
消费级显卡的春天,GTX 3090 YOLOv5s单卡完整训练COCO数据集缩短11.35个小时
前言 本文介绍了在单卡上凭借对YOLOv5的性能分析以及几个简单的优化将GTX 3090 FP32 YOLOv5s的训练速度提升了近20%。对于需要迭代300个Epoch的COCO数据集来说相比 ultralytics/yolov5 我们缩短了11.35个小时的训练时间。
本文转载自GiantPandaCV
作者 | BBuf
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
0x1. 结果展示
我们展示一下分别使用One-YOLOv5以及 ultralytics/yolov5 在GTX 3090单卡上使用YOLOv5s FP32模型训练COCO数据集一个Epoch所需的耗时:

可以看到在单卡模式下,经过我们的优化相比于 ultralytics/yolov5 的训练速度,我们提升了 20% 左右。
然后我们再展示一下2卡DDP模式YOLOv5s FP32模型训练COCO数据集一个Epoch所需的耗时:
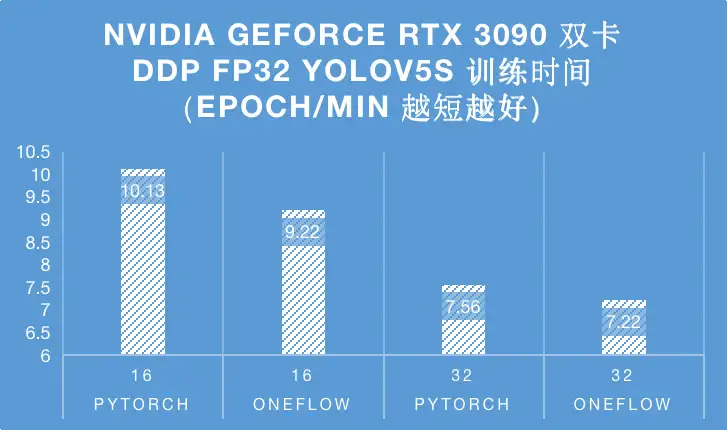
在DDP模式下的性能提升幅度没有单卡这么多,猜测可能是通信部分的开销比较大,后续我们会再研究一下。
0x2. 优化手段
我们在这一节完成技术揭秘。我们深度分析了PyTorch的YOLOv5的执行序列,我们发现当前YOLOv5主要存在3个优化点。第一个就是对于Upsample算子的改进,由于YOLOv5使用上采样是规整的最近邻2倍插值,所以我们可以实现一个特殊Kernel降低计算量并提升带宽。第二个就是在YOLOv5中存在一个滑动更新模型参数的操作,这个操作启动了很多碎的CUDA Kernel,而每个CUDA Kernel的执行时间都非常短,所以启动开销不能忽略。我们使用水平并行CUDA Kernel的方式(MultiTensor)对其完成了优化,基于这个优化One-YOLOv5获得了9%的加速。第三个优化点来源于对YOLOv5 nsys执行序列的观察,我们发现在ComputeLoss部分出现的bbox_iou是整个Loss计算部分一个比较大的瓶颈,我们在bbox_iou函数部分完成了多个垂直的Kernel Fuse,使得它的开销从最初的3.x ms降低到了几百个us。接下来我们分别详细阐述这几种优化:
0x2.1 对UpsampleNearest2D的特化改进
为了不写得啰嗦,我这里直接展示我们对UpsampleNearest2D进行调优的技术总结,大家可以结合下面的 pr 链接来对应下面的知识点总结。我们在A100 40G上测试 UpsampleNearest2D 算子的性能表现。这块卡的峰值带宽在1555Gb/s , 我们使用的CUDA版本为11.8。
进行 Profile 的程序如下:
import oneflow as flow
x = flow.randn(16, 32, 80, 80, device="cuda", dtype=flow.float32).requires_grad_()
m = flow.nn.Upsample(scale_factor=2.0, mode="nearest")
y = m(x)
print(y.device)
y.sum().backward()
https://github.com/Oneflow-Inc/oneflow/pull/9415 & https://github.com/Oneflow-Inc/oneflow/pull/9424 这两个 PR 分别针对 UpsampleNearest2D 这个算子(这个算子是 YOLO 系列算法大量使用的)的前后向进行了调优,下面展示了在 A100 上调优前后的带宽占用和计算时间比较:
| 框架 | 数据类型 | Op类型 | 带宽利用率 | 耗时 |
|---|---|---|---|---|
| PyTorch | Float32 | UpsampleNearest2D forward | 28.30% | 111.42us |
| PyTorch | Float32 | UpsampleNearest2D backward | 60.16% | 65.12us |
| OneFlow 未优化 | Float32 | UpsampleNearest2D forward | 12.54% | 265.82us |
| OneFlow 未优化 | Float32 | UpsampleNearest2D backward | 18.4% | 260.22us |
| OneFlow 优化后 | Float32 | UpsampleNearest2D forward | 52.18% | 61.44us |
| OneFlow 优化后 | Float32 | UpsampleNearest2D backward | 77.66% | 50.56us |
| PyTorch | Float16 | UpsampleNearest2D forward | 16.99% | 100.38us |
| PyTorch | Float16 | UpsampleNearest2D backward | 31.56% | 57.38us |
| OneFlow 未优化 | Float16 | UpsampleNearest2D forward | 7.07% | 262.82us |
| OneFlow 未优化 | Float16 | UpsampleNearest2D backward | 41.04% | 558.88us |
| OneFlow 优化后 | Float16 | UpsampleNearest2D forward | 43.26% | 35.36us |
| OneFlow 优化后 | Float16 | UpsampleNearest2D backward | 44.82% | 40.26us |
- 上述结果使用
/usr/local/cuda/bin/ncu -o torch_upsample /home/python3 debug.py得到profile文件后使用Nsight Compute打开记录。
基于上述对 UpsampleNearest2D 的优化,OneFlow 在 FP32 和 FP16 情况下的性能和带宽都大幅超越之前未经优化的版本,并且相比于 PyTorch 也有较大幅度的领先。
本次优化涉及到的 知识点总结 如下(by OneFlow 柳俊丞):
- 为常见的情况写特例,比如这里就是为采样倍数为2的Nearest插值写特例,避免使用NdIndexHelper带来的额外计算开销,不用追求再一个kernel实现中同时拥有通用型和高效性;
- 整数除法开销大(但是编译器有的时候会优化掉一些除法),nchw中的nc不需要分开,合并在一起计算减少计算量;
- int64_t 除法的开销更大,用int32满足大部分需求,其实这里还有一个快速整数除法的问题;
- 反向 Kernel 计算过程中循环 dx 相比 循环 dy ,实际上将坐标换算的开销减少到原来的 1/4;
- CUDA GMEM 的开销的也比较大,虽然编译器有可能做优化,但是显式的使用局部变量更好;
- 一次 Memset 的开销也很大,和写一次一样,所以反向 Kernel 中对 dx 使用Memset 清零的时机需要注意;
- atomicAdd 开销很大,即使抛开为了实现原子性可能需要的锁总线等,atomicAdd 需要把原来的值先读出来,再写回去;另外,half的atomicAdd 巨慢无比,慢到如果一个算法需要用到 atomicAdd,那么相比于用 half ,转成 float ,再atomicAdd,再转回去还要慢很多;
- 向量化访存;
对这个 Kernel 进行特化是优化的第一步,基于这个优化可以给 YOLOv5 的单卡 PipLine 带来1%的提升。
0x2.2 对bbox_iou函数进行优化 (垂直Fuse优化)
通过对nsys的分析,我们发现无论是one-yolov5还是ultralytics/yolov5,在计算Loss的阶段都有一个耗时比较严重的bbox_iou函数,我们这里先贴一下bbox_iou部分的代码:
def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7):
# Returns Intersection over Union (IoU) of box1(1,4) to box2(n,4)
# Get the coordinates of bounding boxes
if xywh: # transform from xywh to xyxy
(x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)
w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2
b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_
b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_
else: # x1, y1, x2, y2 = box1
b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)
b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)
w1, h1 = b1_x2 - b1_x1, (b1_y2 - b1_y1).clamp(eps)
w2, h2 = b2_x2 - b2_x1, (b2_y2 - b2_y1).clamp(eps)
# Intersection area
inter = (b1_x2.minimum(b2_x2) - b1_x1.maximum(b2_x1)).clamp(0) * \
(b1_y2.minimum(b2_y2) - b1_y1.maximum(b2_y1)).clamp(0)
# Union Area
union = w1 * h1 + w2 * h2 - inter + eps
# IoU
iou = inter / union
if CIoU or DIoU or GIoU:
cw = b1_x2.maximum(b2_x2) - b1_x1.minimum(b2_x1) # convex (smallest enclosing box) width
ch = b1_y2.maximum(b2_y2) - b1_y1.minimum(b2_y1) # convex height
if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 + (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center dist ** 2
if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
v = (4 / math.pi ** 2) * (torch.atan(w2 / h2) - torch.atan(w1 / h1)).pow(2)
with torch.no_grad():
alpha = v / (v - iou + (1 + eps))
return iou - (rho2 / c2 + v * alpha) # CIoU
return iou - rho2 / c2 # DIoU
c_area = cw * ch + eps # convex area
return iou - (c_area - union) / c_area # GIoU https://arxiv.org/pdf/1902.09630.pdf
return iou # IoU
以one-yolov5的原始执行序列图为例,我们发现bbox_iou函数这部分每一次运行都需要花2.6ms左右。并且我们可以看到这里有大量的小的Kernel被调度,虽然每个小Kernel计算很快,但访问Global Memory以及多次Kernel Launch的开销也是比较大的,所以我们做了几个fuse来降低Kernel Launch的开销以及减少访问Global Memrory来提升带宽。
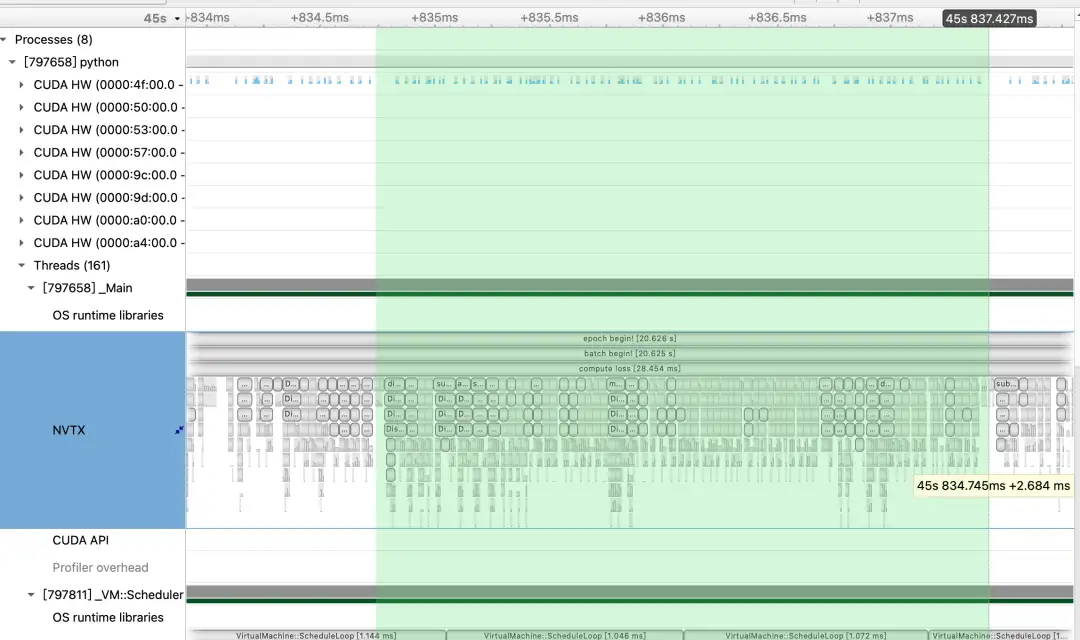
然后经过我们的Kernel Fuse之后的耗时只需要600+us。
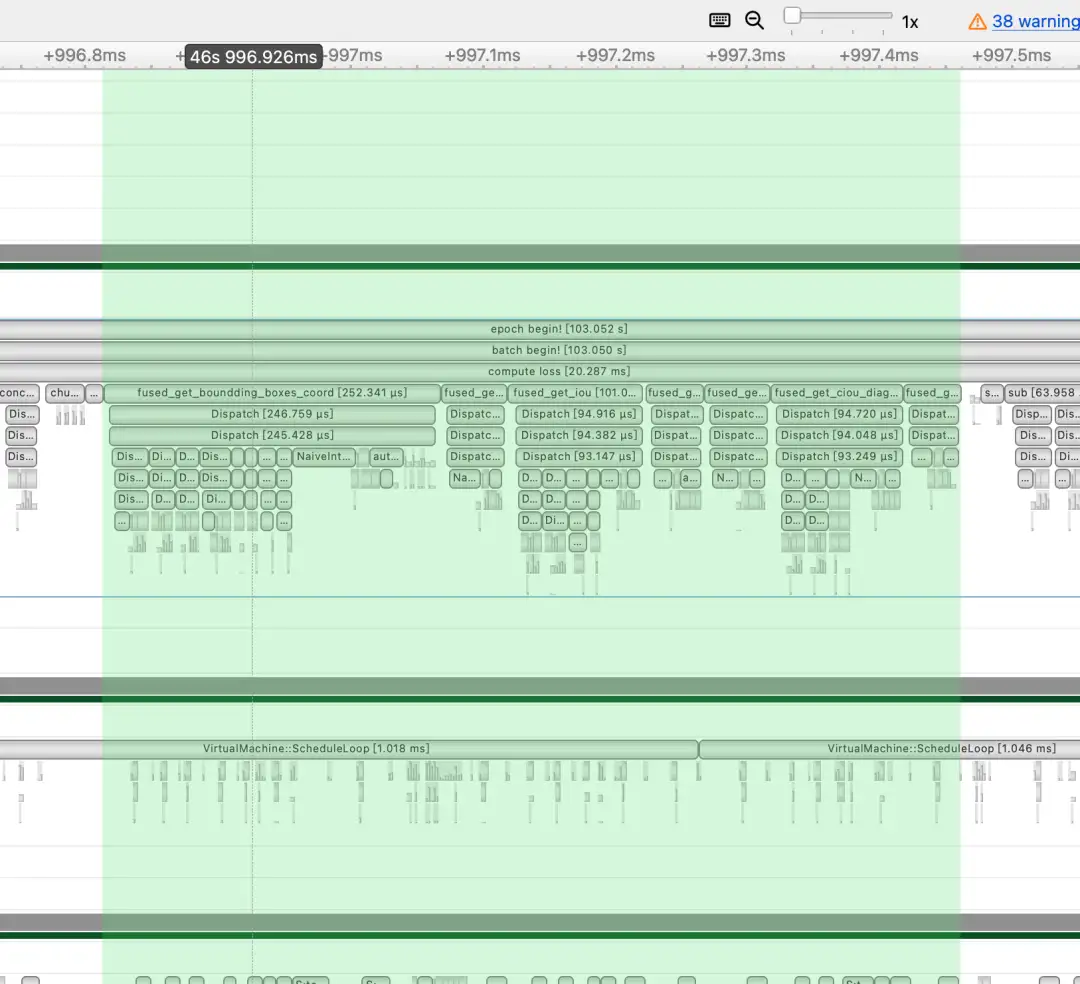
具体来说我们这里做了如下的几个fuse:
- fused_get_boundding_boxes_coord:https://github.com/Oneflow-Inc/oneflow/pull/9433
- fused_get_intersection_area: https://github.com/Oneflow-Inc/oneflow/pull/9485
- fused_get_iou: https://github.com/Oneflow-Inc/oneflow/pull/9475
- fused_get_convex_diagonal_squared: https://github.com/Oneflow-Inc/oneflow/pull/9481
- fused_get_center_dist: https://github.com/Oneflow-Inc/oneflow/pull/9446
- fused_get_ciou_diagonal_angle: https://github.com/Oneflow-Inc/oneflow/pull/9465
- fused_get_ciou_result: https://github.com/Oneflow-Inc/oneflow/pull/9462
然后我们在one-yolov5的train.py中扩展了一个 --bbox_iou_optim 选项,只要训练的时候带上这个选项就会自动调用上面的fuse kernel来对bbox_iou函数进行优化了,具体请看:https://github.com/Oneflow-Inc/one-yolov5/blob/main/utils/metrics.py#L224-L284 。对bbox_iou这个函数的一系列垂直Fuse优化使得YOLOv5整体的训练速度提升了8%左右,是一个十分有效的优化。
0x2.3 对模型滑动平均更新进行优化(水平Fuse优化)
在 YOLOv5 中会使用EMA(指数移动平均)对模型的参数做平均, 一种给予近期数据更高权重的平均方法, 以求提高测试指标并增加模型鲁棒。这里的核心操作如下代码所示:
def update(self, model):
# Update EMA parameters
self.updates += 1
d = self.decay(self.updates)
msd = de_parallel(model).state_dict() # model state_dict
for k, v in self.ema.state_dict().items():
if v.dtype.is_floating_point: # true for FP16 and FP32
v *= d
v += (1 - d) * msd[k].detach()
# assert v.dtype == msd[k].dtype == flow.float32, f'{k}: EMA {v.dtype} and model {msd[k].dtype} must be FP32'
以下是未优化前的这个函数的时序图:
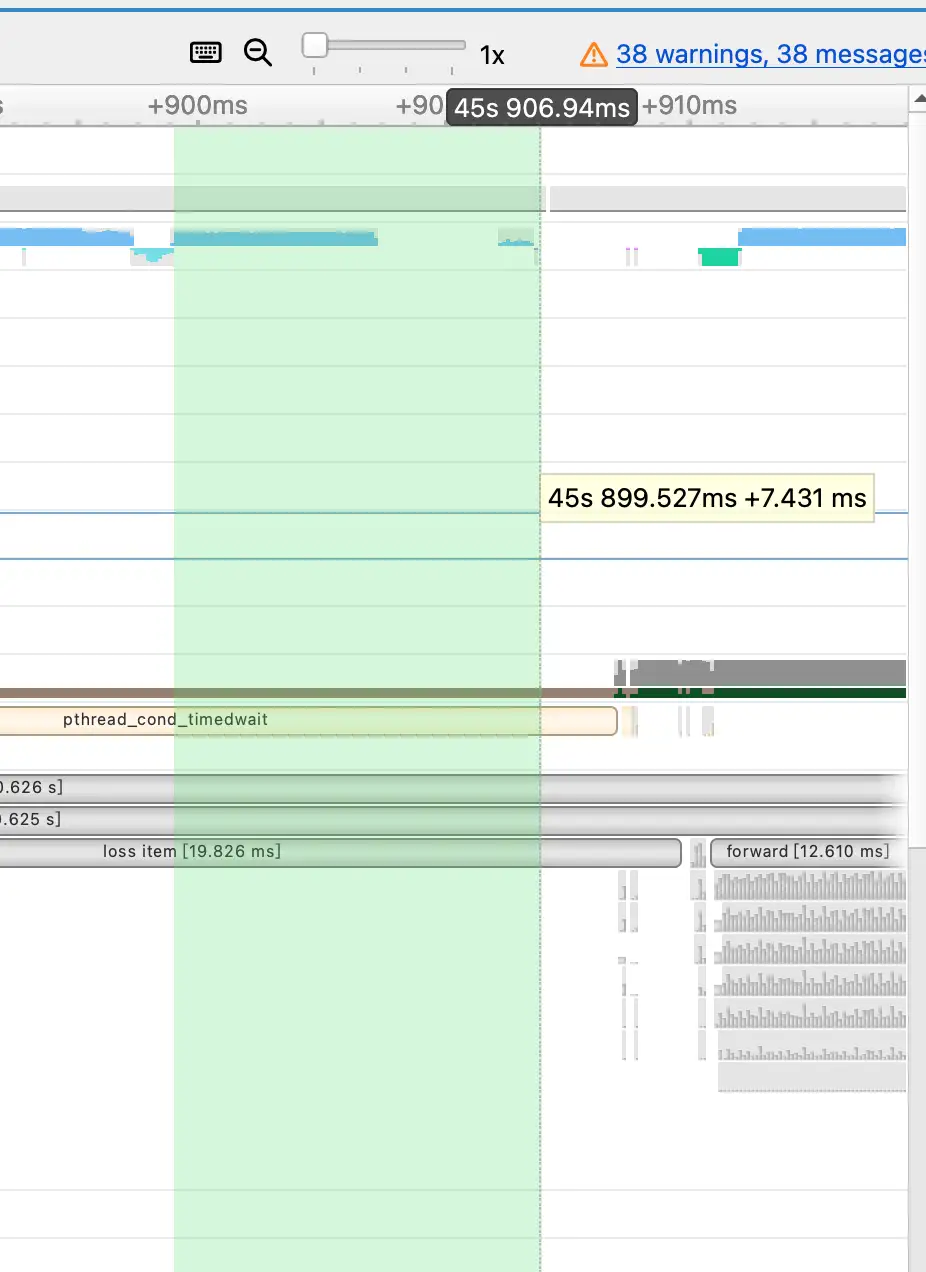
这部分的cuda kernel的执行速度大概为7.4ms,而经过我们水平Fuse优化(即MultiTensor),这部分的耗时情况降低为了127us。
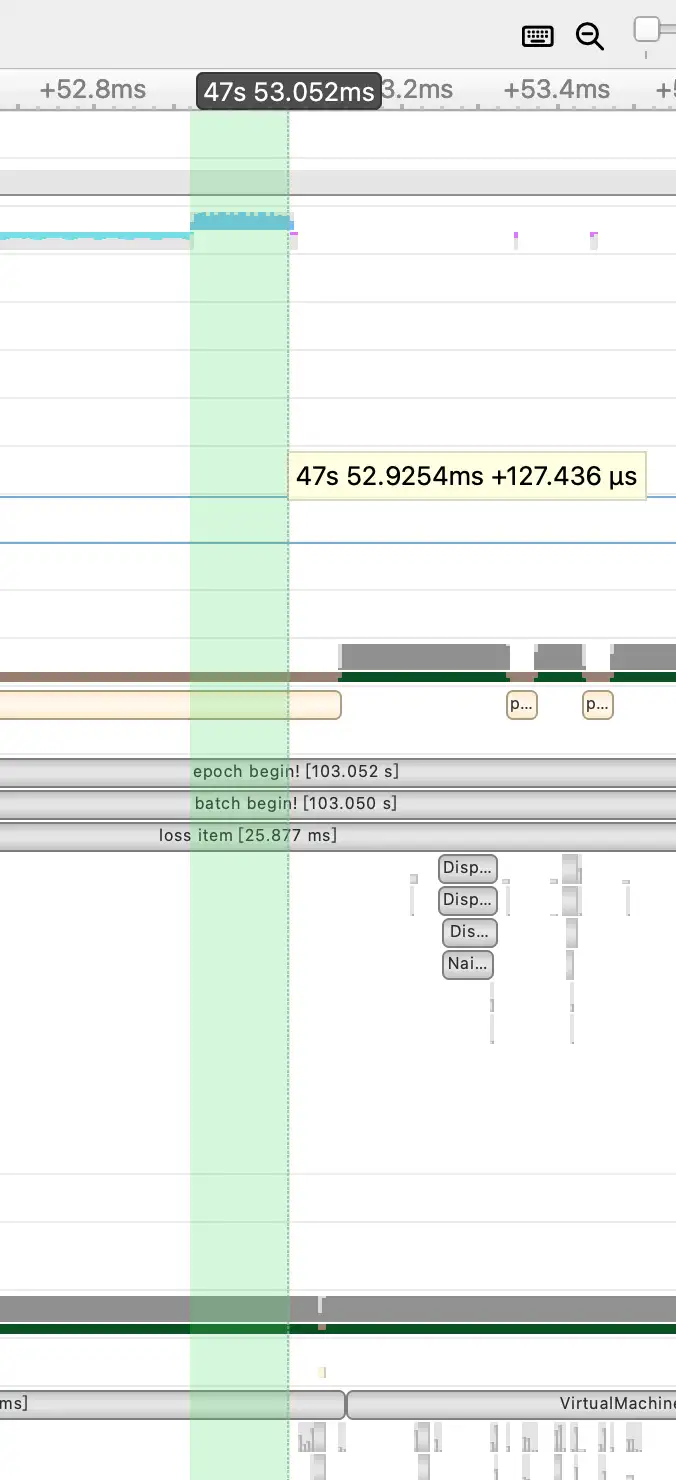
并且水平方向的Kernel Fuse也同样降低了Kernel Launch的开销,使得前后2个Iter的间隙也进一步缩短了。最终这个优化为YOLOv5的整体训练速度提升了10%左右。本优化实现的pr如下:https://github.com/Oneflow-Inc/oneflow/pull/9498
此外,对于Optimizer部分同样可以水平并行,所以我们在 one-yolov5 里面设置了一个multi_tensor_optimizer标志,打开这个标志就可以让 optimizer 以及 EMA 的 update以水平并行的方式运行了。
关于MultiTensor这个知识可以看 zzk 的这篇文章:https://zhuanlan.zhihu.com/p/566595789。zzk 在 OneFlow 中也实现了一套 MultiTensor 方案,上面的 PR 9498 也是基于这套 MultiTensor 方案实现的。介于篇幅原因我们就不展开这个 MultiTensor 的代码实现了,感兴趣的可以留言后续单独讲解。
0x3. 使用方法
上面已经提到所有的优化都集中于 bbox_iou_optim 和 multi_tensor_optimizer 这两个扩展的Flag,只要我们训练的时候打开这两个Flag就可以享受到上述优化了。其他的运行命令和One-YOLOv5没有变化,以One-YOLOv5在GTX 3090上训练yolov5s为例,命令为:
python train.py --batch 16 --cfg models/yolov5s.yaml --weights '' --data coco.yaml --img 640 --device 0 --epoch 1 --bbox_iou_optim --multi_tensor_optimizer
0x4. 总结
目前,yolov5s网络当以BatchSize=16的配置在GeForce RTX 3090上(这里指定BatchSize为16时)训练COCO数据集时,OneFlow相比PyTorch可以节省 11.35 个小时。我们相信这篇文章提到的优化技巧也可以对更多的从事目标检测的学生或者工程师带来启发。欢迎大家star one-yolov5项目:https://github.com/Oneflow-Inc/one-yolov5
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
原来Transformer就是一种图神经网络,这个概念你清楚吗?
TensorFlow 真的要被 PyTorch 比下去了吗?
TensorRT教程(六)使用Python和C++部署YOLOv5的TensorRT模型
用于超大图像的训练策略:Patch Gradient Descent
CV小知识讨论与分析(5)到底什么是Latent Space?
CVPR 2023 Workshop | 首个大规模视频全景分割比赛
如何更好地应对下游小样本图像数据?不平衡数据集的建模的技巧和策

 浙公网安备 33010602011771号
浙公网安备 33010602011771号