
TensorRT教程(六)使用Python和C++部署YOLOv5的TensorRT模型
前言 今天这里主要介绍使用Python部署TensorRT的模型以及使用C++部署TensorRT的模型这两种方法。其实在日常部署的工作中,更多是使用C++进行部署,因为这样可以更加丝滑地迁移到硬件上进行编译使用。
又因为我们一般是部署在Linux平台上,不管是服务器还是边缘设备,使用的系统大多都是Linux操作系统。因此在本文的前一小部分还会讲述如何在Linux进行cuda、cudnn、TensorRT的安装,来让大家在环境配置时少走一些弯路。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
本教程禁止转载。同时,本教程来自知识星球【CV技术指南】更多技术教程,可加入星球学习。
cuda环境配置
下载cuda
在官网 https://developer.nvidia.com/cuda-toolkit 选择合适的cuda进行安装。
安装
使用以下命令进行安装:sh cuda_11.0.2_450.51.05_linux.run,接下来会问你是否同意,你直接按Enter回车同意就可以了。
在安装的选项中,注意,除了不安装驱动,其他都选择安装。
环境变量设置
安装完毕后,回到终端打开~.bashrc,进行环境变量的设置:
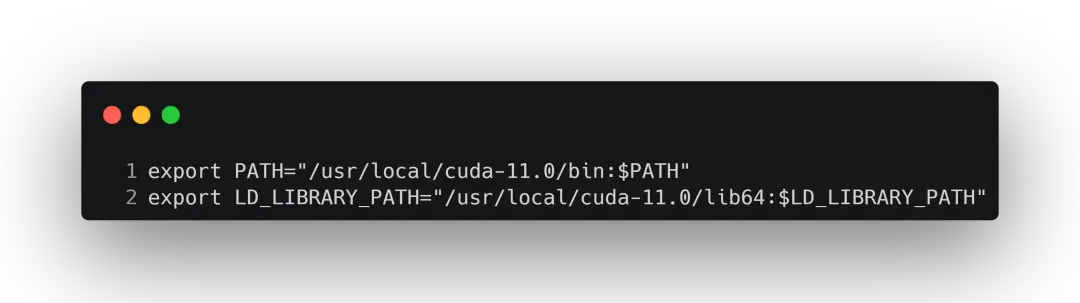
保存后退出,并激活环境变量 :source ~/.bashrc
验证
在终端上输入命令:nvcc -V,如果成功打印出版本信息,并且没有报错的话就证明安装成功。
cudnn环境配置
下载cudnn
去官网中下载符合你平台的cudnn:https://developer.nvidia.com/rdp/cudnn-archive
解压安装
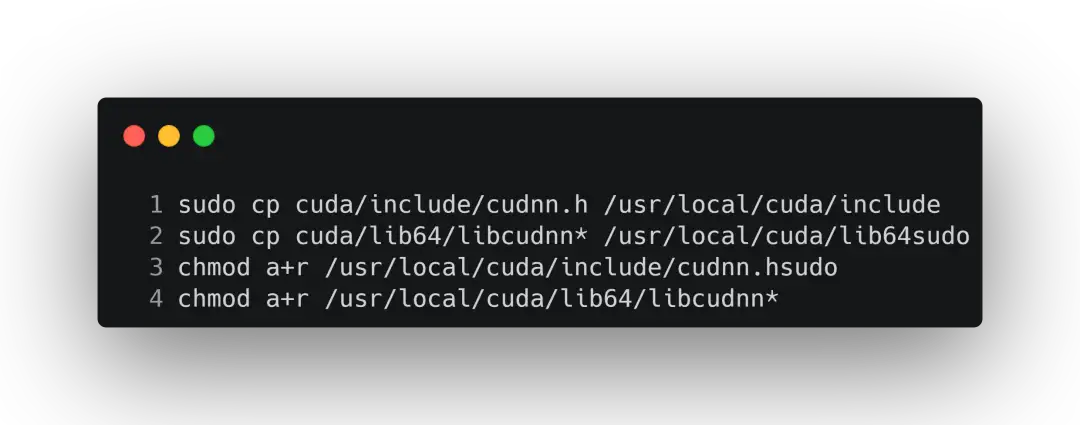
下载完之后就可以进行解压,解压完成后会得到一个cuda文件夹。解压命令如下:tar -zxvf cudnn-10.2-linux-x64-v8.0.3.33.tgz我们知道,下载了cudnn之后需要将里面的文件拷贝到cuda中。所以需要执行以下命令:
查看cudnn的版本
安装结束后查看cudnn的版本,来验证是否正确安装。
cat /usr/local/cuda-10.1/include/cudnn.h | grep CUDNN_MAJOR -A 2
TensorRT环境配置
下载TensorRT
第一步同样是下载。根据你的cuda版本和cudnn版本去TensorRT的官网 https://developer.nvidia.com/tensorrt 选择对应版本的安装包。
进行解压
解压命令如下:tar -zxvf TensorRT.tar.gz
环境变量设置
完成解压后依旧要添加到环境变量中:
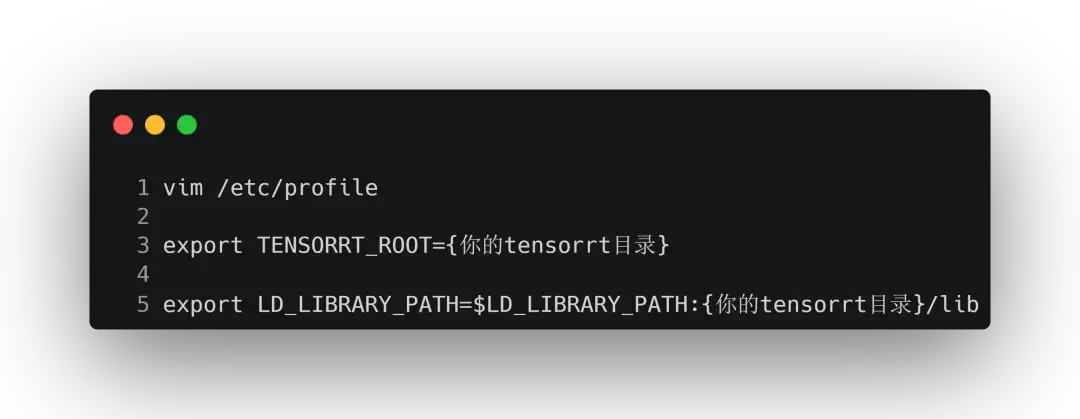
退出保存后:source /etc/profile
除了/etc/profile,也可以通过修改~/.bashrc来进行设置。
/etc/profile此文件为系统的每个用户设置环境信息,当第一个用户登录时,该文件被执行。而~/.bashrc:该文件包含专用于某个用户的bash shell的bash信息,当该用户登录时以及每次打开新的shell时,都会读取这个文件。
/etc/profile只会在用户登录时执行一次,并且在每次修改后都需要重新source来激活;而~/.bashrc在用户每次登录以及打开终端窗口时都会执行。
安装TensorRT下的whl
这里需要为Python安装运行TensorRT的必要包。
进入到tensorRT下的python文件夹,并根据python版本安装合适的包pip install tensorrt-8.2.1.8-cp38-none-linux_x86_64.whl
同时安装uff和graphsurgeon同样,tensorRT下有uff和graphsurgeon文件夹,分别安装两个文件夹下的安装包:
pip install uff-0.6.5-py2.py3-none-any.whl
pip install graphsurgeon-0.4.1-py2.py3-none-any.whl
测试
这里同样是使用mnist来进行测试。首先进入到data\mnist文件夹下,运行python download_pgms.py;
之后程序就会开始下载测试图片,然后通过samples/sampleMNIST下进行编译,最终生成可执行的文件。
步骤如下:
首先在 ./samples/sampleMNIST 目录下执行 make 命令,在 ./bin/ 目录下生成可执行文件。
然后在 ./ 目录下运行 ./bin/sample_mnist 。
程序运行成功后就会在 data\mnist下随机选取一张图进行预测。
除了以上的测试方法之外,你还可以在python中通过输入以下命令进行测试:
import tensorrt print(tensorrt.version)
如果可以正常打印出tensorrt的版本号,就说明安装无误了。
以上就是关于在Linux下,cuda、cudnn、TensorRT的环境配置了。如果是在Linux上的平台,最好的办法就是通过docker进行安装。这样可以少踩很多坑。详情可以查看TensorRT教程系列的第三篇:TensorRT的安装教程。
Python部署
使用TensorRT + Python的部署方式按照YOLOv5官方所提供的用例就没什么问题。
流程也是比较固定:先将pt模型转为onnx,再将onnx模型转为engine,所以在执行export.py时要将onnx、engine给到include。
PT模型转换为ONNX模型
python path/to/export.py --weights yolov5s.pt --include torchscript onnx coreml saved_model pb tflite tfjs
转换之后就会进行检查,看有没有算子是不支持的:onnx.checker.check_model(model_onnx) # check onnx model
ONNX 模型构建流程
在这里简单介绍下ONNX的构建流程:
- 根据网络结构使用make_node方法来创建相关节点,节点中 inputs 和 outputs 的参数决定了 graph 的连接情况;
- 利用定义好的节点然后使用 make_graph 来生成后面的计算图;
- 最后使用生成的计算图来构建模型;
- 检查模型,没有发生错误之后就可以进行保存。
ONNX导出的参数介绍
这里是通过torch.onnx.export进行导出:
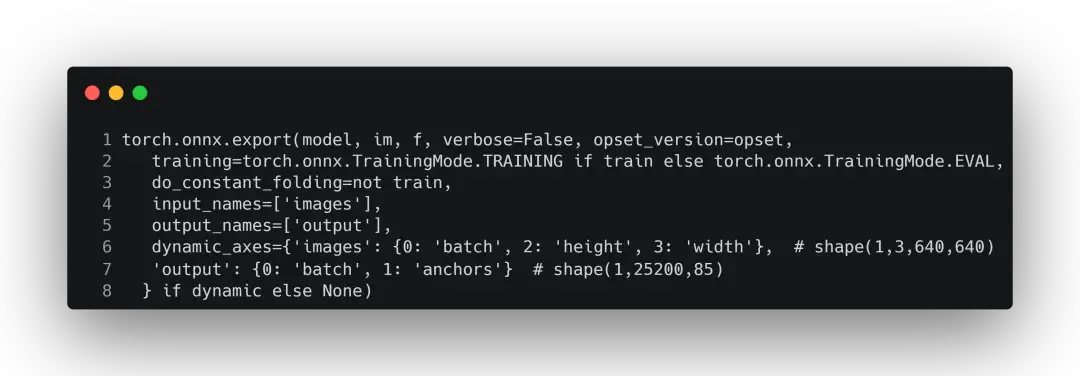
这里介绍一下其中每个参数的含义:
model:就是需要转为 ONNX 的源 pth 模型,只有源模型的结构和权重,才能转化为有效的 ONNX 模型。
args:支持单个参数或者多个参数。任何非变量参数将被硬编码到导出的模型中,按照它们在参数中出现的顺序,任何变量参数都将成为输出模型的输入。它指的是模型的输入,只要满足输入张量的 shape 正确就可以。因为对于导出来说,我们只需关心张量从输入到输出的所流经的路径是否就可以了,而不关心它的结果是否正确。一般来说这个是固定大小的。
f:导出 ONNX 的位置,指定好后就会在相应的地方保存好成功导出的 ONNX。
export_params:代表是否存储模型的权重,默认为 True,为 True 则将所有参数将被导出。因为与 pytorch 不同,pytorch 的模型结构和权重是可以存储在在同一文件里,也可以存储在不同文件中,但 ONNX 存储在一块的。ONNX 格式的权重文件,不仅包含了权重值,也包含了网络中每一层的输入输出信息以及其他辅助信息。
verbose:表示是否打印调试的信息。
traning:默认为False,如果指定为True,将在训练模式下导出模型。一般来说 ONNX 只是为了导出模型,所以一般都为False。
input_names:是模型的输入节点名称,如果不设置的话,会自动分配一些简单的数字作为名称。
output_names:是模型的输出节点名称,和上面一样。ONNX 是通过这些名称来获取输出数据的。
opset_version:默认为9,表示的是转换时是使用哪个 ONNX 算子集版本。如果版本过低,就不支持upsample 等操作。详情可看 https://github.com/onnx/onnx/blob/main/docs/Operators.md
do_constant_folding:表示常量折叠优化,默认为 False。如果为 True,则在导出时进行常量折叠优化。常量折叠优化将用预先计算的常量节点来替换那些所有都是常量输入的操作。
dynamic_axes:用于指定输入、输出的动态变化的入参,是个字典。KEY为输入或输出名称,VALUE为shape的索引以及可能用于导出的axes名称。通常,根据以下的一种方式或两种方式进行组合,最终确定该值:
1.指定所提供输入的动态axes的整数列表,最后将生成自动名称,并应用于导出时所提供的输入/输出的维度上。
2.一个字典,指定从相应输入/输出中的动态shape索引到导出期间希望应用于此类输入/输出的axes的名称的映射。ONNX 默认输入的张量是固定大小的,这样是为了提高效率。但是在实际使用中,我们输入张量的shape可能是动态的,特别是对于没有输入限制的全卷积网络,所以我们可以通过这个参数来进行哪些维度是可以动态改变的。
keep_initializers_as_inputs:默认为 None。如果为 True,那么就导出图中的所有初始值的设定项,一般对应到参数,最后也会作为输入,添加到图中。如果为 False,那么初始值的设定项就不会作为输入添加到图中,而只是将非参数作为输入进行添加。
custom_opsets:用于在导出时指示自定义 opset 域和版本的字典。如果模型包含自定义的操作集,那么就可以选择在字典中指定域和操作集版本:其中KEY为操作集域名,它的 VALUE为操作集版本。注意的是,如果在这个字典中没有提供自定义的操作集,那么操作集版本就默认设置为1。
enable_onnx_checker:默认为 True。如果为 True,onnx 模型检查器将作为导出的一部分运行,以确保导出的模型是没有问题的 ONNX 模型。
use_external_data_format:默认为 False。如果为 True,那么模型就会以 ONNX 外部数据格式导出,比方说,有些模型的参数是存储在二进制文件中的,而不是存储在 ONNX 模型文件中。
onnxsim的使用
如果要精简onnx,就可以将simplify设置为True。设置为True之后,就会调用onnxsim来对原来onnx去除不必要的op操作,也叫去除胶水。在使用之前需要安装onnx-simplifier。
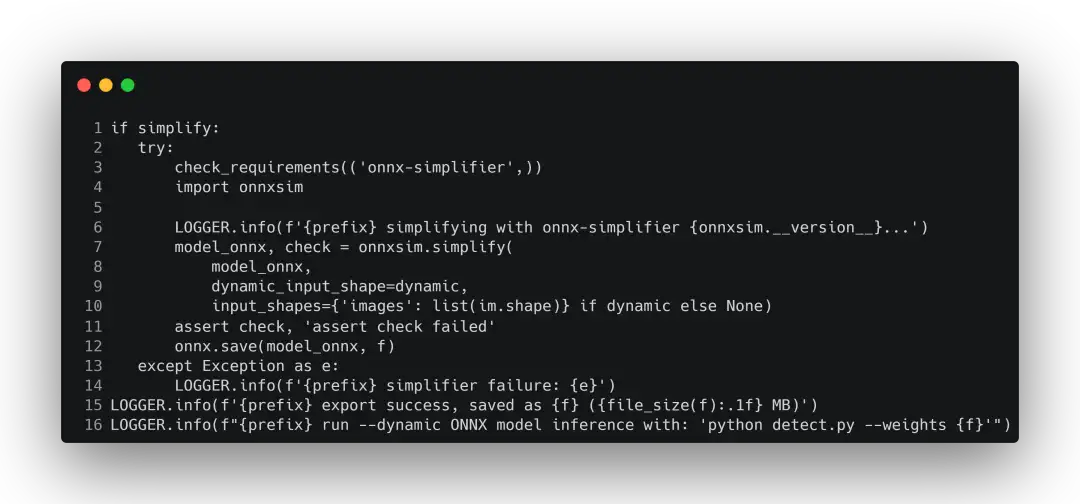
精简完之后可以把简化前和简化后的模型放进netron看优化了哪些地方。netron 就是一个网络结构的可视化神器。我们可以通过它来查看网络的结构。因为这里的模型太大,会占用较长的篇幅,所以本文就不展示了。
构建TensorRT引擎
构建完onnx后,就开始从onnx转为engine。在TensorRT上主要存在以下几个对象:
- builder:用于创建 config、network、engine 等其它对象。
- network:在其它框架的模型解析之后,就会被用于填充到网络 network中去。
- config:主要用于配置builder。
- OnnxParser:用于解析onnx的模型文件,对 ONNX 进行解析并填充到 tensorrt network 的结构当中。
- engine:根据特定的config 与特定的硬件上编译出来的引擎,只能应用于特定的 config 与硬件上。此外,引擎可以持久化保存到本地,以节省下次使用时,不必要的编译时间。engine 集成了模型结构、模型参数 与可以实现最优计算 的kernel 配置。但是于此同时,engine 与硬件和 TensorRT的版本有着强绑定,所以要求进行engine编译与执行的硬件上的TensorRT 版本要保持一致。
- context:用于推理的上下文,是执行 inference 时使用到的实际对象。由 engine 创建,与 engine 是一对多的关系。
在YOLOv5中所提供的转换代码如下:
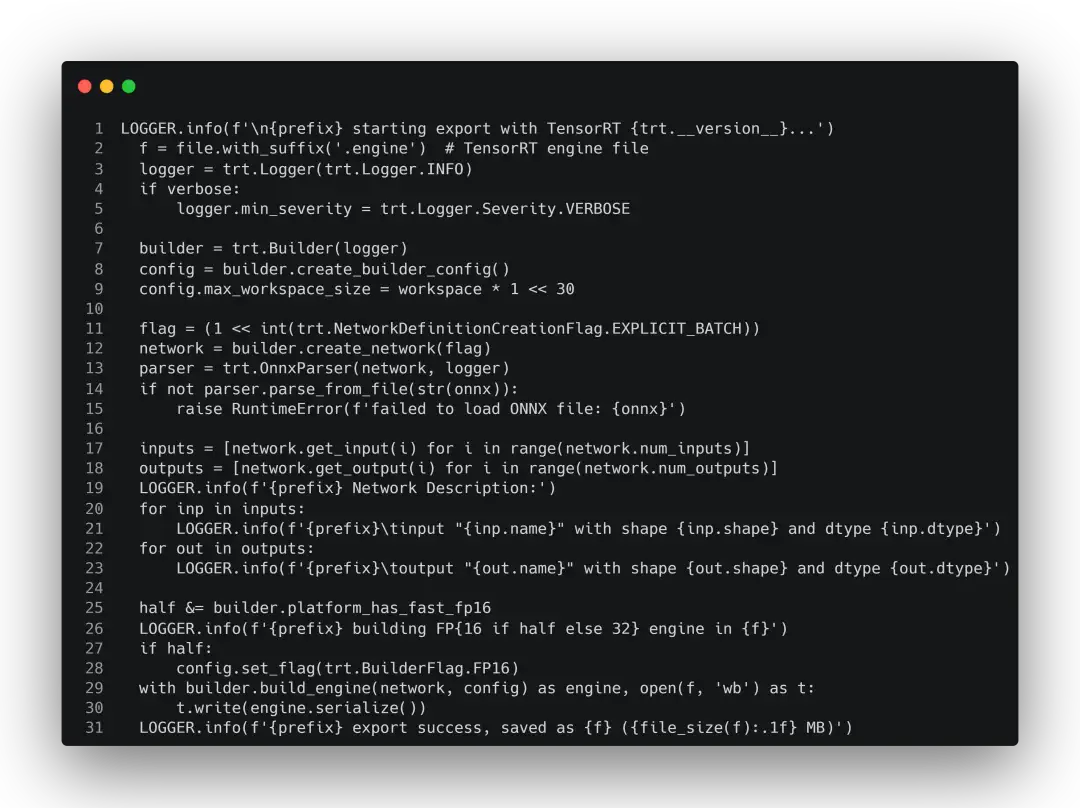
具体每个过程如构建builder、解析onnx的详细内容可以查看TensorRT教程系列的第二篇:TensorRT进阶介绍和第四篇:解读官方例程MNIST,里面有详细的流程介绍。
推理代码
使用engine推理和使用pt推理的流程是大同小异的,同样是使用detect.py。区别就在于model = DetectMultiBackend(weights, device=device, dnn=dnn)中的weight是pt模型还是onnx模型还是engine模型。
进入到DetectMultiBackend这个类中查看,直接跳转到构建engine的部分:
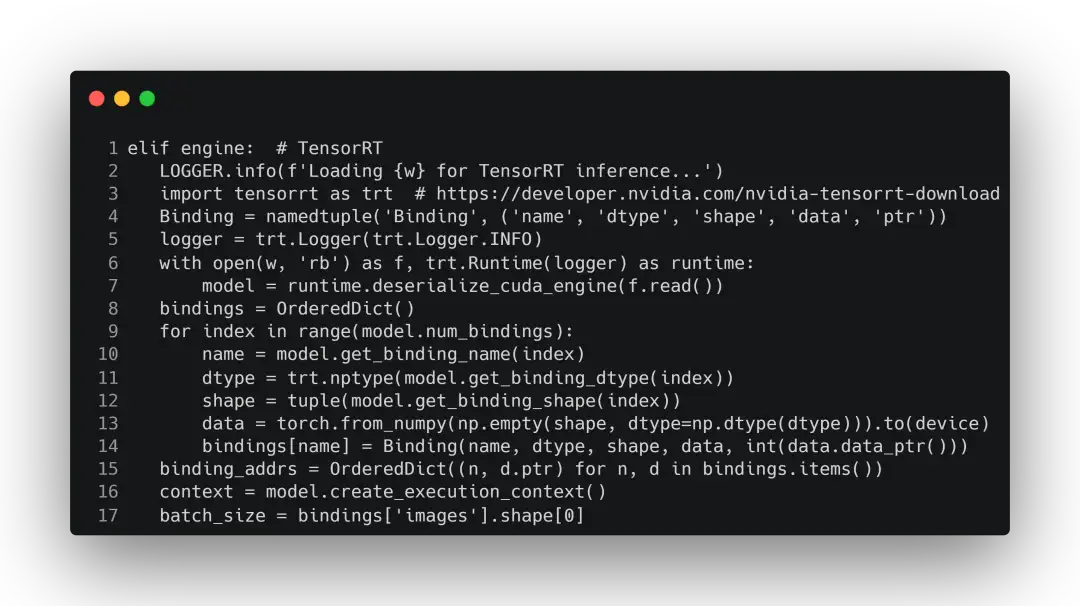
在进行前向推理时,就会调用DetectMultiBackend的forward方法:
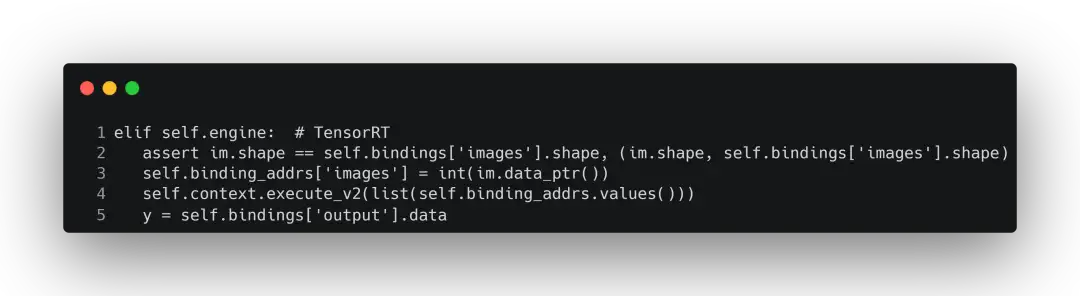
其中y返回的就是推理结果。这个结果会返回到detect.py中,当detect.py捕获到结果之后,就正常走目标检测的后处理流程了。
C++部署
转换onnx、engine的过程上面有了,这里就不再赘述。直接来看如何使用C++进行推理。
推理代码
首先是进行一些模型的准备工作,包括设置nms阈值、置信度阈值、gpu设备的id,以及将引擎进行反序列化,用于后面的推理。
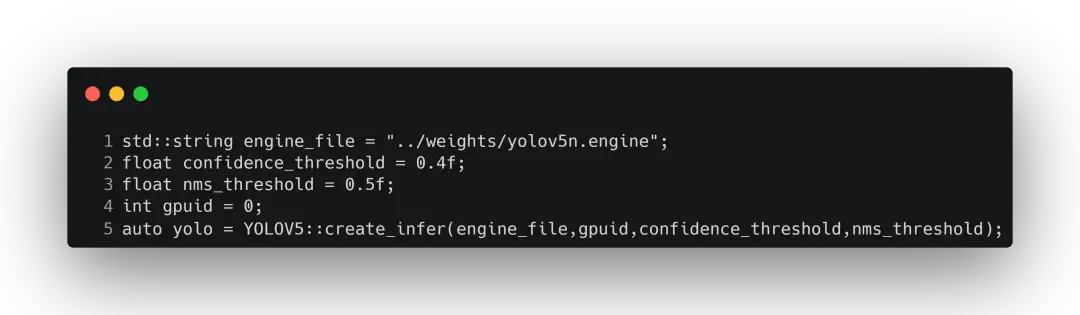
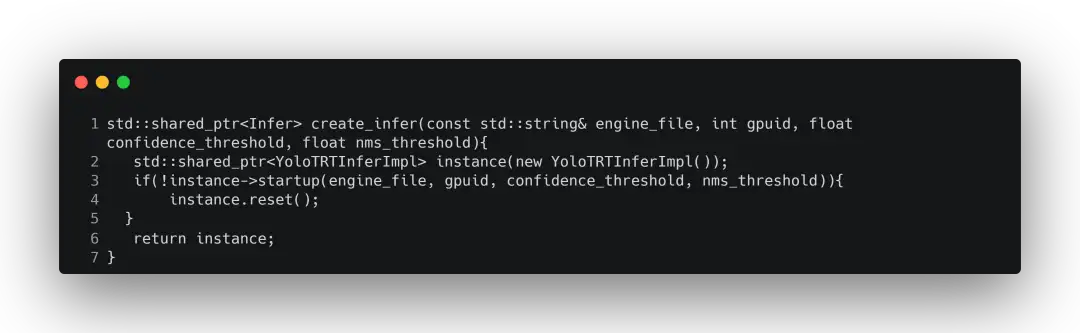
这里还会创建了一个TensorRT的推理对象,这个对象具备了引擎的创建、加载模型,反序列化,创建线程等一系列操作。具体实现为:
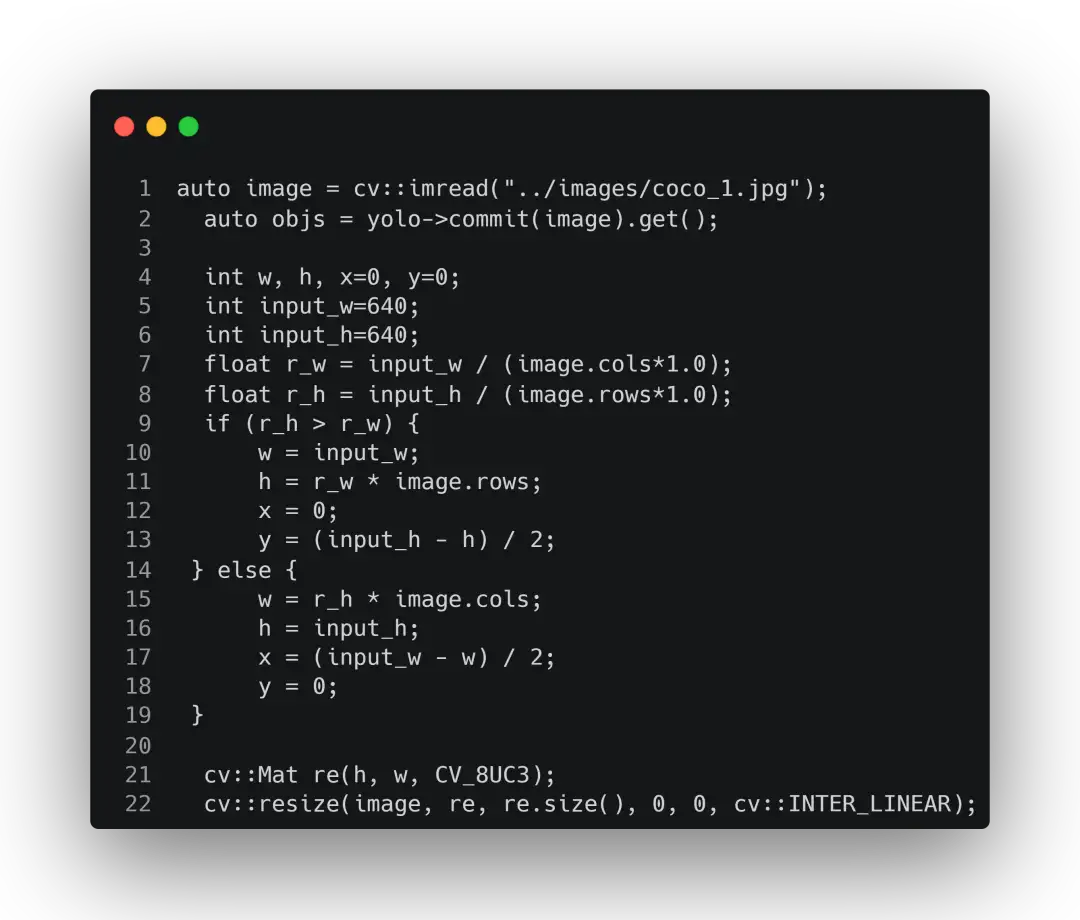
然后就开始读图然后获取结果,注意这里需要根据图片本身的大小以及输入到模型的大小进行一个缩放的过程。
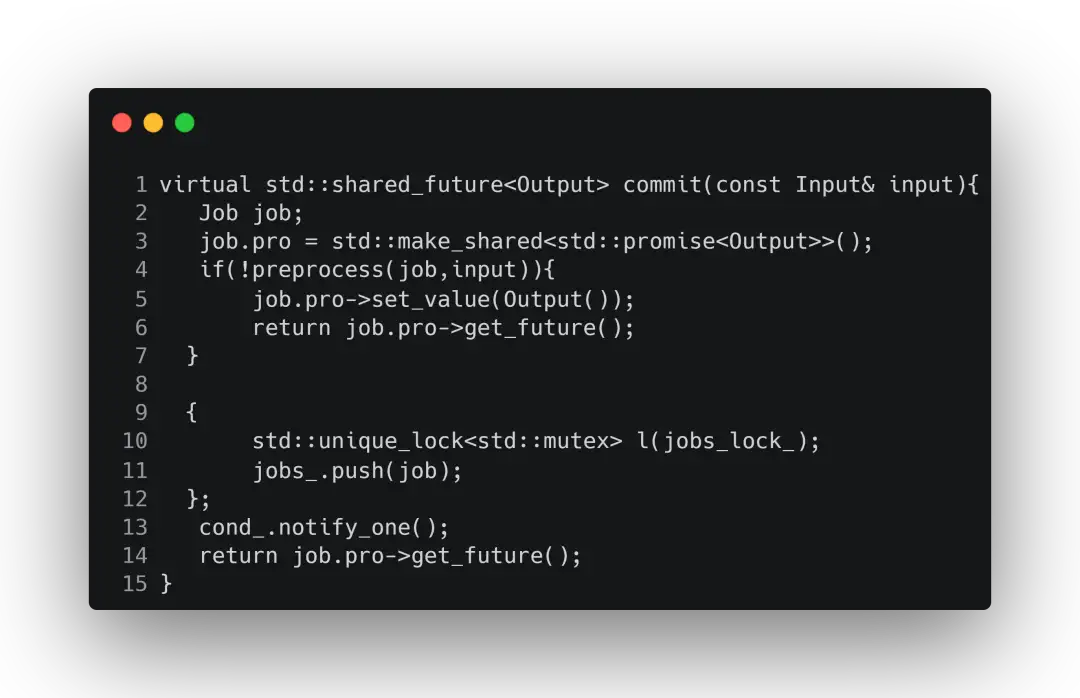
commit为提交图片到推理引擎中,该函数的具体实现为:
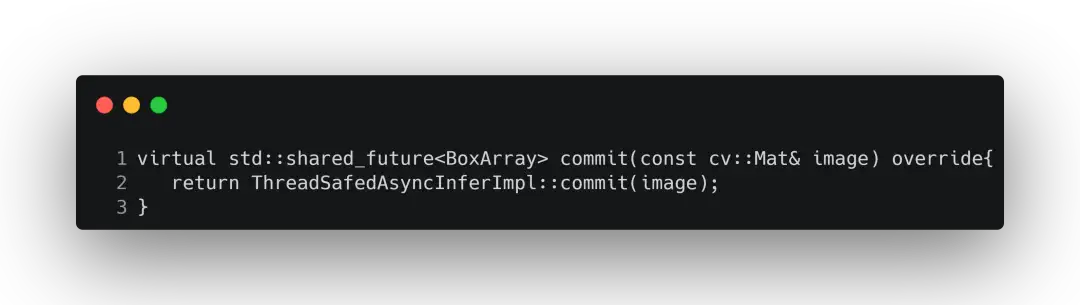
可以看到,这里是使用多线程异步推理。当完成异步推理后会同步cuda上的推理结果,并从GPU转移到CPU上。
推理完之后就是常规的进行nms过滤、画图、保存操作了。
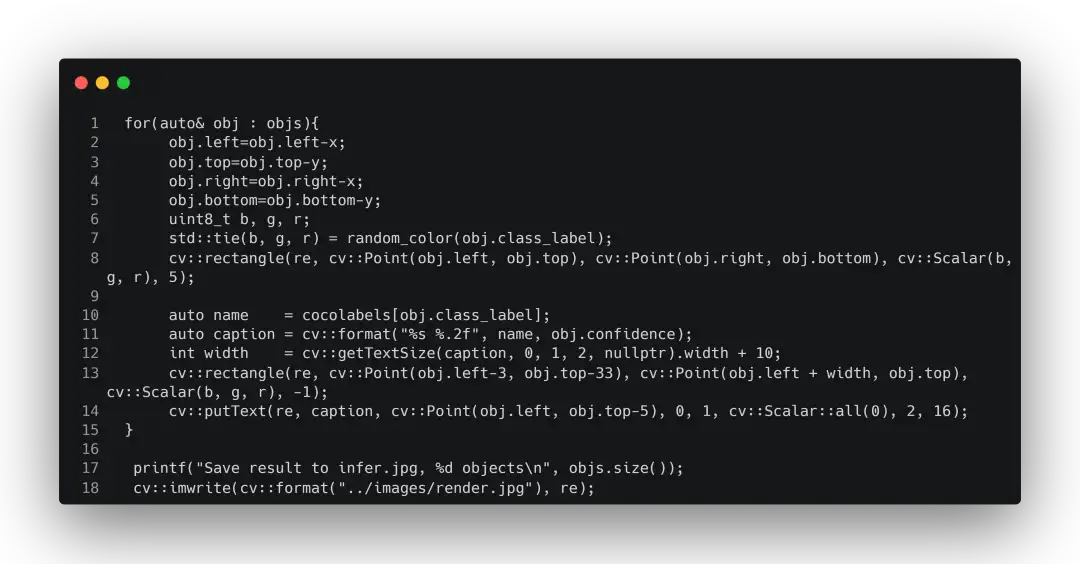
上面有个std::tie,我之前比较少见到,所以在这里也记录一下:std::tie的作用在于将tuple进行解包为独立对象,可以理解为实现批量赋值。
结果对比
以下是使用python加载engine进行推理以及使用C++加载engine进行推理的结果。
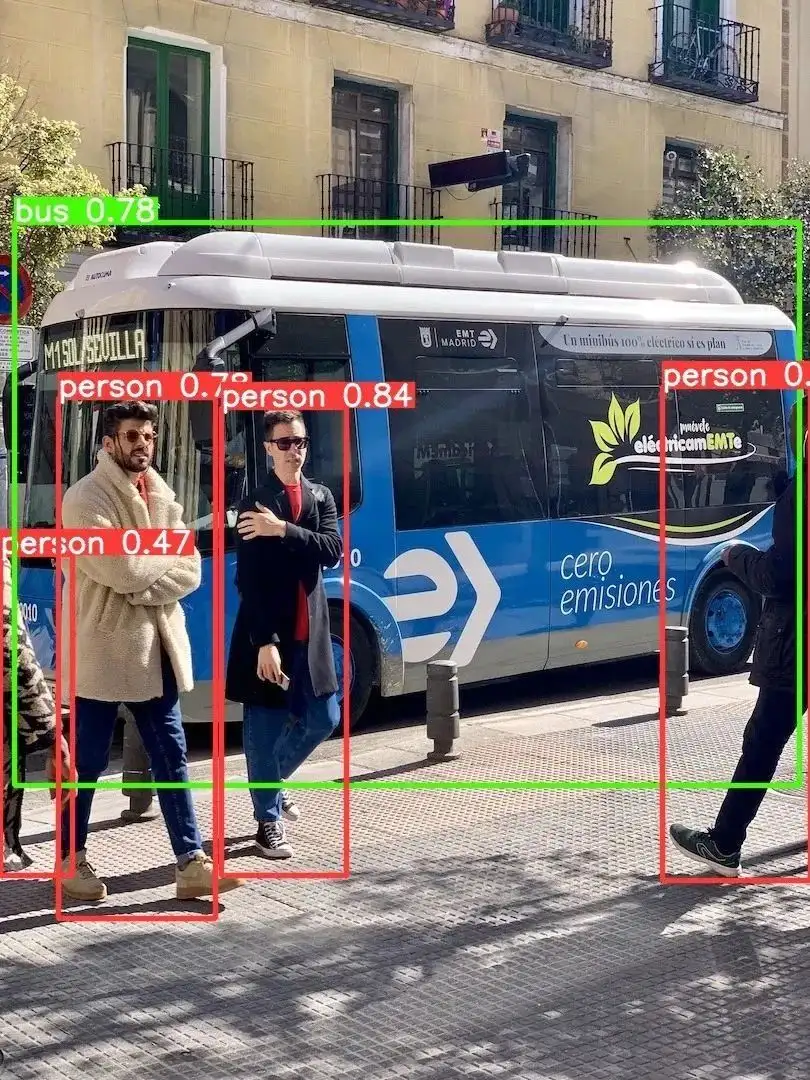
可以看到,两者的差别并不明显,并且可以达到较高的精度。
文末
虽然本文篇幅看起来稍微较长,但是大多内容都可以在之前的文章中查阅到,如TensorRT的安装过程、Engine引擎的构建流程。至于是使用Python来写部署代码,还是使用C++来写部署代码,我个人觉得使用C++的需求会更多。
因为对于移动设备,使用C++会更加友好。抛去语言的性能不说,有的设备可以直接运行C++代码却无法运行Python的代码。所以各位工程师们在业余时间可以看一下C++的有关知识,以增加自己的技术面。
参考链接
https://github.com/ultralytics/yolov5
https://github.com/ZJU-lishuang/yolov5_tensorrt
本教程禁止转载。同时,本教程来自知识星球【CV技术指南】更多技术教程,可加入星球学习。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
用于超大图像的训练策略:Patch Gradient Descent
CV小知识讨论与分析(5)到底什么是Latent Space?
CVPR 2023 Workshop | 首个大规模视频全景分割比赛
如何更好地应对下游小样本图像数据?不平衡数据集的建模的技巧和策
用少于256KB内存实现边缘训练,开销不到PyTorch千分之一
DAMO-YOLO | 超越所有YOLO,兼顾模型速度与精度
入门必读系列(十六)经典CNN设计演变的关键总结:从VGGNet到EfficientNet
TensorRT教程(五)使用TensorRT部署YOLOv6

 浙公网安备 33010602011771号
浙公网安备 33010602011771号