AAAI 2023|优图16篇论文速览,含多标签分类、姿态估计、目标检测、HOI、小样本学习等研究方向
前言 今年腾讯优图实验室共有16篇论文入选,内容涵盖了多标签分类、姿态估计、目标检测、HOI、小样本学习等研究方向,展示了腾讯优图在人工智能领域的技术能力和学术成果。本文介绍了腾讯优图实验室入选论文及方法概述。
来源 | 腾讯优图
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
近日,AAAI 2023(Association for the Advancement of Artificial Intelligence)国际先进人工智能协会公布了录用结果,本届会议共有8777篇投稿,录用1721篇,录用率19.6%。
AAAI是人工智能领域的主要学术组织之一,是一个国际化的非营利科学组织,旨在推动人工智能领域的研究和应用,增进大众对人工智能的了解。会议始于1980年,既注重理论,也注重应用,还会讨论对人工智能发展有着重要影响的社会、哲学、经济等话题。
以下为腾讯优图实验室入选论文概览:
01
面向具有标注噪声的人脸表情识别
Attack can Benefit: An Adversarial Approach to Recognizing Facial Expressions under Noisy Annotations
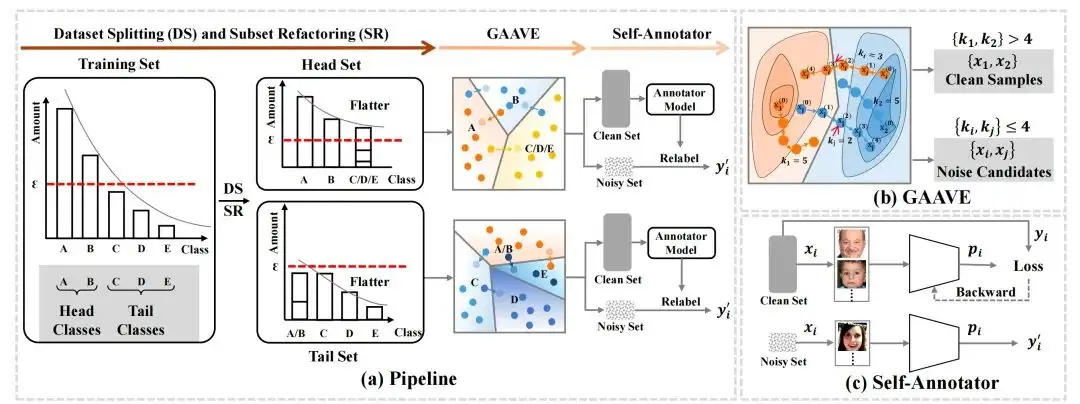
大规模人脸表情数据集通常表现出极端的噪声标签问题,模型容易过拟合于噪声标签样本。同时,表情数据集也表现出极端的类别分布不均衡问题,两个问题相互耦合,给解决表情识别数据中的噪声标签问题带来困难。在本文中,我们提出一个全新的噪声标签定位和重标记方法,即使用对抗攻击来定位噪声标签样本。首先,为了减轻数据分布不平衡的影响,本文提出了一种分治策略,将整个训练集分成两个相对平衡的子集。
其次,基于两个观察结果 (1) 对于用噪声标签训练的深度卷积神经网络,决策边界附近的数据更难区分,更容易被错误标记; (2) 网络对噪声标签的记忆会导致显著的对抗弱点,我们设计了一种几何感知对抗弱点估计方法 ,能够在训练集中发现更多可攻击的数据并将其标记为候选噪声样本。最后,再使用剩余的干净数据来重新标记这些候选噪声样本。
实验结果表明,我们的方法达到了SOTA,相关的可视化结果也证明了所提出方法的优势。
02
联邦学习对抗鲁棒性研究
Delving into the Adversarial Robustness of Federated Learning
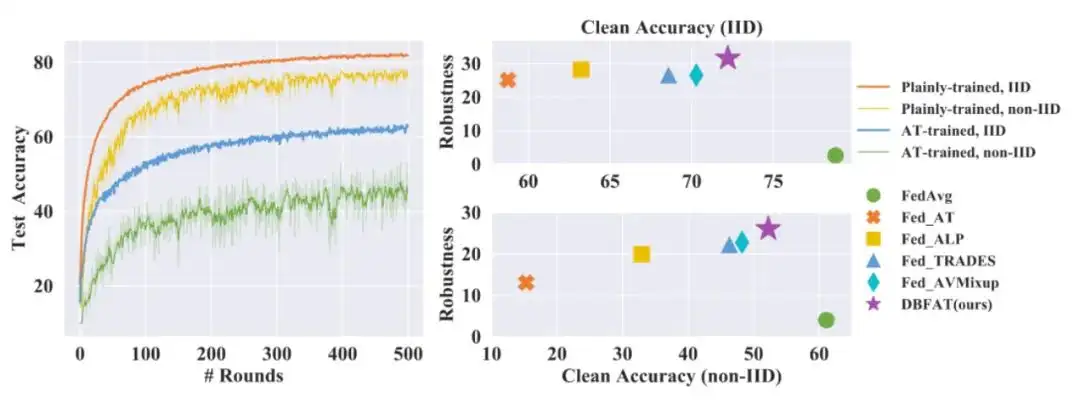
与集中式训练的模型类似,联邦学习(FL)训练的模型同样缺乏对抗鲁棒性。本文主要讨论了联邦学习中的对抗鲁棒性。为了更好地理解现有FL方法的鲁棒性,我们对各种对抗攻击和对抗训练方法进行了评估。
此外,我们揭示了在FL中直接采用对抗性训练所产生的负面影响,即这会严重损害了干净样本的准确率,尤其是在非独立同分布下中。在这项工作中,我们提出了一种基于决策边界的联邦对抗训练(DBFAT)的方法,它由两个组件(即局部重新加权和全局正则化)组成,以提高FL系统的准确性和鲁棒性。
在多个数据集上的大量实验表明,在IID和非IID设置下,DBFAT始终优于其他基线方法。
03
TaCo:一种基于对比学习的文本属性识别方法
TaCo: Textual Attribute Recognition via Contrastive Learning
随着办公数字化进程的持续提速,利用人工智能技术自动、快速、精准地解析输入文档图片的内容,并进一步理解、提取和归纳,即文档智能(DocAI),目前是计算机视觉和自然语言处理交叉学科的一个热门研究方向。在优图实际业务场景中,文档智能技术已经产出了良好的商业价值,在表单理解、版面分析等场景中起到了关键性的支撑。视觉富文档独有的多模态属性,即文本内容,图像信息及文档整体布局的高度耦合,既加大了问题的复杂性,也为技术创新提供了新的着力点。
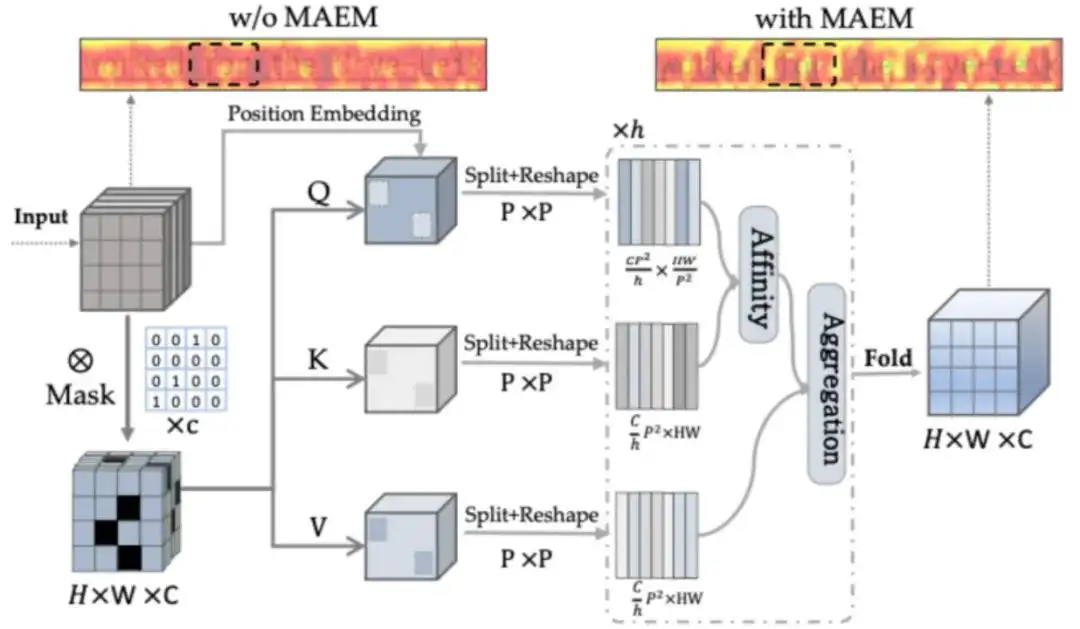
文字是信息的重要载体。除内容外,其多样的视觉属性,如字体/颜色/斜体/粗体/划线,也传达了设计者的理念和思路。如能获取精准的文字视觉属性,对设计从业人员快速获取素材,以及文档图片转word这样的效率工具的开发有直接的助益。但数千种中英文字体,结合开放的配色设计及粗体,斜体等多种状态,即便对于文字设计专家来说,准确判断文字的视觉属性也是一个很大的挑战。因此,研发文字视觉属性识别能力的有潜力为广泛应用赋能。
设计文字视觉属性识别系统并不如想象中简单,因为文字视觉属性间的区别往往是细微的。以字体举例,两个不同字体间往往仅有细微的局部细节差异。与日俱增的新文字样式更近一步加剧了识别的困难,也对系统的泛化性提出了更高的要求。此外,我们在实际应用中观察到,即便是扫描PDF和精心拍摄的图片也会引入噪声和模糊,使细微的局部细节更加难以区分,加大了在特征空间中划分的难度。
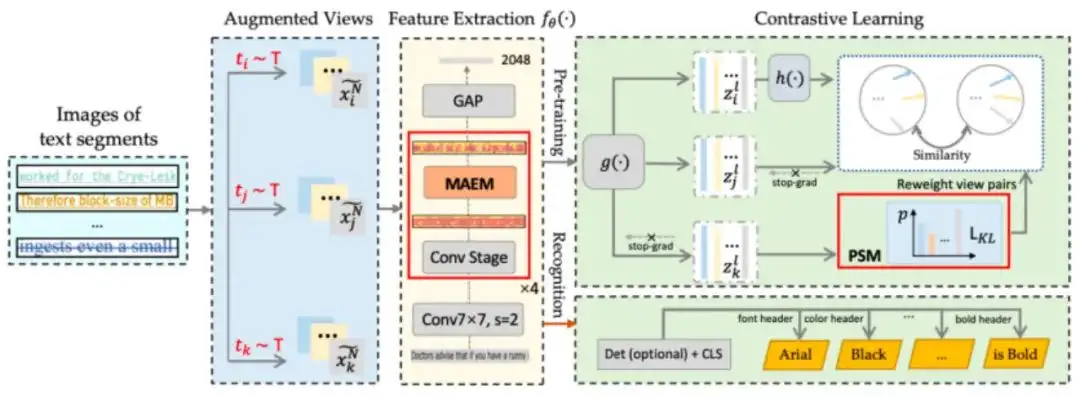
从算法上看,文字视觉属性识别可定义为一个多标签分类问题,输入文本图片,输出文本的各个视觉属性。现有技术方案可以划分为三个类别:1)基于手工设计特征描述符和模板匹配的方法。通常不同文字属性具有不同的视觉风格,可通过统计特征来描述并识别;2)基于深度神经网络的分类方法,用网络提取特征并用于识别;3)基于序列的属性识别方法。基于实际场景的观察,单个文本行内的多个文字往往具有一致的属性。通过将输入图像视为连续的序列信号并建模时序关联,可利用字符间的相关信息和语义一致性来提升识别效果。
遗憾的是,以上方案受困于:1)数据预处理流程复杂。有监督方法依赖于大量专家标注数据;2)可扩展性差,仅支持部分预先定义的类别;3)准确性低,难以捕捉实际场景下相似属性的细微区别。
基于以上观察,我们设计了TaCo (Textual Attribute Recognition via Contrastive Learning)系统用以弥补鸿沟。
04
基于双生完形自编码器的自监督视觉预训练方法
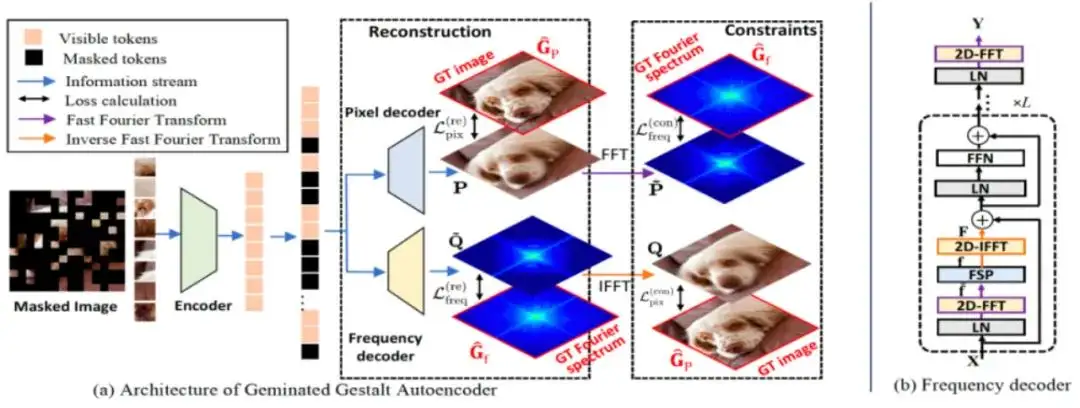
The Devil is in the Frequency: Geminated Gestalt Autoencoder for Self-Supervised Visual Pre-Training
近年来,自监督掩模图像建模(MIM)范式由于其从未标记的数据中学习视觉表示的出色能力,正获得越来越多研究者的兴趣。该范式遵循从掩模图像中恢复内容的“掩模-重构”流程,为了学习高阶语义抽象表示,一系列研究工作尝试采用大比例掩模策略,重构像素。
然而,该类方法存在“过平滑”问题。相比而言,另一个方向的工作引入额外的数据,并采用离线方式直接在监督信息中融入语义。与上述方法不同,我们将视角转移到具有全局视角的傅里叶域,并提出了一种新的掩模图像建模(MIM)方法,称为双生完形自编码器(Ge2-AE),用于解决视觉预训练任务。
具体来说,我们为模型配备了一对并行的解码器,分别负责从像素和频率空间重构图像内容,两者相互约束。通过这种方法,预训练的编码器可以学习到更鲁棒的视觉表示,在下游识别任务上的一系列实验结果证实了这种方法的有效性。
我们还进行了定量和定性的实验来研究我们方法的学习模式。在业内,这是第一个从频域角度去解决视觉预训练任务的MIM工作。
05
定位再生成:基于视觉-语言连接包围框的场景文本视觉问答方法
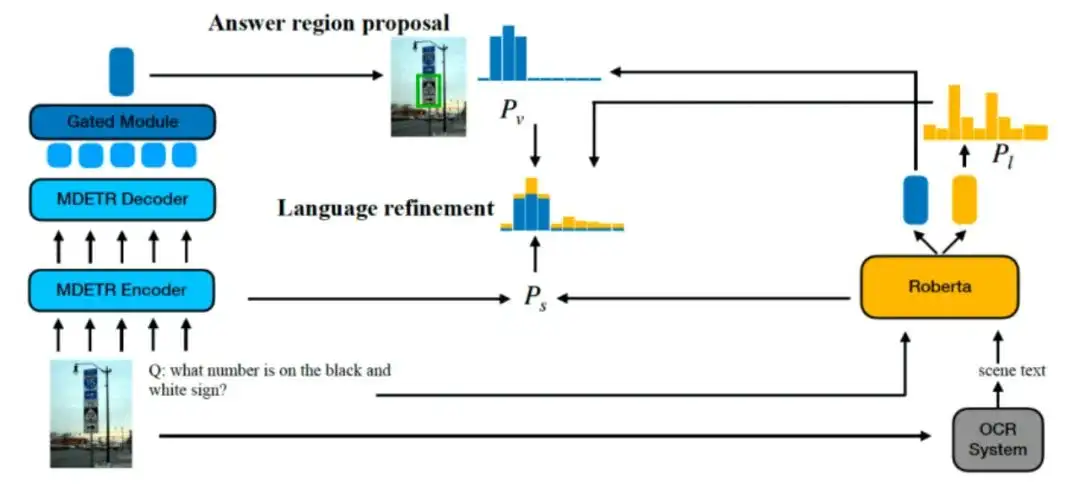
Locate Then Generate: Bridging Vision and Language with Bounding Box for Scene-Text VQA
*本文由腾讯优图实验室和中国科技大学共同完成
本文提出了一种新的多模态场景文本视觉问答框架(STVQA),该框架可以读取图像中的场景文本进行问答。除了可以独立存在的文本或视觉对象外,场景文本在作为图像中的视觉对象的同时,通过传递语言语义,自然地将文本和视觉形态联系在了一起。
与传统的STVQA模型将场景文本中的语言语义和视觉语义作为两个独立的特征不同,本文提出了“先定位后生成”(LTG)范式,将这两种语义明确地统一起来,并以空间包围框作为桥梁连接它们。
具体来说,LTG首先利用由区域建议网络和语言细化网络组成的答案定位模块 (ALM)在可能包含答案词的图像中定位区域,两者通过场景文本边界框进行一对一映射转换。接下来,给定ALM选择的答案词,LTG使用基于预训练语言模型的答案生成模块 (AGM)生成可读的答案序列。采用视觉和语言语义显式对齐的好处是,即使没有任何基于场景文本的预训练任务,LTG也可以在TextVQA数据集和ST-VQA数据集上分别提高 6.06% 和 6.92%的绝对准确性,与非预训练基线方法相比,我们进一步证明,LTG通过空间包围框连接有效地统一了视觉和文本模式,这在之前的方法中研究尚浅。
06
基于少量真实样本指导的稳健网图原型学习
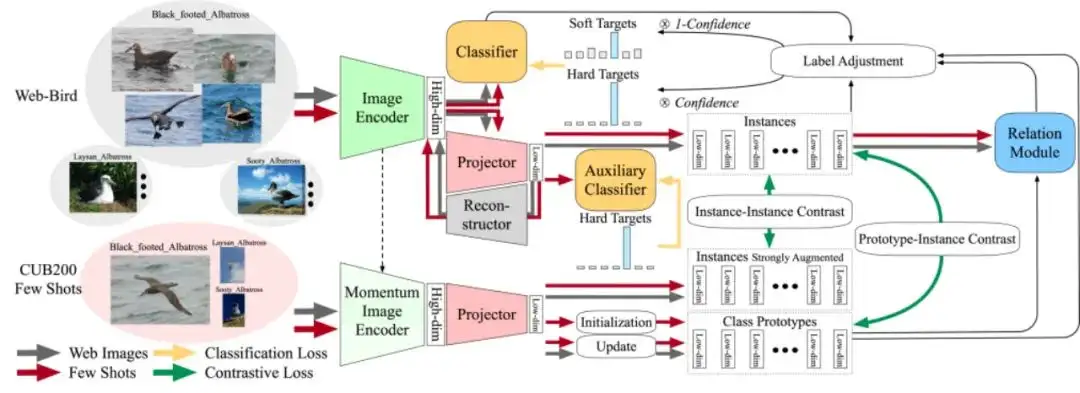
FoPro: Few-Shot Guided Robust Webly-Supervised Prototypical Learning
最近,基于互联网(图像)的监督学习(WSL)研究旨在利用来自互联网上的大量可访问数据。大多数现有方法都侧重于从互联网图像中学习出对噪声稳健的模型,而常常忽略了网络图像领域和真实世界业务领域之间的差异所造成的性能下降问题。只有解决了上述性能差距,我们才能充分挖掘互联网上开源数据集的实用价值。
为此,我们提出了一种名为FoPro的利用少量真实世界样本指导网络图像原型表示学习的方法。它只需要现实业务场景中的少量有标注样本,就可以显著提高模型在真实业务领域的性能。
具体地,本方法使用少量真实场景数据来初始化每个类别中心的特征表示,作为“现实”原型。然后,通过对比学习缩小网络图像实例和真实原型之间的类内距离。最后,该方法用度量学习的方式来衡量网络图像与各类别原型之间的距离。类别原型由表示空间内相邻的高质量网络图像不断修正,并参与移除距离较远的分布外样本(OOD)。
实验中,FoPro使用一些真实领域的样本指导网络数据集的训练学习,并在真实领域的数据集上进行了评估。该方法在三个细粒度数据集和两个大规模数据集上均实现了先进性能。与现有的WSL方法相比,在同样的少量真实样本实验设置下,FoPro在真实场景下的泛化性能表现出色。
07
一种通用的粗-细视觉Transformer加速方案
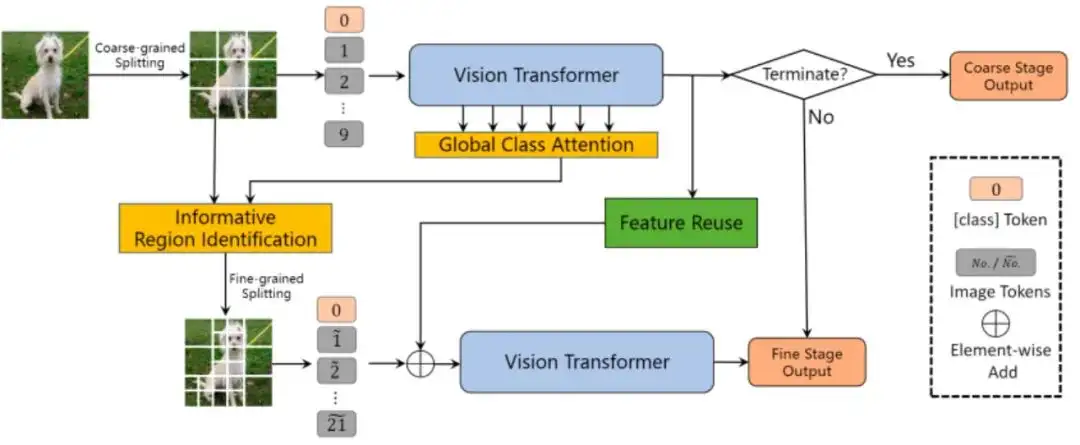
CF-ViT: A General Coarse-to-Fine Method for Vision Transformer
*本文由腾讯优图实验室和厦门大学共同完成
Vision Transformers (ViTs)的核心操作是self-attention,而self-attention的计算复杂度和输入token数目的平方成正比,因此压缩ViT计算量最直接的思路就是减少推理时的token数目,也即减少图像划分的patch数目。
本文通过两阶段自适应推理减少推理过程的token数目:第一阶段将图像划分为粗粒度(大尺寸)patch,目的是使用较少的计算量识别“简单”样本;第二阶段将第一阶段中信息量高的粗粒度patch进一步划分成细粒度(小尺寸)patch,目的是使用较少的计算量识别“困难”样本。
本文还设计了全局注意力用于识别信息量高的粗粒度patch,以及特征复用机制用于增大两阶段推理的模型容量。在不影响Top-1 准确率的情况下,该方法在ImageNet-1k上将LV-ViT-S的FLOPs降低53%, GPU上实测推理速度也加快了2倍。
08
通过视觉语言知识蒸馏的端到端人-物交互检测
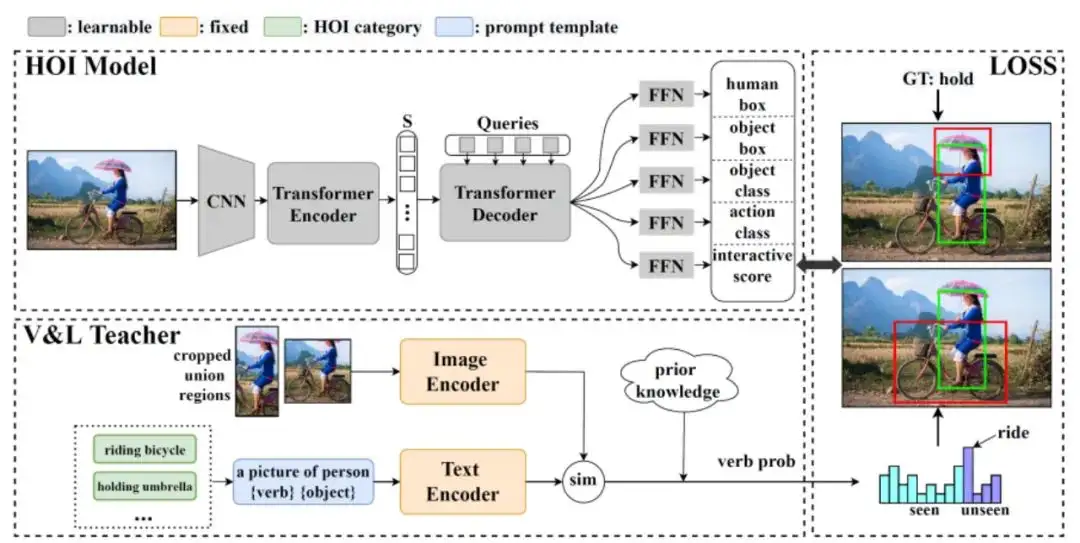
End-to-End Zero-Shot HOI Detection via Vision and Language Knowledge Distillation
大多数现有的人-物交互检测方法严重依赖于具有预定义人-物交互类别的完整标注,这在多样性方面受到限制,并且进一步扩展成本高昂。我们的目标是推进零样本人-物交互检测,以同时检测可见和不可见人-物交互。基本的挑战是发现潜在的人-物对并识别新的人-物交互类别。为了克服上述挑战,我们提出了一种新的基于视觉语言知识提取的端到端零样本人-物交互检测框架。
我们首先设计了一个交互式评分模块,该模块与两阶段二部分匹配算法相结合,以动作不可知的方式实现对人-物对的交互区分。然后,我们将来自预训练的视觉语言教师的动作概率分布以及所看到的真相标注转移到人-物交互检测模型,以实现零样本人-物交互分类。在HICO Det数据集上的大量实验表明,我们的模型发现了潜在的交互对,并能够识别未知的人-物交互。最后,在各种零样本设置下,我们的方法优于先前的优秀方法。此外,我们的方法可推广到大规模目标检测数据,以进一步放大动作集。
09
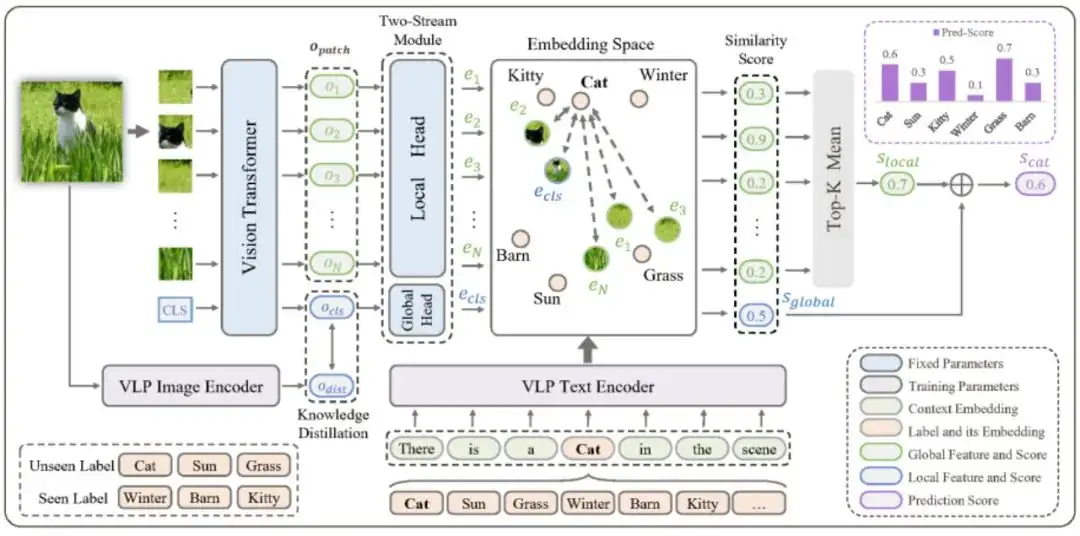
基于多模态知识迁移的开放词典多标签学习
Open-Vocabulary Multi-Label Classification via Multi-modal Knowledge Transfer
分类模型在实际应用中不可避免的会遇到大量在训练集中未出现的标签。为了识别这些标签,传统的多标签零样本学习方法通过引入语言模型(如GloVe)来实现从训练集可见标签到训练集不可见标签的知识迁移。单模态的语言模型虽然很好地建模了标签之间的语义一致性,但忽视了图像分类中关键的视觉一致性信息。
近来,基于图文预训练模型的开放词典(Open-Vocabulary)分类模型在单标签零样本学习上取得了令人印象深刻的效果,但如何将这种能力迁移到多标签场景仍是亟待探索的问题。
在本文中,作者提出了一种基于多模态知识迁移(Multi-modal Knowledge Transfer, MKT)的框架实现了多标签的开放词典分类。具体的,作者基于图文预训练模型强大的图文匹配能力实现标签预测。为了优化标签映射和提升图像-标签映射的一致性,作者引入了提示学习(Prompt-Tuning)和知识蒸馏(Knowledge Distillation)。
同时,作者提出了一个简单但是有效的双流模块来同时捕捉局部和全局特征,提高了模型的多标签识别能力。在NUS-WIDE和OpenImage两个公开数据集上的实验结果表明,该方法有效实现了多标签的开放集合学习。
10
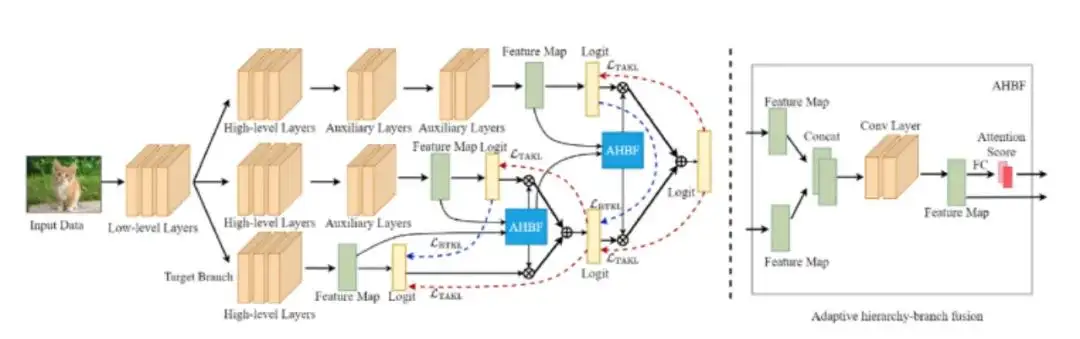
基于自适应层级分支融合的在线知识蒸馏算法摘要
Adaptive Hierarchy-Branch Fusion for Online Knowledge Distillation
*本文由腾讯优图实验室与华东师范大学共同完成
在线知识蒸馏无需使用预训练教师模型进行知识蒸馏,大大提高了知识蒸馏的灵活性。现有方法主要侧重于提高多个学生分支集成后的预测精度,往往忽略了使学生模型快速过拟合并损害性能的同质化问题。该问题来源于使用相同的分支架构和粗糙的分支集成策略。为了缓解此问题,在本文中提出了一种用于在线知识蒸馏的新型自适应层级分支融合框架,简称为AHBF-OKD。
该框架主要设计了层级分支结构和自适应层级分支融合模块来提高模型多样性,从而使不同分支的知识能够互补。特别地,为了有效地将知识从最复杂的分支转移到最简单的目标分支,本文提出了一种自适应层级分支融合模块来递归地创建层级间的辅助教师模块。在训练过程中,来自高层的辅助教师模块内的知识被有效地蒸馏给当前层次结构中的辅助教师模块和学生分支。因此,不同分支的重要性系数被自适应地分配以减少分支同质化。
大量实验验证了AHBF-OKD 在不同数据集上的有效性,包括 CIFAR-10/100 和 ImageNet 2012。例如,经过蒸馏的ResNet18 在 ImageNet 2012 上达到了29.28%的Top-1错误率。
11
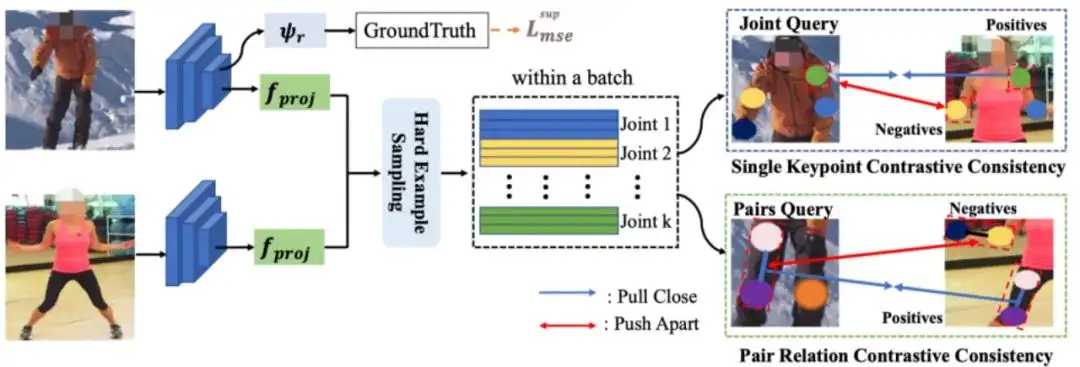
基于图像间一致性的多人姿态估计方法
Inter-image Contrastive Consistency for Multi-person Pose estimation
近年来,多人姿态估计(MPPE)取得了令人瞩目的进展。然而,由于遮挡或者人体之间的外观差异很大,模型很难学习一致的关键点表征。本篇论文中,我们提出了图像间对比一致性方法,来加强 MPPE任务中图像之间的关键点特征的一致性。
具体来说,我们考虑双重一致性约束,包括单关键点对比一致性(SKCC)和成对关键点对比一致性(PRCC)。SKCC用来加强图像中同类别关键点的一致性,从而提高特定类别的鲁棒性。虽然 SKCC能使模型有效减少由于外观变化引起的定位错误,但由于缺乏关键点结构关系指导,在极端姿势(例如遮挡)下仍然具有挑战性。因此,我们提出PRCC来加强图像之间成对关键点关系的一致性。PRCC 与 SKCC 合作,进一步提高了模型在处理极端姿势时的能力。
在三个数据集(即 MS-COCO、MPII、CrowdPose)上的广泛实验表明,所提出的 ICON 比基线取得了较大的改进。
12
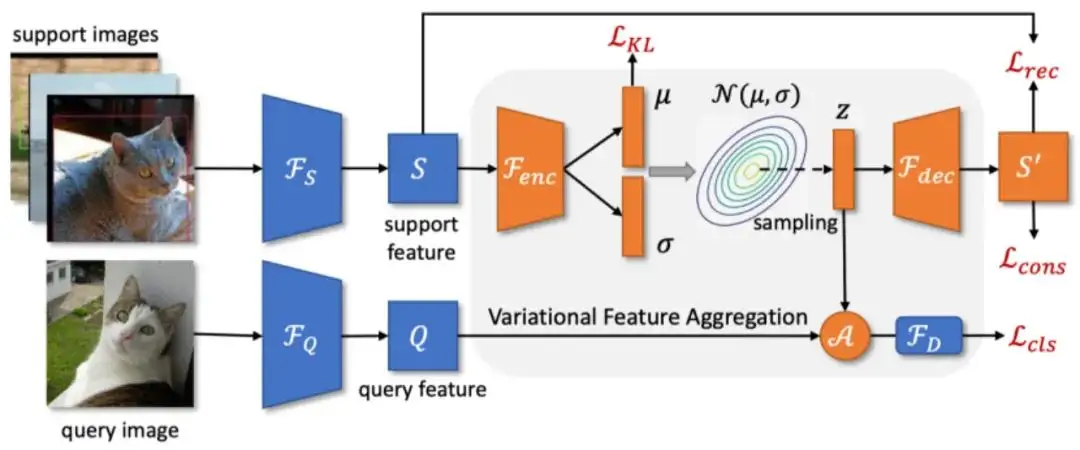
基于变分特征融合的少样本目标检测模型
Few-Shot Object Detection via Variational Feature Aggregation
由于少样本目标检测器通常在样本较多的基础类进行训练,并在样本较少的新颖类上进行微调,其学习到的模型通常偏向于基础类,并且对新颖类样本的方差敏感。为了解决这个问题,本文提出了基于元学习框架的两种特征聚合算法。
具体来说,本文首先提出了一种类别无关的特征聚合算法CAA,其通过聚合不同类别的查询(Query)和支持(Support)特征,使得模型学习到类别无关的特征表示,并减少了基础类与新颖类之间的混淆。
基于 CAA,本文又提出了变分特征聚合算法VFA,其通过将样本编码为类别的分布,实现了更加鲁棒的特征聚合。本文使用了变分自动编码器(VAE)来估计类别的分布,并从对样本方差更鲁棒的分布中抽样变分特征。
此外,本文解耦了分类和回归任务,以便在不影响目标定位的情况下,在分类分支上进行特征聚合。
13
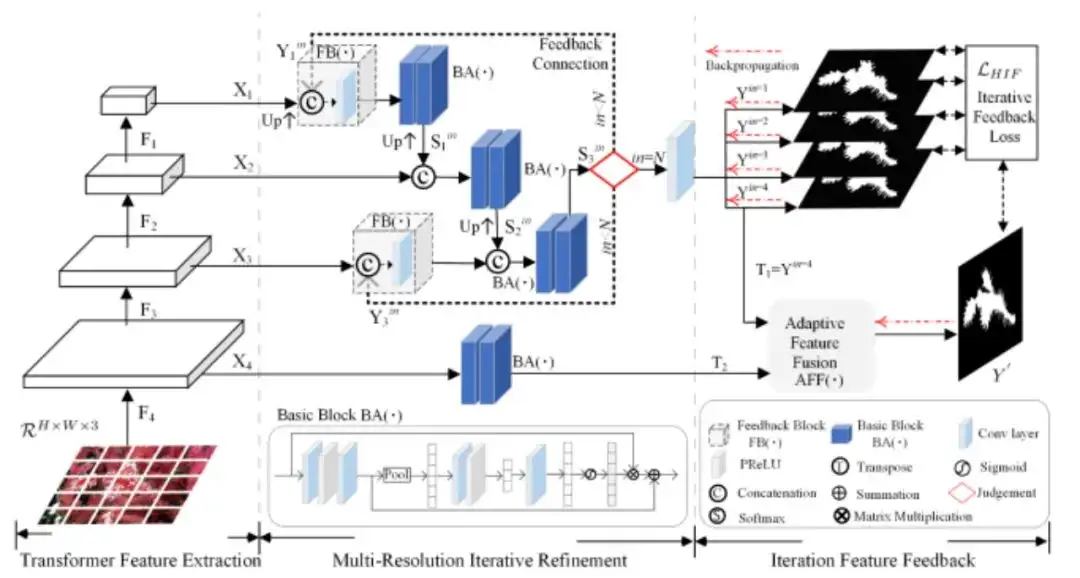
用于伪装物体分割的高分辨率迭代反馈网络
High-resolution Iterative Feedback Network for Camouflaged Object Detection
发现视觉同化到背景中的伪装对象对于物体检测算法和人类来说都是棘手的问题。因为两者都容易被前景对象与背景环境之间完美的内在相似性所迷惑或欺骗。
为了应对这一挑战,我们提取高分辨率纹理细节,以避免细节退化,因为这种细节退化会导致边缘和边界视觉模糊效应。我们引入了一种新颖的HitNet 网络框架,以迭代反馈方式通过高分辨率特征改进低分辨率表征,其实质是多尺度分辨率之间基于全局循环的特征交互。
另外,为了设计更好的反馈特征流并避免由递归路径引起的特征崩塌,我们提出了一种迭代反馈策略,以对每个反馈连接施加更多约束。
在四个具有挑战性的数据集上进行的大量实验表明,与 35 种先进的方法相比,我们的 HitNet 打破了性能瓶颈并取得了显着改进。此外,为了解决伪装场景中数据稀缺的问题,我们提供了一个将显着物体转换为伪装物体的应用程序,从而从不同的显着物体中生成更多的伪装训练样本,代码将公开。
14
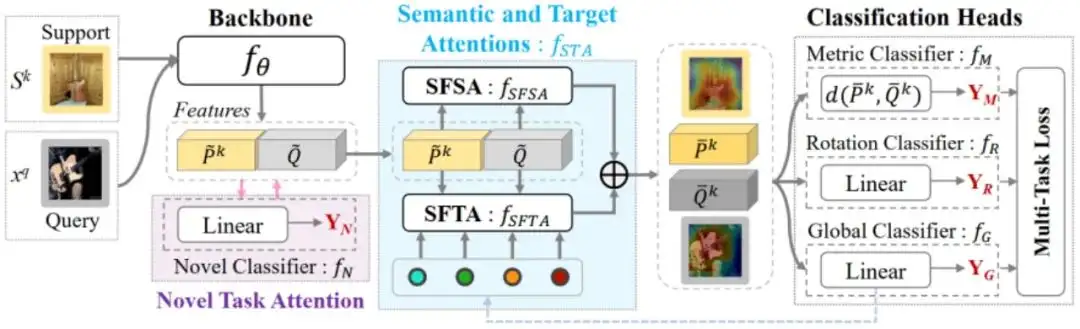
SpatialFormer: 基于语义和目标感知注意力的小样本学习方法
SpatialFormer: Semantic and Target Aware Attentions for Few-Shot Learning
最近的小样本学习方法强调生成强区分性的嵌入特征,以准确计算支持集和查询集之间的相似性。当前基于 CNN 的cross-attention方法通过增强支持和查询图像对的相互语义相似区域来生成更有区分性的特征。然而,它存在两个问题:CNN 结构基于局部特征产生不准确的注意力图,以及互为相似的背景导致干扰。
为了缓解这些问题,我们设计了一种新颖的SpatialFormer结构,以基于全局特征生成更准确的注意力区域。传统的 Transformer 建模内在实例级相似性导致小样本分类准确率下降,而我们的SpatialFormer探索了对输入之间的语义级相似性以提高性能。
然后,我们提出两个注意模块,称为 SpatialFormer Semantic Attention (SFSA) 和 SpatialFormer Target Attention (SFTA),以增强目标对象区域,同时减少背景干扰。其中,SFSA 突出了对特征之间具有相同语义信息的区域,而 SFTA 找到了与基本类别相似的新特征的潜在前景对象区域。
大量实验证明了我们方法的有效性,并且我们在多个基准数据集上取得了更优的性能。
15
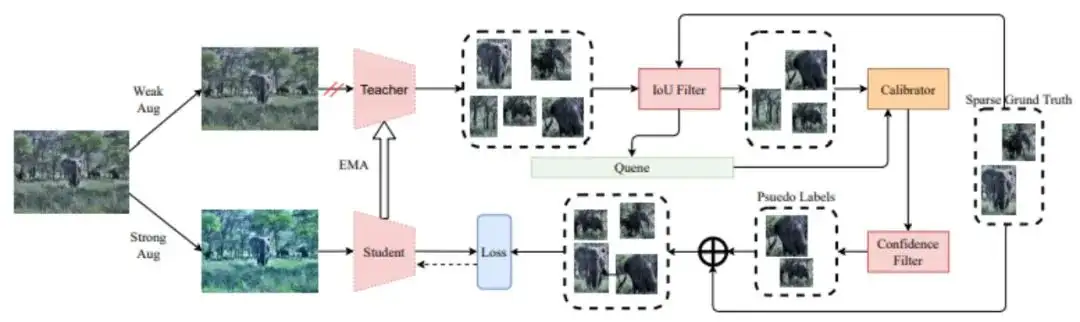
基于校正教师模型的稀疏标注目标检测
Calibrated Teacher for Sparsely Annotated Object Detection
完全监督的目标检测需要标注训练图像中的所有目标实例,但这需要大量的标注人力成本,同时在标注中往往存在有不可避免的漏标。图像中漏标的目标将会提供误导性的监督并损害模型训练,为此我们研究稀疏标注的目标检测方法,通过为遗漏的目标生成伪标签来减轻此问题。
早期的稀疏标注目标检测方法往往依赖于预设的得分阈值来筛选漏标框,但是在不同的训练阶段,不同的目标类别,以及不同目标检测器中,其有效阈值是不同的。因此,具有固定阈值的已有方法仍存在优化空间,并且需要针对不同的检测器繁琐地调整超参数。
为了解决这一障碍,我们提出了一个"校准教师模型",其中对预测的置信度估计经过得分校准,使其符合检测器的实际精度。从而,针对不同训练阶段以及不同检测器将具有相似的输出置信度分布,因此多个检测器可以共享相同的固定阈值并实现更好的性能。
此外,我们提出了一个简单但有效的FIoU机制,以降低因漏失标注而引起的假阴性目标的分类损失权重。
广泛的实验表明,我们的方法在12种不同的稀疏标注目标检测设置下达到了最优的性能。
16
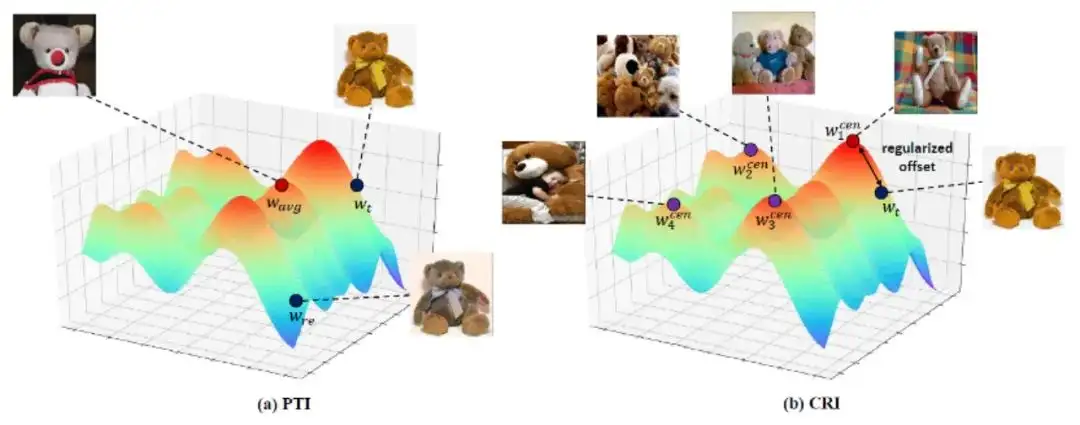
基于大规模通用数据集的退化图像高分辨率GAN反演方法
High-Resolution GAN Inversion for Degraded Images in Large Diverse Datasets
在过去的几十年里,大量的、多样化的图像数据显示出越来越高的分辨率和质量。然而,我们获得的一些图像可能受到多种退化,影响了感知和下游任务的应用。我们需要一种通用的方法从退化的图像中生成高质量的图像。在本文中,我们提出了一个新的框架,利用StyleGAN-XL的强大生成能力进行反演来解决上述问题。
为了缓解StyleGAN-XL在反演时遇到的挑战,我们提出了聚类正则反演(CRI):(1)通过聚类将庞大且复杂的隐空间划分为多个子空间,并为反演过程找到更优的初始化起点,从而降低优化难度。(2)利用GAN网络隐空间的特性,在反演过程中引入带有正则化项的偏移量,将隐向量约束在能生成高质量图像的隐空间内。
我们在复杂的自然图像的多种修复任务(补全、上色和超分辨率)上验证了我们的CRI方案,在定量和定性方面都获得了较好的结果。我们进一步证明了CRI针对不同数据和不同的GAN模型是鲁棒的。
就我们所知,本文是首个采用StyleGAN-XL从受退化的自然图像中生成高质量图像的工作。
注:以上数据均为实验室数据
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
原来Transformer就是一种图神经网络,这个概念你清楚吗?
TensorRT教程(六)使用Python和C++部署YOLOv5的TensorRT模型
姿态估计端到端新方案 | DirectMHP:用于全范围角度2D多人头部姿势估计
用于超大图像的训练策略:Patch Gradient Descent
CV小知识讨论与分析(5)到底什么是Latent Space?
CVPR 2023 Workshop | 首个大规模视频全景分割比赛
如何更好地应对下游小样本图像数据?不平衡数据集的建模的技巧和策
用少于256KB内存实现边缘训练,开销不到PyTorch千分之一

 浙公网安备 33010602011771号
浙公网安备 33010602011771号