

神经网络损失函数分布可视化神器
前言 本文介绍了一系列可视化方法探索了神经损失函数的结构,以及loss landscape对泛化的影响,提出了一种基于 "Filter Normalization" 的简单可视化方法。当使用这种归一化时,最小化的锐度与泛化误差有很高的相关性,这种展示的可视化结果非常清晰。
本文转载自极市平台
作者丨CV开发者都爱看的
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
本文目录
1 神经网络损失函数分布可视化神器 (来自马里兰大学) 1 Loss landscape 论文解读 1.1 背景和动机 1.2 损失函数可视化基础 1.3 Filter Normalization 1.4 可视化实验:Loss landscape 尖锐,扁平的困境 1.5 把以上可视化实验再用 Filter Normalization 方法做一遍 1.6 究竟什么使得神经网络可训练?一些 Loss Surfaces 非凸结构的发现
1 神经网络损失函数分布可视化神器
论文名称:Visualizing the Loss Landscape of Neural Nets
论文地址:
https://arxiv.org/pdf/1712.09913.pdf
1.1 背景和动机
训练一个神经网络,需要最小化一个高维非凸损失函数——这一任务在理论上很难,但在实践中有时很容易。简单的梯度下降方法通常可以找到全局的最小值 (训练损失为零或接近零)。然而,这种较容易训练好一个网络的行为却并不普遍,神经网络的可训练性高度依赖于网络架构设计的选择、优化器的选择、变量初始化和各种因素。而且,这些选择对于潜在的 loss landscape 的影响尚不清楚。
因此,本文从神经网络损失函数分布可视化的角度,想研究以下几个问题:
-
为什么我们能够最小化高度非凸神经损失函数?
-
为什么得到的最小值这个结果具有泛化性?
-
不同的神经网络网络架构如何影响损失函数分布 (loss landascape),以及训练的超参数参数如何影响损失函数分布?
具体而言,本文的贡献是:
-
本文提出一种基于 "Filter Normalization" 的简单可视化方法。当使用这种归一化时,最小化的锐度与泛化误差有很高的相关性,这种展示的可视化结果非常清晰。
-
本文观察到,当网络变得足够深时,神经网络的 loss landscape 会迅速从接近凸的状态过渡到高度混乱的状态。这种从凸到混沌行为的转变伴随着泛化误差的急剧下降,并最终导致整个网络可训练性的下降。
-
本文观察到,残差连接促进了 loss landscape 更加平坦,并阻止了向混沌行为的过渡,这有助于解释为什么残差连接对于训练极深的网络是必要的。
-
本文通过计算在局部极小值附近 Hessian 矩阵的的最小 (最负) 特征值来定量测量非凸性,并将结果可视化为 heatmap。
-
本文研究了 SGD 优化轨迹的可视化,也解释了可视化这些轨迹时出现的困难。
1.2 损失函数可视化基础
一般通过最小化 来训练神经网络。其中, 表示神经网络的参数, 函数 衡量神经网络对数据样本标签的预测程度, 为数据样本的个数。神经网络包含许多参数, 因此它们的损失函数存在于一个非常高维的空间中。
一维的线性插值可视化方法
一种已有的1维的可视化方法是线性插值法 (Linear interpolation), 就是选择两个参数向量 和 , 并沿连接这两点的直线 绘制损失函数的值 。但是一维线性插值方法有几个缺点。
首先,一维线性插值方法去可视化神经网络的非凸性 (non-convexities) 是很困难的,这就导致了损失函数在最小化轨迹上似乎缺乏局部最小值。一些损失函数具有非凸性,而这些非凸性与不同网络架构之间的泛化差异相关。而且,一维线性插值方法不考虑 Batch Normalization 或者网络中的不变性对称性。因此,由一维线性插值方法产生的插值结果可能具有误导性。
二维的线性插值可视化方法
为了使用二维的线性插值可视化方法, 我们可以在图中选择首先一个中心点 , 并选择两个方向向量 和 。
然后, 在 1D (曲线) 情况下, 绘制一个形式为 的函数, 或者在 2D (平面) 情况下, 绘制一个形式为 的函数。但是, 由于二维绘图的计算负担, 这些方法通常只适合于在小区域中绘制低分辨率图, 没有捕获损失曲面复杂的非凸性。
以上方法的问题
那么以上的一维,二维的线性插值可视化方法不好在哪了呢?虽然以上这两种在随机方向移动一个小距离,并绘制函数值的绘图方法很简单,但它无法捕捉损失函数的固有几何形状,并且不能用于比较两个不同的最小化器或两个不同的神经网络模型的几何形状。这是因为网络权重的比例不变性 (scale invariance) 。当使用 ReLU 非线性激活函数时,如果将网络中某一层的权重乘以10,并将下一层的权重除以10,网络输出将保持不变。当使用 BN 时,同理也存在这种不变性。
那么网络权重的比例不变性 (scale invariance) 对于以上的一维,二维的线性插值可视化方法有哪些影响呢?
具有较大权重的神经网络可能具有平滑且缓慢变化的损失函数:比如说,如果权重的幅值比1大得多,那么将权重扰动一个单位对网络性能的影响很小。但是如果权重远小于1,那么同样的单位扰动可能会产生很大的影响,使损失函数对权重扰动显得相当敏感。
1.3 Filter Normalization
基于以上一维和二维的线性插值可视化方法的缺点,本文提出一种叫做 Filter Normalization 的可视化方法。这种方法的思想也是基于以上的一维,二维的线性插值可视化方法。
以上方法问题的核心其实就来自于 "单位扰动" ,即:
-
对于权重幅值较大的神经网络而言,一个单位的扰动对它没啥作用,即使得 loss 的改变几乎可以忽略不计,那么它就更可能具有一个平滑且缓慢变化的 loss landscape。
-
对于权重幅值较小的神经网络而言,一个单位的扰动对它会产生很大的影响,使得 loss 发生灾难性的改变,使得 loss landscape 对权重扰动显得相当敏感。
那么为了克服这个难题, 本文作者提出一种滤波器归一化 (Filter Normalization) 的做法, 即:对于网络权重 , 和一个随机的高斯方向向量 , 然后作者将 中的每个滤波器归一化, 使其具有与 中相应滤波器相同的范数。换句话说, 进行替换, 如下式所示:

式中, 代表第 层, 第 个滤波器的高斯方向向量, 代表 Frobenius 范数。滤波器归一 化 (Filter Normalization) 并不局限于卷积 (Conv) 层, 也适用于全连接 层 (相当于 卷 积)。
作者在下一节证明了经过滤波器归一化的图的锐度与泛化误差有很好的相关性,而没有滤波器归一化的图可能非常具有误导性。
1.4 可视化实验:Loss landscape 尖锐,扁平的困境
在上一节中,我们提到有的神经网络具有平滑且缓慢变化的 loss landscape (称为 sharp minimizer),而有的具有剧烈变化的 loss landscape (称为 flat minimizer)。在本节中,将通过一些实验结果阐明:sharp minimizer 和 flat minimizer 的泛化性有什么关系?
在这里呢,作者探讨了 sharp minimizer 和 flat minimizer 的区别。
具体而言,作者首先训练了一个 CIFAR-10 分类模型 (1个9层的 VGG 模型),使用了2种 Batch Size (8192 和 128)。定义 和 分别是使用小 Batch Size 和大 Batch Size 训练得到的神经网络参数。按照线性插值的做法,作者绘制了中间参数训练和测试数据集上的损失函数值,即:
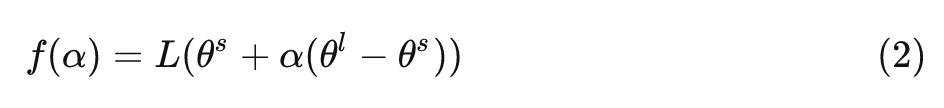
式中, 当 时, 其函数值是使用小 Batch Size 训练得到的损失函数值; 当 时, 其函数值是使用大 Batch Size 训练得到的损失函数值。
如下图 1(a) 所示, 在不使用权重衰减 weight decay 的情况下, 蓝色线是损失函数值, 红色线是精度, 实线是训练曲线, 虚线是测试曲线。可以看到, 随着 从0到1 (即模型参数 从 到 的 过程中), 可以看出小 batch 模型 的曲线很宽, 而大 batch 模型 的曲线很窄。
但是如下图 1(d) 所示, 在使用权重衰减 weight decay 的情况下, 情况则正好相反, 可以看出大 batch 模型 的曲线也变宽了。但是在以上所有实验中, 小 batch 模型 的泛化性一直都很好, 这说明曲线的锐度与模型的泛化性之间没有明显的相关性。
下图 1(b) 和 1(e) 表示使用 weight decay 或者禁用 weight decay 时训练过程中权值范数的变化。当禁用权值衰减时,权值范数在训练过程中不受约束地稳定增长。
下图 1(c) 和 1(f) 表示训练过程中权值分布直方图。可以看到,当大 Batch Size 使用零权重衰减时,得到的权重往往比小 Batch Size 的情况要小。而通过添加 weight decay 可以扭转这种影响。出现这种规模上的差异的原因很简单:较小的 Batch Size 比大的 Batch Size 导致每个周期的权重更新更多,因此权重衰减的收缩效应 (它对权重的范数施加了惩罚) 更明显。
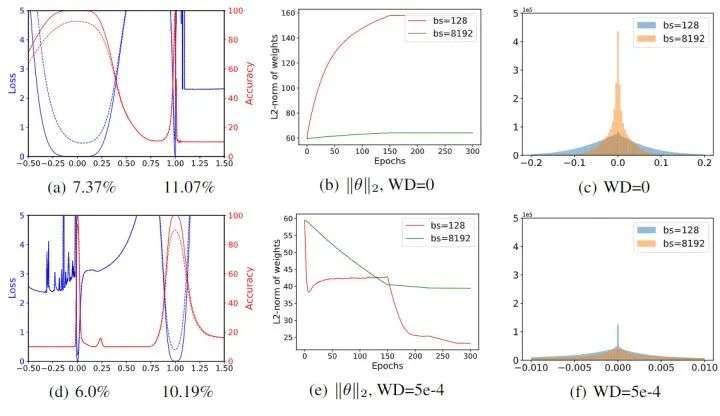
图1:不同 Batch Size 线性插值的可视化结果:(a) 和 (d) 是按照线性插值的做法,绘制中间参数训练和测试数据集上的损失函数值。(b) 和 (e) 表示使用 weight decay 或者禁用 weight decay 时训练过程中权值范数的变化。(c) 和 (f) 表示训练过程中权值分布直方图
1.5 把以上可视化实验再用 Filter Normalization 方法做一遍
在上一节中,作者表明:使用传统的一维线性插值方法得到的结论是:sharp minimizer 和 flat minimizer 的泛化性没什么关系。 在本小节中,作者把以上可视化实验再用 Filter Normalization 方法做一遍。如下图2所示,可视化结果仍然显示了小 Batch Size 和大 Batch Size 最小值之间的锐度差异,但这些差异比在非归一化图中出现的差异要微妙得多。
作者还使用两个随机方向和等高线图来可视化这些结果。用小 Batch Size 和非零权重衰减获得的权重比锐利的大 Batch Size 最小化具有更宽的轮廓。现在我们看到曲线的锐度与模型的泛化性之间很好地相关。大 Batch Size 产生视觉上更尖锐的最小值 (尽管不是很明显),但测试误差更高。
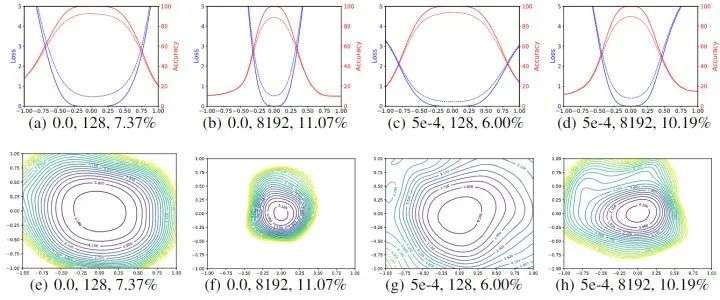
图2:不同 Batch Size 使用滤波器归一化 1D 和 2D 的可视化结果
1.6 究竟什么使得神经网络可训练?一些 Loss Surfaces 非凸结构的发现
大量经验表明,似乎有些神经结构比其他的更容易最小化。例如,使用 Skip Connection,ResNet 使得我们可以训练非常深的神经网络结构,而没有 Skip Connection 的相同的神经网络结构是不可训练的。而且,一个网络是否可以得到良好的训练很大程度上取决于训练开始时的初始参数。
作者使用可视化方法,对神经结构进行了实证研究,以探索为什么损失函数的非凸性在某些情况下似乎是有问题的。希望回答以下问题:
-
损失函数是否具有显著的非凸性?
-
如果非凸性存在,为什么它们在所有情况下都可以训练?
-
为什么有些网络架构容易训练?
-
为什么结果对初始化如此敏感?
实验设置
作者考虑以下3种网络架构:
-
ResNet20/56/110
-
VGG-like 模型,没有残差连接
-
Wide ResNets
所有模型都在 CIFAR-10 数据集上使用 Nesterov 动量 SGD 训练,Batch Size 大小为128,权重衰减为0.0005,持续300个 Epochs。学习率初始化为 0.1,在第150、225和275个 Epoch 下降10倍。使用滤波器归一化的可视化方法,作者对架构如何影响 loss landscape 进行了一些观察。
模型深度的影响
如下图3所示,可以看到,当不使用残差连接时,网络深度对神经网络的 loss landscape 有显著的影响。比如当深度为20时,不使用残差连接的 ResNet-20-NS 有较好的表现,这并不太令人惊讶,因为用于 ImageNet 的原始VGG 网络有19层,也可以有效地训练。但是,随着网络深度的增加,VGG 类网络的损失面自发地从 (近) 凸过渡到混沌。ResNet-56-NS 具有显著的非凸性和大区域,其中梯度方向 (与图中描绘的等高线正常) 不指向中心的最小值。而且,随着向某些方向移动,损失函数会变得非常大。ResNet-110-NS 显示出更明显的非凸性,当我们在图中所示的各个方向移动时,它变得非常陡峭。
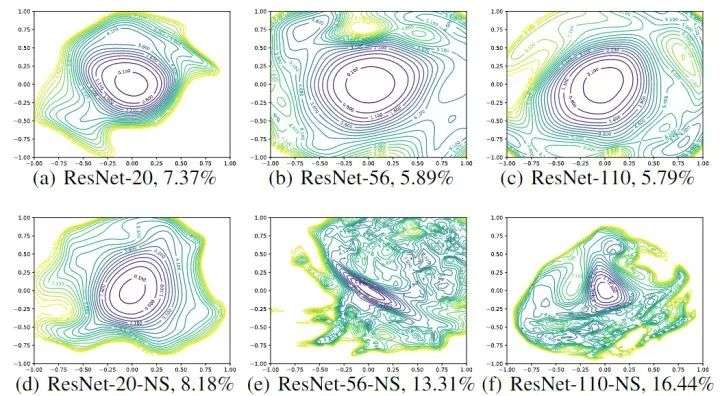
图3:Wide-ResNet-56 有残差连接 (上) 和无残差连接 (下) 的 loss landscape,k=2 意思是每层滤波器数量乘以2
有无残差连接的影响
残差连接对损失函数的 loss landscape 有显著的影响。在上图3中可以看到,随着深度的增加,残差连接阻止了向混沌行为的过渡。残差连接的影响似乎对深的网络架构最为重要。对于更浅的网络 (ResNet-20 和 ResNet-20-NS),残差连接的影响不明显。如下图4所示是 ResNet-56 有无残差连接的 loss landscape 对比,图5所示是 ResNet-110 无残差连接和 DenseNet 121 层的 loss landscape 对比。
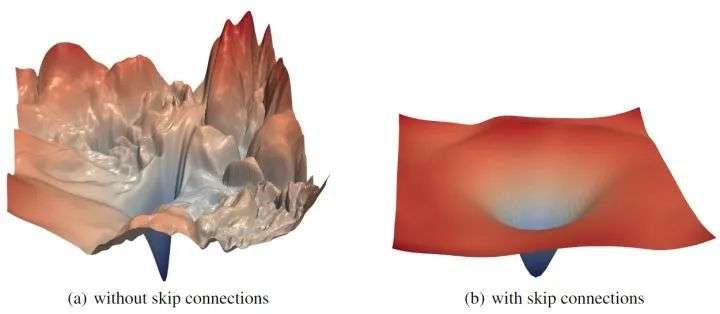
图4:ResNet-56 有无残差连接的 loss landscape 对比
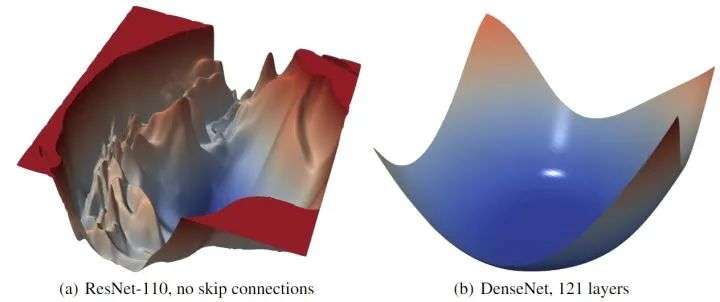
图5:ResNet-110 无残差连接和 DenseNet 121 层的 loss landscape 对比
模型宽度的影响
为了比较每层卷积滤波器数量的影响,作者通过将每层的滤波器数量乘以 来比较更窄或者更宽的 ResNet 的影响。如下图6所示,可以看到更宽的模型的 loss landscape 更宽,即:增大网络宽度可以获得更宽更平坦的 loss landscape。
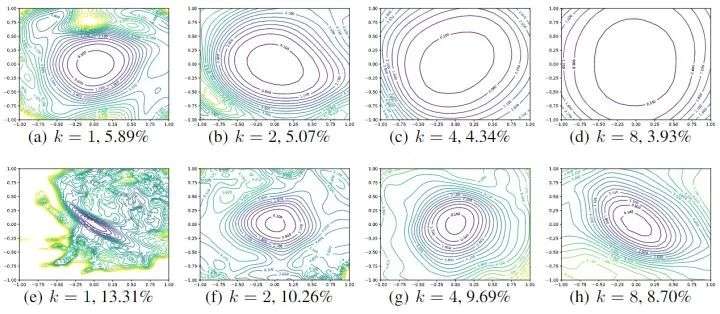
图6:Wide-ResNet-56 有残差连接 (上) 和无残差连接 (下) 的 loss landscape,k=2 意思是每层滤波器数量乘以2
网络初始化的影响
在图3中看到的一个有趣的性质是,网络的 loss landscape 似乎都可以分成两种区域:一种是损失函数值相对较低,loss landscape 的凸性很好;一种是损失函数值相对较高,loss landscape 的凸性很差。这种混沌和凸区域的划分可能解释了良好初始化策略的重要性。
如果一个神经网络模型的 loss landscape 很平坦,那么初始化的位置很可能位于具有 "良好表现" 的损失函数区域,可能永远不会出于非凸的部分。相反,如果一个神经网络模型的 loss landscape 很陡峭,那么初始化的位置很可能由于梯度不足导致增加优化的难度。
图3和图6都表明,loss landscape 对泛化性有显著的影响。混沌,陡峭的 loss landscape (没有残差连接的深度网络) 导致更糟糕的训练和测试误差,而更凸的景观具有更低的误差值。
总结
本文提出一种基于 "Filter Normalization" 的简单可视化方法。当使用这种归一化时,最小化的锐度与泛化误差有很高的相关性,这种展示的可视化结果非常清晰。本文观察到,当网络变得足够深时,神经网络的 loss landscape 会迅速从接近凸的状态过渡到高度混乱的状态。这种从凸到混沌行为的转变伴随着泛化误差的急剧下降,并最终导致整个网络可训练性的下降。本文观察到,残差连接促进了 loss landscape 更加平坦,并阻止了向混沌行为的过渡,这有助于解释为什么残差连接对于训练极深的网络是必要的。本文通过计算在局部极小值附近 Hessian 矩阵的的最小 (最负) 特征值来定量测量非凸性,并将结果可视化为 heatmap。本文研究了 SGD 优化轨迹的可视化,也解释了可视化这些轨迹时出现的困难。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
模型部署交流群:732145323。用于计算机视觉方面的模型部署、高性能计算、优化加速、技术学习等方面的交流。
其它文章


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
2021-02-17 CNN可视化技术总结(四)--可视化工具与项目