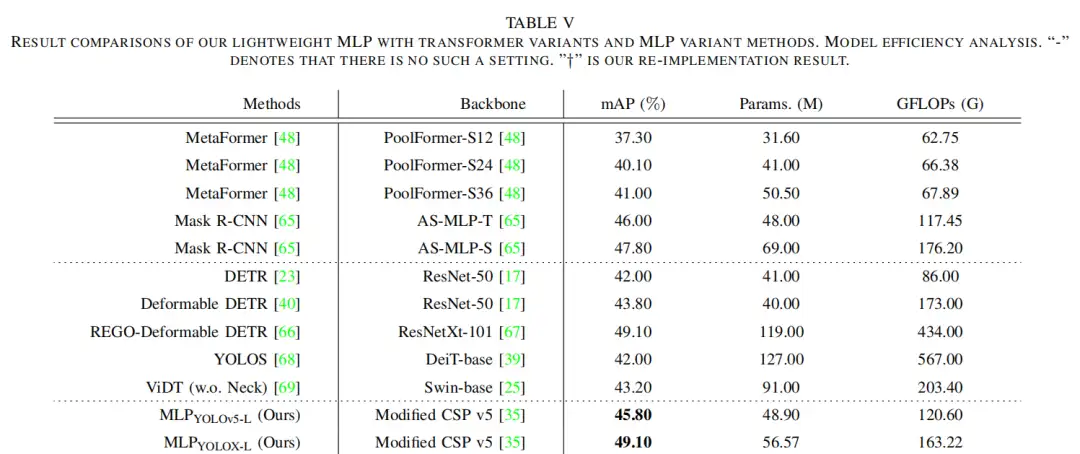
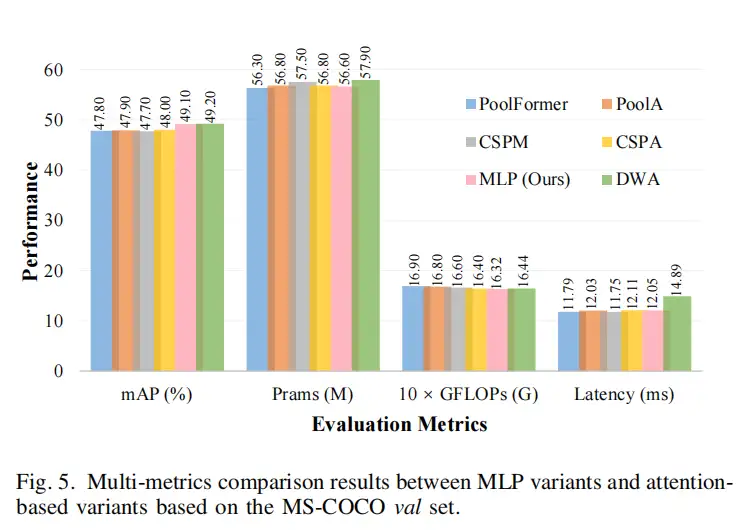
4.4、与最先进的方法的比较
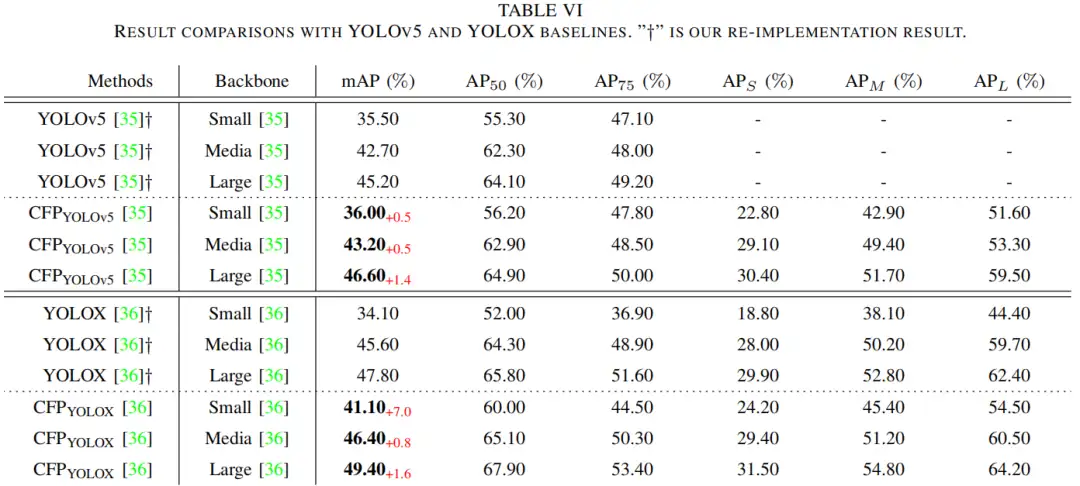

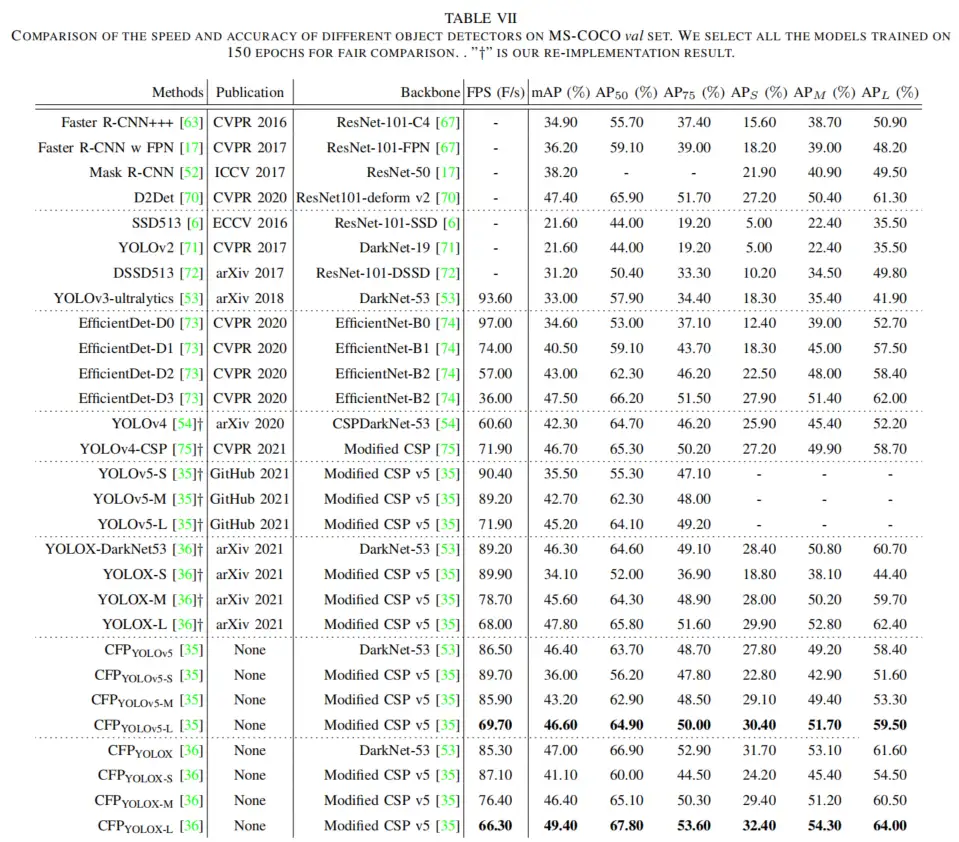
5、参考
[1].Centralized Feature Pyramid for Object Detection.
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
原来Transformer就是一种图神经网络,这个概念你清楚吗?
TensorFlow 真的要被 PyTorch 比下去了吗?
TensorRT教程(六)使用Python和C++部署YOLOv5的TensorRT模型
用于超大图像的训练策略:Patch Gradient Descent
CV小知识讨论与分析(5)到底什么是Latent Space?
CVPR 2023 Workshop | 首个大规模视频全景分割比赛
如何更好地应对下游小样本图像数据?不平衡数据集的建模的技巧和策
用少于256KB内存实现边缘训练,开销不到PyTorch千分之一


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· PowerShell开发游戏 · 打蜜蜂
· 在鹅厂做java开发是什么体验
· 百万级群聊的设计实践
· WPF到Web的无缝过渡:英雄联盟客户端的OpenSilver迁移实战
· 永远不要相信用户的输入:从 SQL 注入攻防看输入验证的重要性