代码实战:YOLOv5实现钢材表面缺陷检测
前言 目前,基于机器视觉的表面缺陷已经在各个工业领域广泛取代人工视觉检测,包括3C、汽车、家电、机械制造、半导体电子、化工、制药、航空航天、轻工等行业。许多基于深度学习的缺陷检测方法也被广泛应用于各种工业场景。
本文的代码实战,是基于YOLOv5目标检测算法,在NEU表面缺陷数据集上实现钢材表面缺陷检测。要求Python>=3.7.0,PyTorch>=1.7。
本文转载自笑傲算法江湖
作者 | Ctrl CV
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
一、YOLOv5
选取YOLOv5,一方面是因为从最终效果来看YOLOv5已经相当优秀,是发展的比较完备、使用比较广泛的一个版本;而更重要的是YOLOv5的调用、训练和预测都十分方便,为初学者提供了良好的练手工具。YOLOv5的另一个特点就是它为不同的设备需求和不同的应用场景提供了大小和参数数量不同的网络。
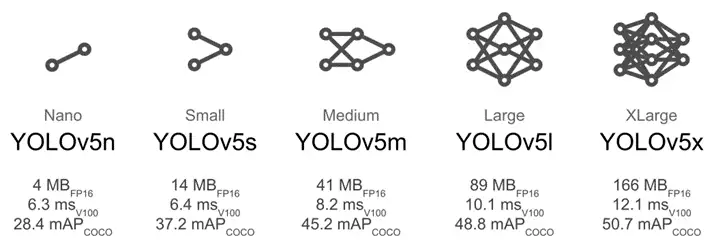
如图所示,大一点的模型比如YOLOv5l和YOLOv5x参数更多,在大规模的COCO数据集上有更高的预测准确率;而小模型比如YOLOv5n或YOLOv5s占空间更小,适合部署在移动设备上,且推理速度更快,适合于高帧 率视频的实时检测。
参考代码:https://github.com/ultralytics/yolov5
二、钢材表面缺陷数据集
东北大学(NEU)表面缺陷数据集,收集了热轧带钢6种典型的表面缺陷,即轧内垢(RS)、斑块(Pa)、裂纹(Cr)、点蚀面(PS)、夹杂物(In)和划痕(Sc)。该数据库包括1800张灰度图像:6种不同类型的典型表面缺陷各300个样本。
下图为6种典型表面缺陷的样本图像,每张图像的原始分辨率为200×200像素。从图中,我们可以清楚地观察到类内缺陷在外观上存在较大差异,例如划痕(最后一列)可能是水平划痕、垂直划痕和倾斜划痕等。与此同时,类间缺陷也具有相似的特征,如滚积垢、裂纹和坑状表面。此外,由于光照和材料变化的影响,类内缺陷图像的灰度会发生变化。总之,NEU表面缺陷数据库包含两个难题,即类内缺陷存在较大外观差异,类间缺陷具有相似方面,缺陷图像受到光照和材料变化的影响。

对于缺陷检测任务,数据集提供了标注,标注了每个图像中缺陷的类别和位置。下图展示了数据集上的一些检测结果示例。对于每个缺陷,黄色框是表示其位置的边界框,绿色标签是类分数。

数据地址:http://faculty.neu.edu.cn/songkechen/zh_CN/zdylm/263270/list/
三、YOLOv5数据格式
YOLOv5标签文件中每一行的数据为class, x, y, w, h,其中class是该物体的类别,x,y是检测框中心坐标,w,h是检测框的宽和高。
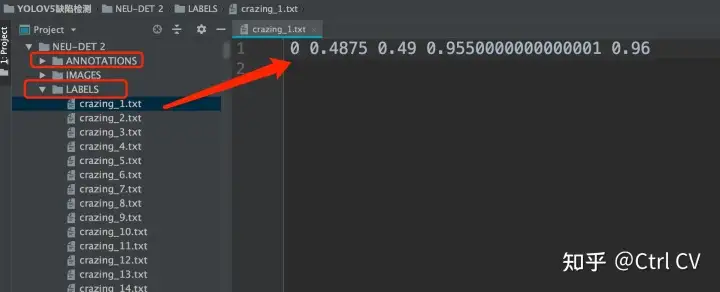
四、格式转换voc2yolo
从网上获取一些目标检测的数据集资源标签的格式都是VOC(xml格式)的,而YOLOv5训练所需要的文件格式是YOLO(txt格式)的,这里就需要对xml格式的标签文件转换为txt文件。同时训练自己的YOLOv5检测模型的时候,数据集需要划分为训练集和验证集。这里提供了一份代码将xml格式的标注文件转换为txt格式的标注文件,并按比例划分为训练集和验证集。
import xml.etree.ElementTree as ET
import os
from os import getcwd
from tqdm import tqdm
classes = ["crazing", "inclusion", "patches", "pitted_surface", "rolled-in_scale", "scratches"]
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = './xml/%s.xml' % (image_id)
out_file = open('./labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == "__main__":
wd = getcwd()
print(wd)
if not os.path.exists('./labels/'):
os.makedirs('./labels/')
image_ids = os.listdir('./datasets')
for image_id in tqdm(image_ids):
convert_annotation(image_id.split('.')[0])
五、训练
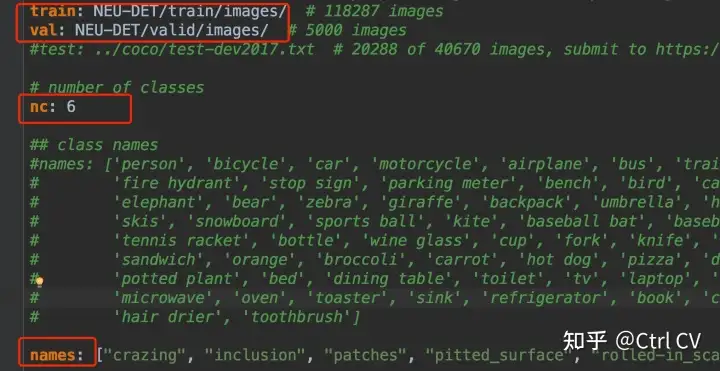
YOLOv5是通过yaml格式的配置文件来找到对应的训练测试数据,因此在训练前需要对该文件进行简单配置。我们可以通过修改YOLOv5的配置文件来实现,需要修改的配置文件有两个,我们先复制一份data/coco.yaml,这里将其重命名为my_coco.yaml
- 在
download前加上一个#注释掉这段代码 - 将
train、val、test修改为自己的路径,以train为例,NEU-DET/train/images/ - 将
nc修改为数据的类别数,如钢材表面缺陷,故修改为6 - 将
names修改自己数据的类名,如names: ["crazing", "inclusion", "patches", "pitted_surface", "rolled-in_scale", "scratches"]
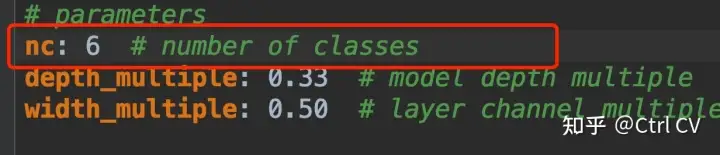
下一个需要修改的文件为模型配置文件,在models文件夹中有四个模型的配置文件:yolov5s.yaml、yolov5m.yaml、yolov5l.yaml和yolov5x.yaml,可以根据需要选择相应的模型,这里以yolo5s.yaml为例,打开文件,修改文件中的nc为自己的类别数即可。
python train.py --weights weights/yolov5s.pt --cfg models/yolov5s.yaml --data data/my_coco.yaml --epoch 30 --batch-size 32
六、测试
训练结束后,在runs/exp0文件夹下会自动生成训练结果,其中包括模型权重、混淆矩阵、PR曲线等。
进行测试时,打开detect.py文件,修改source为检测图片的文件夹,运行之后,在run->detect中输出检测结果;或者通过如下方式进行测试。
python detect.py --source ./data/images/example.jpg --weights runs/exp0/weights/best.pt --conf-thres 0.25


最终预测的结果如下,可以看出模型缺陷检测效果。

本文仅做学术分享,如有侵权,请联系删文。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
用于超大图像的训练策略:Patch Gradient Descent
CV小知识讨论与分析(5)到底什么是Latent Space?
CVPR 2023 Workshop | 首个大规模视频全景分割比赛
如何更好地应对下游小样本图像数据?不平衡数据集的建模的技巧和策
用少于256KB内存实现边缘训练,开销不到PyTorch千分之一
DAMO-YOLO | 超越所有YOLO,兼顾模型速度与精度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号