
顶刊TPAMI 2023!Food2K:大规模食品图像识别
前言 美团基础研发平台视觉智能部与中科院计算所展开科研课题合作,共同构建大规模数据集Food2K,并提出渐进式区域增强网络用于食品图像识别,相关研究成果已发表于T-PAMI 2023。
本文主要介绍了数据集特点、方法设计、性能对比,以及基于该数据集的迁移实验等方面的内容,并对Food2K未来的工作进行了展望。希望本文能为从事相关工作的同学带来一些帮助或者启发。
来源 | 美团技术团队
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
- 1 引言
- 2 Food2K数据集
- 3 方法
- 全局-局部特征学习
- 区域特征增强
- 训练和预测
- 4 实验
- 方法验证与分析
- 基于Food2K的泛化实验
- 5 未来工作
- 6 总结及展望
- 7 参考文献
- 8 本文作者
1 引言
视觉智能部与中科院计算所于2020-2021年度展开了《细粒度菜品图像识别和检索》科研课题合作,本文系双方联合在IEEE T-PAMI2023发布论文《Large Scale Visual Food Recognition》 (Weiqing Min, Zhiling Wang, Yuxin Liu, Mengjiang Luo, Liping Kang, Xiaoming Wei, Xiaolin Wei, Shuqiang Jiang*) 的解读。IEEE T-PAMI全称为IEEE Transactions on Pattern Analysis and Machine Intelligence,是模式识别、计算机视觉及机器学习领域的国际顶级期刊,2022年公布的影响因子为24.314。

图1 Food2K数据集
食品计算[1]因能够支撑许多食品相关的应用得到越来越广泛的关注。食品图像识别作为食品计算的一项基本任务,在人们通过辨认食物进而满足他们生活需求方面发挥着重要作用,如食品营养理解[2,3]和饮食管理[4]等。此外,食品图像识别是细粒度视觉识别的一个重要分支,具有重要的理论研究意义。
现有的工作主要是利用中小规模的图像数据集进行食品图像识别,如ETH Food-101[5]、Vireo Food-172[6]和ISIA Food- 500[7],但是它们的数据规模不足以支撑更复杂更先进的食品计算模型的建立。考虑到大规模数据集已成为许多常规图像分类和理解任务发展的关键推动因素,食品计算领域也迫切需要一个大规模的食品图像数据集来进一步支撑各种食品计算任务,如跨模态食谱检索和生成[8,9]。因此我们构建了一个新的大规模基准数据集Food2K。该数据集包含1,036,564张食品图像和2,000类食品,涉及12个超类(如蔬菜、肉类、烧烤和油炸食品等)和26个子类别。与现有的数据集相比,Food2K在类别和图像数量均超过其一个数量级。除了规模之外,我们还进行了严格的数据清理、迭代标注和多项专业检查,以保证其数据的质量。
在此基础上,我们进一步提出了一个面向食品图像识别的深度渐进式区域增强网络。该网络主要由渐进式局部特征学习模块和区域特征增强模块组成。前者通过改进的渐进式训练方法学习多样互补的局部细粒度判别性特征(如食材相关区域特征),后者利用自注意力机制将多尺度的丰富上下文信息融入到局部特征中,进一步增强特征表示。
本文在Food2K上进行的大量实验证明了所提出方法的有效性,并且在Food2K上训练的网络能够改善各种食品计算视觉任务的性能,如食品图像识别、食品图像检索、跨模态菜谱-食品图像检索、食品检测和分割等。我们期待 Food2K及在Food2K上的训练模型能够支撑研究者探索更多的食品计算新任务。本论文相关的数据集、代码和模型可从网站下载:http://123.57.42.89/FoodProject.html。
2 Food2K数据集
Food2K同时包含西方菜和东方菜,在食品专家的帮助下,我们结合现有的食品分类方法建立了一个食品拓扑体系。Food2K包括12个超类(如“面包”和“肉”),每个超类都有一些子类别(如“肉”中的“牛肉”和“猪肉”),每种食品类别包含许多菜肴(如“牛肉”中的“咖喱牛肉”和“小牛排”),如下图2所示:
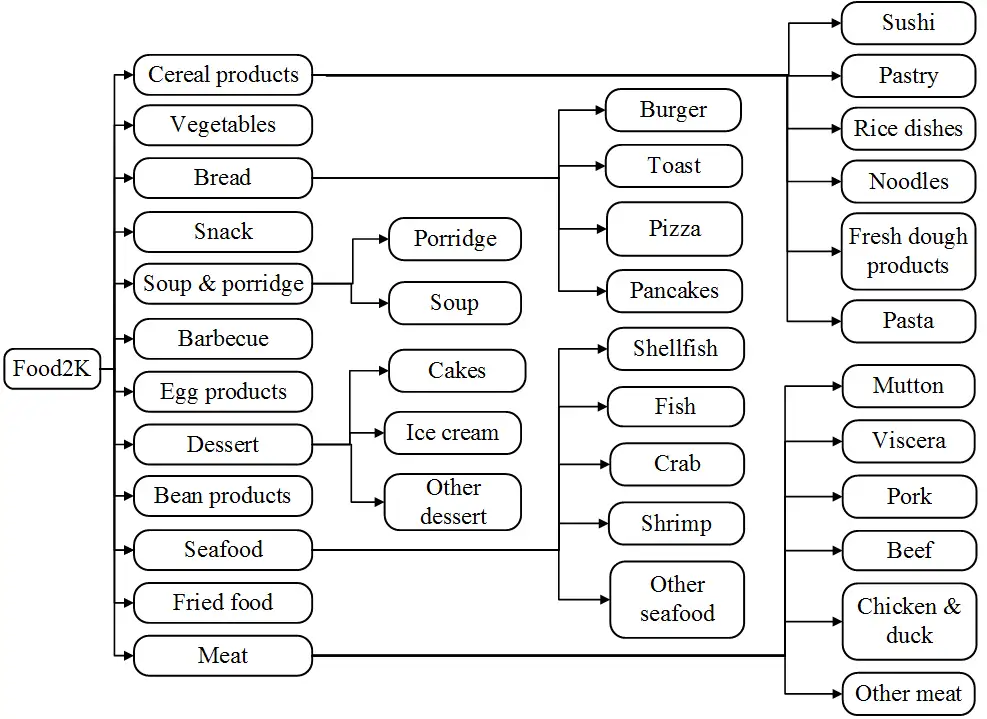
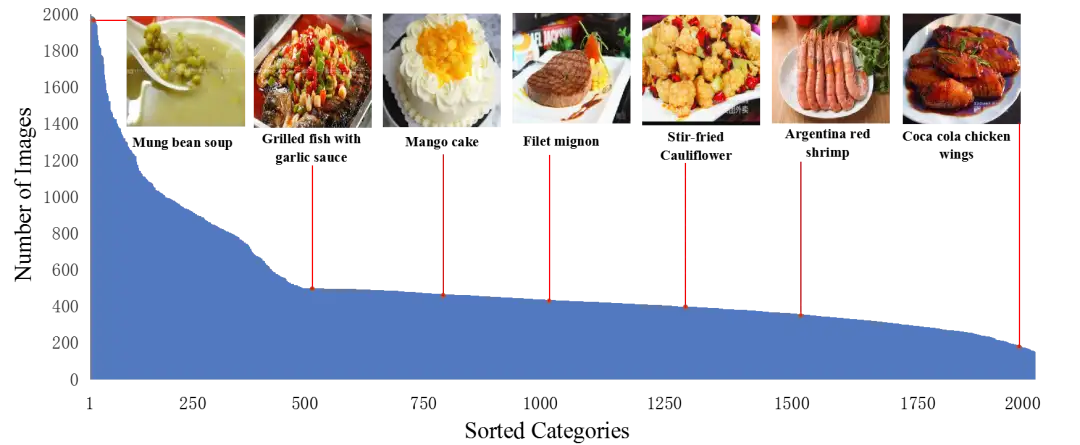
下图3展示了每个食品类别的图像数量,Food2K中每个类别的图像数量分布在[153,1999]之间不等,呈现出明显的长尾分布现象,与类别不平衡性。
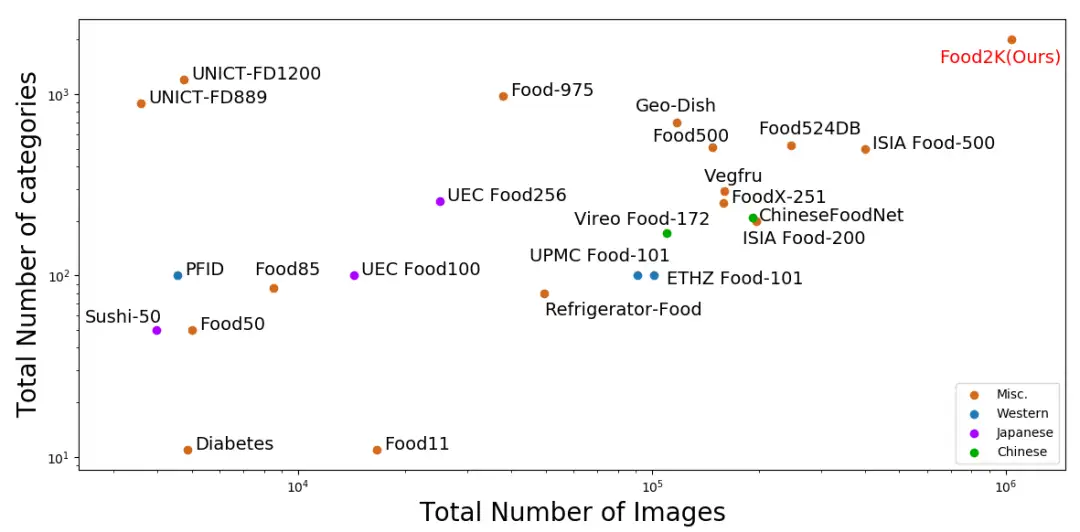
下图4展示了Food2K与现有食品图像识别数据集的图像数量对比,可以看到Food2K在类别和图像数量上都远超过它们。
除此之外,Food2K还具有以下特征:
1)Food2K涵盖了更多样化的视觉外观和模式。不同食材组合、不同配饰、不同排列等都会导致同一类别的视觉差异。举例来说,新鲜水果沙拉因其不同的水果成分混合而呈现出不同的视觉外观。这些食品的独特特征导致了更高的类内差异,使大规模的食品图像识别变得更加困难。
2)Food2K包含更细粒度的类别标注。以“Pizza”为例,一些经典的食品数据集,如Food-101,只有较粗粒度的披萨类。而Food2K中的披萨类则进一步分为更多的类别。不同披萨图像之间的细微视觉差异主要是由独特的食材或同一食材的粒度不同引起的,这也导致了识别的困难。所有这些因素使Food2K成为一个新的更具挑战性的大规模食品图像识别基准,可以视为食品计算领域的“ImageNet”。
3 方法
食品图像识别需要挖掘食品图像的本身特点,并同时考虑不同粒度的图像特征进行识别。通过观察我们发现,食品图像有着明显的全局特征和局部特征。
首先,食品图像明显有着全局的外观、形状和其他结构方面的特征,且该特征存在较大的类内差异。如下图5的“奶油核桃饼”明显有着变化不一的形状,炒面有着丰富多样的纹理。虽然当前已经有很多方法来解决这一问题,但大多数方法主要集中在提取某种类型的特征,而忽略了其他类型的特征。

其次,食品图像中有细微差别的细节信息,部分细节信息是其关键的局部特征。在许多情况下,现有的神经网络无法很好地挖掘那些具有判别性的细节特征。如图5中第3栏所示,仅仅依靠全局特征是不足以区分“玉米羹”和“鸡蛋羹”,必须进一步挖掘其食材信息的不同(图中黄色框内)。因此,如何更好地挖掘食品图像的全局特征和局部特征,对于提升食品图像特征表达能力来说尤为重要。
第三,如下图6所示,不同的食材在不同的食品类别中所占的权重也是不一样的。“香菜”在“香菜”拌牛肉中是一个关键性食材,必不可少,但是在“老醋海蜇”这道菜中仅仅是一个配料,并不总是出现在该类别的所有图像中。因此需要挖掘局部特征之间的关系,突出重点局部特征。进而提高食品识别的准确率。

针对上述这些特点,本文设计了深度渐进式区域特征增强网络,它可以共同学习多样化且互补的局部和全局特征。该网络结构如下图7所示,该网络主要由三部分组成:全局特征学习模块、渐进式局部特征学习模块和区域特征增强模块。
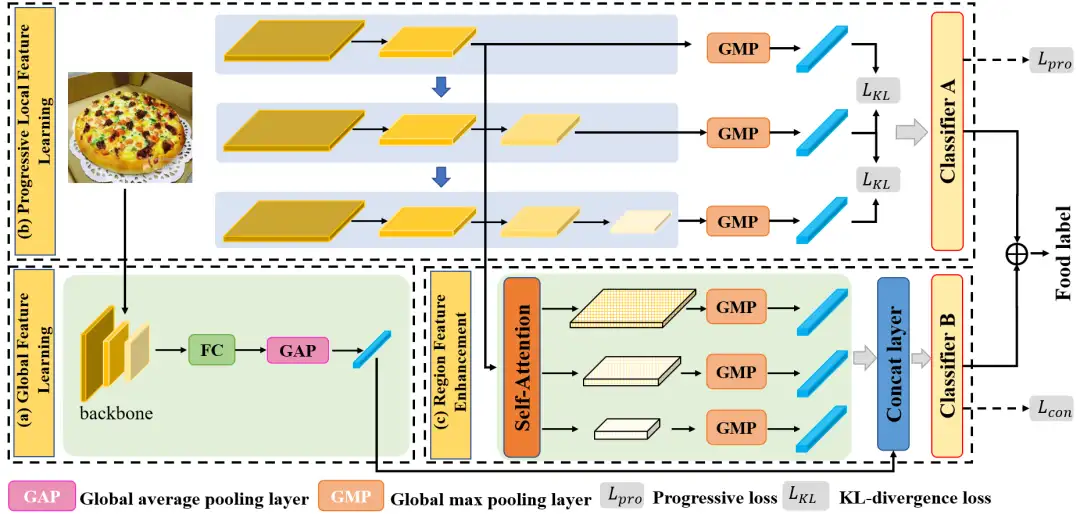
其中,渐进式局部特征学习主要采用渐进式训练策略来学习互补的多尺度细粒度的局部特征,例如不同的食材相关信息。区域特征增强使用自注意力机模块,将更丰富的多尺度上下文信息合并到局部特征中,以增强局部特征表示。然后,我们通过特征融合层将增强的局部特征和来自全局特征学习模块的全局特征融合到统一的特征中。
此外,在模型训练时,本文逐步渐进式地训练网络的不同阶段,最后将训练整个网络,并在此过程中引入散度以增加各个阶段之间的差异性,以捕获更丰富多样化的局部信息。在推理阶段,考虑到每个阶段的输出特征和融合后的特征之间的互补性,我们将它们的预测结果结合起来得到最终分类得分。接下来,本文将详细介绍各个模块的计算原理。
| 全局-局部特征学习
食品识别可以看作是一个层次化的任务,在不同超类下的食品图像有着明显可分的视觉差异,因此可以基于他们的全局特征进行识别。
但是在同一超类下,不同子类的食品图像之间的差异却非常小。因此食品识别需要同时学习食品图像的全局特征和局部特征。因此,我们提取并融合了这两个特征,此过程可以使用两个子网络分别提取食品图像的全局和局部特征。这两个子网络可以是两个独立的网络,但是这部分工作为了提高效率并减小模型参数,本文中两个子网络共享基础网络的大部分层。
全局特征学习
对于全局特征学习,本文取最后一个卷积层的输出,使用全局平均池化(Global Average Pooling, GAP)来提取全局特征:其中为从主干网络最后一个卷积层中提取的特征。
渐进式局部特征学习
局部特征子网络旨在学习食品的区分性细粒度特征。由于食材和烹饪风格的多样性,食品图像的关键判别部分是多尺度和不规则的。作为本方法第一个创新点,我们提出了渐进式训练策略来解决这个问题。在这种策略中,我们首先训练具有较小感受野的网络较低阶段(可以理解为模型中较低的层),然后逐步扩大该局部区域范围,并引入新的层加入训练。
这种训练策略将迫使我们的模型提取更精细的判别性局部特征,例如与食材相关的特征。在此过程之后,我们从不同层提取特征以获得多尺度的特征表示。具体来说,对于来自局部特征子网络的每一层的输出 ,其中u是网络的不同阶段。我们使用一个卷积层和一个全局最大池化层(Global Maximum Pooling,GMP)来得到它们的局部特征向量:
因此,该策略可以首先在网络较浅的层中学习更稳定的细粒度信息,然后随着训练的进行逐渐将注意力转移到在较深的层中学习粗粒度信息。具体来说,当具有不同粒度的特征被送入网络时,它可以提取出有判别性的局部细粒度特征,例如食材成分信息。然而,简单地使用渐进式训练策略不会得到多样化的细粒度特征,因为通过渐进式训练学习到的多尺度特征信息可能集中在食品图像中相似的区域。
而作为本方法第二个创新点,我们引入KL散度对来自不同阶段的特征进行离散化,以增加它们之间的差异性。我们通过最大化不同阶段特征之间的KL散度值,可以迫使网络模型在不同阶段关注不同区域的多尺度特征,这有助于网络捕获尽可能多的细节信息。
具体来说,我们将训练过程划分为个步骤,每一步训练前个阶段,其中是网络的总阶段数。因为我们将在最后阶段(也称为特征融合阶段)将融合所有的全局和局部特征,因此总步骤数为。在我们的方法中,对于渐进式训练的每一步训练的网络不同层的输出,使用对该输出特征进行处理。由一个卷积层、一个批归一化层和一个单元组成。然后我们可以得到局部特征表示 。最后,对于来自不同阶段的这些多个局部特征,我们利用散度来增加阶段之间的差异,这有助于捕获尽可能多的细节。对每两个相邻阶段的输出,计算散度的方式如下,其中散度的reduction设置为batchmean。
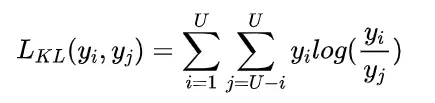
| 区域特征增强
不同于一般的细粒度任务中的识别对象,食品图像没有固定的语义信息。现有的大部分食品识别方法直接挖掘这些判别性局部特征,忽略了局部特征之间的关系。因此,我们采用自注意力机制来学习不同局部特征之间的关系。该策略旨在捕获特征图中同时出现的食品特征。
具体来说,借鉴于Non-Local Interaction的操作,我们在同一个特征图内操作实现自注意力增强,并输出与输入同尺度的特征图。我们首先提取所有个阶段局部特征表示,然后通过自注意力机制获得增强后的特征,计算方式如下:
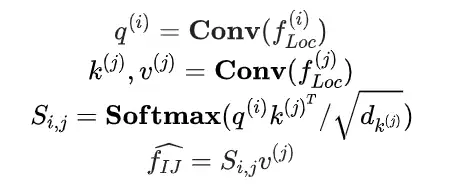
其中,和是中位于i和j位置的像素特征。基于此我们可以得到增强特征。最后我们将这些相同大小的增强后的特征图融合起来,并使用卷积运算将它们转换为相同的维度。最后,我们可以得到个局部特征。通过这种策略我们的模型能够使局部特征实现跨空间和尺度的信息交互。在训练过程中,在获得全局特征和局部特征后,我们在特征融合阶段将它们融合后为最终表示为:
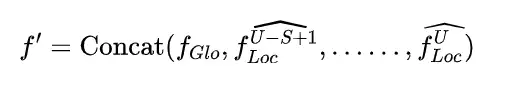
| 训练和预测
在网络优化过程中,我们迭代更新网络的参数。首先,我们利用各个阶段的交叉熵损失,来反向传播以更新相应网络的参数。在此过程中,当前阶段的所有网络参数都将被优化,即使它们在之前的阶段已经被更新过。然后在特征融合阶段,我们利用另一个交叉熵损失函数来更新整个网络的参数。此外,我们的网络以端到端的方式进行训练。在渐进式训练过程中,对于每个阶段的输出,我们采用以下交叉熵损失:
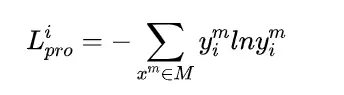
其中是一组训练数据,表示个样本,是对应的类别标签。对于最后融合得到的特征表示,我们使用另一个交叉熵损失:
其中是预测标签,是训练样本的总数。接下来,我们引入的散度作为一项损失加入到最终的损失函数中,以增加阶段之间的差异性进而以捕获更丰富的细节信息,所以最终损失函数为:
其中,α和β是平衡参数。
在模型推理阶段,来自最终特征融合征阶段输出的特征,被输入到分类器B中获得对应的预测输出。对于前几个阶段的输出,我们可以利用分类器A来预测相应的输出值,其中分类器A由两个全连接层和Batchnorm及Elu非线性单元组成。
考虑到不同阶段的预测输出和特征融合阶段最终输出之间的互补性,我们可以将所有输出组合在一起以提高识别性能。因此我们将所有阶段的预测得分(包括最终得分)相加,以相同的权重来预测对应的食品类别:
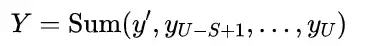
4 实验
首先,我们在Food2K上对现有的食品识别方法和我们提出的方法进行了比较。然后,我们研究Food2K在食品识别、食品图像检索、跨模态菜谱-食品图像检索、食品检测和食品分割五个食品计算任务上的泛化能力。
| 方法验证与分析
本文使用在ImageNet上预训练的ResNet[10]作为基础网络。对于实验性能评估,使用Top-1准确率(Top-1)和Top-5准确率(Top-5)对食品类别识别进行评估。
在Food2K上的性能实验
表1展示了在Food2K上现有的食品识别方法和所提方法的性能比较。从表中可以看出,我们的方法在Top-1和Top-5准确率上分别高出主干网络(ResNet)2.24%和1.4%,以ResNet101为主干的网络超过了现有的食品识别方法,取得了较好的识别性能。同时,这也证实了结合渐进式训练策略和自注意力来增强局部特征表示的优势。
在Food2K上的消融实验
本文在消融实验中主要探讨了以下几个问题:
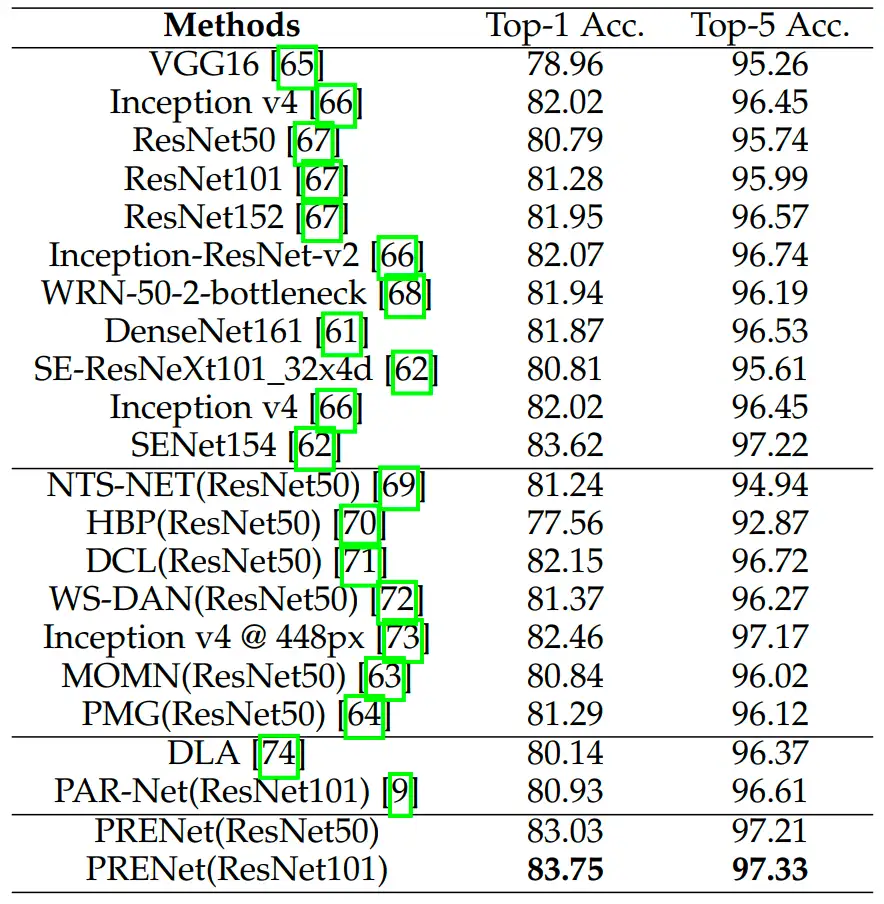
(1)网络不同组件的有效性:从下图8(a)中可以看出,渐进式策略(PL)的引入能够带来识别性能增益,且与区域特征增强(RE)相结合后进一步提高了性能。这说明我们提出的PL+RE的学习策略能够有效地学到更具判别性的局部特征。
(2)渐进式学习阶段的数量U:从下图8(b)中可以看出,当U从1到3时,我们的方法在Food2K上分别取得了81.45%、82.11%和83.03%的Top-1分类准确率。模型的分类性能连续提高了0.66%和0.92%。然而,当U = 4时,精度开始下降,可能的原因是浅层网络主要关注类别无关的特征。
(3)不同学习阶段的效果:为了更好地验证每个学习阶段和最终的连接阶段的贡献,我们还通过分别使用每个阶段的预测分数来进行评估。从下图8(c)中可以看出,相比于使用单一阶段进行预测,联合每个阶段的得分进行预测能够带来性能提升。此外,我们的方法将每个阶段的预测分数和联合特征的预测分数进行组合,能够实现最佳的识别性能。
(4)平衡参数α和β:我们还研究了公式αβ中平衡参数对性能的影响。我们发现,当α,β时,即总损失仅包括散度时,此时模型无法收敛。当α,β时,即仅使用交叉熵损失进行优化,模型的性能明显下降。当α,β时,模型取得了最佳的识别性能,这说明联合渐进式训练和KL散度的策略能够提高多样化局部细节特征的学习能力。
可视化
我们使用Grad-CAM来进行可视化分析。如下图9所示,以“Wasabi Octopus”为例,基线方法仅能获得有限的信息,不同的特征图倾向于关注相似的区域。相比之下,我们的方法在第一阶段更关注“Vegetable Leaf”,而第二阶段主要关注“Octopus”。而在第三阶段,我们的方法可以捕获该食品的总体特征,所以全局和局部特征都能被用于识别。

基于Food2K的泛化实验
食品图像识别
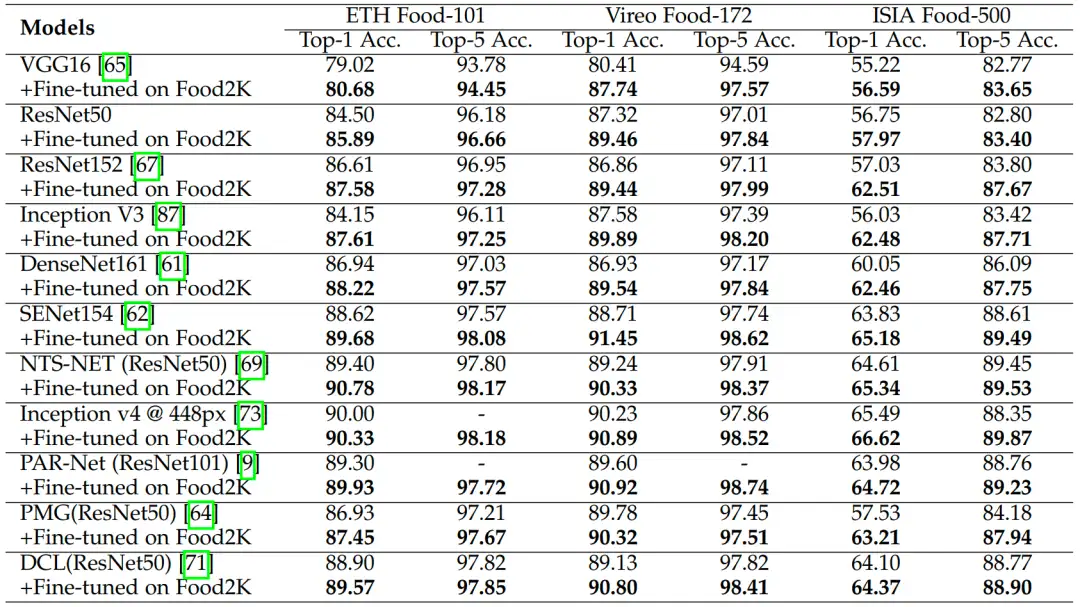
我们评估了在Food2K上预训练过的模型在ETH Food-101、Vireo Food-172和ISIA Food-500上的泛化能力。从表2中我们可以看出,使用Food2K进行预训练后所有方法都取得了一定程度的性能提升,这说明我们的数据集在食品图像识别任务上具有良好的泛化能力。
食品检测
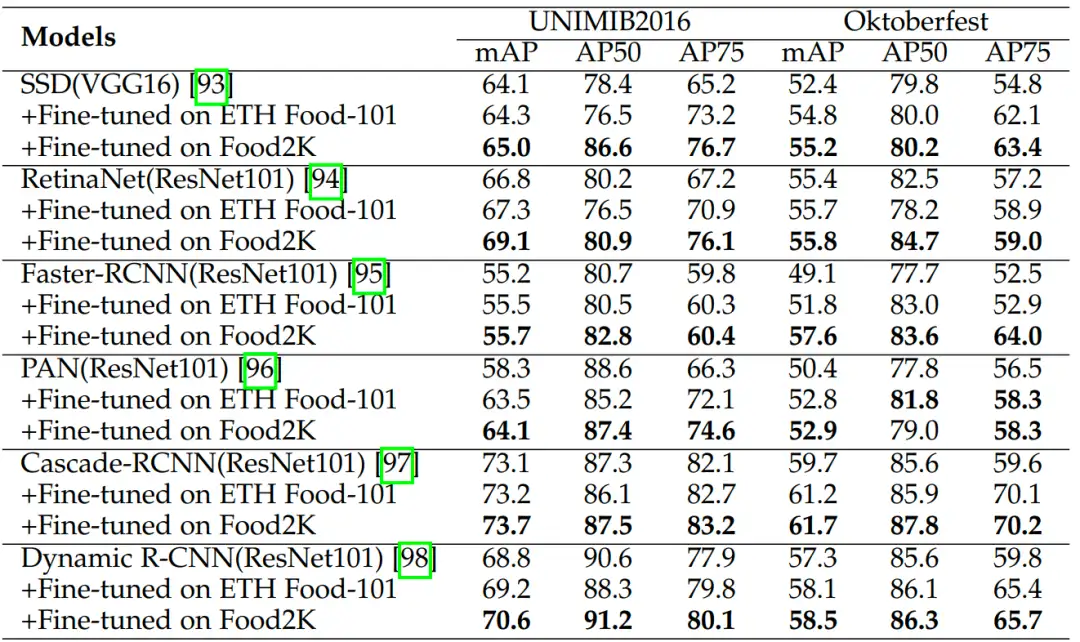
我们评估了Food2K数据集对食品检测任务的泛化能力,评估任务为检测食品托盘中的食品。为了进行比较,我们还对在ETH Food-101上进行预训练的模型进行了评估。从表3中可以看出,使用Food-101和Food2K能够提升所有方法的mAP和AP75指标,且Food2K所带来的性能增益要超过Food-101。这说明我们的方法在食品检测任务上表现出良好的泛化性能。
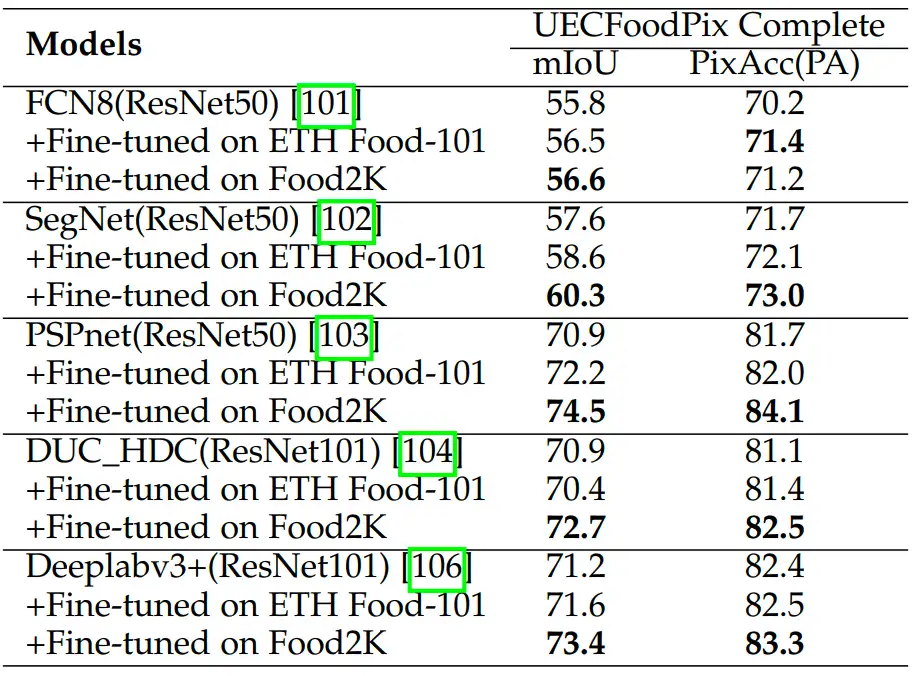
食品分割
我们还评估了Food2K在食品分割任务上的性能。从表4中可以看出,对于所有使用Food2K进行预训练的模型均能带来性能的提升。这也证明了我们的数据集在分割任务上具有良好的泛化表现。
食品图像检索
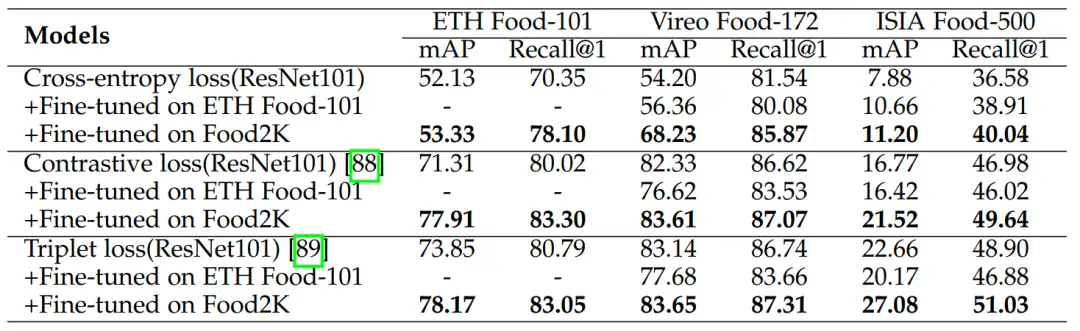
我们进一步在食品图像检索任务上验证Food-2K的泛化能力。具体来说,我们在ETH Food-101、Vireo Food-172和ISIA Food-500数据集上实验,并使用与前文相同的数据集划分方式。测试集的每张图片依次作为查询项,其余的图片作为检索库。我们分别使用交叉熵损失函数和以Contrastive loss和Triplet loss为代表的度量学习损失函数来微调ResNet101网络,并使用mAP和Recall@1指标评估方法的性能。
表5的结果展示了在Food-2K数据集上预训练后微调的网络取得了不同程度的性能增益。具体来说,在Vireo Food-172数据集上取得了最优性能,并在三个数据集上分别取得了4.04%, 5.28% 和4.16%的性能增益。值得注意的是,当使用额外的ETH Food-101数据集预训练,以及在度量学习损失函数方法上微调的方法并没有取得性能增益,但使用Food2K数据集预训练仍然取得了性能增益,这是因为食品图像检索任务对目标数据集之间的差异较为敏感(ETH Food-101和Vireo Food-172),并间接表明来自Food2K的图像类别和尺度的多样性提升了食品图像检索任务的泛化性。
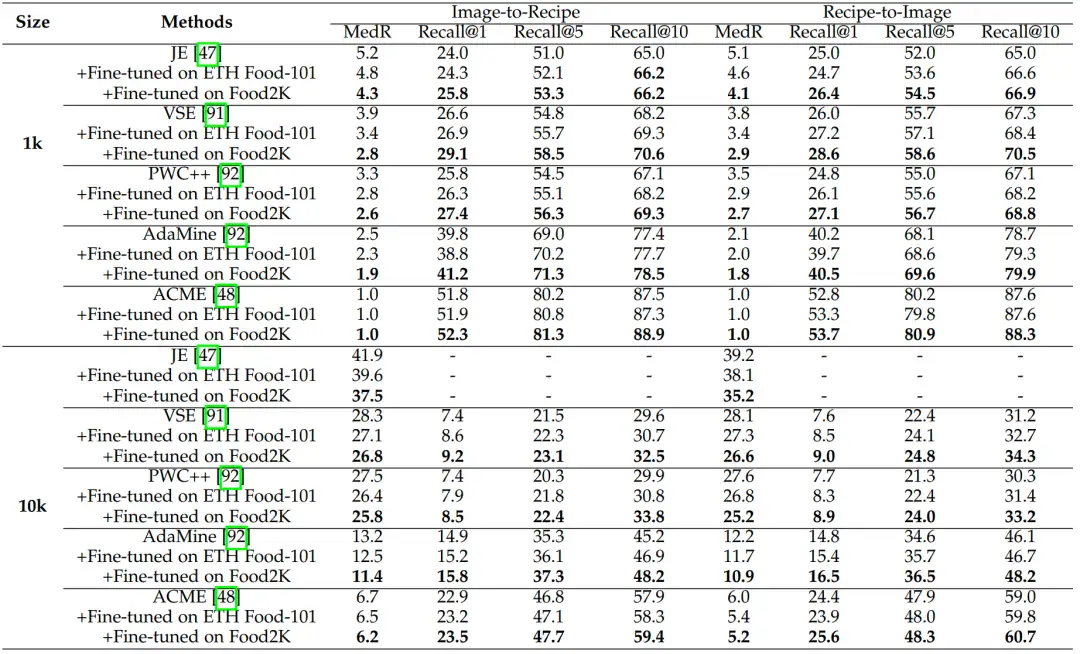
跨模态菜谱-食品图像检索
我们还在跨模态菜谱-食品图像检索任务上进一步验证Food2K的泛化能力。具体来说,我们在Recipe1M[11]数据集上验证方法的性能,并使用与之相同的数据集划分方法。与此同时,我们使用MedR和Recall@K指标来评估。表6展示了我们使用不同的网络主干,并分别通过ImageNet、ETH Food-101和Food2K数据集预训练的结果。结果发现使用ETH Food-101和Food2K数据集预训练后在目标数据集上微调都取得了性能的增益,使用我们的Food-2K数据集取得了更大的性能增益。
5 未来工作
本文全面的实验证明了Food2K对于各种视觉和多模态任务具有较好的泛化能力。基于Food2K的一些潜在研究问题和方向如下。
(1)大规模鲁棒的食品图像识别:尽管一些细粒度识别方法(如PMG[12,22])在常规细粒度识别数据集中获得了最佳性能,但它们在Food2K上表现欠佳。虽然也有一些食品图像识别方法(如PAR-Net[13])在中小规模食品数据集上取得了较好的性能,但它们在Food2K大规模食品图像识别数据集上也并不能获得更好的性能。
我们推测,随着食品数据的多样性和规模的增加,不同食材、配饰和排列等因素产生了更复杂的视觉模式,以前的方法不再适用。因此,基于Food2K有更多的方法值得进一步探究。例如Transformers[14,23]在细粒度图像识别方面产生了巨大的影响,其在大规模数据集上的性能高于CNNs。Food2K可以提供足够的训练数据来开发基于Transformers的食品图像识别方法来提高性能。
(2)食品图像识别的人类视觉评价:与人类视觉对一般物体识别的研究相比,对食品图像识别进行评价可能更加困难。例如,食品具有较强的地域和文化特征,因此来自不同地区的人对食品图像识别会有不同的偏见。最近的一项研究[15]给出了人类视觉系统和CNN在食品图像识别任务中的比较。为了避免信息负担过重,需要学习的菜肴数量被限制在16种不同类型的食物中。更有趣的问题,值得进一步的探索。
(3)跨模态迁移学习的食品图像识别:我们已经验证了Food2K在各种视觉和多模态任务中的推广。未来我们可以从更多的方面来研究迁移学习。例如,食物有独特的地理和文化属性,可以进行跨菜系的迁移学习。这意味着我们可以使用来自东方菜系的训练模型对西方菜系进行性能分析,反之亦然。经过更细粒度的场景标注,如区域级甚至餐厅级标注,我们可以进行跨场景迁移学习来进行食品图像识别。此外,我们还可以研究跨超类别迁移学习的食品图像识别。例如,我们可以使用来自海鲜超类的训练模型来对肉类超类进行性能分析。这些有趣的问题也都值得深入探索。
(4)大规模小样本食品图像识别:最近,有一些基于中小型食品类别的小样本食品图像识别方法[16,17]研究。LS-FSFR[18]是一项更现实的任务,它旨在识别数百种新的类别而不忘记以前的类别,且这些数百种新的食品类别的样本数很少。Food2K提供了大规模的食品数据集测试基准来支持这项任务。
(5)更多基于Food2K的应用:本文验证了Food2K在食品图像识别、食品图像检索、跨模态菜谱-食品图像检索、食品检测和分割等各种任务中具有更好的泛化能力。Food2K还可以支持更多新颖的应用。食品图像生成是一种新颖而有趣的应用,它可以通过生成对抗网络(GANs)[19]合成与现实场景相似的新的食品图像。例如,Zhu等人[20]可以从给定的食材和指令中生成高度真实和语义一致的图像。不同的GANs,如轻量级的GAN [21],也可以用于生成基于Food2K的食物图像。
(6) 面向更多任务的Food2K扩展:基于训练的Food2K模型可以应用于更多与食物计算任务中。另外,考虑到一些工作[6]已经表明食材可以提高识别性能,我们计划扩展Food2K来提供更丰富的属性标注以支持不同语义级别的食品图像识别。我们还可以在Food2K上进行区域级和像素级标注使其应用范围更广。我们还可以开展一些新的任务,如通过在Food2K上标注美学属性信息,对食品图像进行美学评估。
6 总结及展望
在本文中,我们提出了具有更多数据量、更大类别覆盖率和更高多样性的Food2K,它可以作为一个新的大规模食品图像识别基准。Food2K适用于各种视觉和多模态任务,包括食品图像识别、食品图像检索、检测、分割和跨模态菜谱-食品图像检索。
在此基础上,我们进一步提出了一个面向食品图像识别的深度渐进式区域增强网络。该网络主要由渐进式局部特征学习模块和区域特征增强模块组成。渐进式局部特征学习模块通过改进的渐进式训练方法学习多样互补的局部细粒度判别性特征,区域特征增强模块利用自注意力机制将多尺度的丰富上下文信息融入到局部特征中以进一步增强特征表示。在Food2K上进行的大量实验证明了该方法的有效性。
美团本身有着丰富的食品数据及业务应用场景,如何利用多元化数据进行食品图像细粒度分析理解,解决业务痛点问题是我们持续关注的方向。目前,美团视觉智能部持续深耕于食品细粒度识别技术,并成功将相关技术应用于按搜出图、点评智能推荐、扫一扫发现美食等不同的业务场景中,不仅提升了用户体验,还降低了运营成本。
在技术沉淀层面,我们围绕此食品计算技术不断推陈出新,目前申请专利20项,发表CCF-A类会议或期刊论文4篇(如AAAI、TIP、ACM MM等);我们还参加了2019年和2022年CVPR FGVC细粒度识别比赛,并取得了一冠一亚的成绩;同时在ICCV 2021上也成功举办了以LargeFineFoodAI为主题的视觉研讨会,为推动食品计算领域的发展贡献了一份绵薄之力。
未来,我们计划进一步围绕这条主线,探索多模态信息融入、多任务学习等技术路线,不断沉淀经验教训,并将相关技术推广到更多、更远、更有价值的生活服务场景中,从而更好地服务好社会。
7 参考文献
[1] W. Min, S. Jiang, L. Liu, Y. Rui, and R. Jain, “A survey on food computing,” ACM CSUR, vol. 52, no. 5, pp. 1–36, 2019.
[2] A. Meyers, N. Johnston, V. Rathod, A. Korattikara, A. Gorban, N. Silberman, S. Guadarrama, G. Papandreou, J. Huang, and K. P. Murphy, “Im2Calories: towards an automated mobile vision food diary,” in ICCV, 2015, pp. 1233–1241.
[3] Q. Thames, A. Karpur, W. Norris, F. Xia, L. Panait, T. Weyand, and J. Sim, “Nutrition5k: Towards automatic nutritional understanding of generic food,” in CVPR, 2021, pp. 8903–8911.
[4] Y. Lu, T. Stathopoulou, M. F. Vasiloglou, S. Christodoulidis, Z. Stanga, and S. Mougiakakou, “An artificial intelligence-based system to assess nutrient intake for hospitalised patients,” IEEE TMM, pp. 1–1, 2020.
[5] L. Bossard, M. Guillaumin, and L. Van Gool, “Food-101–mining discriminative components with random forests,” in ECCV, 2014, pp. 446–461.
[6] J. Chen and C.-W. Ngo, “Deep-based ingredient recognition for cooking recipe retrieval,” in ACM MM, 2016, pp. 32–41.
[7] W. Min, L. Liu, Z. Wang, Z. Luo, X. Wei, and X. Wei, “ISIA Food- 500: A dataset for large-scale food recognition via stacked globallocal attention network,” in ACM MM, 2020, pp. 393–401.
[8] J. Mar´ın, A. Biswas, F. Ofli, N. Hynes, A. Salvador, Y. Aytar, I. Weber, and A. Torralba, “Recipe1M+: A dataset for learning cross-modal embeddings for cooking recipes and food images,” IEEE T-PAMI, vol. 43, no. 1, pp. 187–203, 2021.
[9] H. Wang, G. Lin, S. C. H. Hoi, and C. Miao, “Structure-aware generation network for recipe generation from images,” in ECCV, vol. 12372, 2020, pp. 359–374.
[10] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in CVPR, 2016, pp. 770–778.
[11] A. Salvador, N. Hynes, Y. Aytar, J. Marin, F. Ofli, I. Weber, and A. Torralba, “Learning cross-modal embeddings for cooking recipes and food images,” in CVPR, 2017, pp. 3020–3028.
[12] R. Du, D. Chang, A. K. Bhunia, J. Xie, Z. Ma, Y. Song, and J. Guo, “Fine-grained visual classification via progressive multigranularity training of jigsaw patches,” in ECCV, 2020, pp. 153– 168.
[13] J. Qiu, F. P.-W. Lo, Y. Sun, S. Wang, and B. Lo, “Mining discriminative food regions for accurate food recognition,” in BMVC, 2019.
[14] Dosovitskiy, Alexey, et al. "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale." In ICLR, 2020.
[15] P. Furtado, M. Caldeira, and P. Martins, “Human visual system vs convolution neural networks in food recognition task: An empirical comparison,” in CVIU, 2020, pp. 102878.
[16] H. Zhao, K.-H. Yap, and A. Chichung Kot, “Fusion learning using semantics and graph convolutional network for visual food recognition,” in WACV, 2021, pp. 1711–1720.
[17] S. Jiang, W. Min, Y. Lyu, and L. Liu, “Few-shot food recognition via multi-view representation learning,” ACM TOMM, vol. 16, no. 3, pp. 87:1–87:20, 2020.
[18] A. Li, T. Luo, Z. Lu, T. Xiang, and L. Wang, “Large-scale few-shot learning: Knowledge transfer with class hierarchy,” in CVPR, 2019, pp. 7212–7220.
[19] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. WardeFarley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” in NIPS, vol. 27, 2014.
[20] B. Zhu and C. Ngo, “CookGAN: Causality based text-to-image synthesis,” in CVPR, 2020, pp. 5518–5526.
[21] B. Liu, Y. Zhu, K. Song, and A. Elgammal, “Towards faster and stabilized gan training for high-fidelity few-shot image synthesis,” in ICLR, 2020.
[22] Zhu, H., Ke, W., Li, D., Liu, J., Tian, L., & Shan, Y. Dual cross-attention learning for fine-grained visual categorization and object re-identification. In CVPR 2-22(pp. 4692-4702).
[23] He, J., Chen, J. N., Liu, S., Kortylewski, A., Yang, C., Bai, Y., & Wang, C. . Transfg: A transformer architecture for fine-grained recognition. In AAAI 2022 (Vol. 36, No. 1, pp. 852-860).
8 本文作者
致岭、丽萍、君实、晓明等,均来自美团基础研发平台/视觉智能部。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章

 浙公网安备 33010602011771号
浙公网安备 33010602011771号