Transformer-Based Learned Optimization
前言 本文为学习优化器提出一种新的神经网络体系结构,其灵感来自经典的BFGS算法。和BFGS一样,将预条件矩阵估计为一级更新的和,但使用基于transformer的神经网络来预测这些更新以及步长和方向。与以往几种优化方法相比,能在目标问题的参数空间的不同维度之间进行条件反射,同时仍然适用于变维度的优化任务,无需再训练。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。

论文:https://arxiv.org/pdf/2212.01055.pdf
代码:https://github.com/google/learned_optimization
背景
本文提出了一种新的优化方法。它通过一个表达函数(如多层感知器)表示优化器更新步骤,然后在一组训练优化任务上确定该函数的参数。由于学习到的优化器的更新功能是从数据中估计的,原则上它可以学习各种理想的行为,如学习速率计划和多个局部极小值。这与传统的优化器形成对比,后者是人为设计的,是硬编码的。
对于需要反复解决相关优化任务的应用程序,学习优化器能起到很好的效果。例如,三维人体姿态估计通常被表述为特定损失函数的最小值。对于这种方法,估计不同图像观测的三维姿态需要对许多密切相关的问题反复优化相同的目标函数。传统的优化方法将这些问题视为独立的,而这可能是次优的,因为它没有聚集解决多个相关优化任务的经验。
如图1所示,对基准优化方法的经典优化目标以及基于物理的人体姿态重构的现实任务上对Optimus进行评估。
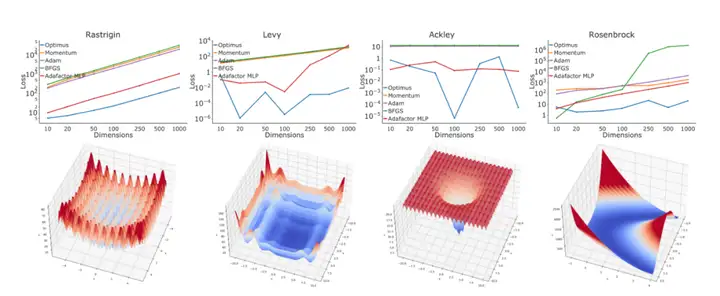
图1。第一行:评估结果,显示优化器为第一行对应的目标函数所达到的平均目标值(y轴)与目标函数的维度(x轴)的对比。最下面一行:用于评估本文方法的目标函数的例子。
本文的主要贡献
1. 介绍了一种用于学习优化的新型神经网络体系结构。
2. 元训练速度明显加快,与BFGS相比,重建质量更好,并且在最小化损失方面更快。
方法
基于transformer的学习优化器Optimus受到BFGS秩一近似方法的启发,该方法用于估计逆Hessian,用作预处理矩阵,以获得下降方向。参数更新是由独立操作每个参数的学习优化器和学习预处理器(Bk)产生的下降方向(sk)的乘积,完整更新如下

Optimus的概述示意图如图2所示。
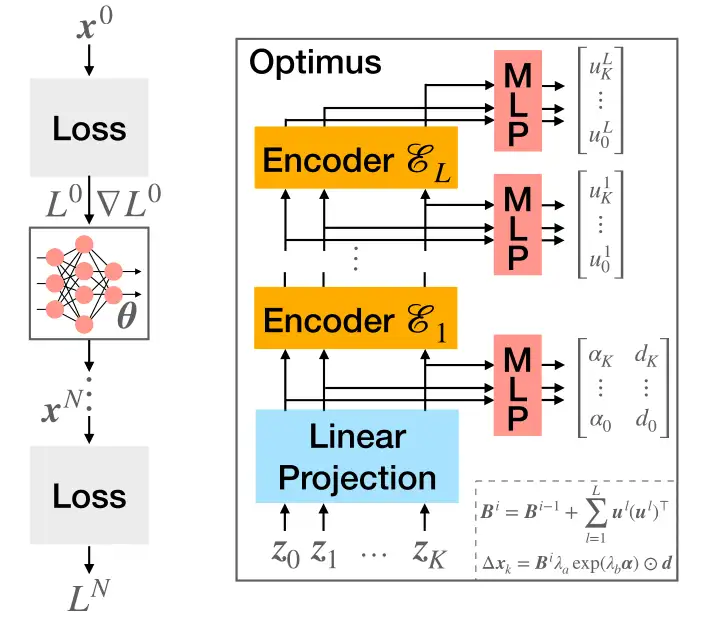
图2。左:基于transformer的学习型优化器Optimus迭代最小化损失L的概述示意图。右:Optimus的架构由L个堆叠的Transformer编码器组成,在给定的特征向量zk下预测参数更新∆xk。
使用两个组件来预测参数更新∆,独立地预测向量x的每个维度的更新方向和幅度。MLP将特征向量作为输入,并输出两个值
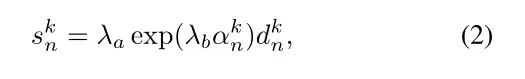
引入一种机制来耦合x的每个维度的优化过程,并使优化算法能够跨迭代存储信息。将这些更新定义为低秩更新
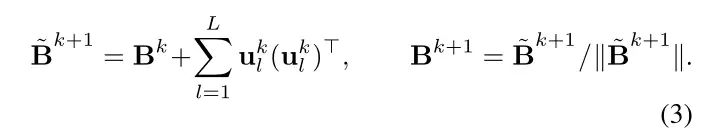
它通过编码器的自我注意力机制实现了单个参数更新之间的耦合。这使得很容易就能扩展到不同维度的问题。并且它允许优化器跨迭代积累信息,类似于BFGS如何随着优化的进行逐步逼近逆Hessian矩阵。本文方法通过学习在其他学习优化器(如Adafactor MLP)中估计的一阶更新的预条件来实现。虽然这种预处理方法大大提高了步长,但其计算成本随参数数量的增加呈二次增长。
实验
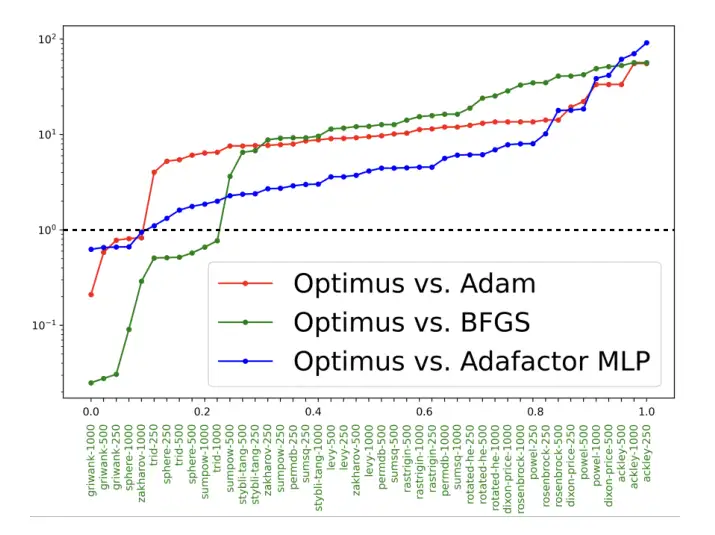
图4。Optimus与Adam、BFGS和Adafactor MLP在达到目标函数预定义最小值所需的相对迭代次数的比较。
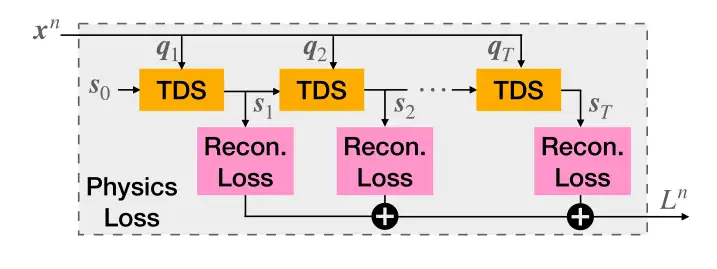
图6。在DiffPhy方法的基础上介绍的物理损失概述。优化变量x对应于物理模拟人体的关节力矩,其目标是最小化物理特征与观察到的视觉证据之间的姿势重建损失。
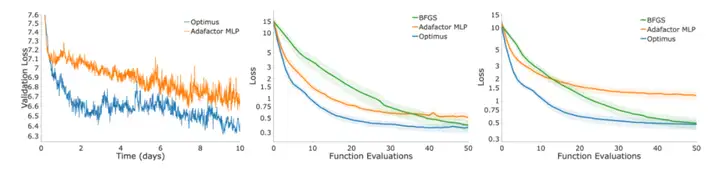
图7。左:Optimus和Adafactor MLP训练过程中验证损失的比较。中:在tab中“in domain”示例优化过程中损失曲线的比较。右:tab中“域外”示例优化过程中的损失曲线。

表1。针对Human3.6M验证集的运动捕捉数据进行轨迹优化的不同方法的比较。
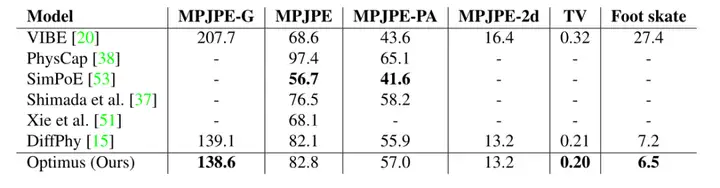
表2。对Human3.6M验证集的定量结果比较。

表3。泛化到新数据集的定量结果。
结论
本文引入了一种新的学习过的优化器,它具有可表达的体系结构,可以捕获参数空间中的复杂依赖项。此外,还证明了Optimus对于基于物理的三维重建的现实任务以及经典优化问题的基准测试的有效性。且Optimus适合于损失函数主导优化计算复杂度的任务(例如,基于物理的重构)。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
模型部署交流群:732145323。用于计算机视觉方面的模型部署、高性能计算、优化加速、技术学习等方面的交流。
ECCV2022 | 重新思考单阶段3D目标检测中的IoU优化
Vision Transformer和MLP-Mixer联系和对比
从零搭建Pytorch模型教程(三)搭建Transformer网络
从零搭建Pytorch模型教程(四)编写训练过程--参数解析
从零搭建Pytorch模型教程(五)编写训练过程--一些基本的配置
从零搭建pytorch模型教程(八)实践部分(一)微调、冻结网络
从零搭建pytorch模型教程(八)实践部分(二)目标检测数据集格式转换

 浙公网安备 33010602011771号
浙公网安备 33010602011771号