一文看尽深度学习中的生成对抗网络 | GANs架构发展的8年
前言 生成对抗网络 (Generative Adversarial Networks, GANs) 在过去几年中被广泛地研究,其在图像生成、图像转换和超分辨率等领域取得了显著的进步。到目前为止,已经提出了大量基于GANs的相关工作和综述。本文基于柏林圣三一大学计算机科学与统计学院的王正蔚博士与字节跳动AI实验室联合发表的一篇综述[1]为基础,详细的解读GANs的来龙去脉,同时为大家介绍近期一些相关工作,中间也会穿插一些笔者的见解。最后,本文也将列出一些可探索的未来研究方向,希望能给予读者一些启发。
本文转载自CVHub
作者 | 派派星
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
背景
生成对抗网络已应用在各种领域,例如计算机视觉(Computer Vision)、自然语言处理(Natural Language Processing)、时间序列合成(Time-series Synthesis)和语义分割(Semantic Segmentation)等。GANs本质上属于机器学习中的生成模型系列,与其他生成模型(如变分自动编码器)相比,GANs能够有效地生成所需要的样本,消除确定性偏差,并且与内部神经网络结构具有良好的兼容性。这些特性使GANs在计算机视觉领域获得了巨大的成功。尽管GANs至今已取得了巨大的成功,但将其应用于现实世界仍存在许多挑战,最主要的难点为:
- 高质量图像的生成
- 生成图像的多样性
- 训练的不稳定性
为了改善如上所述的问题,可以从体系结构角度或从损失函数角度对GANs进行修改。下图展示了2014-2020年提出的具有代表性的GANs分类。我们将当前GANs分为两类:体系结构变体(architecture-variant)和 损失变体(loss-variant)。在体系结构变体中,我们分为三类,分别为网络结构(network architecture)、隐空间(latent space) 以及 应用研究(application-focus)。网络结构类别表示对整个GAN结构进行改进或修改,例如Progressive GAN[2]使用渐进增大的训练方式。潜在空间类别表示基于潜在空间的不同表示的结构修改,例如Conditional GAN[3]涉及向生成器和判别器提供标签信息。最后一类应用研究是指根据不同的应用进行修改,例如CycleGAN[4]有一个特定结构用于图像风格转换。对于损失变体,我们将其分成两类,损失类型和正则化。损失类型是指可以针对GANs优化的不同损失函数,而正则化则是一种附加惩罚,被设计在损失函数或是归一化操作中。本文先对基于体系结构改进的GANs进行介绍。
Original GAN
论文链接:https://arxiv.org/abs/1406.2661 代码链接:https://github.com/goodfeli/adversarial
如上图所示,原始GAN[5]分为两个组件,一个为判别器 ,用于区分真实样本与生成样本;另一个为生成器 ,用于生成假样本来欺骗判别器。给定一个分布 ,将概率分布定义为样本 的分布。GAN的目的是要学习近似实际数据分布的生成器分布 。用于优化GAN的损失函数如下:
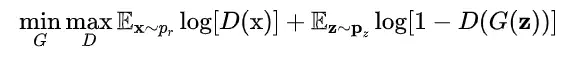
GANs作为深度生成模型(DGM)家族的一员,由于与传统DGMs相比具有以下优势:
- GANs性能更强
与变分自动编码器(VAE)相比,GAN能够计算任何类型的概率密度,从而生成更清晰的图像。 - GAN框架能训练任何类型的生成器网络
其他的DGMs可能对生成器有要求,例如需要生成器的输出层为高斯。 - 数据大小没有限制
这些优势促使GANs在生成合成数据(尤其是图像数据)时达到SOTA性能。
Energy-based GAN
论文链接:https://arxiv.org/abs/1609.03126 代码链接:https://github.com/eriklindernoren/PyTorch-GAN
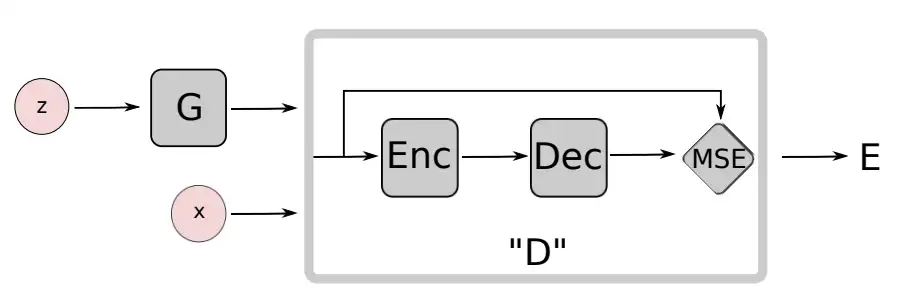
Energy-based GAN[6](EBGAN)通过利用auto-encoder作为判别器,使其鉴别对象不再是真假样本,而是鉴别样本的重构性。即不再对真实样本与生成样本之间的差异进行打分,而是利用一种“记忆”(通过auto-encoder实现)让判别器记住真实样本分布,若输入x与“记忆”相似则给高分,否则给低分。该方法应用于一些简单的图像数据集(MNIST[7]、CIFAR-10[8]和Toronto face)中取得了不错的效果,对比原始GAN,EBGAN做了如下工作:
- 由于EBGAN的判别器是经过预训练的,因此生成器在一开始便能获得比较大的“能量驱动”(energy besed),有效地较低了模型的训练成本。
- 该文章提出k step优化判别器以及1 setp优化生成器,以避免判别器过拟合。
- 采用最大化 来训练生成器,避免优化生成器时出现梯度消失的问题。此修改等效于利用反向KL散度来度量 和 之间的差异,会引起非对称的问题。
- 将maxout[9]应用在判别器,而ReLU和sigmoid激活函数应用于生成器。而然设置对于复杂图像并没有表现出良好的泛化性能。
Semi-supervised GAN
论文链接:https://arxiv.org/abs/1606.01583 代码链接:https://github.com/eriklindernoren/PyTorch-GAN
Semi-supervised GAN[10](SGAN) 是在半监督学习的背景下提出的。半监督学习是介于监督学习和无监督学习之间的一个很有前景的研究领域。与监督学习(每个样本需要提供标签)和无监督学习(不提供标签)不同,半监督学习为一小部分样本提供标签。与原始GAN不同,SGAN 的判别器是多头的,如上图所示,它具有 softmax 和 sigmoid 分别用于对真实数据进行分类并区分真假样本。SGAN在MNIST数据集上进行了大量的实验,结果表明SGAN中的判别器和生成器的都比原始GAN表现更好。这种多头判别器的架构比较简单,也许会限制模型的多样性,结合更复杂的鉴别器架构可能会进一步提高模型的性能。
Bidirectional GAN
论文链接:https://arxiv.org/abs/1605.09782 代码链接:https://github.com/eriklindernoren/Keras-GAN
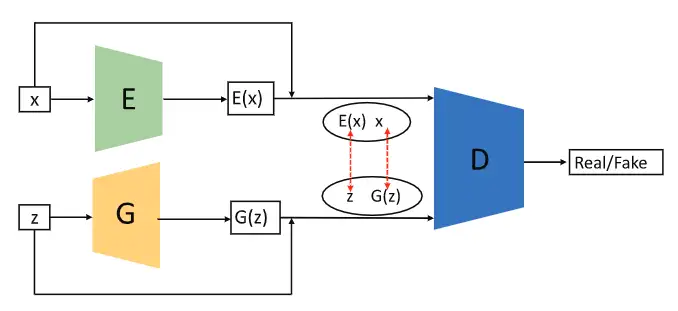
原始GAN无法学习逆映射,例如将数据投影回隐空间。Bidirectional GAN[11](BiGAN)正是为解决此问题而设计的。如上图所示,BiGAN的网络结构包含一个编码器 、一个生成器 以及一个判别器 。 将真实样本数据编码为 ,而 则将 解码为。因此, 旨在评估每对 与 之间的差异, 和 并不会直接交互。通过加入编码器与解码器之间的相互反转结构,BiGAN的性能得到了进一步地提升。如果将这种模型应用于处理对抗样本将会很有趣。
Conditional GAN
论文链接:https://arxiv.org/abs/1411.1784 代码链接:https://github.com/eriklindernoren/PyTorch-GAN
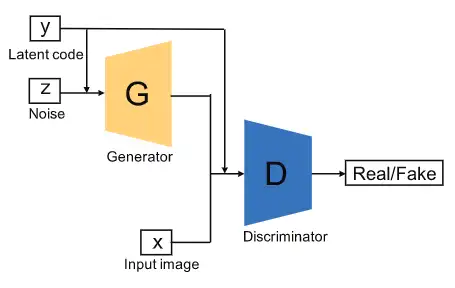
Conditional GAN[12](CGAN)的创新在于通过提供类标签(class label)来进一步优化生成器和判别器。如上图所示,CGAN提供了额外的信息 (可以是类标签或者其它模态的数据)给生成器和判别器。值得注意的是, 通常是先独自进行编码,然后再与已编码的 和 进行拼接。例如,在MNIST数据集的实验中, 和 分别被映射到层大小为200和1000的隐藏层,然后在生成器中再进行结合(200+1000=1200)。通过这种做法,CGAN能提升判别器的判别能力。CGAN的损失函数与原始GAN略有不同,如以下等式所示:
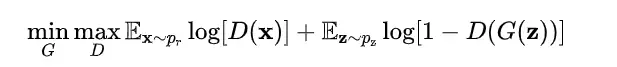
其中 和 受限于。得益于额外的 信息,CGAN不仅能够处理单一模态的图像数据,而且还可以处理多模态的数据。例如,包含标记图像数据及其相关用户生成元数据的Flickr数据集,这将GAN带到了多模态数据生成领域。
InfoGAN
论文链接:https://arxiv.org/abs/1606.03657 代码链接:https://github.com/eriklindernoren/PyTorch-GAN
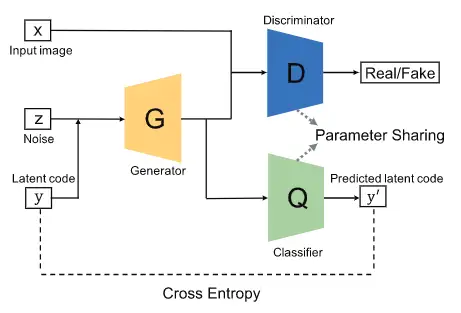
InfoGAN[13]被提出作为一种超越CGAN的模型,它通过利用无监督的方式,最大化条件变量和生成数据之间的互信息,以学习可解释的特征表示。如上图所示,InfoGan引入了另一个分类器 来预测由 生成的 。 和 的结合在这里可以理解为自动编码器,其中我们旨在找出最小化 和 之间交叉熵的 。然而, 和原始GAN都是干一样的事情,即区分真实样本和生成样本。为了减少计算开销, 和 共享所有卷积层除了最后的全连接层,这使得判别器拥有判别真假样本的能力并且恢复信息 。与原始GAN结构相比,这使得InfoGAN具有更强的判别能力。InfoGAN使用的损失是CGAN损失的正则化:
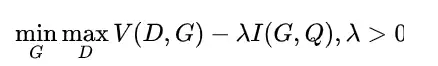
其中 为CGAN的优化目标除了判别器不需要额外的 信息作为输入,并且 为互信息。
Auxiliary Classifier GAN
论文链接:http://proceedings.mlr.press/v70/odena17a.html 代码链接:https://github.com/buriburisuri/ac-gan
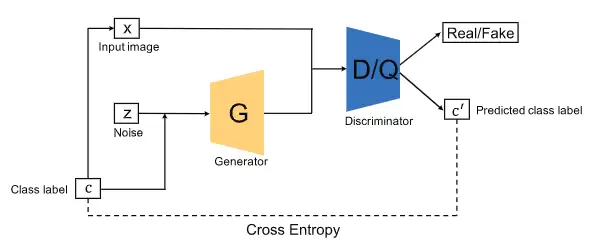
Auxiliary Classifier GAN[14](AC-GAN)与CGAN和InfoGAN非常相似,如上图所示,它包含了一个辅助分类器。每一个生成样本都一个对应类标签 和噪声 。需要注意的是,AC-GAN与前两个架构变体(CGAN 和 InfoGAN)的区别在于附加信息,这里仅限于类标签,而前两个可以是其他的领域数据。因此,上图中使用 和 来标记以突显其与前两种方法的差异。AC-GAN的判别器由一个判别器 以及一个分类器 组成,与InfoGAN类似,判别器与分类器共享参数除了最后一层。AC-GAN的损失函数可以写成以下形式:
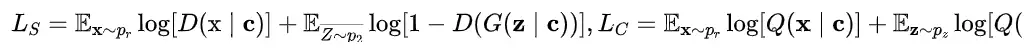
其中 通过最大化 训练, 通过最大化 训练。AC-GAN 提高了生成图像的视觉质量以及模型多样性。但是,这些改进需要依赖大规模的带标签数据集,这在实际应用中可能会带来挑战。
Laplacian Pyramid of Adversarial Networks
论文链接:https://arxiv.org/abs/1506.05751 代码链接:https://github.com/AaronYALai/Generative_Adversarial_Networks_PyTorch

Laplacian Pyramid of Adversarial Networks[15](LAPGAN)被设计用于将低分辨率图像作为输入,生成高分辨率图像。拉普拉斯金字塔[16]是一种图像编码方法,它使用多个尺度但形状相同的局部算子作为基础函数。LAPGAN 在拉普拉斯金字塔框架 [16] 中利用级联 CNN 来生成高质量图像,如上图所示。LAPGAN使用拉普拉斯金字塔对图像进行上采样,而不是使用转置卷积。首先,LAPGAN使用第一个生成器生成一张非常小的图像,这可以提升生成器的稳定性,接着通过使用拉普拉斯金字塔对该图像进行上采样。然后,将上采样的图像喂给下一个生成器以生成图像差异以及图像差异的总和。如上图所示,我们将 的生成图像作为输入图像,虽然图像尺度非常小,但有利于训练的稳定性。对于较大的图像,生成器用于生成图像差异,这比相同大小的原始图像要简单得多。
Deep Convolutional GAN
论文链接:https://arxiv.org/abs/1511.06434 代码链接:https://github.com/carpedm20/DCGAN-tensorflow
Deep Convolutional GAN[16] (DCGAN)是第一个将转置卷积神经网络架构应用于生成器的方法。转置卷积能够有效地将CNN特征进行可视化[17]。DCGAN 的生成器使用转置卷积操作对图像进行上采样,这能够提升其生成高分辨率图像的质量。与原始GAN 相比,DCGAN 的架构有一些关键的修改,这有利于高分辨率建模以及稳定训练:
- DCGAN使用跨步卷积(strided convolution)代替结构中所有的池化层。
- 判别器和生成器都使用批归一化(batch normalization),这有助于网络更有效地进行训练。
- 除了最后的输出层使用Tanh,生成器的其他层全部使用ReLU激活函数;判别器的所有层均使用Leaky ReLU激活函数。
DCGAN是GANs历史上非常重要的里程碑,转置卷积操作被后续提出的GANs广泛应用。由于模型容量的限制,DCGAN只能在低分辨率和多样性较少的图像上取得较好的效果。
Boundary Equilibrium GAN
论文链接:https://arxiv.org/abs/1703.10717 代码链接:https://github.com/carpedm20/BEGAN-tensorflow
GANs可以生成非常逼真的图像,比使用像素损失的自编码器生成的图像更锐利清晰。然而,GANs仍然面临许多未解决的困难:超参数选择困难、模式坍塌和平衡生成器和判别器的收敛程度困难。Boundary Equilibrium GAN[18](BEGAN)借鉴了EBGAN和WGAN各自的一些优点,提出了一种新的评价生成器生成质量的方式,使得网络能有效地避免模式崩溃(model collapse)和训练不稳定的问题。
通常,如果两个分布越接近,则可以认为它们越相似,当生成数据分布非常接近于真实数据分布的时候,生成器就具备了足够的生成能力。BEGAN代替了这种估计概率分布方法,它不直接去估计生成分布 与真实分布 的差距,而是估计分布的误差分布之间的差距,即只要分布之间的误差分布相近的话,也可以认为这些分布是相近的。
总的来说,Boundary Equilibrium GAN作了如下贡献:
- 提出了一个简单强大的GAN结构,使用标准的训练步骤实现了快速且稳定的收敛。
- 对于GAN中的 和 的平衡提出了一种均衡的概念。
- 提供了一个超参数,用于平衡图像的多样性和生成质量。
- 提出了一种收敛程度的估计(灵感来自于WGAN)。
BEGAN网络结构简洁且无需调整大量的超参数,在CeleB数据集上达到了优异的性能效果。
Progressive GAN
论文链接:https://arxiv.org/abs/1710.10196 代码链接:https://github.com/akanimax/pro_gan_pytorch
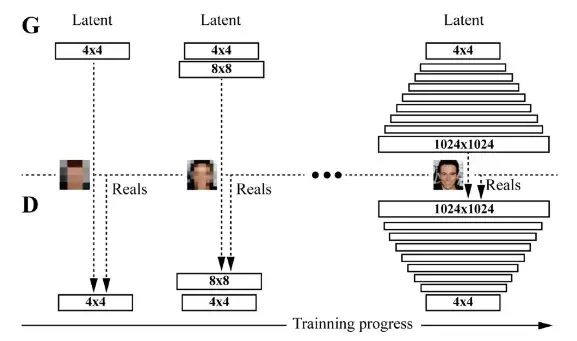
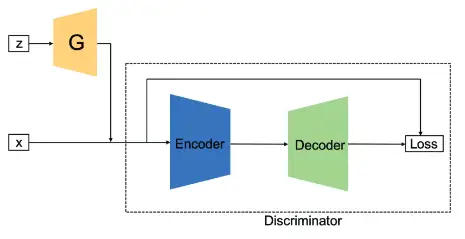
Progressive GAN[19](ProGAN)也是一种应用于图像生成的生成对抗网络。不同于先前的GANs的训练策略,它们都是先搭建好网络再进行训练,而ProGAN则是采用逐步增长的训练策略,如上图所示。具体来说,生成器 和判别器数 最初只有一层,前者用于生成分辨率极低(4×4)的图像,后者再对生成的图像与真实图像(同等分辨率)进行编码得到输出结果。训练若干轮次。接着,给 和 均加一层,使得生成的图像分辨率更高(8×8),并且将其与真实图像一起输入至判别器,获得输出结果。再次训练若干轮次。重复上述过程,直至生成图像分辨率达到指定大小。
ProGAN解决了生成高分辨率图像的问题。该方法最主要的贡献为提出了一种渐进式训练方式。然而,ProGAN与多数GAN一样,控制生成图像的特定特征的能力非常有限。图像特征属性相互纠缠,即使略微调整输入,会同时影响生成图像的多个属性。因此如何将ProGAN改为条件生成模型,或者增强其调整单个属性的能力,是一个不错的研究方向。
StyleGAN
论文链接:https://openaccess.thecvf.com/content_CVPR_2019/papers/Karras_A_Style-Based_Generator_Architecture_for_Generative_Adversarial_Networks_CVPR_2019_paper.pdf 代码链接:https://github.com/NVlabs/stylegan
由于ProGAN是逐级生成图片的,我们没有办法对其增添控制,这导致ProGAN无法生成具有特定特征的图像。因此,在ProGAN的基础上,StyleGAN[20]对生成器做出了进一步的改进和提升,其主要通过分别修改每一层级的输入,在不影响其他层级的情况下以控制该层所表示的视觉特征。StyleGAN的主要贡献如下:
借鉴了风格迁移,提出新的生成器结构(基于样式的生成器)
- 实现无监督地分离高级属性(姿态,身份)与随机变化(头发,雀斑)
- 实现可直观地,按特定尺度控制合成
实现了更高的生成质量,更好的解耦能力
- 通过映射网络f将隐向量z映射至中间的隐空间W。输入隐向量z必须遵循训练数据的概率密度,这会导致某种程度的不可避免的纠缠,而中间的隐空间W则不受限制。
提出了两种新的量化隐空间解耦程度的方法
- 感知路径长度和线性可分性。与传统的生成器体系结构相比,新的生成器允许更线性和解耦地表示不同的变化因素。
提出了FFHQ人脸数据集
- 高质量、大规模的人脸数据集,7万张1024×1024图片
不得不说,StyleGAN不论是在理论上,还是工程实践上,都是具有突破性的,它不仅可以生成高质量的图像,而且还可以对生成图像进行有效的控制和理解。
Self-attention GAN
论文链接:http://proceedings.mlr.press/v97/zhang19d/zhang19d.pdf 代码链接:https://github.com/heykeetae/Self-Attention-GAN
传统CNNs只能捕获局部空间信息并且感受野会受到一定的限制,这导致了基于传统CNN的GANs学习多类别的复杂数据集会非常困难以及生成图像中的关键语义可能会发生偏移,例如生成的脸部图像中鼻子并不一定在正确的位置。自注意力机制能够捕获大感受野的同时无需牺牲太多的计算效率。Self-attention GAN[21](SAGAN)生成器和判别器都运用了自注意力机制,如上图所示。受益于自注意力机制,SAGAN能够学习空间像素的全局依赖关系来生成图像,其在ImageNet数据集的多类别图像生成任务中取得了很好的性能表现。
BigGAN
论文链接:https://arxiv.org/abs/1809.11096 代码链接:https://github.com/ajbrock/BigGAN-PyTorch
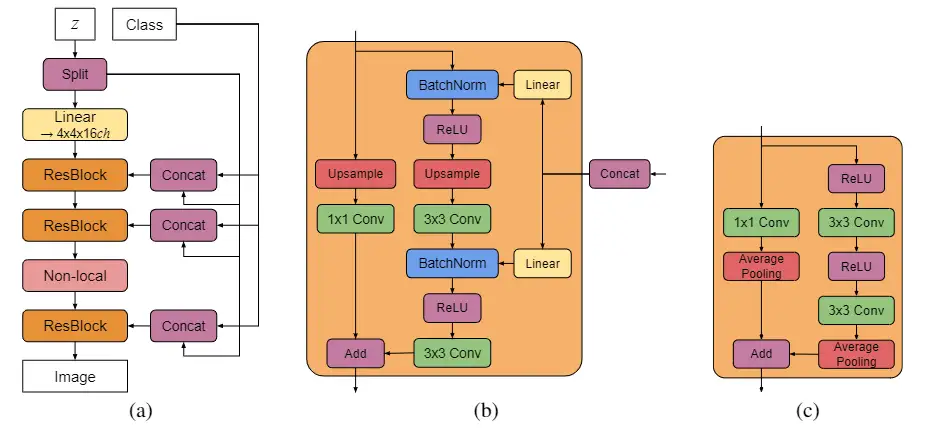
BigGAN[22]作为GAN发展史上重要的里程碑,在生成图像精度和多样性均作出了跨越式提升。在ImageNet训练下,将Inception Score(IS,生成图像的质量)和Frechet Inception Distance(FID,生成图像的多样性)分别从52.52和18.65提升到166.3和9.6。BigGAN主要有以下贡献点:
通过增加模型参数量(扩展channel)以及增大batch size
- batch size提高分别2、4、8,通道数增加1.5倍,性能均获得不同程度的提升。
使用截断技术(truncation trick)
- 使用传统的正太分布结合截断技术来权衡样本的保真度和多样性。
结合了各种新颖trick
- 采用共享嵌入(shared embeddings)将类别信息投影至生成器的每个BN层,有效利用了类别信息且不增加参数量;
- 通过层次化隐空间将随机噪声向量输入到生成器的每一层中,使得随机噪声向量能直接作用在不同层级特征;
- 使用正交正则化来改善截断技术引起的饱和伪影问题,使得更有效利用整个随机噪声向量空间合成更高质量的样本。
通过利用许多新颖的方法和技巧,BigGAN的性能可以得到有效的提升,然而网络在训练时也容易崩溃,因此在实际使用中有必须采取提前停止训练的措施。此外,BigGAN也探索了一套能够指示训练崩溃的度量指标,使得能针对性地分析并解决网络训练不稳定的问题。
Label-noise rGANs
论文链接:http://openaccess.thecvf.com/content_CVPR_2019/papers/Kaneko_Label-Noise_Robust_Generative_Adversarial_Networks_CVPR_2019_paper.pdf 代码链接:https://github.com/takuhirok/rGAN
我们在上文已经分别讨论过CGAN和AC-GAN,它们都具有学习解耦表示(disentangled representation)以及提高GANs的判别能力。然而,训练模型需要大规模标记的数据集,这在实际场景中具有很大的挑战性。label-noise rGANs[23]通过结合噪声过渡模型,能够从具有噪声的训练标签中学习到干净的标签条件生成分布。上图展示了基于AC-GAN和CGAN的扩展,这些rGANs的核心部分为噪声过度模块 ( 为噪声标签, 为干净标签)引入到判别器中。rGAN在CIFAR-10 和 CIFAR-100数据集上进行了对比实验,其中在CIFAR-10数据集上的性能优于原始架构,并且还表现出对噪声标签的鲁棒性。但是,在 CIFAR-100 中,当向标签引入高噪声时,rGAN的性能会下降。结果表明rGAN在遇到更复杂的数据集时仍然有些局限性,未来需要进一步研究。
Your Local GAN
论文链接:https://openaccess.thecvf.com/content_CVPR_2020/papers/Daras_Your_Local_GAN_Designing_Two_Dimensional_Local_Attention_Mechanisms_for_CVPR_2020_paper.pdf 代码链接:https://github.com/giannisdaras/ylg
注意力机制通过建模像素间关系,能有效地处理复杂的几何形状以及捕获长距离依赖,以进一步提高网络性能。然而,注意力也存在以下限制。首先计算开销大。标准的密集注意力需要的空间和时间成倍增加。其次,计算注意力时将二维的空间结构展开为一维向量会损失空间特性。针对以上的问题,Your Local GAN[24](YLG)主要做了以下贡献:
- 引入了局部稀疏注意力层,该层保留了二维图像的局部性,并且可以通过attention steps来支持良好的信息流。
- 使用了信息流图的信息理论框架,以量化信息流的步骤并保持二维局部性。
- 基于SAGAN结构提出了YLG-SAGAN,使得网络的性能和训练时间均得到大幅优化。
- 提出了一种解决GANs反演问题的新方法,能对更大模型的损失进行梯度下降的自然反演过程。
YLG通过应用稀疏注意力与信息流的相关技术以有效提高网络性能。然而,该工作存在两个相互矛盾的目标。一方面,YLG旨在使网络尽可能稀疏以提高计算和统计效率,另一方面它们仍然需要支持良好和完整的信息流。
AutoGAN
论文链接:https://openaccess.thecvf.com/content_ICCV_2019/papers/Gong_AutoGAN_Neural_Architecture_Search_for_Generative_Adversarial_Networks_ICCV_2019_paper.pdf 代码链接:https://github.com/VITA-Group/AutoGAN
AutoGAN[25]将神经架构搜索(NAS)算法引入生成对抗网络(GANs)。生成器架构变体的搜索空间通过RNN、参数共享和动态重置来引导以加速该过程。AutoGAN使用Inception Score(IS)作为奖励,并引入多级搜索策略以渐进方式执行 NAS。在谱归一化 GAN (SN-GAN) 的训练设置之后,作者使用hinge loss来训练共享GAN。
AutoGAN方法的设计非常具有创新性,同时也提出了关于NAS和GANs有效结合的新挑战。目前,NAS仍然有待对标准分类问题进行优化,更不用说GANs固有的训练不稳定问题。对比手动设计的GAN架构,虽然AutoGAN是非常新颖的并且展示出了不错的性能,但是还有以下问题需要解决:
- 生成器的搜索空间是有限的,并且没有讨论判别器的搜索策略。
- AutoGAN并未在高分辨率图像生成数据集上进行测试,其适用性不能被直观的评估。
MSG-GAN
论文链接:http://openaccess.thecvf.com/content_CVPR_2020/papers/Karnewar_MSG-GAN_Multi-Scale_Gradients_for_Generative_Adversarial_Networks_CVPR_2020_paper.pdf 代码链接:https://github.com/HelenMao/MSGAN
众所周知,GANs很难适应不同的数据集。研究者认为造成这种情况的原因之一是当真实分布和虚假分布没有足够的重叠时,梯度的信息量无法有效地从判别器传递到生成器。MSG-GAN[26]被提出作为处理这类问题的一种手段。如上图所示,生成器和判别器的隐空间相连,以便它们共享更多的信息。更具体地说,在生成器的每个转置卷积的激活值通过1×1卷积映射到不同尺度的图像上。相似地,映射图像被 进一步编码为激活值,然后与真实图像的激活值拼接起来,这种连接使得判别器与生成器之间能共享更多的信息,并且实验结果也验证了有效性。
尽管 MSG-GAN 在多个图像数据集上取得了非常好的结果,但 MSG-GAN 生成不同图像的能力尚未经过测试并且我们发现 CIFAR10 上的结果不如其他数据集。这可能是由生成器和判别器 之间的连接引起的,导致生成器的多样性受到限制。图像的多样性可能会引起不一致的匹配激活,这会对训练产生负面影响,可以尝试添加自注意力模块来改善这个问题。
总结
本文对不同结构的GANs进行了总结,重点介绍了在图像质量、模式多样性和训练不稳定这三个关键挑战上他们是如何提高性能的。上图(a)展示了从2014到2020的GANs在架构改进上的发展,可以发现,在不同架构的GANs中存在许多联系。上图(b)展示了GANs对于三大挑战的相对性能表现。有兴趣的读者可以查阅原论文以更深入地了解每个GAN变体的原理和性能表现。接下来本文将简要回顾一下不同架构的GANs是如何解决三大挑战的。
图像质量
GANs 的基本目标之一是生成具有高质量的逼真图像。由于网络的容量有限,原始 GAN (FCGAN) 仅应用于 MNIST、Toronto face 和 CIFAR-10 数据集。DCGAN 和 LAPGAN 引入了转置卷积和上采样过程,这使得模型能生成更高分辨率的图像。其他的结构变体GANs(如BEGAN、ProGAN、SAGAN和BigGAN)在损失函数上也进行了改进以进一步提升图像的质量。仅就架构组件而言,BEGAN使用自动编码器作为判别器,在像素级别上比较生成图像和真实图像,这有助于生成器生成易于重建的数据。ProGAN 采用更深层次的架构,模型随着训练的进行而扩展。这种渐进式训练策略提高了判别器和生成器的学习稳定性,因此模型更容易学习如何生成高分辨率图像。SAGAN 主要通过谱归一化提升性能,BigGAN验证了更大的batch size和更深的模型有助于高分辨率图像的生成。
梯度消失
改变损失函数是目前解决此类问题的唯一方法。本文介绍的一些GANs避免了梯度消失问题,但这主要是因为它们使用了不同的损失函数。
模式多样性
这是 GANs 最具挑战性的问题。GANs很难生成逼真的多样化图像(例如自然图像)。在架构变体GANs中,只有SAGAN和BigGAN较好地解决了这个问题。受益于自注意力机制,SAGAN和BigGAN 中的 CNN 可以捕获大的感受野,克服生成图像中的shifting components问题,这使得此类 GANs 能够生成不同的图像。
References
[1] Generative Adversarial Networks in Computer Vision: A Survey and Taxonomy [2] Progressive growing of gans for improved quality, stability, and variation [3] Conditional Generative Adversarial Nets [4] Unpaired Image-to-image Translation Using Cycle-consistent Adversarial Networks [5] Generative adversarial networks [6] Energy-based generative adversarial network [7] Gradient-based learning applied to document recognition [8] Learning Multiple Layers of Features from Tiny Images [9] Deep sparse rectifier neural networks [10] Semi-supervised Learning with Generative Adversarial Networks [11] Adversarial Feature Learning [12] Conditional Generative Adversarial Nets [13] InfoGAN: Interpretable representation learning by information maximizing generative adversarial nets [14] Conditional image synthesis with auxiliary classifier gans [15] Deep generative image models using a laplacian pyramid of adversarial networks [16] Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks [17] Generative Adversarial Text to Image Synthesis [18] Began: Boundary equilibrium generative adversarial networks [19] Progressive Growing of GANs for Improved Quality, Stability, and Variation [20] A style-based generator architecture for generative adversarial networks [21] Self-attention Generative Adversarial Networks [22] Large Scale GAN Training for High Fidelity Natural Image Synthesis [23] Label-noise robust generative adversarial networks [24] Your local GAN: Designing two dimensional local attention mechanisms for generative models [25] AutoGAN: Neural architecture search for generative adversarial networks [26] Multi-scale gradients for generative adversarial network
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
用于超大图像的训练策略:Patch Gradient Descent
CV小知识讨论与分析(5)到底什么是Latent Space?
CVPR 2023 Workshop | 首个大规模视频全景分割比赛
如何更好地应对下游小样本图像数据?不平衡数据集的建模的技巧和策
用少于256KB内存实现边缘训练,开销不到PyTorch千分之一
DAMO-YOLO | 超越所有YOLO,兼顾模型速度与精度
入门必读系列(十六)经典CNN设计演变的关键总结:从VGGNet到EfficientNet

 浙公网安备 33010602011771号
浙公网安备 33010602011771号