一层卷积能做啥?BOE告诉你:一层卷积可以做超分!
前言 本文是京东方团队关于端侧超分的深度思考,以端侧设备超分为切入点,对经典上采样与深度学习超分之间的“空白”地带进行思考,提出了一类“一层”超分架构,并对所提方案与其他轻量型超分方案以及bicubic从不同角度进行了对比,同时也为未来端侧超分算法的设计提供了一个极具价值的参考点。
本文转载自AIWalker
作者 | Happy
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。

arXiv: https://arxiv.org/pdf/2108.10335.pdf
Abstract
经典的图像缩放(比如bicubic)可以视作一个卷积层+一个上采样滤波器,它在所有显示设备与图像处理软件中是普遍存在的。
在过去的十年里,深度学习技术已被成功应用到图像超分任务上,它们往往由多个卷积与大量滤波器构成。深度学习方法已成功占据了图像上采样任务的质量基准。深度学习方法能否在端侧设备(比如显示屏、平板电脑以及笔记本电脑)上取代经典上采样技术吗 ?一方面,随着能高效运行深度学习任务的硬件的迅速发展,AI芯片发展趋势呈现出了非常好的前景;另一方面,只有少数SR架构能够在端侧设备上实时处理非常小尺寸图像。
我们对该问题的可能方案进行了探索以期弥补经典上采样与轻量深度学习超分之间的空白。作为从经典到深度学习上采样之间的过渡,我们提出了edge-SR(eSR):一层架构,它采用可解释机制进行图像上采样。当然,一层架构无法达到与深度学习方法的性能,但是,对于高速度需求来说,eSR具有更好的图像质量-推理速度均衡。弥补经典与深度学习上采样之间的空白对于大量采用该技术非常重要。
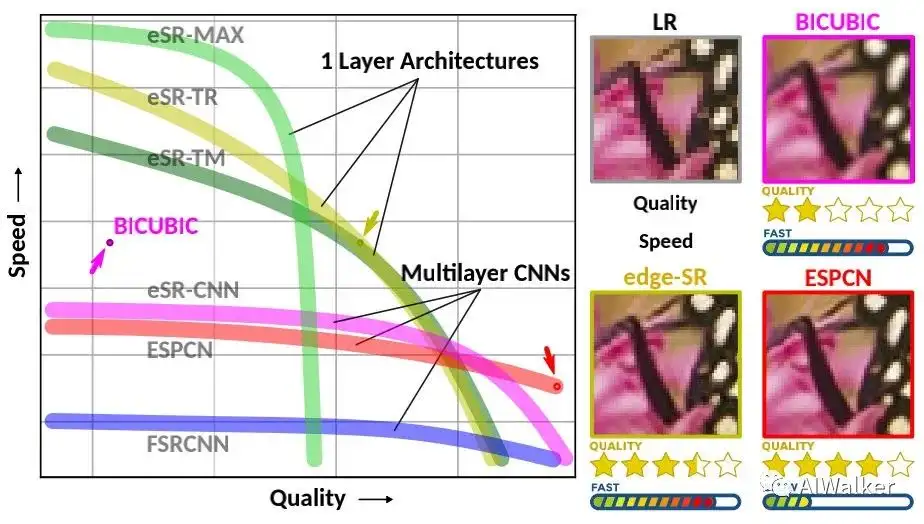
本文贡献包含以下几点:
- 提出了几种一层架构以弥补经典与深度学习上采样之间的空白;
- 在1185中深度学习架构中进行了穷举搜索,可参考上图,不同的架构具有不同的性能-速度均衡。
- 对一层自注意力架构进行了可解释分析,对自注意力机制提供了一种新的解释。
上述结果可能会带来以下影响:
- 图像超分系统有可能大量应用到端侧设备;
- 对小网络的内部学习机制有更好的理解;
- 对未来应用于研究了一个更好的性能-耗时均衡参考。
Super-Resolution for Edge Devices
Classical 图像上采样与下采样指的是LR与HR之间的转换。最简单的下采样有pooling、downsample。downsample一半是在水平和垂直方向进行均匀的像素丢弃,这种处理会导致高频信息丢失,导致Alisaing问题。为解决该问题,经典的线性下采样首先采用anti-aliasing低通滤波器移除高频,然后再下采样。现有深度学习框架中采用stride convolution实现。线性上采样则与之相反,下图给出了实现可视化图,即先上采样后滤波 。
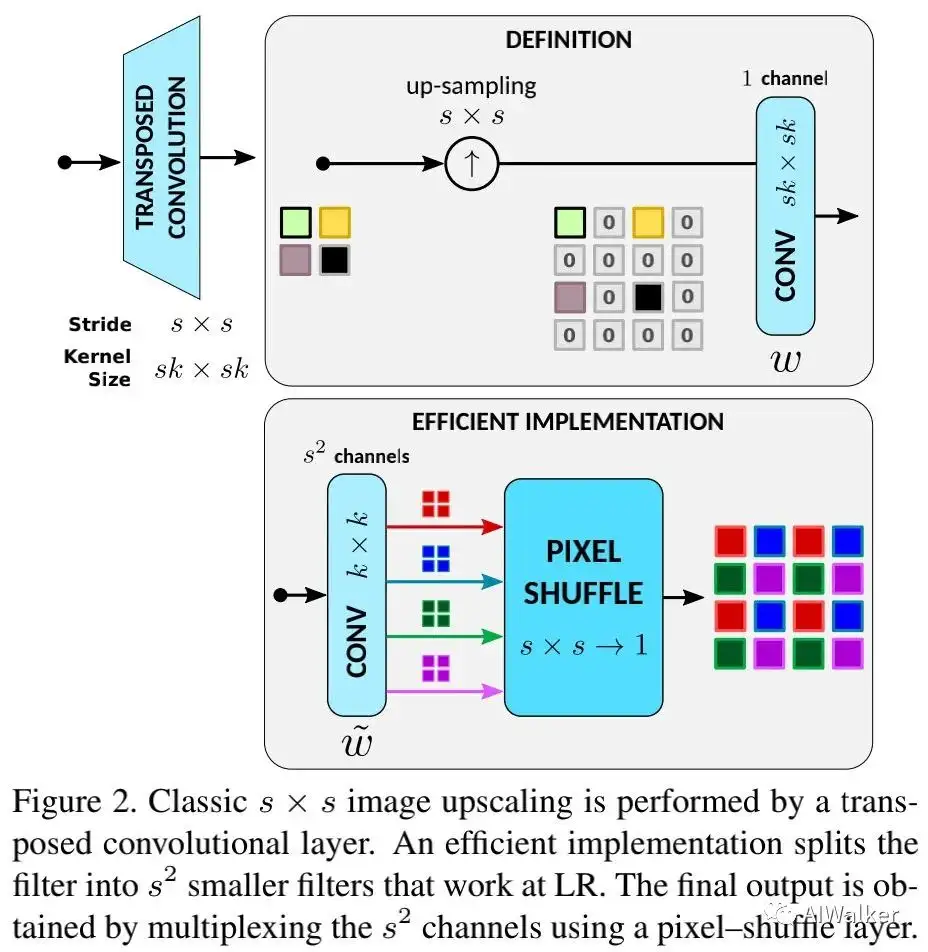
由于引入过多零,造成大量的资源浪费,上图中的定义实现非常低效。本文提出了一种高效实现,见上图下部分,即先滤波再pixelshuffle。注:作者采用标准bicubi插值滤波器系数进行验证,两者具有完全相同的结果。
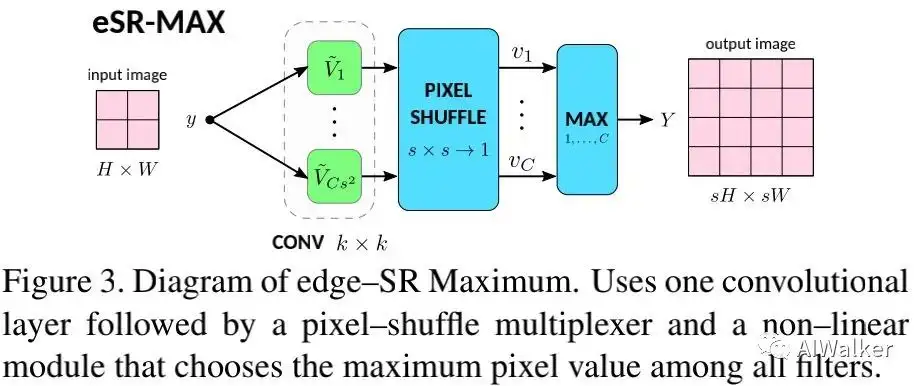
Maxout 本文提出的首个一层网络为edge-SR Maximum(eSR-MAX),见下图。
class edgeSR_MAX(nn.Module):
def __init__(self, C, k, s):
super().__init__()
self.pixel_shuffle = nn.PixelShuffle(s)
self.filter = nn.Conv2d(1,s*s*C,k,1,(k-1)//2,bias=False)
def forward(self, x):
return self.pixel_shuffle(self.filter(x)).max(dim=1, keepdim=True)[0]
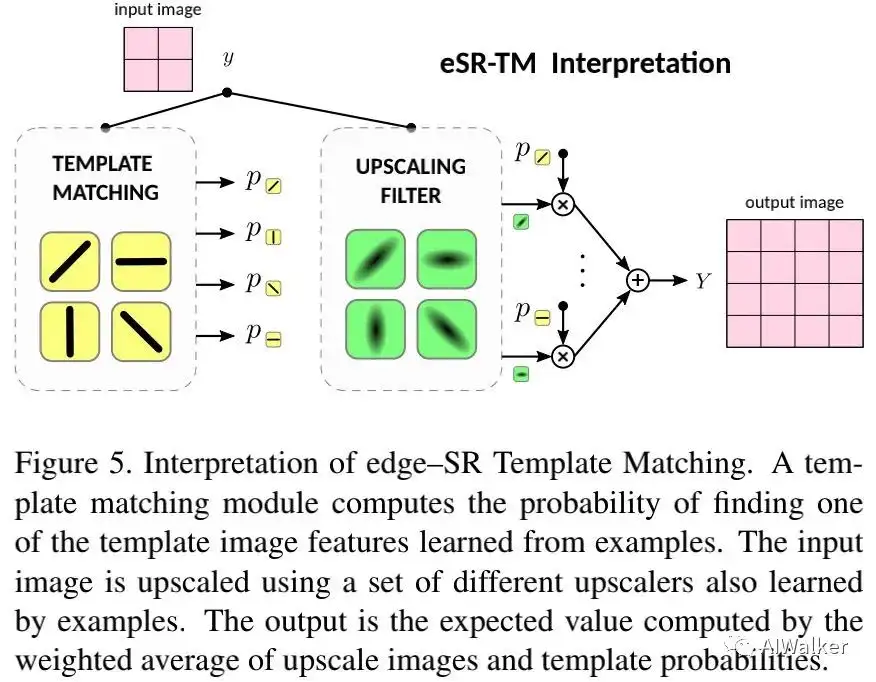
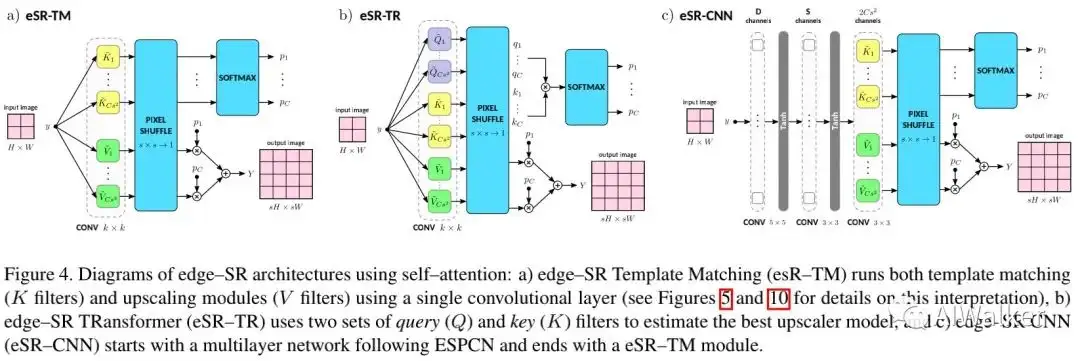
Self-Attention 本文提出的第二个一层网络为edge-SR Template Matching(eSR-TM)。下图给出了该方案的解释示意图,它利用了模板匹配的思想。
class edgeSR_TM(nn.Module):
def __init__(self, C, k, s):
super().__init__()
self.pixel_shuffle = nn.PixelShuffle(s)
self.softmax = nn.Softmax(dim=1)
self.filter = nn.Conv2d(1,2*s*s*C,k,1,(k-1)//2,bias=False)
def forward(self, x):
filtered = self.pixel_shuffle(self.filter(x)
B,C,H,W = filtered.shape
filtered = filtered.view(B,2,C,H,W)
upscaling= filtered[:,0]
matching = filtered[:,1]
return torch.sum(upscaling * self.softmax(matching), dim=1, keepdim=True)
Transformer 本文提出的第三种方案是edge-SR TRansformer(eSR-TR),见下图,它采用了Transformer的自注意力机制,某种程度上时eSR-TM的简化。
class edgeSR_TR(nn.Module):
def __init__(self, C, k, s):
self.pixel_shuffle = nn.PixelShuffle(s)
self.softmax = nn.Softmax(dim=1)
self.filter = nn.Conv2d(1,3*s*s*C,k,1,(k-1)//2,bias=False)
def forward(self, x):
filtered = self.pixel_shuffle(self.filter(x))
B,C,H,W = filtered.shape
filtered = filtered.view(B,3,C,H,W)
value = filtered[:,0]
query = filtered[:,1]
key = filtered[:,2]
return torch.sum(value*self.softmax(query*key),dim=1,keepdim=True)
edge-SR CNN 此外本文还提出了edge-SR CNN(eSR-CNN),见上图c。下图给出了所提几种方案的算法实现。

class edgeSR_CNN(nn.Module):
def __init__(self, C, D, S, s):
super().__init__()
self.softmax = nn.Softmax(dim=1)
if D == 0:
self.filter = nn.Sequential(
nn.Conv2d(D, S, 3, 1, 1),
nn.Tanh(),
nn.Conv2d(S,2*s*s*C,3,1,1,bias=False),
nn.PixelShuffle(s))
else:
self.filter = nn.Sequential(
nn.Conv2d(1, D, 5, 1, 2),
nn.Tanh(),
nn.Conv2d(D, S, 3, 1, 1),
nn.Tanh(),
nn.Conv2d(S,2*s*s*C,3,1,1,bias=False),
nn.PixelShuffle(s))
def forward(self, input):
filtered = self.filter(input)
B, C, H, W = filtered.shape
filtered = filtered.view(B, 2, C, H, W)
upscaling = filtered[:, 0]
matching = filtered[:, 1]
return torch.sum(upscaling * self.softmax(matching), dim=1, keepdim=True)
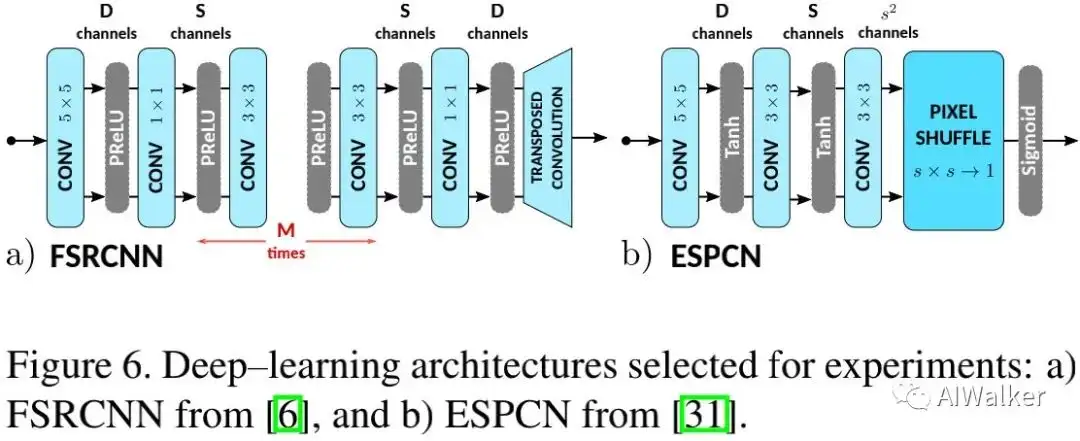
Deep-Learning 作为对标,本文以FSRCNN、ESPCN为候选,结构见下图。两者的区别有两点:激活函数、上采样方式。
Experiments

上图所构建的1185超分模型池,训练数据采用General100与T91进行,模型的输入为1通道灰度图像。整个训练过程花费了两个月时间@Tesla M40GPUX7。为测试最终模型,主要考虑了两种推理设备:
- Nvidia Jetson AGX Xavier:Nvidia公司的嵌入式GPU设备,功耗30Watt;
- Raspberry Pi 400:树莓派CPU处理器,功耗15Watt。
测试过程中,每个模型的输出为14个Full-HD图像,测试集源自DIV2K。推理过程采用FP16推理。图像质量评价则采用了Set5、Set14、BSDS100、Urban100以及Manga109等基准数据集。
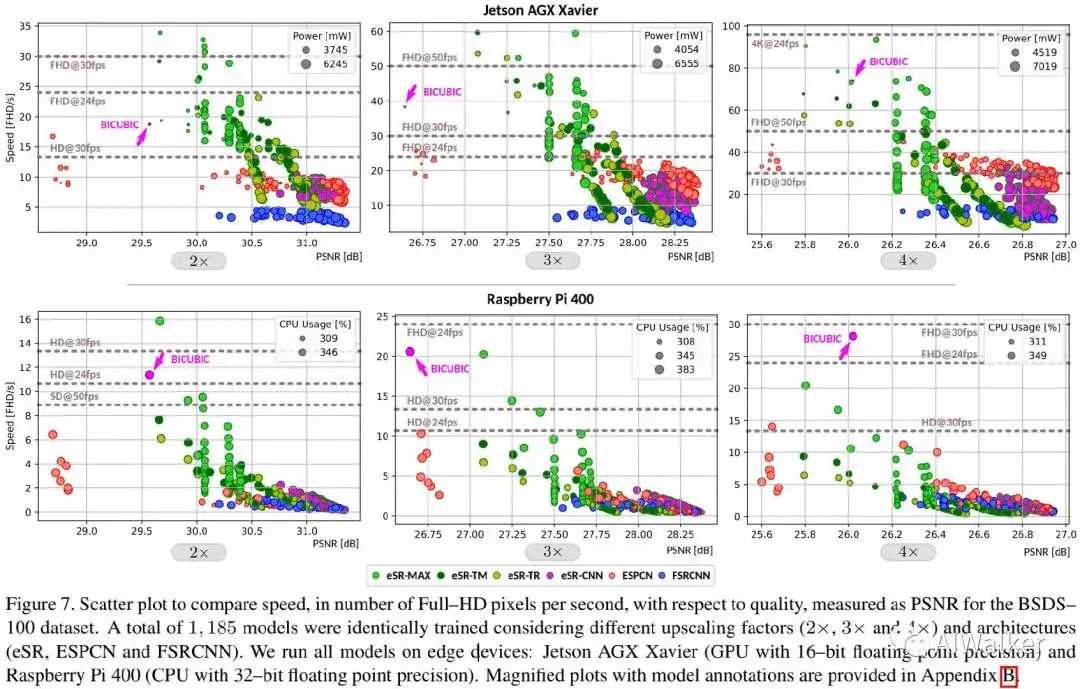
上图对比了不同方案的性能-速度,以bicubic作为基准,从中可以看拿到:
- 在端侧GPU设备上,所提edge-SR成功弥补了经典上采样与深度学习超分之间的空白,同时具有比bicubic上采样更好的速度-质量均衡;
- 在树莓派CPU设备上,edge-SR弥补了x2与x3倍率下的空白,但x4任务上bicubic上采样具有更佳的性能。
- 深度学习方案更擅长于提升图像质量,如ESPCN在高质量范围具有最快速度;
- eSR-CNN并未提升ESPCN质量,但提升了其速度;
- eSR-MAX具有最快速度,但质量不稳定;
- eSR-TM与eSR-TR在中等速度-质量方面具有最佳性能。
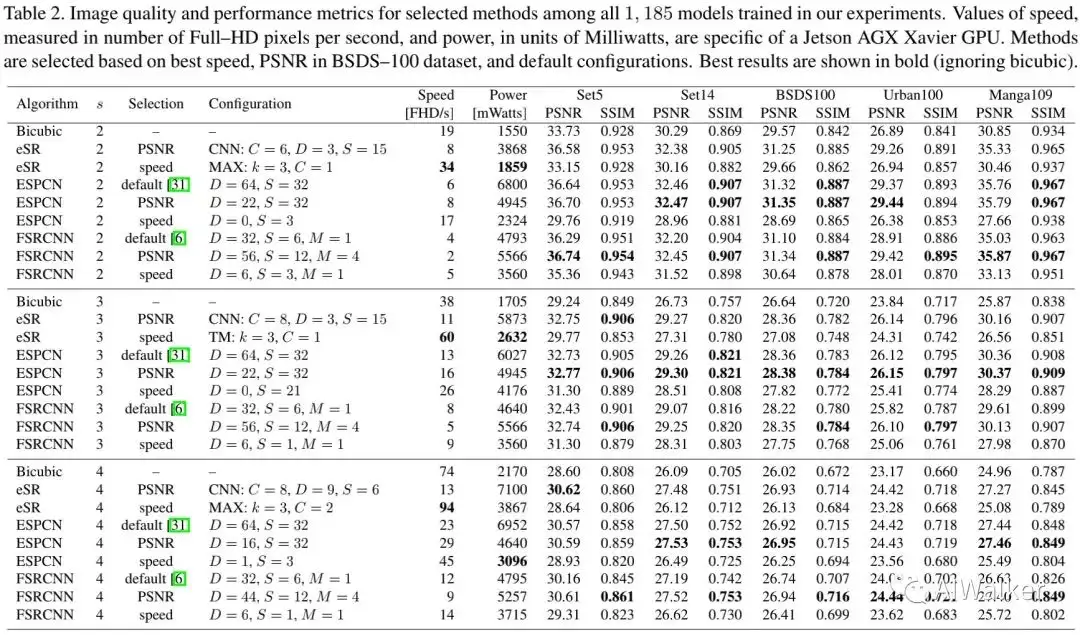
上表给出了不同方案的性能,可以看到:eSR方案取得了最佳速度、最低功耗 ,同时具有比bicubic上采样更好的图像质量。
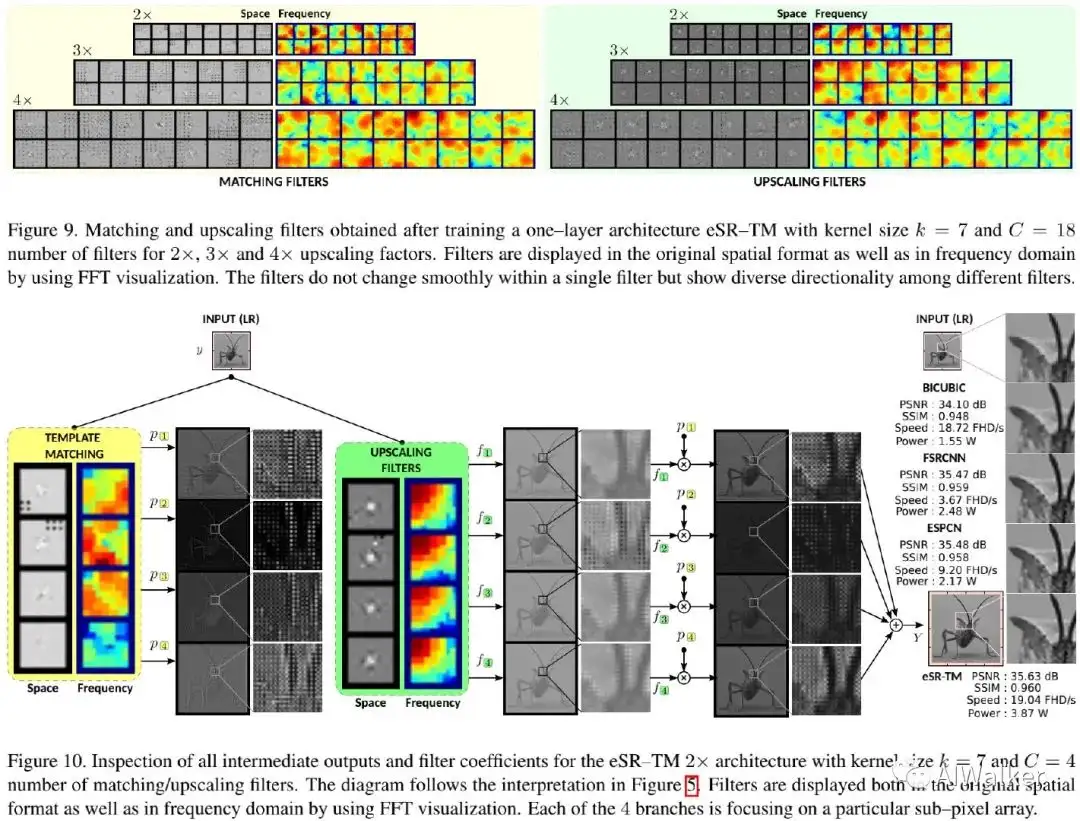
上述两个图对eSR-TM与eSR-TR进行了可视化解释,从中可以看到:
- 对于eSR-TM而言,不同滤波器处理不同频率带;尽管滤波器不平滑,但具有一定程度的方向辨别能力;
- 对于eSR-TR而言,matching与上采样滤波器同样不平滑,但有一定的方向性。
个人反思
视频类low-level算法想落地到端侧,尤其是要求高分辨率+实时推理 时,难度真的非常大,谁做谁知道。性能好的模型,速度完全跟不上;但是要速度快吧,性能又不突出,视频low-level算法真的适合用AI吗 ?
京东方的研究员脑洞实在太大了,不去关注性能,转而去关注bicubic插值与深度学习超分方案在性能-速度均衡之间的那块“空白区域”,进而提出了“脑洞”更大的一层超分模型!一层能干啥?在看到该文之前,真是想都不敢想。
就算是一层模型,京东方的研究员也是玩出了花样,又是Maxout,又是模板匹配、又是Transformer,真是大写的 !
比较可惜的是这篇文章并未开源,虽然复现很简单,但作为“拿来主义”的我,有训练好的谁还去重新训练呢,对吧...
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
原来Transformer就是一种图神经网络,这个概念你清楚吗?
TensorFlow 真的要被 PyTorch 比下去了吗?
TensorRT教程(六)使用Python和C++部署YOLOv5的TensorRT模型
用于超大图像的训练策略:Patch Gradient Descent
CV小知识讨论与分析(5)到底什么是Latent Space?
CVPR 2023 Workshop | 首个大规模视频全景分割比赛
如何更好地应对下游小样本图像数据?不平衡数据集的建模的技巧和策
用少于256KB内存实现边缘训练,开销不到PyTorch千分之一

 浙公网安备 33010602011771号
浙公网安备 33010602011771号