MMYOLO 想你所想:训练过程可视化
前言 本文将结合 MMYOLO,对训练过程中常见的可视化需求进行详细描述。
本文转载自OpenMMLab
来源 | 带来新知识的
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
主要内容如下:
- 训练 loss 和评估指标等标量可视化
- 追加自定义标量
- 训练中正样本可视化分析
- 配置文件存储和可视化
- 模型结构图可视化
- 参数梯度分布可视化
注意:由于 MMYOLO 中的可视化器是直接引用 MMDetection 3.x 中的,故本文所述内容完全适用于 MMDetection 3.x,并且因为 MMEngine 中统一了可视化器,因此本文部分内容也同样适用于 OpenMMLab 2.0 的各个框架。
MMEngine 官方地址:
https://github.com/open-mmlab/mmengine
MMDetection 官方地址:
https://github.com/open-mmlab/mmdetection
MMYOLO 官方地址:
https://github.com/open-mmlab/mmyolo
由于 MMYOLO 还处于快速迭代中,后续不同版本可能参数或者功能会有略微区别,本文发布时 MMYOLO 版本为 0.4.0。
1. Loss 和评估指标等标量可视化
此功能已经在 MMEngine 中实现了,我们无需进行任何额外操作。
以 YOLOv5 算法为例,为了方便进行演示,我们选择 configs/yolov5/yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py 这样的配置,该配置是基于 COCO 预训练权重,然后用在非常小的 balloon 气球数据集上进行微调。
(1) 下载 balloon 数据集

执行以上命令,下载数据集并转化格式后,balloon 数据集在 data 文件夹中准备好了,train.json 和 val.json 便是 coco 格式的标注文件了,可以直接进行训练和测试。
(2) 训练并使用 WandB 可视化 loss 曲线
上述配置中,默认是没有加载预训练权重的,大家可以在 configs/yolov5/yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py 快速添加如下代码:
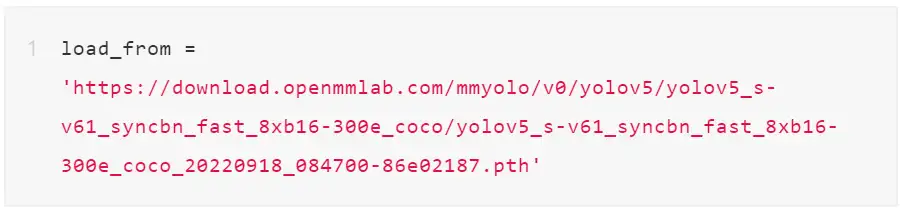
MMEngine 中目前已经支持 LocalVisBackend、WandbVisBackend 和 TensorboardVisBackend 三种后端。MMYOLO 中默认的可视化后端是本地后端 LocalVisBackend,想切换为 WandB 只需要修改 vis_backends 即可。
直接打开 configs/_base_/default_runtime.py,将 vis_backends 修改为如下所示:

开启训练的脚本为:

可视化的 WandB 曲线如下所示:
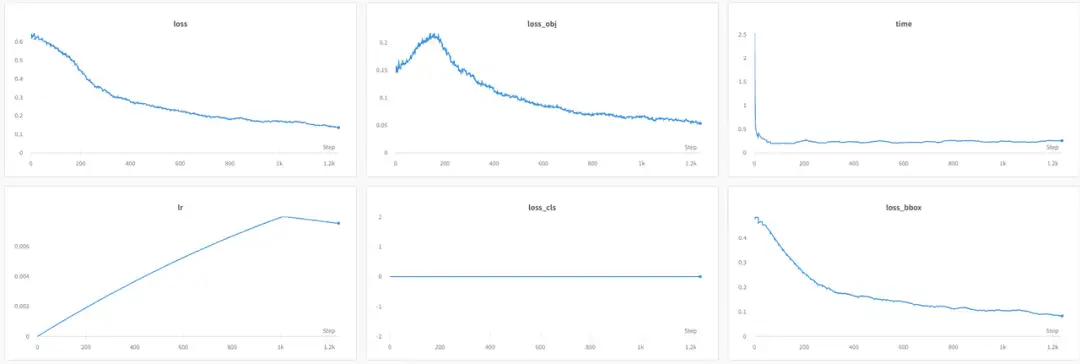
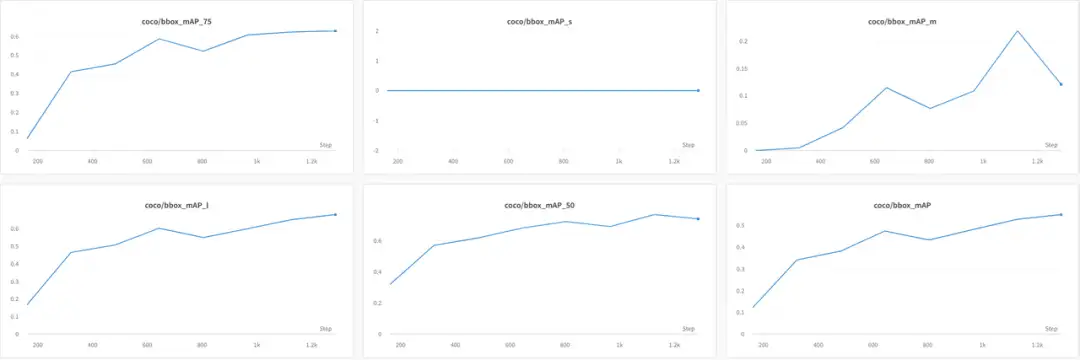
由于 balloon 是单类数据集,并且其中没有 COCO 中划定的小物体框,所以 loss_cls 始终是 0,mAP_s 也始终是 0。
2. 追加自定义标量
在大部分时候,我们非常希望能在训练过程中保存一些额外关注的信息用于进一步分析。新版的 MMEngine 也支持了这个功能。一个非常典型的例子为:将 YOLOv5 训练过程中当前 batch 的正样本总个数信息打印到终端中,并且通过指定后端将其同时保存到 WandB 后端中。要实现该功能非常简单,只需将你想要保存的变量加入到 MessageHub 实例对象中即可。
具体做法是:在 https://github.com/open-mmlab/mmyolo/blob/main/mmyolo/models/dense_heads/yolov5_head.py#L602

第 620 行代码(上图黄色部分)后面添加如下代码即可:

启动训练后,终端打印信息如下:
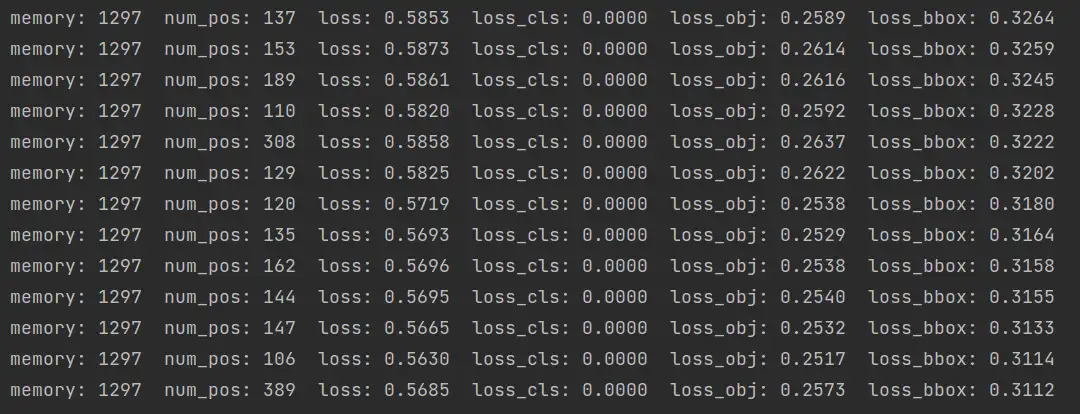
可以发现会额外打印 num_pos 正样本的个数,同时在 WandB 中也有存储:
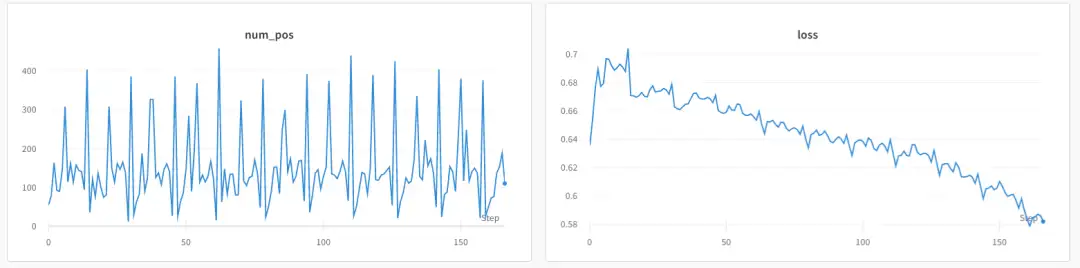
3. 训练中正样本可视化分析
目标检测算法中正样本分配策略是一个非常核心的部件,其对检测算法的性能影响很大,对其进行深入可视化分析有助于理解算法的正样本分配策略,也有助于排查代码问题等等。
MMYOLO 中目前已经支持了 YOLOv5、YOLOv6、YOLOv7、YOLOv8、RTMDet、YOLOX 和 PPYOLOE 一共 7 个主流算法,其中包括的正样本策略如下:
- YOLOv5 的 shape 匹配策略
- YOLOX 的 simOTA 匹配策略
- RTMDet 的动态软标签匹配策略
- TOOD 算法的任务对齐 TaskAligned 匹配策略
而 YOLOv6 前几个 epoch 采用的是 ATSS 策略,后几个 epoch 采用的是TaskAligned 策略,YOLOv8 采用的是 TaskAligned 策略,YOLOv7 采用的是 YOLOv5 的 shape 匹配策略和 YOLOX 的 simOTA 匹配策略。
上述算法中 YOLOv5 和 YOLOv7 是 Anchor-Based 算法,其余都是 Anchor-Free 算法。
在 MMYOLO 中代码直接支持正样本可视化存在如下难点:
- 正样本可视化代码和 loss 计算等代码深度绑定,如果直接在代码中支持,会导致 MMYOLO 中代码看起来过于复杂,不利于代码阅读
- 正样本可视化一般只是代码调试或者分析时候才会使用,且会影响训练速度
本着代码简单清晰原则,正样本可视化暂时没有直接合入 mmyolo 包里面,而是放到了 projects 目录下,链接为 https://github.com/open-mmlab/mmyolo/blob/main/projects/assigner_visualization/README.md
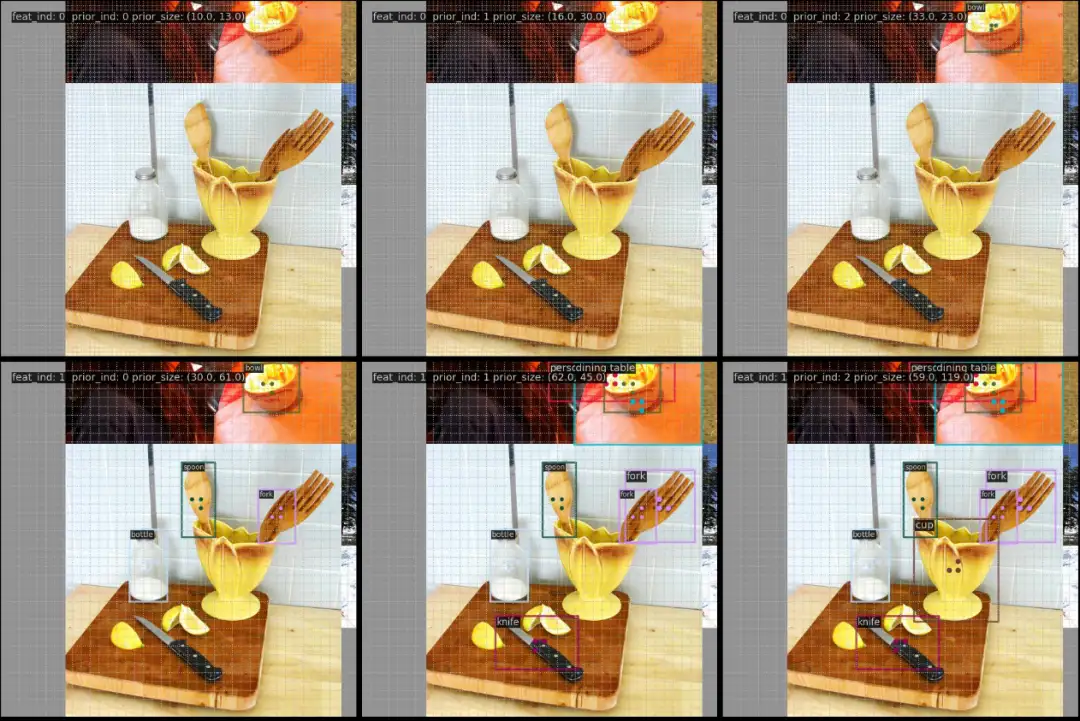
上图为 YOLOv5_s 模型正样本可视化效果图。目前(2023.2.13) MMYOLO 的 main 分支只支持了 YOLOv5 正样本可视化分析,但是在 dev 分支中已经支持了 RTMDet、YOLOv7 和 YOLOv8。下面以 dev 分支来详细说明。
3.1 YOLOv5 正样本可视化
YOLOv5 的正样本匹配策略是静态策略,也就是和算法的实时网络预测无关,这种情况下就不需要加载 COCO 训练好的权重了。
使用方式非常简单,只需要运行如下命令即可:

会在当前路径下新建 assigned_results 文件夹,内部保存的是每一张图的正样本结果:
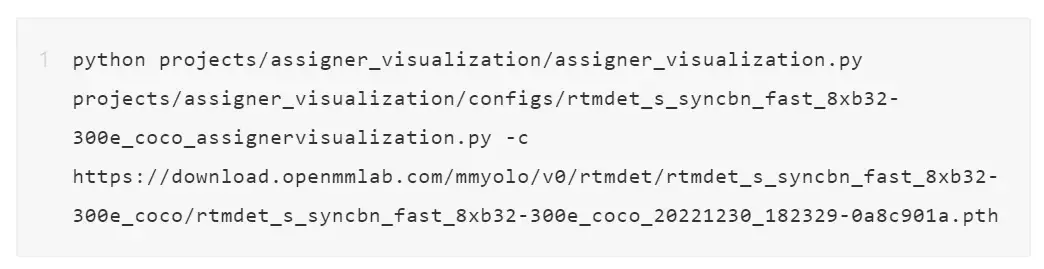
我们选择其中一张图片来说明图片中绘制的内容具体含义。

YOLOv5 一共 3 个尺度的输出层,分别对应上图的 feat_ind 从 0~2,每个输出层的每个位置包括 3 个 anchor,对应上图的 prior_ind 从 0~2,所以上图中,(0, 0) 表示第 0 个输出层(stride 最小)中第 0 个 anchor 的正样本匹配情况,(2, 1) 表示第 2 个输出层中第 1 个 anchor 的正样本匹配情况,prior_size 表示当前 anchor 的 shape 大小。
上图一共包括 4 个标签,基于 shape 匹配策略,大物体会在 stride 大的尺度匹配,小物体会在 stride 小的尺度匹配,并且 YOLOv5 中还增加了跨网格预测功能,所以每个正样本中心都会有额外的两个正样本点也当做是匹配上。
如果想同时显示 anchor,可以开启 --show-prior 标志:

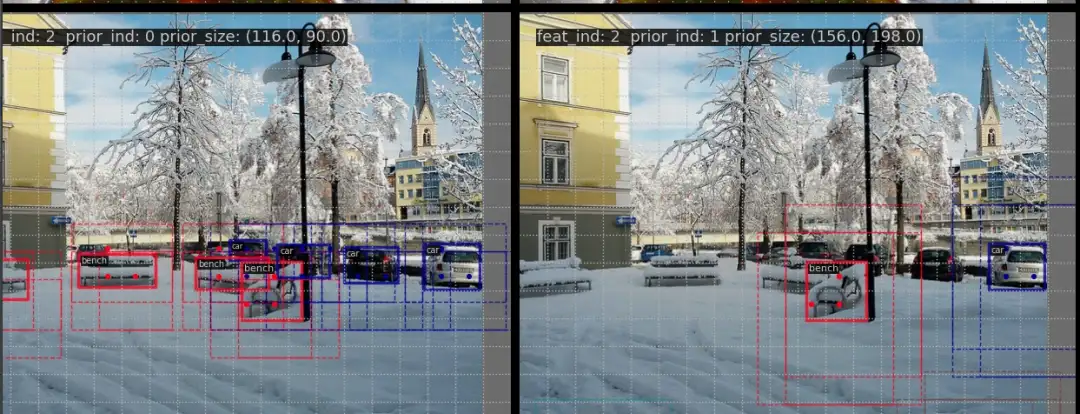
上图为 YOLOv5_s 显示先验框效果图,其中不同类别使用不同的颜色显示,虚线是 anchor。
3.2 RTMDet 正样本可视化
RTMDet 是动态匹配策略,其正样本匹配策略和当前网络输出息息相关。也就是说在训练过程中都是动态的,加载不同时刻权重可视化效果不一样。
由于目前正样本可视化功能没有集成到训练中,因此目前的折中办法就是加载不同时刻的权重进行可视化,后续我们会想办法支持训练中动态可视化。
使用方式和前面一模一样。运行脚本为:
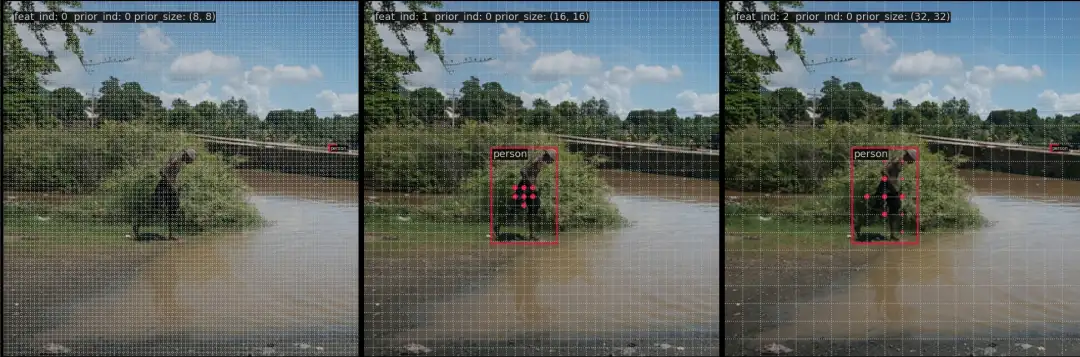
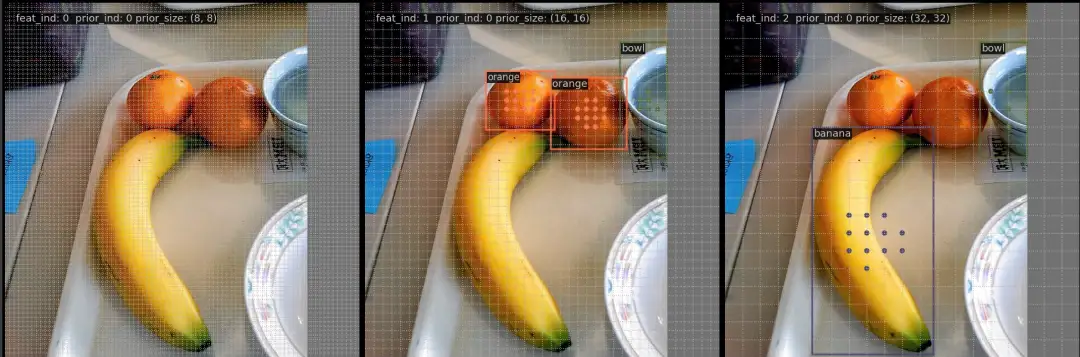
RTMDet 是 Anchor-Free 算法,可以简单认为其 anchor 个数是 1,因此 prior_ind 始终是 0。以下是挑选的 3 张图片的可视化效果:

目前这个 project 还在不断完善中,如果你有啥好的意见,非常欢迎来共同完善或者反馈。
4. 配置文件存储和可视化
我们在进行多个对比实验时候,会特别关心某个配置文件到底修改了哪些参数,因为时间久了可能会忘记,所以默认情况下,MMEngine 在训练开始前会将 config 文件保存到本地,同时存储到各个可视化后端,方便后续查看。
配置文件保存到本地有丢失的风险,一个好的策略是保存到远端,例如 WandB 中。基于 WandB 后端,MMEngine 已经支持了自动代码上传,配置文件保存等功能。
依然以第 1 部分的配置为例,训练时候会在 artifacts 中保存各类数据。
(1) 自动代码上传
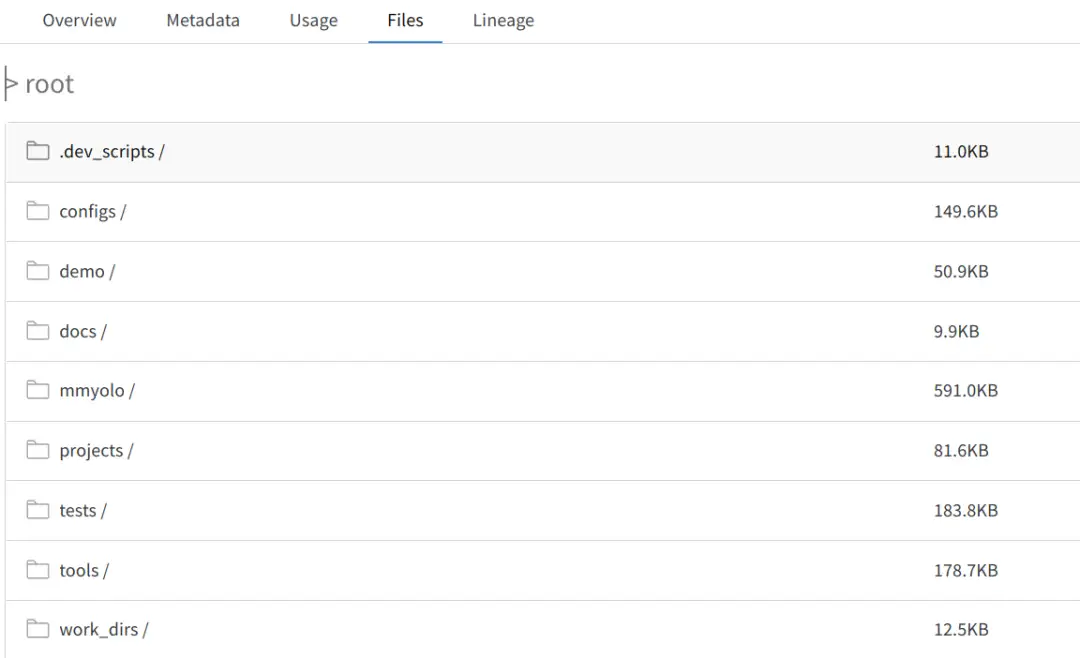
在浏览器的 artifacts 页面中可以找到 Files tab(如下图),里面存储了当前实验的所有代码和 work_dir。
(2) 配置文件存储和查看
除了在 work_dir 中会保存一份完整配置外,在 metadata 页面也会保存配置中的所有超参,如下图所示:
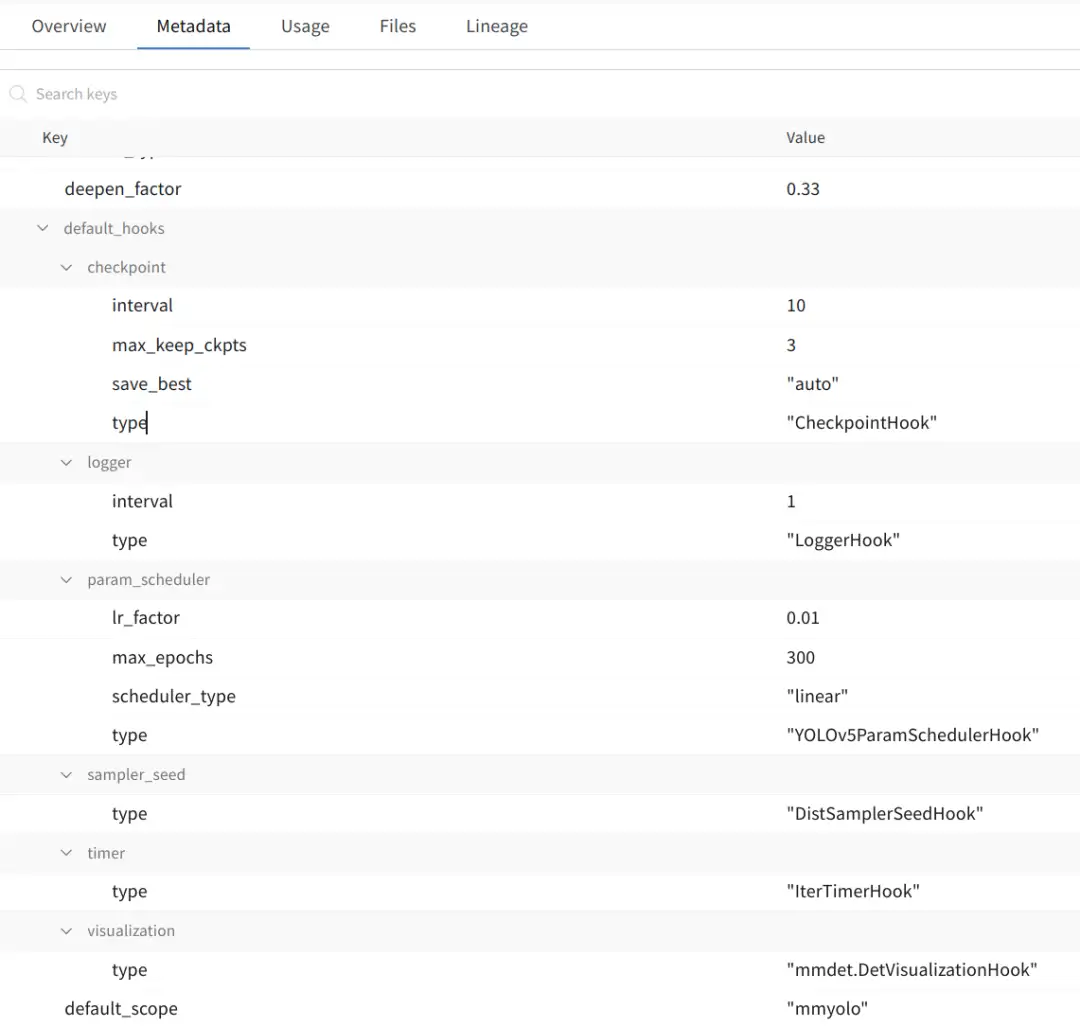
(3) 自动对比修改的超参
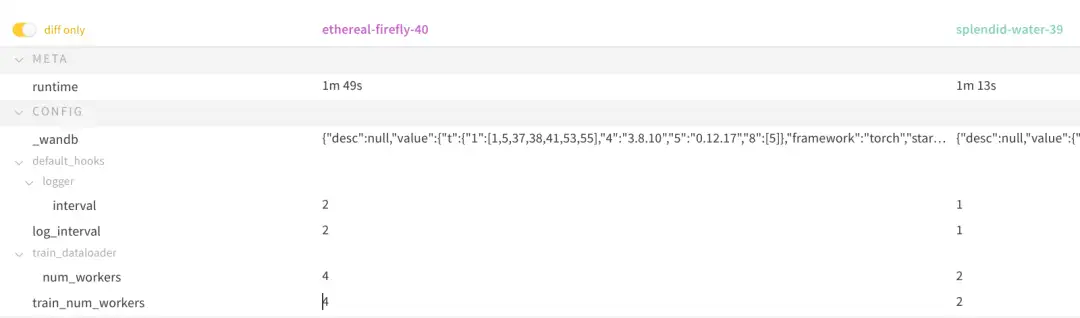
WandB 有一个非常不错的功能,可以显示不同实验之间修改了哪些参数。基于上述配置,修改train_num_workers 和 log_interval 的参数,通过 WandB 的 add panel -> run-comparer -> diff only 步骤就可以显示如下效果:
5. 模型结构图可视化
模型结构图可视化也是一个非常常见的需求,在最新的 MMEngine 0.5.0 中还没有完全支持,主要原因是有些后端没有这个功能,有些后端接收的参数也不一样。
目前想实现模型结构图可视化有两条途径:
- 导出为 ONNX 格式,然后采用 netron 工具查看,效果较好,缺点是不是任何模型都能导出 ONNX
- 采用 Tensorboard 查看网络结构,实现简单,缺点是可视化效果一般
本文讲一下如何使用 Tensorboard 查看网络结构。在 MMYOLO 工程根路径下,新建文件 tb_graph_demo.py,内容如下:

可视化器后端配置切换为 TensorboardVisBackend:

运行上述 demo 会在当前路径下生成 tb_graph/vis_data 文件夹,浏览器启动命令为:

效果如下所示:
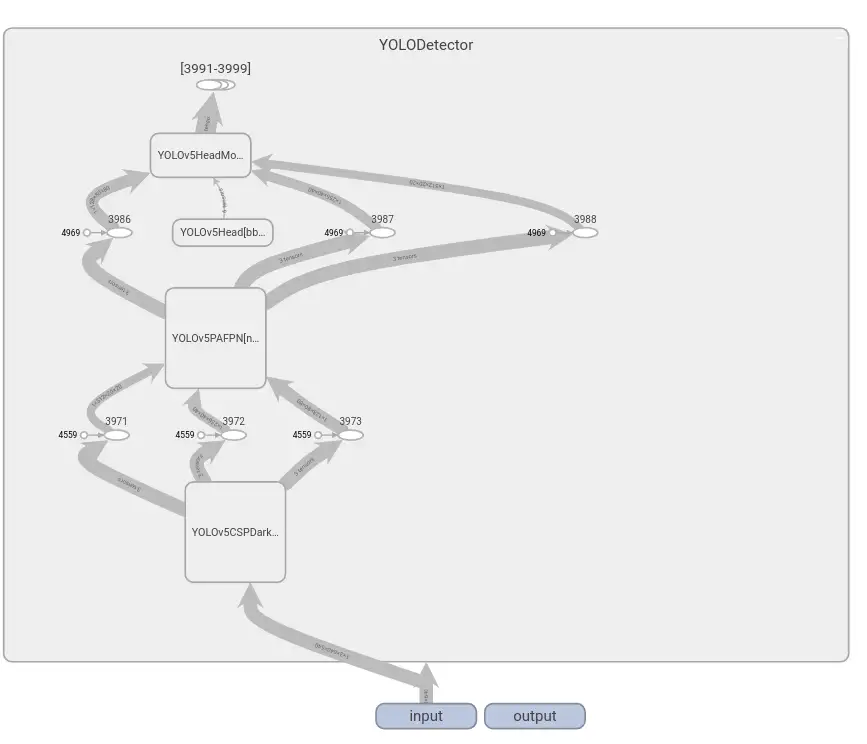
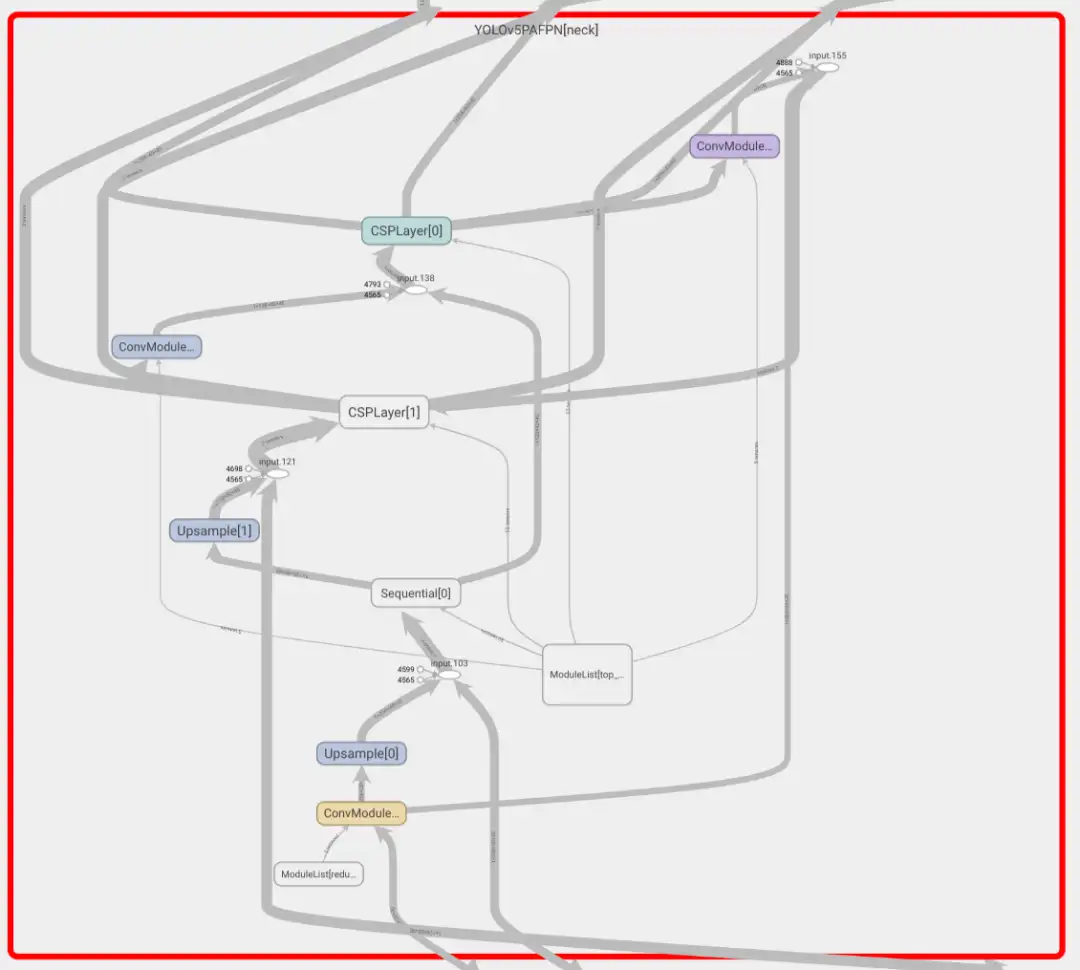
核心功能就是如下三行代码:

6. 参数梯度分布的可视化
类似第 5 小节中的模型结构图可视化功能,虽然 MMEngine 中没有提供统一接口实现参数梯度分布可视化,但是你依然可以先获取特定后端,然后通过后端的特定 API 实现。
- WandB 的 Watch 开启训练前加入一次就行
- Tensorboard 的 add_histogram 可以每个 epoch 加一次,也可以每隔多少迭代间隔看一次
(1) Wandb 可视化参数梯度分布
假设你已经修改可视化后端为 WandbVisBackend。为了无侵入的支持参数梯度分布可视化,我们可以新增一个 hook 并重写 before_train 方法,如果想偷懒,可以直接修改mmdet/engine/hooks/visualization_hook.py,因为 MMYOLO 会调用这个可视化 hook,新增如下代码:

以 YOLOv5-s 为例训练后效果如下:

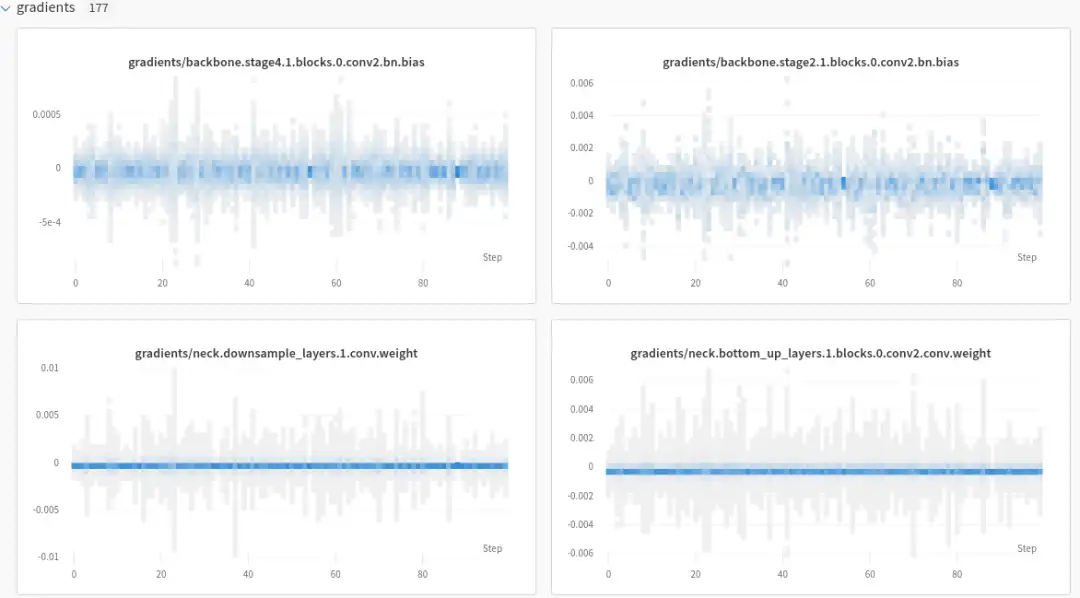
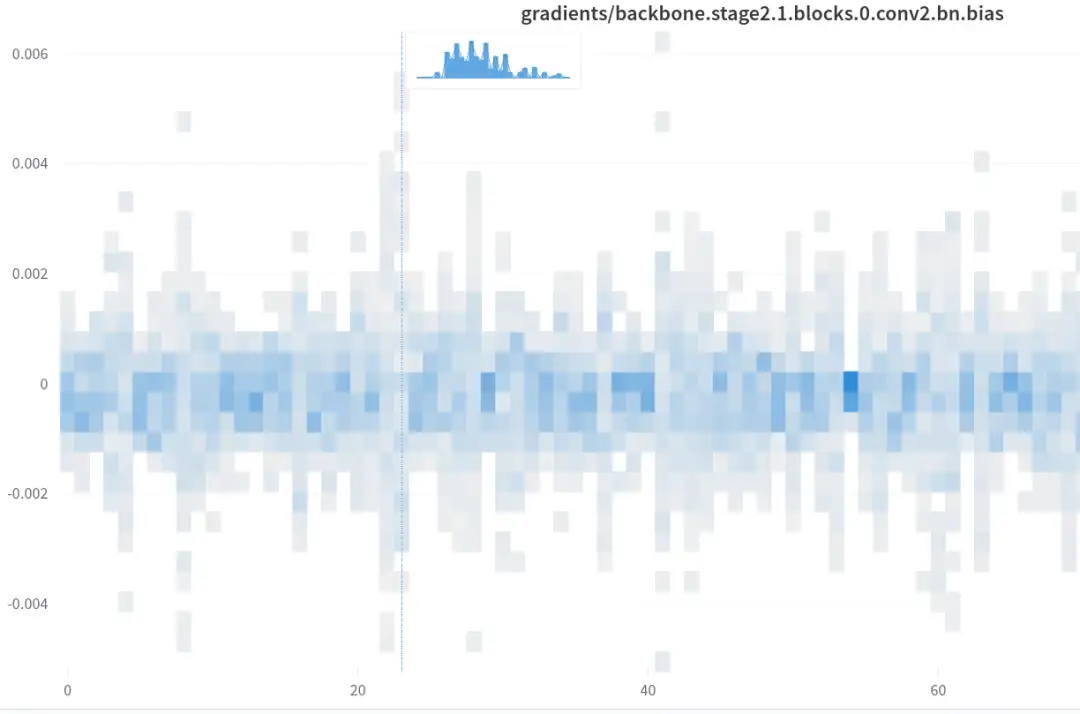
细节如下:
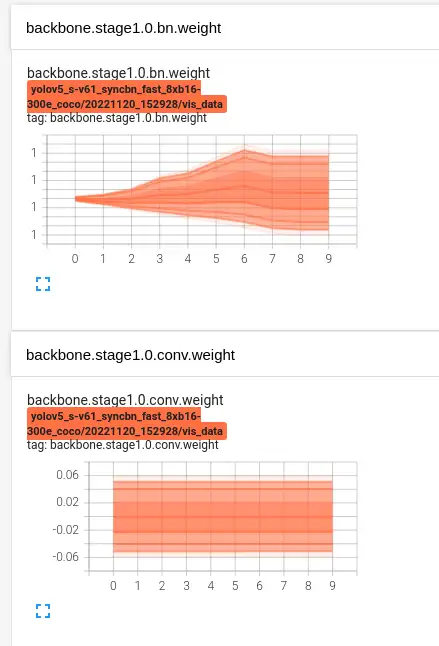
(2) Tensorboard 可视化参数梯度分布
和前面类似,假设你已经修改了可视化后端为 TensorboardVisBackend。仅仅需要修改 mmdet/engine/hooks/visualization_hook.py,并新增一个 after_train_epoch。在每个 epoch 后面调用 API 进行模型参数分布和梯度分布可视化。
但是比较遗憾的是梯度分布暂时获取不到,因为 MMEngine 优化器在每个 step 后会把梯度清 0,导致你在 hook 中获取的梯度都是 0 值。

效果如下所示:
总结
本文以几个小例子演示了 MMYOLO 和 MMEngine 的可视化器和可视化后端功能在训练中常见需求。如果上述所示功能依然无法满足你的定制化需求,欢迎给我们反馈,我们将不断完善,尽量提供更好的用户体验。
MMYOLO 官方地址:
https://github.com/open-mmlab/mmyolo
MMEngine 官方地址:
https://github.com/open-mmlab/mmengine
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
原来Transformer就是一种图神经网络,这个概念你清楚吗?
TensorRT教程(六)使用Python和C++部署YOLOv5的TensorRT模型
姿态估计端到端新方案 | DirectMHP:用于全范围角度2D多人头部姿势估计
用于超大图像的训练策略:Patch Gradient Descent
CV小知识讨论与分析(5)到底什么是Latent Space?
CVPR 2023 Workshop | 首个大规模视频全景分割比赛
如何更好地应对下游小样本图像数据?不平衡数据集的建模的技巧和策
用少于256KB内存实现边缘训练,开销不到PyTorch千分之一

 浙公网安备 33010602011771号
浙公网安备 33010602011771号