
3D目标检测中点云的稀疏性问题及解决方案
前言 针对点云稀疏性带来3D目标检测上的困难,涌现了一系列方法来缓解该问题,包括多模态数据融合、点云下采样方法的改进、基于知识蒸馏的特征学习和点云补全等。下面,本文将对当前研究较多的解决点云稀疏性的方法进行汇总和总结,希望可以给大家带来一些启发。
本文转载自自动驾驶之心
作者 | 贫困人口
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
1. 点云稀疏性的定义
点云的稀疏性指激光雷达的采样点覆盖相对于场景的尺度来讲,具有很强的稀疏性。例如,将目前主流的户外3D目标检测数据集KITTI[1]的点云投影到对应的RGB图像上,大约只有3%的像素才有对应的点云;VoxelNet[2]将获取的点云等间距的划分到体素空间,超过90%的体素是空的。稀疏性产生的原因包括远距离、遮挡和反光等。
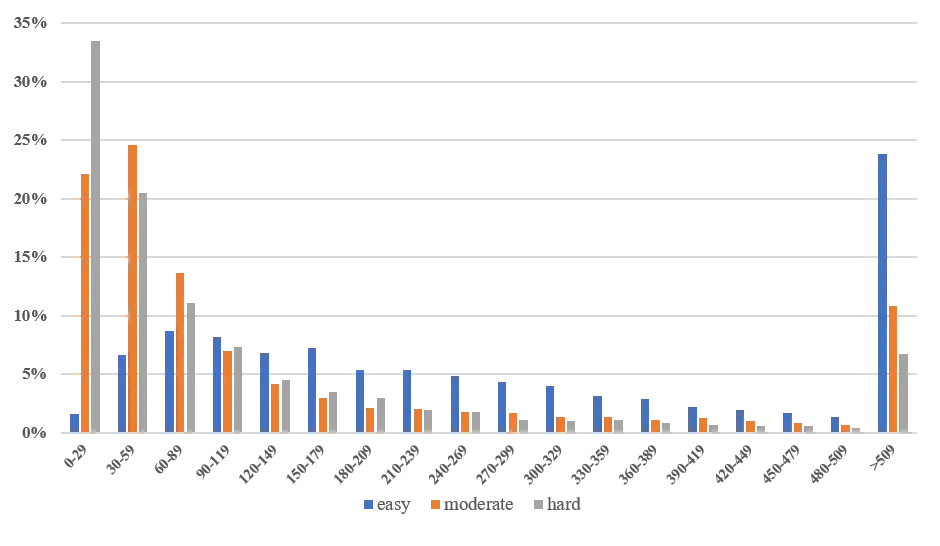
仍然以KITTI数据集为例,KITTI数据集将不同目标的检测难度划分为"Easy"、"Moderate"和"Hard"三类,我们统计了KITTI数据集中不同难度GT框内的点云数目分布情况,如下图所示,可以看出,"Moderate"和"Hard"目标中分别有超过47%和54%的点云数少于60个points,其对应的形状和结构是极其不完整的,进而给3D目标检测带来困难。
2. 点云稀疏性给3D目标检测带来的难点
2.1 待检测目标形状不完整,语义信息缺失
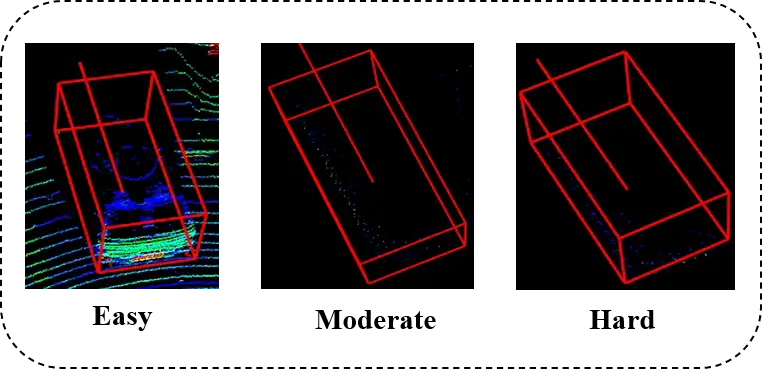
对于远距离或者遮挡的目标,点云密度随着距离增大而减小,当距离增大或者发生遮挡时,获取的目标点云很少,导致目标的结构信息和语义信息不完整。如下图所示,我们可视化了KITTI数据集中的”Car“目标在真实场景中的点云情况,可以看出:Easy难度目标的可视化形状是比较完整的,这类目标便于网络检出,SOTA方法的检测精度可以达到90%左右;而Moderate和Hard难度目标的可视化形状缺失比较严重,目标的结构信息和语义信息不完整,这类目标的检测精度较低。
2.2 待检测目标容易与背景混淆,造成误检
对于远距离目标,传感器获取的目标点云较少,在这种情况下,待检测目标可能与场景中的背景混淆,造成误检。
如下图所示,待检测目标"Pedestrian"和直杆(背景)距离传感器25米,获取的点云稀疏,几乎呈现相同的几何形状。这种相似的几何表示给检测带来困难。

2.3 待检测目标的点云相较场景点云占比少
相较于整个场景点云,待检测目标的点云的占比较少。PV-RCNN[3]指出在KITTI数据集中,待检测目标的点云(point of interest)的个数大约为2K,而整体场景的点云个数大约为15K;这种差距在后续的点云下采样过程可能会进一步扩大,进而导致可用的前景点特征少,导致检测精度降低。
3. 点云稀疏性的解决方案
针对点云稀疏性带来3D目标检测上的困难,涌现了一系列方法来缓解该问题,包括多模态数据融合、点云下采样方法的改进、基于知识蒸馏的特征学习和点云补全等。下面,本文将对当前研究较多的解决点云稀疏性的方法进行汇总和总结,希望可以给大家带来一些启发。
3.1 改进点云下采样方法
整个场景的点云数很多,且背景点占比较大,将整个场景的点云全部送入网络提取特征会极大的增大计算量,不能保证实时性。因此,现有的基于点云的3D目标检测方法会先对场景点云进行下采样,再将下采样后的点云送入网络提取特征和检测。例如PointRCNN[4]在处理KITTI数据时,会先将场景点云随机下采样到16384个,再处理这16384个点云,用于特征提取和检测。
但是,由于前景点在整个场景中占比较少,随机下采样点云可能会导致前景点的占比进一步较少,加剧前景点的稀疏性问题,降低检测精度。因此,一些工作提出基于特征或基于语义感知的下采样等方法来缓解该问题。
论文标题:3DSSD: Point-based 3D Single Stage Object Detector (2020CVPR oral)
论文地址:https://arxiv.org/pdf/2002.10187.pdf
作者单位:Zetong Yang等,港中文和港科技
核心思想:作者首先分析了基于点云的二阶段3D检测网络,第一部分利用SA层下采样和提取点云的语义特征,FP层用于上采样,并将特征广播到下采样期间所丢弃的点,再利用3D RPN生成proposals;第二部分利用refinement模块进一步提高初始proposals的精度;而作者认为FP层和refinement模块耗时较多,可以移除;基于此,作者结合距离下采样和特征下采样,提出了一种融合的下采样策略,从而平衡前背景点数量,保证足够的前景点。
方法简述:
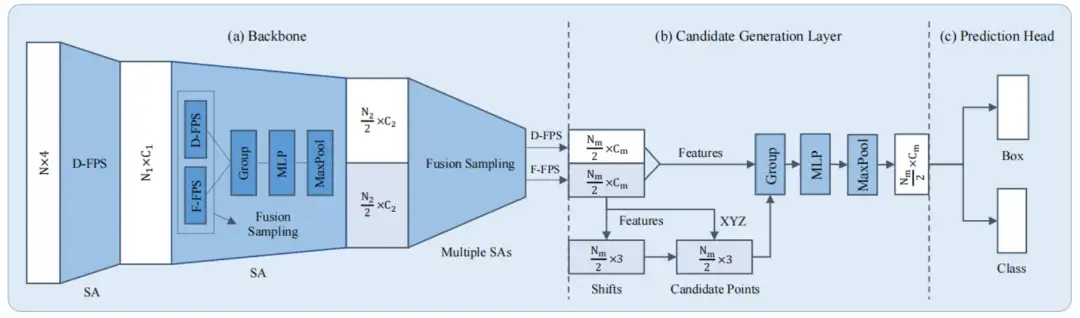
- 为了尽可能保留前景点,删除背景点,必须同时考虑距离信息和语义信息。而在深度学习框架中,很容易得到点云的语义信息,因此作者首先提出Feature-FPS(F-FPS),充分利用点云的特征信息进行下采样,以保留目标的前景点;同时,考虑到背景点囊括了周围的语义信息,有助于提升分类精度,因此进一步结合Distance-FPS(D-FPS),将距离信息考虑在内,提出了Fusion-FPS,进行场景点云下采样。分别采样N/2个点;
- 进一步提取采样点特征,送入CG层,对于边界框回归任务而言,背景点是无用的,因此仅使用F-FPS的点作为初始中心点,这些初始中心点在其相对位置的监督下移动到其相应的实例中,得到候选点。然后,将候选点当做CG层的中心点,再通过预先设置的阈值从F-FPS和D-FPS的集合点中找到他们的周围点,最后采用MLP提取它们的特征,这些特征用来预测最后的3D边界框。
- 该方法在保证实时性(25FPS)的同时,在KITTI数据集和nuscene数据集上取得了不错的精度。
论文标题:SASA: Semantics-Augmented Set Abstraction for Point-based 3D Object Detection (2022 AAAI)
论文地址:https://arxiv.org/pdf/2201.01976.pdf
作者单位:Chen Chen等,悉尼大学等
核心思想:现有的Set Abstraction通常以距离作为标准(如FPS),来选择较远的点来尽可能覆盖整个场景,但是这样会导致keypoints包含过多的背景点,从而导致pedestrian等点云数较少的object漏检。针对该问题,作者对PointNet++做了两处改进:增加一个前景背景点分割模块来识别前景点作为输入;提出S-FPS采样策略来选择关键点。
方法简述:

- 给定输入点云,先提取场景点云特征,再将其送入点云分割模块,进行前背景点分割(二分类网络,通过2层MLP实现),得到前景点分割得分;前背景点的标注信息通过3D标注的检测框可以直接得到,即检测框内的点为前景点,检测外的点为背景点;
- 利用S-FPS(Semantics-guided Farthest Point Sampling),综合考虑目标点的语义特征(分割得分)和距离信息,使得下采样过程中前景点的权重比背景点更大,更容易采样到前景点,将这部分前景点作为新的关键点,送入pointnet++提取更高维的特征,再送入已有的3D检测框架完成检测任务;
- S-FPS潜在划分前景目标出现的区域,有助于后续网络检出目标;此外,由于S-FPS是从分割得分最高的点开始下采样,对于点云的排列顺序不敏感;该方法在KITTI和nuscene数据集上取得了不错的精度。
3.2 基于知识蒸馏的特征迁移
对于现实场景中的点云,由于遮挡、远距离等原因,采集的点云是稀疏的,导致模型提取的特征不完整,不利于3D检测;但是,现实场目标存在某些共性特征,例如:车是对称物体,车都有四个轮子等,对于人类而言,我们只要看到目标的某个部分,我们就可以知道该目标的类别和大概的位置。因此,一些工作考虑通过知识蒸馏、迁移学习等方法,利用完整目标的完整特征指导真实场景中残缺目标的进行特征学习,或者将点云的深度信息引入到基于RGB图像的3D目标检测中。
论文标题:AGO-Net: Association-Guided 3D Point Cloud Object Detection Network (2022TPAMI)
论文地址:https://arxiv.org/pdf/2208.11658.pdf
作者单位:Liang Du等,复旦大学等
核心思想:作者将现实场景的不完整的稀疏点云定义为感知域,将对应场景补全的完整点云定义为概念域,通过孪生网络辅助稀疏点云从完整点云学习特征,从而生成更完整的特征,进行目标检测任务,且在测试阶段不会引入额外的计算。
方法简述:
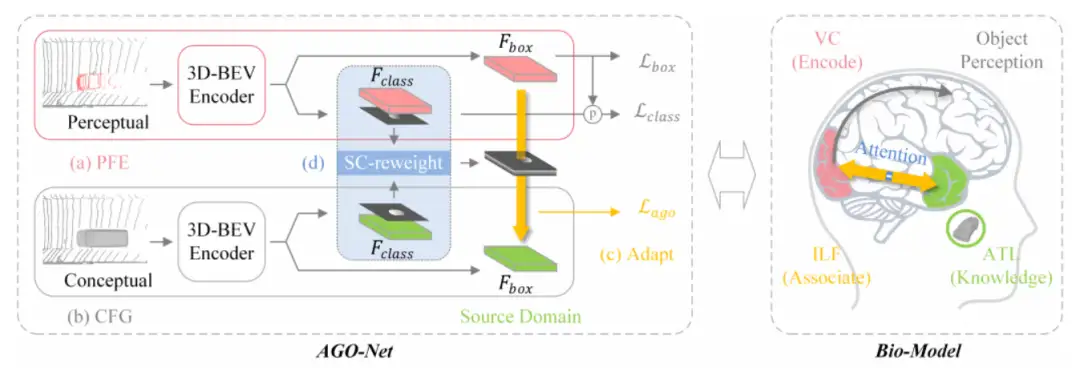
- AGO网络由一对孪生网络组成,包括PFE(perceptual feature encoder)和CFG(conceptual feature generator),可以采用已有的3D检测框架替换;以及SC-weight模块,辅助网络对加强场景的前景特征的学习;
- 首先,单独训练感知域的网络(CFG)。该网络的输入数据是真实场景的稀疏点云(上图中的Perceptual)补全后的完整点云(上图中的Conceptual),经过3D BEV encoder后得到的是完整的目标特征,该特征送入检测头可以得到接近100%的检测精度,当CFG训练完成后,冻结该网络,用于给后续PFE的训练提供完整且稳定的特征;
- 再训练整个AGO网络。具体而言,将真实场景的稀疏点云输入PFE,经过与CFG相同结构的3D BEV encoder,抽取特征;同时,补全后的点云输入已经训练过且冻结参数的CFG,用于产生完整的特征;再利用CFG产生的完整特征指导PFE进行特征学习,MSE损失函数作为约束函数,促使PEF产生完整的目标特征;此外,作者还引入SC-weight模块辅助PFE 更好的学习完整特征,该模块通过前景mask将前景特征抠出来,使得网络聚焦于前景特征的学习;
- 测试阶段,去除CFG模块,只留下PFE模块,在测试阶段不会增加额外的计算;而且,由于PFE模块在训练阶段有了CFG模块的指导,可以生成更完整的特征,因而可以取得不错的检测结果。
论文标题:MONODISTILL: LEARNING SPATIAL FEATURES FOR MONOCULAR 3D OBJECT DETECTION (2022 ICLR)
论文地址:https://arxiv.org/pdf/2201.10830.pdf
作者单位:Zhiyu Chong等,大连理工大学等
核心思想:基于单目图像的3D目标检测由于缺乏深度信息,其3D检测的性能一直差强人意;因此,作者考虑通过teacher-student框架,将点云的深度信息(spatial cues)引入到单目图像的3D目标检测网络,提升检测精度;对于点云和RGB图像不同的特征表示,作者将点云投影到图像平面,进行特征对齐。
方法简述:
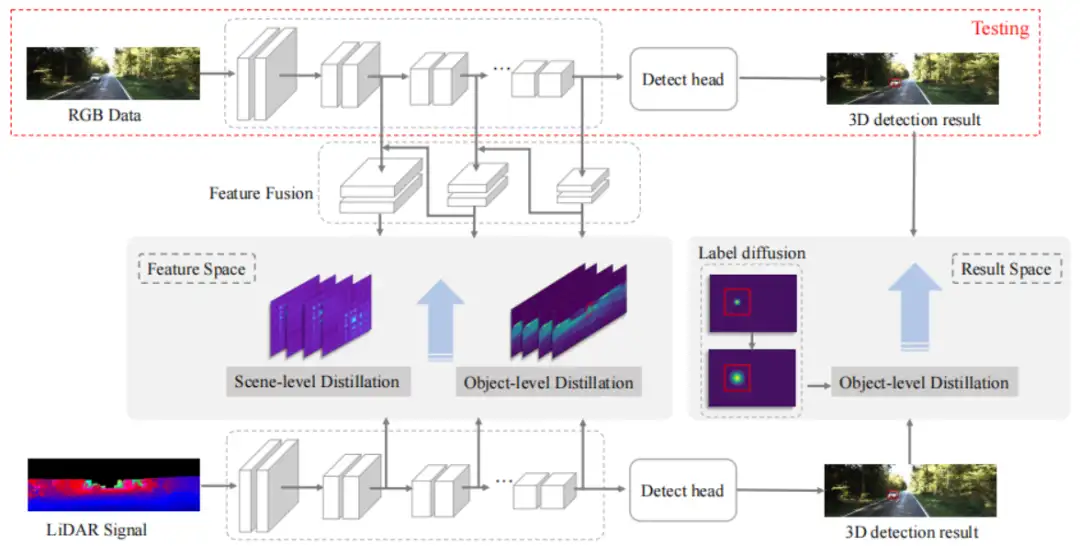
- 基于单目图像的3D检测模块(即student网络):首先,将单目图像输入到已有的3D目标检测框架,提取RGB图像特征,具体而言,采用DLA-34 作为 backbone,一些并行的 heads 用于预3d 目标检测,
- 基于点云的3D检测模块(即teacher网络):为了保证点云和RGB图像的特征的一致性,使用和student一样的模型结构,只是将输入换成深度补全后的点云深度图,即先将点云输入投影到RGB图像平面,得到sparse深度图,再利用插值算法得到dense深度图,将其输入到与student相同的3D目标检测网络,提取“点云”特征,该网络作为teacher网络;
- 作者进一步在特征层面和结果层面提出scene-level、object-level知识蒸馏,以帮助student网络更好的从teacher学习到点云的深度信息;
- 同样,在测试阶段,去除teacher网络,只保留student网络,没有引入额外的计算量;且没有改变原始的单目图像的3D检测框架。
3.3 多模态数据融合
基于多模态数据融合的3D目标检测主要指利用跨模态数据提升模型的检测精度。一般而言,多模态数据包含:图像数据、激光雷达数据、毫米波雷达数据、双目深度数据等,本文主要关注当前研究较多的图像+点云融合的3D目标检测模型。点云数据具备目标的几何信息和深度信息,但缺乏目标的颜色和纹理信息,而这些信息对于目标的识别分类十分重要;图像数据颜色和纹理信息丰富,但缺乏深度信息,不能很好的定位目标。因此,一些工作考虑结合二者数据的优点,进行3D目标检测任务。
论文标题:CLOCs: Camera-LiDAR Object Candidates Fusion for 3D Object Detection (2020 IROS)
论文地址:https://arxiv.org/pdf/2009.00784.pdf
作者单位:Su Pang等,Michigan State University
核心思想:作者认为,对于决策级的融合而言,多模态数据不需要与其他模态进行同步或对齐,且利用二者的检测结果排除了大部分冗余背景区域,因此更有助于网络学习;方法相对而言比较简单,CLOCs是利用检测结果进行的跨模态融合,属于决策级融合的范畴。
方法简述:
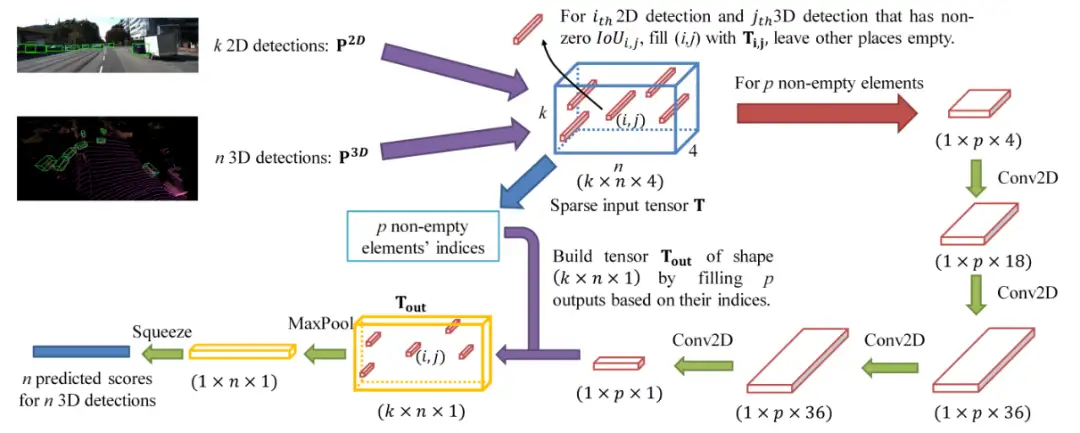
- 将RGB图像输入到已有的2D目标检测模型中,得到k个2D检测框,表示2D图像中潜在含有目标的区域;
- 同时将点云输入到已有的3D目标检测模型中,得到n个3D检测框,表示3D场景中潜在含有目标的区域;
- 对于2D和3D检测结果k和n,构建新的矩阵T,包括描述二者几何一致性的IoU(IoU=0的检测框直接去除)、2D检测框的置信度得分、3D检测框的置信度得分和3D检测框到地面的归一化距离d;
- 进一步对保留的候选框进行特征提取,得到最终的检测结果。
论文标题:Sparse Fuse Dense: Towards High Quality 3D Detection with Depth Completion (2022CVPR)
论文地址:https://arxiv.org/pdf/2203.09780.pdf
作者单位:Xiaopei Wu等,Zhejiang University
核心思想:作者认为目前户外点云+图像的方法没有纯点云的方法效果好的原因包括2个,(1)多模态的数据增广困难以及(2)现在方法大多是从点云找对应的图像融合特征,但是点云能对应上的像素点比较少,没有完全利用好图像的特征。因此,作者考虑多模态特征加权融合,以及跨模态对齐问题;SFD利用的是3D场景预测出的候选框,并在不同模态数据上进行特征提取,因此属于RoI-level的融合范畴
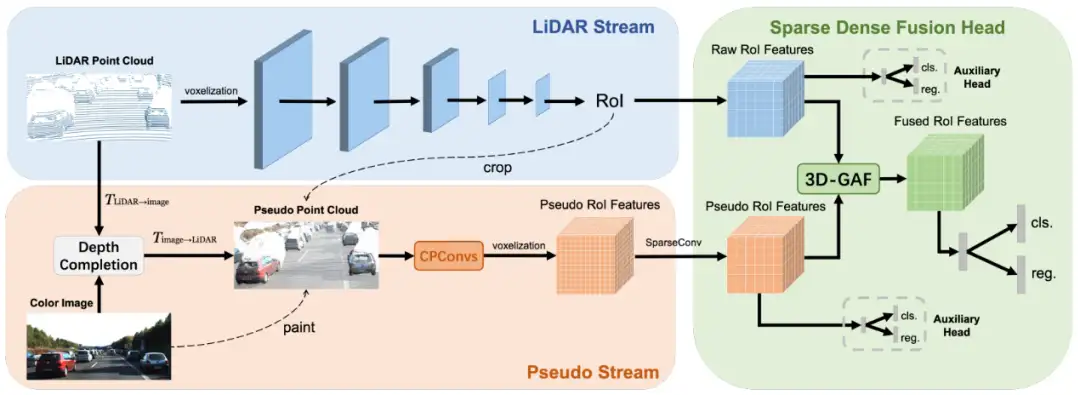
方法简述:
- 先利用深度补全网络,将原始RGB图像映射到3D场景中,对图像上的像素点进行深度补全,在KITTI数据集上预训练后再训练目标检测网络时不再改变参数,进一步生成伪点云;补全后的点云就由sparse变为dense了,且每个像素都有了对应的点云;
- 再利用dense且包含颜色信息的伪点云进行特征提取,再和原始点云特征融合,进一步生成候选框;
- 在fusion模块,对每一个候选框,分别提取点云特征和伪点云特征;对点云特征和伪点云特征,利用attention进行重新加权,并输出最后的检测结果;
- 此外,作者还提出了一种适用于多模态的数据增强方法SynAugment,包括Manipulate Images like Point Clouds(多模态数据增强的最大挑战是如何处理像点云这样的图像。作者通过深度补全的方法,将2D图像转换为伪点云,此时伪点云承载了图像的所有信息,然后像处理原始点云一样处理伪点云),和Extract Image Features in 3D Space(即将2D图像转化为伪点云,然后在3D空间中提取伪点云特征)
论文标题:Pointpainting: Sequential Fusion for 3D Object Detection (2020CVPR)
论文地址:https://arxiv.org/pdf/1911.10150.pdf
作者单位:Sourabh Vora等,nuTonomy
核心思想:利用细粒度图像分割信息对3D点云进行补全,即将点云投影到图像语义分割网络的输出中,并将分类分数附加到每个点云上,从而增加点云的语义信息;
方法简述:
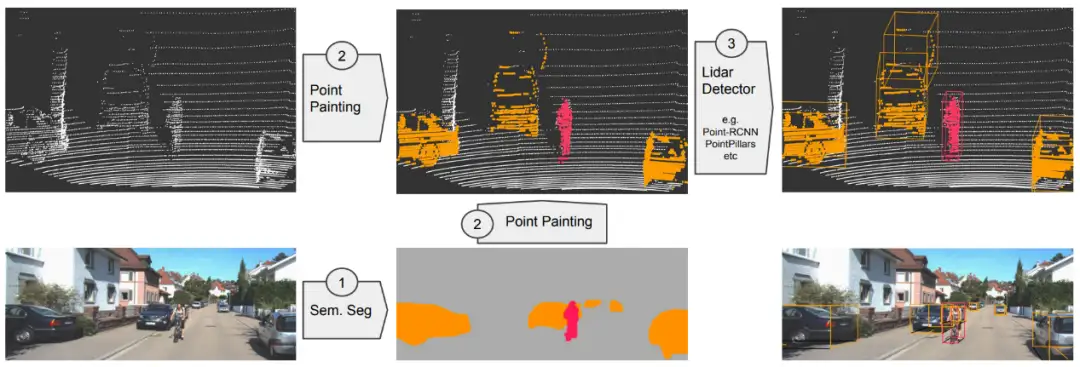
- 2D语义分割网络:使用一个基于图像的分割网络来计算pixel-wise分割分数;
- Painting/Fusion:将2D中预测出的分割结果投影到对应的3D point中,对原始3D信息进行补全;
- 3D目标检测:利用补全后的3D点云进行预测,不需要改变原始3D目标检测框架,只需要改变输入的维度即可,由N变为N+1;
3.4 点云补全
针对稀疏点云的目标,一些方法直接采用点云补全的方式,先将目标补充为较为完整的目标,再进行3D目标检测。
论文标题:Spatial information enhancement network for 3D object detection from point cloud (2022 PR)
论文地址:https://arxiv.org/pdf/2012.12397.pdf
作者单位:Ziyu Li等,东南大学等
核心思想:作者考虑到距离传感器远近目标中点云数量的不平衡的问题,即距离LiDAR较远的目标收集到的点数相对较少,作者认为网络是难以处理这种不平衡性;进而提出一种空间信息增强的模块,从稀疏的、不完整点云预测密集的、完整的空间表示,来缓解这种不平衡性。
方法简述:
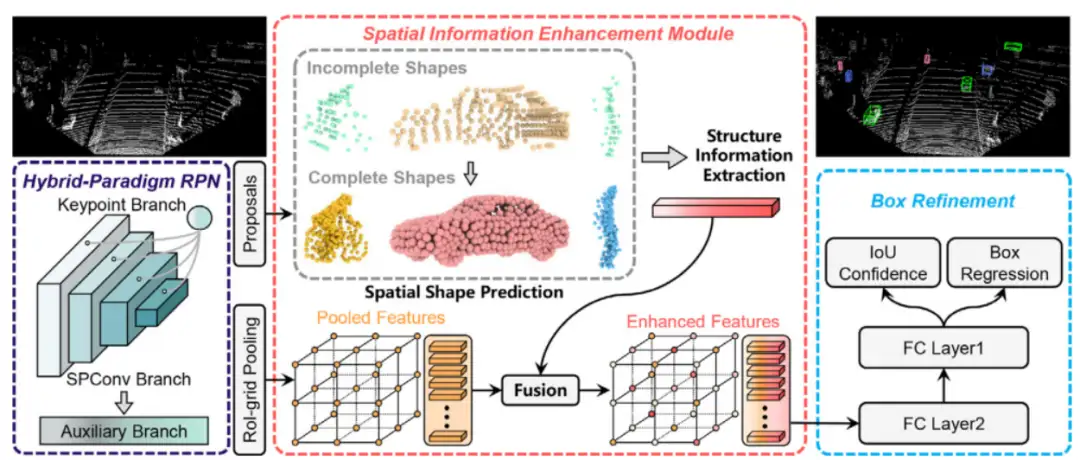
- RPN模块:首先,对输入点云体素化,使用SPConv卷积学习体素特征,然后Keypoint分支使用注意力机制动态编码体素特征,作者还提出一个辅助模块(将坐标转换为真实场景坐标,再使用PointNet++特征传播层进行插值,将每一块得到的特征进行结合用以学习结构信息)用于学习结构信息;
- Spatial information enhancement(SIE)模块:来预测完整的空间表示。首先,对于proposal中不完整的点云,将其输入到一个成熟的3D补全框架(如PCN[5]),来生成完整的目标形状;然后,对于预测的点云,使用FPS采用m个点云,利用pointnet++提出多尺度特征,再利用全连接层将其转化为全局特征;
- 特征融合和3D检测模块:将生成的全局特征与原始点云pooling后的特征进行加权融合,得到enhanced feature,进行检测任务,并在KITTI数据集上取得了目前最好的精度;
论文标题: Multimodal Virtual Point 3D Detection(2021 NeurIPS)
论文地址:https://arxiv.org/pdf/2111.06881.pdf
作者单位:Tianwei Yin等,UT Austin等
核心思想:作者结合实例分割网络,先对2D图像进行分割,利用分割结果生成虚拟点云,对原始场景补全,得到完整的目标进行3D检测。
方法简述:
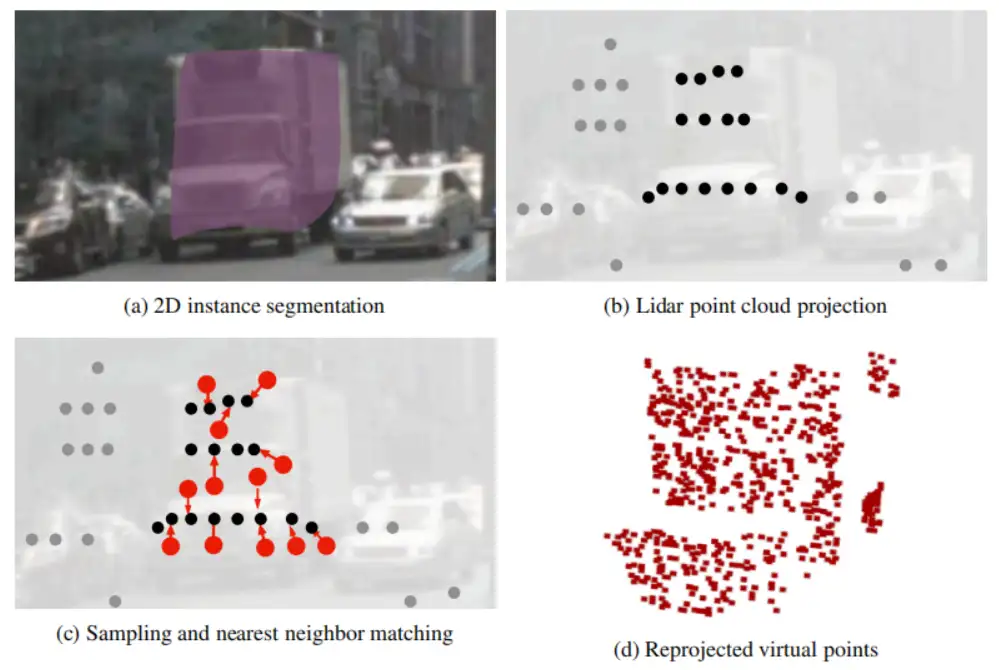
- 首先对2D图像进行实例分割,得到分割结果,本文采用的是CenterNet2作为实例分割网络;
- 再将点云投影到2D图像上,每个实例上都会有一些投影的点云,如(b)所示,mask内的点云为黑色,其余的点云为灰色;
- 根据前景区域内点云的深度信息生成虚拟点云,生成虚拟点的方法是在2D实例分割区域中进行随机采样K个点,根据周围点云的深度插值得到这K个点的深度值;
- 最后再将这K个点投影到点云坐标系,得到虚拟点云,达到了对原始场景补全的目的,再进行3D检测。
4. 参考文献
- A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? the KITTI vision benchmark suite,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2012, pp. 3354–3361.
- Zhou Y, Tuzel O. Voxelnet: End-to-end learning for point cloud based 3d object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 4490-4499.
- Shi S, Guo C, Jiang L, et al. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 10529-10538.
- S. Shi, X. Wang, and H. Li, “PointRCNN: 3D object proposal generation and detection from point cloud,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2019, pp. 770–779.
- W. Yuan, T. Khot, D. Held, C. Mertz, M. Hebert, PCN: point completion network, in: 3DV, 2018, pp. 728–737.
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
原来Transformer就是一种图神经网络,这个概念你清楚吗?
TensorRT教程(六)使用Python和C++部署YOLOv5的TensorRT模型
姿态估计端到端新方案 | DirectMHP:用于全范围角度2D多人头部姿势估计
用于超大图像的训练策略:Patch Gradient Descent
CV小知识讨论与分析(5)到底什么是Latent Space?
CVPR 2023 Workshop | 首个大规模视频全景分割比赛
如何更好地应对下游小样本图像数据?不平衡数据集的建模的技巧和策
用少于256KB内存实现边缘训练,开销不到PyTorch千分之一

 浙公网安备 33010602011771号
浙公网安备 33010602011771号